海報
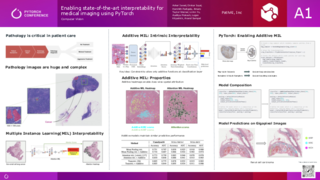
使用 PyTorch 啟用醫療影像最先進的可解釋性
Dinkar Juyal, Syed Asher Javed, Harshith Padigela, Limin Yu, Aaditya Prakash, Logan Kilpatrick, Anand Sampat, PathAI
PathAI 是一家位於波士頓的公司,致力於使用 AI 驅動的病理學來改善患者護理。我們大量使用 PyTorch 來建構我們的 ML 系統,特別是在大型十億像素病理影像上訓練和部署模型。在本案例研究中,我們將重點介紹我們如何使用 PyTorch 來建構、實驗和部署 Additive Multiple Instance Learning (MIL) 模型。Additive MIL 是一種使用 PyTorch Lightning 建構的新型 MIL 技術,可實現從數百萬像素進行端到端學習,同時提供空間熱圖的細緻可解釋性。這些模型可以精確計算十億像素大小影像中的每個較小區域對最終模型預測的貢獻程度。這使得可以在病理影像之上視覺化類別方向的興奮性和抑制性貢獻。這可以告知從業者模型失敗的原因,並引導病理學家找到感興趣的區域。所有這些都得益於 PyTorch 快速的研究到原型到部署的迭代週期。
電腦視覺

TorchUnmix:用於 PyTorch 中組織病理學影像的自動染色分離和擴增
Erik Hagendorn
TorchUnmix 是一個旨在為組織病理學全玻片影像提供自動染色分離和擴增的程式庫。組織化學染色的分離(分離)是透過正交轉換來自預定義的光吸收係數(稱為染色向量)的 RGB 像素資料來執行的 [1]。經常使用預先計算的公開可用染色向量定義,但由於組織學和/或影像擷取過程,實驗室間的差異很常見,導致次優的分離結果。傳統的染色向量估計方法依賴於染色的豐富分佈,使其對於從免疫組織化學染色觀察到的較稀疏分佈不太實用。Geis 等人提出了一種基於色調-飽和度-密度色彩空間中像素值的 k 平均值聚類來確定最佳染色向量的方法,該方法已在本研究中使用 [2]。雖然染色向量可用於量化個別染色,但 TorchUnmix 還提供執行染色擴增的功能。染色擴增是一種在深度學習模型訓練過程中使用的方法,透過分離影像、隨機修改個別染色,然後將染色組合成最終的擴增影像來提高泛化能力 [3]。據我們所知,沒有其他程式庫在 PyTorch 中完全實現上述方法,並利用 GPU 加速。此外,TorchUnmix 還擴展了用於執行自動染色分離和擴增的所有計算,使其能夠在成批影像上運作,與其他程式庫相比,大幅提高了執行效能速度。
程式庫

使用 Ray AIR 進行可擴展的訓練和推論
Kai Fricke, Balaji Veeramani
擴展機器學習很困難:像 SageMaker 這樣的雲端平台解決方案可能會限制彈性,但客製化的分散式框架通常難以實作。實際上,ML 工程師很難將他們的工作負載從本機原型設計擴展到雲端。Ray AI Runtime ('Ray AIR') 是一個圍繞分散式運算框架 Ray 建構的機器學習程式庫的整合集合。它提供了一個易於使用的介面,用於可擴展的資料處理、訓練、調整、批次預測和線上服務。將現有的 PyTorch 訓練迴圈調整為 Ray AIR 的 PyTorch 整合只需要少至 10 行程式碼的變更。而從本機開發擴展到雲端根本不需要任何程式碼變更。
程式庫

AutoMAD:用於 PyTorch 模型的混合模式自動微分
Jan Hückelheim
混合模式自動微分結合了反向傳播和正向微分。兩種模式都有優缺點:對於具有許多可訓練參數的標量函數,反向傳播是有效的。反向傳播使用記憶體來儲存中間結果,需要資料流反轉,對於許多輸出變數而言,可擴展性較差。正向微分易於實作、節省記憶體,並且易於向量化/平行化或移植到新的硬體。正向模式在大量可訓練參數的情況下,可擴展性較差。AutoMAD 可以將兩種模式結合起來。對某些層使用正向微分,而對其他層使用反向傳播。
程式庫

xFormers:高效 Transformer 的建構模塊
Daniel Haziza, Francisco Massa, Jeremy Reizenstein, Patrick Labatut, Diana Liskovich
我們展示 xFormers,這是一個加速 Transformer 研究的工具箱。 它包含高效的組件,例如一種高效記憶體的多頭注意力機制,可以加速訓練 2 倍,同時使用一小部分的記憶體。 xFormers 組件也是可客製化的,並且可以組合在一起以構建 Transformer 的變體。 我們希望能夠促進基於 Transformer 的下一代研究。
程式庫

linear_operator - PyTorch 中的結構化線性代數
Max Balandat
linear_operator (https://github.com/cornellius-gp/linear_operator) 是一個基於 PyTorch 構建的結構化線性代數庫。 它提供了一個 LinearOperator 類別,該類別表示從未實例化的張量,而是通過矩陣乘法、求解、分解和索引等操作進行訪問。 這些對象使用客製化的線性代數運算,可以利用特定的矩陣結構(例如,對角、塊對角、三角形、Kronecker 等)進行計算,從而在時間和記憶體複雜度方面實現顯著(多個數量級)的改進。 此外,許多高效的線性代數運算(例如,求解、分解、索引等)可以從 LinearOperator 的 matmul 函數自動生成。 這使得組合或實現客製化的 LinearOperator 變得非常容易。 使 linear_operator 易於在 PyTorch 代碼中使用的關鍵方面是它與 `__torch_function__` 介面的整合 - 常見的線性代數運算(例如矩陣乘法、求解、SVD)被映射到相應的 torch 函數 (`__matmul__`、`torch.linalg.solve`、`torch.linalg.svd`),因此 LinearOperator 對象可以作為密集張量的直接替代品,即使在現有程式碼中也是如此。 LinearOperator 運算本身可能會返回 LinearOperator 對象,在每次計算後自動追蹤代數結構。 因此,使用者永遠不需要推斷使用哪種高效的線性代數例程(只要使用者定義的輸入元素編碼已知的輸入結構即可)。
程式庫

使用 Ludwig 進行聲明式機器學習:使用簡單而靈活的數據驅動配置的端到端機器學習管道
Justin Zhao
Ludwig 是一個聲明式機器學習框架,可以使用簡單而靈活的數據驅動配置系統輕鬆定義和比較機器學習管道。 最小配置聲明了輸入和輸出特徵及其各自的數據類型。 使用者可以指定額外的參數來預處理、編碼和解碼特徵,從預訓練模型載入,組合內部模型架構,設置訓練參數或執行超參數優化。 Ludwig 將自動構建一個端到端機器學習管道,使用配置中明確指定的任何內容,同時回復為任何未指定參數的智慧預設值。 科學家、工程師和研究人員使用 Ludwig 來探索最先進的模型架構,運行超參數搜索,並擴展到大於可用記憶體數據集和多節點集群,解決使用結構化和非結構化特徵的各種問題。 Ludwig 在 Github 上擁有 8.5K+ 星星,並且構建在 PyTorch、Horovod 和 Ray 之上。
程式庫

廣義形狀:塊稀疏性、MaskedTensor、NestedTensor
Christian Puhrsch
此海報概述了與稀疏記憶體格式、遮罩計算以及對可變形狀數據集合的支援相關的可用和正在進行的開發。 特別是,它包含塊稀疏記憶體格式、MaskedTensor 和 NestedTensor 的案例研究。
程式庫

Betty:用於廣義元學習的自動微分庫
Sang Keun Choe
Betty 是一個簡單、可擴展且模組化的庫,用於廣義元學習 (GML) 和多層優化 (MLO),構建在 PyTorch 之上,它為許多 GML/MLO 應用程式(包括少樣本學習、超參數優化、神經架構搜索、數據重新加權等等)提供統一的程式設計介面。 Betty 的內部自動微分機制和軟體設計是通過將 GML/MLO 新穎地解釋為數據流圖來開發的。
程式庫

Functorch:Pytorch 中的可組合函數轉換
Samantha Andow, Richard Zhou, Horace He, Animesh Jain
受到 Google JAX 的啟發,functorch 是 Pytorch 中的一個庫,提供可組合的 vmap(向量化)和自動微分轉換(grad、vjp、jvp)。 自從它與 Pytorch 1.11 一起首次發布以來,結合這些轉換幫助使用者開發和探索以前在 Pytorch 中難以編寫的新技術,例如神經正切核和非線性優化(參見 PyTorch 中的 Theseus)。 這將介紹一些基本用法,並重點介紹一些利用 functorch 的研究。
程式庫

用於偏微分方程的大規模神經求解器
Patrick Stiller, Jeyhun Rustamov, Friedrich Bethke, Maksim Zhdanov, Raj Sutarya, Mahnoor Tanveer, Karan Shah, Richard Pausch, Sunna Torge, Alexander Debus, Attila Cangi, Peter Steinbach, Michael Bussmann, Nico Hoffmann
我們的開源神經求解器框架提供基於數據的免資料 ML 求解器,用於研究和分析基於 Pytorch 的自然科學中的現象。 我們是第一個證明由 2d Schr√∂dinger 方程建模的某些量子系統可以精確求解,同時保持強大的擴展性。 我們還開發了一種新的神經網絡架構 GatedPINN [1],將基於專家混合範例的可適應域分解引入到 Physics-informed 神經網絡的訓練中。 Horovod 促進了我們的 GatedPINN 的分佈式大規模訓練,從而實現了出色的 GPU 利用率,使神經求解器為即將到來的百億億次級時代做好準備。 即將推出的項目涉及更高維度的問題,例如 3d 激光系統和耦合模型,以研究 Vlasov-Maxwell 系統。 在新型高度可擴展的計算硬體上的進一步實驗為高保真神經求解器應用於現實世界的應用(例如逆散射問題)鋪平了道路。
程式庫


模型準備聯邦學習和設備計算
Zhihan Fang
聯邦式學習 (Federated Learning) 與差分隱私 (Differential Privacy) 結合,已成為訓練機器學習模型同時保護使用者隱私最有前景的方法之一,並被越來越廣泛地採用。Meta 中現有關於人物屬性的模型,大多是基於傳統的集中式機器學習方法構建的。最近,由於內部和外部對使用者隱私的日益關注,Meta 的機器學習團隊正面臨訊號遺失或限制,無法在模型中應用新功能來進一步提高模型效能。在本文中,我們將介紹我們構建的一個通用框架,用於準備和產生用於聯邦式學習的模型。模型準備過程是利用傳統的機器學習來了解目標問題的模型結構和超參數,包括訓練、推論、評估。它還需要一個模擬過程,來訓練目標模型結構並了解伺服器端的模擬環境,以調整聯邦式學習 (FL) 特定的超參數。模型產生過程是產生與設備相容的模型,這些模型可以直接在使用者的設備上用於聯邦式學習。我們將聯邦式學習框架應用於我們的設備端模型,並與設備訊號整合,以改善使用者體驗並保護使用者隱私。
程式庫

PyTorch 中使用 Cooper 進行約束優化
Jose Gallego-Posada, Juan Camilo Ramirez
Cooper (https://github.com/cooper-org/cooper) 是一個通用、深度學習優先的 PyTorch 約束優化函式庫。 Cooper 與 PyTorch (幾乎!) 無縫整合,並保留了通常的損失反向傳播步驟工作流程。 如果您已經熟悉 PyTorch,使用 Cooper 將會非常容易! 該函式庫旨在鼓勵和促進深度學習中約束優化問題的研究。 Cooper 專注於非凸約束優化問題,其中損失或約束不一定是「表現良好」或「理論上容易處理」的。 此外,Cooper 的設計考慮到可以很好地與目標函數和約束函數的 Mini-batch/隨機估計一起使用。 Cooper 實作了幾個流行的約束優化協議,因此您可以專注於您的專案,而我們則負責幕後的細節。
https://github.com/cooper-org/cooper
程式庫

使用分散式張量進行二維平行處理
Wanchao Liang, Junjie Wang
本次演講將介紹使用分散式張量的 PyTorch 二維平行處理 (資料平行處理 + 張量平行處理),分散式張量是 PyTorch Distributed 提供的一個基本分散式基元,可以支援張量平行處理。 我們已經證明,將 FSDP + 張量平行處理結合使用可以讓我們訓練像 Transformer 這樣的大型模型,並提高訓練效能。 我們提供端到端的訓練技術,讓您能夠以二維平行處理方式訓練模型,並以分散式方式儲存/載入檢查點模型。
程式庫

PyTorch Tabular:用於表格資料深度學習的框架
Manu Joseph
儘管深度學習在文字和圖像等模態中表現出非凡的有效性,但在表格資料中,無論在普及度還是效能方面,一直落後於梯度提升。 但最近出現了一些專門為表格資料建立的新模型,這些模型正在推高效能的門檻。 然而,普及度仍然是一個挑戰,因為沒有像 Sci-Kit Learn 這樣易於使用、即用型的深度學習函式庫。 PyTorch Tabular 旨在改變這一點,它是一個易於使用且靈活的框架,可以像 Sci-Kit Learn 一樣輕鬆地在表格資料中使用 SOTA 模型架構。
程式庫

Better Transformer:加速 PyTorch 中的 Transformer 推論
Michael Gschwind, Christian Puhrsch, Driss Guessous, Rui Zhu, Daniel Haziza, Francisco Massa
我們介紹 Better Transformer,這是一個 PyTorch 專案,旨在透過實作 Better Transformer 'fastpath' 來加速 Transformer 的推論和訓練,並且可以立即啟用。 Fastpath 加速了 Transformer 模型中最常執行的許多函數。 從 PyTorch 1.13 開始,PyTorch Core API 使用加速運算來實作,可在許多 Transformer 模型(例如 BERT 和 XLM-R)上提供高達 2 倍-4 倍的加速。 加速運算基於 (1) 運算子和核心融合,以及 (2) 利用可變序列長度 NLP 批次產生的稀疏性。 除了透過 fastpath 改善 MultiHeadAttention 之外,該模型還包括對 MultiHeadAttention 和 TransformerEncoder 模組的稀疏性支援,以利用具有巢狀張量的可變序列長度資訊來處理 NLP 模型。 目前,我們使用 Better Transformer 啟用了 torchtext 和 Hugging Face 網域函式庫,從而為文字、圖像和音訊模型帶來顯著的加速。 從下一個版本開始,PyTorch 核心將包含更快的融合核心和訓練支援。 您可以使用 PyTorch Nightlies(即將發佈的 PyTorch 版本的每日預覽版本)來預覽這些功能。
程式庫

PiPPy:適用於 PyTorch 的自動管線平行處理
Ke Wen, Pavel Belevich, Anjali Sridhar
PiPPy 是一個為 PyTorch 模型提供自動管線平行處理的函式庫。 透過編譯器技術,PiPPy 將模型分割成多個管線階段,而無需變更模型。 PiPPy 還提供了一個分散式執行時間,將分割階段分發到多個裝置和主機,並以重疊方式協調微批次執行。 我們展示了 PiPPy 在 Hugging Face 模型上的應用,在雲端平台上實現了 3 倍的加速。
程式庫

使用 AWS Inferentia 進行 PyTorch 推論的實用指南
Keita Watanabe
在本節中,我們將逐步介紹如何使用 Inferentia 執行機器學習模型的推論過程。 此外,我們將比較與 GPU 的推論效能,並討論成本優勢。 在本節的後段,我們還將介紹 Kubernetes 上的模型部署。
優化

PyG CPU 效能優化
Mingfei Ma
透過更快的稀疏聚合來加速 PyG CPU 效能。 PyG 是一個建立在 PyTorch 上的函式庫,可以輕鬆地編寫和訓練圖神經網路,它嚴重依賴訊息傳遞機制來進行資訊聚合。 我們優化了來自 PyTorch 的訊息傳遞的關鍵瓶頸,包括: 1. Scatter Reduce:當 EdgeIndex 以 COO 記憶體格式儲存時,對應於典型的 PyG 使用案例。 2. SpMM Reduce:當 EdgeIndex 以 CSR 記憶體格式儲存時,對應於使用案例。
優化

PyTorch 2.0 匯出中的量化
Jerry Zhang
目前,PyTorch 架構優化 (torch.ao) 提供兩種量化流程工具:Eager Mode 量化 (beta) 和 FX Graph Mode 量化 (prototype)。 隨著 PyTorch 2.0 即將推出,我們將在 PyTorch 2.0 匯出路徑之上重新設計量化,本次演講將介紹我們在 PyTorch 2.0 匯出路徑中支援量化的計劃、其相較於先前工具的主要優勢,以及模型開發人員和後端開發人員將如何與此流程互動。
優化

Torch-TensorRT:用於加速使用 TensorRT 進行 PyTorch 推論的編譯器
Naren Dasan, Dheeraj Peri, Bo Wang, Apurba Bose, George Stefanakis, Nick Comly, Wei Wei, Shirong Wu, Yinghai Lu
Torch-TensorRT 是一個開源編譯器,目標是 NVIDIA GPU,用於在 PyTorch 中實現高效能的深度學習推論。它結合了 PyTorch 的易用性與 TensorRT 的效能,可以輕鬆最佳化 NVIDIA GPU 上的推論工作負載。 Torch-TensorRT 支援 TensorRT 中的所有類別最佳化,包括降低混合精度到 INT8,透過簡單的 Python 和 C++ API 設計,可以直接從 PyTorch 工作。 Torch-TensorRT 輸出標準 PyTorch 模組以及 TorchScript 格式,以允許一個完全獨立、可移植和靜態的模組,其中嵌入了 TensorRT 引擎。我們展示了 Torch-TensorRT 的最新改進,包括新的 FX 前端,它允許開發人員使用完整的 Python 工作流程來最佳化模型,並在 Python 中擴展 Torch-TensorRT,以及統一的 Torch-TensorRT Runtime,它啟用了混合 FX + TorchScript 工作流程,並討論了該專案的未來工作。
優化

透過利用 oneDNN Graph 的圖融合來加速 PyTorch 的推論
Sanchit Jain
開源的 oneDNN Graph 函式庫透過靈活的圖形 API 擴展了 oneDNN,以最大化在 AI 硬體(目前為 x86-64 CPU,但 GPU 支援即將推出)上生成高效程式碼的最佳化機會。它會自動識別要透過融合加速的圖形分割區。其融合模式包括融合計算密集型操作,例如卷積、matmul 及其相鄰操作,用於推論和訓練用例。自 PyTorch 1.12 以來,oneDNN Graph 已作為實驗性功能支援,以加速 x86-64 CPU 上 Float32 資料類型的推論。在 PyTorch master 分支中存在使用 oneDNN Graph 進行 BFloat16 資料類型推論的支援,因此也存在於每晚發布的 PyTorch 版本中。 Intel Extension for PyTorch 是一個基於 PyTorch 之上的開源函式庫,可以被視為 Intel 在 PyTorch 中進行最佳化的「臨時場所」。它利用 oneDNN Graph 進行 int8 資料類型的推論。本海報展示了使用 PyTorch 的 TorchBench 基準測試套件的可重現結果,以展示使用 Float32、BFloat16 和 int8 資料類型的 PyTorch 和 oneDNN Graph 實現的推論加速。
優化

回到 Python:無需觸碰 C++ 即可擴展 PyTorch
Alban Desmaison
本海報介紹了 PyTorch 團隊設計的新的擴展點,允許使用者從 Python 擴展 PyTorch。我們將介紹 Tensor Subclassing、Modes 和 torch 函式庫。我們將簡要描述每個擴展點,並透過記憶體分析、日誌記錄使用的運算符、量化和自訂稀疏核心等範例進行說明,所有這些都在少於 100 行程式碼中完成。我們還將介紹您無需直接修改 PyTorch 即可新增新裝置和編寫核心的新方法。
其他

PyTorch 中的函數化 (Functionalization)
Brian Hirsh
函數化是一種從傳送給下游編譯器的任意 PyTorch 程式中刪除突變的方法。 PyTorch 2.0 堆疊的全部內容是捕獲 PyTorch 運算的圖形,並將它們傳送給編譯器以獲得更好的效能。 PyTorch 程式可以突變和別名狀態,這使得它們對編譯器不友好。函數化是一種採用包含 PyTorch 運算符(包括可變和別名運算符)的程式,並從程式中刪除所有突變,同時保留語義的技術。
其他

Walmart Search:在 TorchServe 上大規模提供模型服務
Pankaj Takawale, Dagshayani Kamalaharan, Zbigniew Gasiorek, Rahul Sharnagat
Walmart Search 已開始在搜尋生態系統中採用深度學習,以改善各個部分的搜尋相關性。作為我們的試點用例,我們希望在執行時提供計算密集型的 Bert Base 模型服務,目標是實現低延遲和高吞吐量。我們有 JVM 託管的 Web 應用程式加載並提供多個模型服務。實驗模型正在被加載到相同的應用程式上。這些模型尺寸很大,計算成本很高。我們使用這種方法面臨以下限制:使用最新版本更新模型或新增新的實驗模型需要應用程式部署。單個應用程式的記憶體壓力增加。由於在啟動期間加載多個 ML 模型,因此啟動時間較慢。由於 CPU 限制,並行性沒有好處(並行模型預測與循序模型的指標)。
其他

TorchX:從本地開發到 Kubernetes 並返回
Joe Doliner, Jimmy Whitaker
TorchX 對於快速開發 PyTorch 應用程式非常有用。但當涉及部署時,沒有什麼是容易的。透過 docker 開發、Kubernetes 和客戶排程器,有很多東西需要學習。在本次演講中,我們將討論組織如何部署到生產環境,為什麼 TorchX 是一個很棒的系統,以及我們學到的經驗,以便您可以避免遇到它們。
生產環境 (PRODUCTION)

使用 Fully Sharded Data Parallel (FSDP) 和 PyTorch/XLA 進行大規模訓練
Shauheen Zahirazami, Jack Cao, Blake Hechtman, Alex Wertheim, Ronghang Hu
PyTorch/XLA 使 PyTorch 使用者能夠在 XLA 裝置(包括 Google 的 Cloud TPU)上執行其模型。 PyTorch/XLA 的最新改進使可以使用 FSDP 訓練 PyTorch 模型來訓練非常大的模型。在這項工作中,我們展示了在 Cloud TPU v4 上訓練 HuggingFace GPT-2 的基準測試和硬體 Flops 利用率。
生產環境 (PRODUCTION)

FSDP 生產環境準備
Rohan Varma, Andrew Gu
本次演講深入探討了 PyTorch Fully Sharded Data Parallel (FSDP) 的最新進展,這些進展實現了更好的吞吐量、記憶體節省和可擴展性。這些改進已解鎖了對不同模式的模型以及不同模型和資料大小使用 FSDP 的限制。我們將分享將這些功能應用於特定用例(例如 XLMR、FLAVA、ViT、DHEN 和 GPT3 風格模型)的最佳實務。
生產環境 (PRODUCTION)

使用 Kubeflow Pipelines 和 TorchX 編排 Pytorch 工作流程
Erwin Huizenga, Nikita Namjoshi
TorchX 是 PyTorch 應用程式的通用作業啟動器,可幫助 ML 從業者加快迭代時間並支援端到端的生產。在本次演講中,我們將向您展示如何使用 Kubeflow Pipeline (KFL) DSL 建置和運行 TorchX 組件作為管道。我們將詳細介紹如何使用 KFP 和 TorchX 建置組件,以及如何使用 KFP DSL 編排和運行 ML 工作流程。
生產環境 (PRODUCTION)

由社群領導的 ML 編譯器和基礎設施專案的 OSS 生態系統
Shauheen Zahirazami, James Rubin, Mehdi Amini, Thea Lamkin, Eugene Burmako, Navid Khajouei
ML 開發通常因框架和硬體之間的不相容性而受阻,迫使開發人員在建構 ML 解決方案時在技術上妥協。 OpenXLA 是一個由社群領導的 ML 編譯器和基礎設施專案的開源生態系統,由 AI/ML 領導者(包括阿里巴巴、Amazon Web Services、AMD、Arm、Apple、Google、Intel、Meta、NVIDIA 等)共同開發。它將透過讓 ML 開發人員在領先的框架上建構模型,並在任何硬體後端上以高效能執行它們來解決此挑戰。這種靈活性將使開發人員能夠為他們的專案做出正確的選擇,而不是被封閉系統鎖定在決策中。我們的社群將首先協作發展 XLA 編譯器和 StableHLO,這是一種可攜式的 ML 計算運算集,使框架更容易跨不同的硬體選項部署。
生產環境 (PRODUCTION)

壓縮 PyTorch 中的 GPU 記憶體使用量
Mao Lin, Keren Zhou, Penfei Su
有限的 GPU 記憶體資源通常會阻礙 GPU 加速應用程式的效能。雖然 PyTorch 的快取分配器旨在最大限度地減少昂貴的記憶體分配和釋放的次數,並最大限度地提高 GPU 記憶體資源的有效利用率,但我們對常見深度學習模型的研究揭示了顯著的記憶體碎片問題。在某些情況下,多達 50% 的 GPU 記憶體被浪費。為了更好地理解記憶體碎片化的根本原因,我們開發了一種工具,可以透過兩種方式視覺化 GPU 記憶體使用情況:分配器視圖和區塊視圖。分配器視圖顯示每次分配或釋放事件的記憶體使用情況,區塊視圖顯示特定記憶體區塊隨時間的變化。我們的分析揭示了節省 GPU 記憶體的巨大潛力,這將緩解有限資源的瓶頸。透過採用交換、激活重新計算和記憶體重組等策略,我們能夠顯著減少 GPU 記憶體浪費。
工具 (TOOLS)

'Brainchop':瀏覽器內 MRI 體積分割和渲染
Mohamed Masoud, Farfalla Hu, Sergey Plis
在 Brainchop 專案中,我們將高擬真度的預訓練深度學習模型引入科學家和臨床醫師的瀏覽器中,用於結構性磁振造影 (MRI) 的體積分析,而無需他們具備設定 AI 解決方案的技術技能。所有這些都在一個可擴展的開源框架中完成。我們的工具是第一個在網路上支援完整大腦體積處理的前端 MRI 分割工具,可在瀏覽器中一次性完成。此特性由我們輕量且可靠的深度學習模型 Meshnet 提供支援,該模型能夠一次性處理整個大腦的體積,從而以適度的計算需求提高準確性。高品質的客戶端處理解決了隱私問題,因為數據無需離開客戶端。此外,基於瀏覽器的實作能夠利用可用的硬體加速,無論品牌或架構如何。GitHub:https://github.com/neuroneural/brainchop
https://github.com/neuroneural/brainchop
工具 (TOOLS)

TorchBench:量化開發迴圈期間的 PyTorch 效能
Xu Zhao, Will Constable, David Berard, Taylor Robie, Eric Han, Adnan Aziz
對於像 PyTorch 這樣的 ML 框架來說,保持效能水準是一項挑戰。現有的 AI 基準測試(如 MLPerf)是端到端的,因此需要大量的數據集、大規模的 GPU 叢集和長時間的基準測試。我們開發了 TorchBench,這是一個新穎的 AI 基準測試套件,它以最小的數據輸入、單個 GPU 和每次測試僅需幾毫秒的延遲為特色。 TorchBench 現在已部署為 PyTorch 每夜發布過程的一部分,用於防範效能/正確性回歸,並在 SOTA 機器學習模型上測試實驗性的 PyTorch 功能。
工具 (TOOLS)

透過 OpenFold 將 AI 普及化於生物學
Gustaf Ahdritz, Sachin Kadyan, Will Gerecke, Luna Xia, Nazim Bouatta, Mohammed AlQuraishi
OpenFold 由哥倫比亞大學開發,是一個使用 PyTorch 實作的開源蛋白質結構預測模型。 OpenFold 的目標是驗證 AlphaFold 2(DeepMind 的蛋白質結構預測模型)是否可以從頭開始重現,更重要的是,讓系統的元件可供志同道合的研究人員和學者使用,以便他們在其基礎上進行建構。在這項研究中,Weights & Biases 被用於加速 OpenFold 重現 AlphaFold 2。 W&B 的協作性質使得見解可以從單個研究人員擴展到整個團隊,並有助於解決 ML 中的可重現性挑戰。
工具 (TOOLS)
