使用 NVIDIA MPS 執行 TorchServe¶
為了部署 ML 模型,TorchServe 在不同的程序中啟動每個 worker,從而將每個 worker 與其他 worker 隔離。每個程序都會建立自己的 CUDA 上下文來執行其核心並存取已配置的記憶體。
雖然 NVIDIA GPU 在其預設設定中允許在單個裝置上執行多個程序的 CUDA 核心,但它涉及以下缺點
核心的執行通常是序列化的
每個程序都會建立自己的 CUDA 上下文,這會佔用額外的 GPU 記憶體
對於這些情況,NVIDIA 提供多進程服務 (MPS),它
允許在同一 GPU 上多個程序共享相同的 CUDA 上下文
以平行方式執行其核心
這可能會導致
在同一 GPU 上使用多個 worker 時提高效能
由於共享上下文而降低 GPU 記憶體利用率
為了利用 NVIDIA MPS 的優勢,我們需要在啟動 TorchServe 本身之前使用以下命令啟動 MPS 守護程序。
sudo nvidia-smi -c 3
nvidia-cuda-mps-control -d
第一個命令啟用 GPU 的獨佔處理模式,允許只有一個程序(MPS 守護程序)可以使用它。第二個命令啟動 MPS 守護程序本身。要關閉守護程序,我們可以執行
echo quit | nvidia-cuda-mps-control
有關 MPS 的更多詳細資訊,請參閱 NVIDIA 的 MPS 文件。應該注意的是,由於硬體資源有限,MPS 僅允許 48 個程序(對於 Volta GPU)連接到守護程序。向同一個 GPU 新增更多客戶端/worker 將導致失敗。
基準測試¶
為了展示啟動 MPS 的 TorchServe 的效能,並協助決定是否為您的部署啟用 MPS,我們將使用具有代表性的工作負載執行一些基準測試。
首先,我們想要研究在不同的操作點啟動 MPS 後,worker 的輸送量如何演變。作為我們基準測試的範例工作負載,我們選擇 HuggingFace Transformers 序列分類範例。我們在 AWS 上的 g4dn.4xlarge 以及 p3.2xlarge 執行個體上執行基準測試。這兩種執行個體類型都為每個執行個體提供一個 GPU,這將導致在同一 GPU 上排程多個 worker。對於基準測試,我們專注於 benchmark-ab.py 工具測量的模型輸送量。
首先,我們測量單個 worker 在不同批次大小下的輸送量,因為它將向我們展示 GPU 的計算資源在什麼時候被完全佔用。其次,我們測量在我們預期 GPU 仍然有一些資源可以共享的批次大小下,部署了兩個 worker 的輸送量。對於每個基準測試,我們執行五次執行並取執行的中位數。
我們使用以下的 config.json 進行基準測試,僅會相應地覆寫 worker 數量和批次大小。
{
"url":"/home/ubuntu/serve/examples/Huggingface_Transformers/model_store/BERTSeqClassification",
"requests": 10000,
"concurrency": 600,
"input": "/home/ubuntu/serve/examples/Huggingface_Transformers/Seq_classification_artifacts/sample_text_captum_input.txt",
"workers": "1"
}
請注意,我們將並發等級設定為 600,以確保 TorchServe 內的批次聚合將批次填滿至最大批次大小。但同時,由於許多請求將在佇列中等待處理,這會扭曲延遲測量結果。因此,我們將忽略以下內容中的延遲測量。
G4 執行個體¶
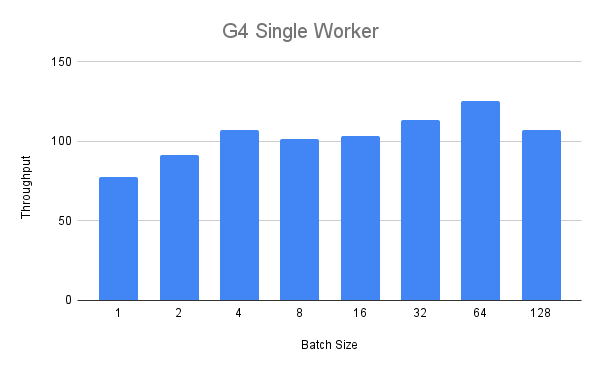
我們首先針對 G4 執行個體執行單一 worker 基準測試。在下圖中,我們看到在批次大小達到 4 之前,輸送量隨著批次大小穩定增加。
接下來,我們將 worker 數量增加到 2,以便比較運行和不運行 MPS 的輸送量。為了為第二組執行啟用 MPS,我們首先為 GPU 設定獨佔處理模式,然後如上所示啟動 MPS 常駐程式。
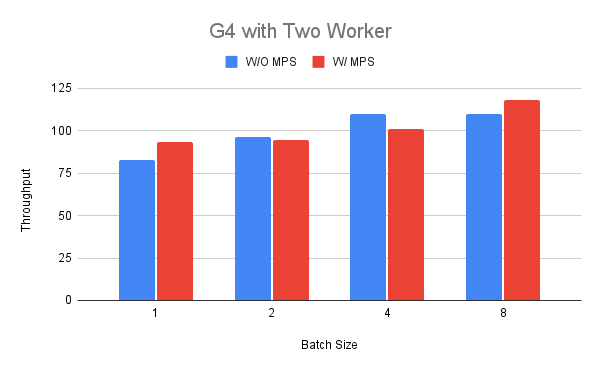
我們根據之前的發現選擇介於 1 到 8 之間的批次大小。在圖中我們可以看到,在批次大小為 1 和 8 的情況下,輸送量方面的效能可能會更好(最高 +18%),而在其他情況下則可能會更差(-11%)。對此結果的一種解釋可能是,當我們在其中一個 worker 中運行 BERT 模型時,G4 執行個體沒有太多資源可以共享。
P3 執行個體¶
接下來,我們將使用更大的 p3.2xlarge 執行個體運行相同的實驗。對於單一 worker,我們得到以下輸送量值
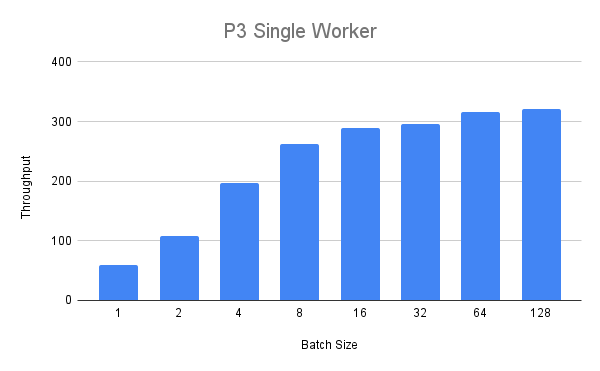
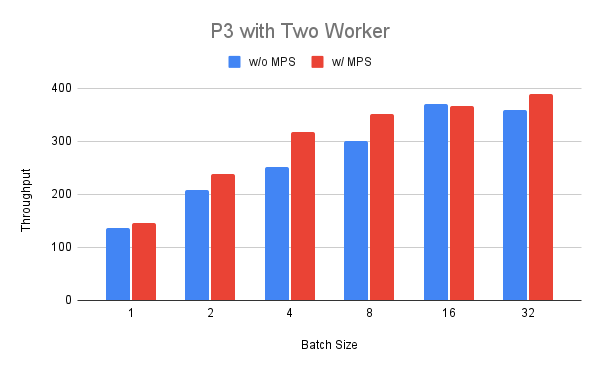
我們可以看到輸送量穩定增加,但對於大於 8 的批次大小,我們看到報酬遞減。最後,我們在 P3 執行個體上部署兩個 worker,並比較啟用和不啟用 MPS 的運行情況。 我們可以看到,對於介於 1 到 32 之間的批次大小,啟用 MPS 的輸送量始終更高(最高 +25%),批次大小 16 除外。
總結¶
在上一節中,我們看到,通過為運行相同模型的兩個 worker 啟用 MPS,我們得到了好壞參半的結果。對於較小的 G4 執行個體,我們僅在某些操作點看到了好處,而對於較大的 P3 執行個體,我們看到了更一致的改進。這表明,在輸送量方面,使用 MPS 運行部署的好處高度依賴於工作負載和環境,需要使用適當的基準測試和工具針對特定情況進行確定。 應該注意的是,之前的基準測試僅側重於輸送量,而忽略了延遲和記憶體佔用。由於使用 MPS 只會建立單一 CUDA 上下文,因此可以將更多 worker 打包到同一個 GPU 中,這也需要在相應的場景中考慮。
