幾週前,TorchVision v0.11 發布,其中包含許多新的元件、模型和訓練配方改進,從而實現了最先進 (SOTA) 的結果。該專案被稱為「TorchVision with Batteries Included」,旨在使我們的函式庫現代化。我們希望透過使用常見的構建模組,使研究人員能夠更輕鬆地重現論文並進行研究。此外,我們渴望為應用 ML 從業者提供必要的工具,以便使用與研究中相同的 SOTA 技術,在他們自己的資料上訓練他們的模型。最後,我們希望更新我們的預先訓練權重,並為我們的使用者提供更好的現成模型,希望他們能夠構建更好的應用程式。
儘管仍有許多工作要做,但我們希望與您分享上述工作的一些令人興奮的結果。我們將展示如何使用 TorchVision 中包含的新工具,在 ResNet50 等競爭激烈且經過充分研究的架構上實現最先進的結果 [1]。我們將分享用於將我們的基準線提高 4.7 個準確度點以上,以達到最終 top-1 準確度 80.9% 的確切配方,並分享推導新訓練過程的歷程。此外,我們將展示此配方可以很好地推廣到其他模型變體和系列。我們希望以上內容將影響未來開發更強大的可推廣訓練方法的研究,並激勵社群採用並為我們的努力做出貢獻。
結果
使用我們在 ResNet50 上找到的新訓練配方,我們更新了以下模型的預先訓練權重
| 模型 | 準確度@1 | 準確度@5 |
|---|---|---|
| ResNet50 | 80.858 | 95.434 |
| ResNet101 | 81.886 | 95.780 |
| ResNet152 | 82.284 | 96.002 |
| ResNeXt50-32x4d | 81.198 | 95.340 |
請注意,除了 RetNet50 之外,所有模型的準確度都可以透過稍微調整其訓練參數來進一步提高,但我們的重點是擁有一個對所有模型都表現良好的單一穩健配方。
更新: 我們已更新了 TorchVision 的大多數流行分類模型,您可以在此 部落格文章中找到詳細資訊。
目前有兩種方法可以使用模型的最新權重。
使用多個預先訓練權重 API
我們目前正在開發一種新的原型機制,該機制將擴展 TorchVision 的模型構建器方法,以支援多個權重。除了權重之外,我們還儲存有用的 元資料(例如標籤、準確度、配方連結等)以及使用模型所需的預處理轉換。範例
from PIL import Image
from torchvision import prototype as P
img = Image.open("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Initialize model
weights = P.models.ResNet50_Weights.IMAGENET1K_V2
model = P.models.resnet50(weights=weights)
model.eval()
# Initialize inference transforms
preprocess = weights.transforms()
# Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
prediction = model(batch).squeeze(0).softmax(0)
# Make predictions
label = prediction.argmax().item()
score = prediction[label].item()
# Use meta to get the labels
category_name = weights.meta['categories'][label]
print(f"{category_name}: {100 * score}%")
使用舊版 API
那些不想使用原型 API 的人可以選擇使用以下方法透過舊版 API 存取新的權重
from torchvision.models import resnet
# Overwrite the URL of the previous weights
resnet.model_urls["resnet50"] = "https://download.pytorch.org/models/resnet50-11ad3fa6.pth"
# Initialize the model using the legacy API
model = resnet.resnet50(pretrained=True)
# TODO: Apply preprocessing + call the model
# ...
訓練配方
我們的目標是使用 TorchVision 新引入的元件來推導出一種新的強大訓練配方,該配方在從頭開始在 ImageNet 上訓練 vanilla ResNet50 架構時(沒有額外的外部資料)實現最先進的結果。儘管透過使用特定於架構的技巧[2]可以進一步提高準確度,但我們決定不包含它們,以便該配方可以用於其他架構。我們的配方非常注重簡單性,並且基於 FAIR 的工作[3]、[4]、[5]、[6]、[7]。我們的發現與 Wightman 等人的平行研究一致。[7],他們也報告了透過專注於訓練配方所實現的重大準確度提升。
事不宜遲,以下是我們配方的主要參數
# Optimizer & LR scheme
ngpus=8,
batch_size=128, # per GPU
epochs=600,
opt='sgd',
momentum=0.9,
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
# Regularization and Augmentation
weight_decay=2e-05,
norm_weight_decay=0.0,
label_smoothing=0.1,
mixup_alpha=0.2,
cutmix_alpha=1.0,
auto_augment='ta_wide',
random_erase=0.1,
ra_sampler=True,
ra_reps=4,
# EMA configuration
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
# Resizing
interpolation='bilinear',
val_resize_size=232,
val_crop_size=224,
train_crop_size=176,
使用我們的標準訓練參考指令碼,我們可以透過以下指令訓練 ResNet50
torchrun --nproc_per_node=8 train.py --model resnet50 --batch-size 128 --lr 0.5 \
--lr-scheduler cosineannealinglr --lr-warmup-epochs 5 --lr-warmup-method linear \
--auto-augment ta_wide --epochs 600 --random-erase 0.1 --weight-decay 0.00002 \
--norm-weight-decay 0.0 --label-smoothing 0.1 --mixup-alpha 0.2 --cutmix-alpha 1.0 \
--train-crop-size 176 --model-ema --val-resize-size 232 --ra-sampler --ra-reps 4
方法
在探索過程中,我們謹記以下幾個原則
- 訓練是一個隨機過程,而我們試圖優化的驗證指標是一個隨機變數。這是因為我們採用隨機權重初始化方案,以及訓練過程中存在隨機效應。這意味著我們無法僅透過單次運行來評估配方變更的效果。標準的做法是進行多次運行(通常是 3 到 5 次),並研究彙總統計數據(例如平均值、標準差、中位數、最大值等)。
- 不同的參數之間通常存在顯著的交互作用,尤其是對於那些專注於正規化和減少過擬合的技術。因此,更改其中一個參數的值可能會影響其他參數的最佳配置。為了應對這種情況,可以採用貪婪搜尋方法(通常會導致次優結果,但實驗易於處理),或者應用網格搜尋(導致更好的結果,但計算成本高昂)。在這項工作中,我們使用了兩者的混合方法。
- 非確定性或引入雜訊的技術通常需要更長的訓練週期才能提高模型效能。為了保持易於處理,我們最初使用短訓練週期(少量 epoch)來決定哪些路徑可以儘早排除,以及哪些路徑應該使用更長的訓練時間來探索。
- 由於重複的實驗,存在過度擬合驗證資料集的風險 [8]。為了降低部分風險,我們僅應用能顯著提高準確性的訓練優化,並使用 K 折交叉驗證來驗證在驗證集上完成的優化。此外,我們確認我們的配方成分可以很好地推廣到我們沒有優化超參數的其他模型。
主要準確性改進的細目
正如在 先前的部落格文章 中討論的,訓練模型並不是一個準確性單調遞增的旅程,這個過程涉及很多回溯。為了量化每次優化的效果,下面我們嘗試展示一個理想化的線性旅程,從 TorchVision 的原始配方開始,推導出最終的配方。我們要澄清的是,這實際上是對我們所遵循的路徑的過度簡化,因此應該有所保留地看待。
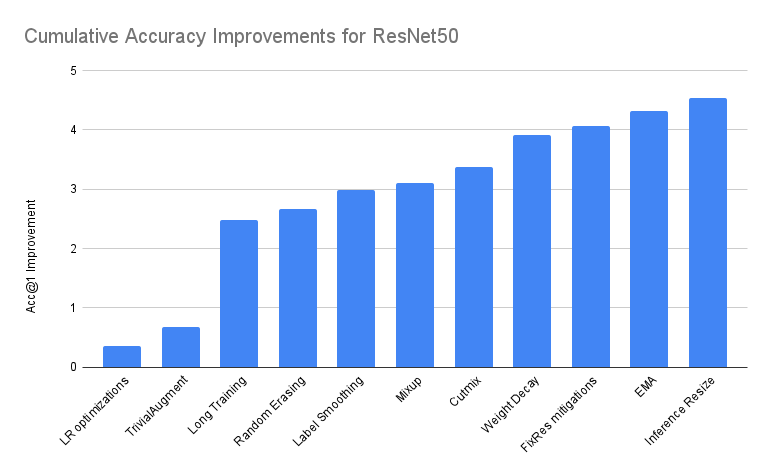
在下表中,我們提供了在 Baseline 之上堆疊增量改進的效能摘要。除非另有說明,否則我們報告的是 3 次運行中 Acc@1 最佳的模型
| 準確度@1 | 準確度@5 | 增量差異 | 絕對差異 | |
|---|---|---|---|---|
| ResNet50 Baseline | 76.130 | 92.862 | 0.000 | 0.000 |
| + LR 優化 | 76.494 | 93.198 | 0.364 | 0.364 |
| + TrivialAugment | 76.806 | 93.272 | 0.312 | 0.676 |
| + 長時間訓練 | 78.606 | 94.052 | 1.800 | 2.476 |
| + 隨機擦除 | 78.796 | 94.094 | 0.190 | 2.666 |
| + 標籤平滑 | 79.114 | 94.374 | 0.318 | 2.984 |
| + Mixup | 79.232 | 94.536 | 0.118 | 3.102 |
| + Cutmix | 79.510 | 94.642 | 0.278 | 3.380 |
| + 權重衰減調整 | 80.036 | 94.746 | 0.526 | 3.906 |
| + FixRes 緩解 | 80.196 | 94.672 | 0.160 | 4.066 |
| + EMA | 80.450 | 94.908 | 0.254 | 4.320 |
| + 推理大小調整 * | 80.674 | 95.166 | 0.224 | 4.544 |
| + 重複擴增 ** | 80.858 | 95.434 | 0.184 | 4.728 |
* 推理大小的調整是在最後一個模型之上完成的。詳情請見下文。
** 社群貢獻是在文章發布後完成的。詳情請見下文。
Baseline
我們的 baseline 是先前發布的 TorchVision 的 ResNet50 模型。它使用以下配方進行訓練
# Optimizer & LR scheme
ngpus=8,
batch_size=32, # per GPU
epochs=90,
opt='sgd',
momentum=0.9,
lr=0.1,
lr_scheduler='steplr',
lr_step_size=30,
lr_gamma=0.1,
# Regularization
weight_decay=1e-4,
# Resizing
interpolation='bilinear',
val_resize_size=256,
val_crop_size=224,
train_crop_size=224,
以上大多數參數都是我們 訓練腳本 上的預設值。我們將從這個 baseline 開始,透過引入優化來逐步達到最終的配方。
LR 優化
我們可以應用一些參數更新來提高準確性和訓練速度。這可以透過增加 batch size 並調整 LR 來實現。另一種常見的方法是應用 warmup 並逐步增加我們的學習率。這在使用非常高的學習率時尤其有益,並有助於早期 epoch 中訓練的穩定性。最後,另一個優化是應用 Cosine Schedule 來調整我們在 epoch 期間的 LR。cosine 的一個很大的優點是沒有超參數需要優化,這減少了我們的搜尋空間。
以下是在 baseline 配方之上應用的額外優化。請注意,我們已經進行了多次實驗來確定參數的最佳配置
batch_size=128, # per GPU
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
與 baseline 相比,上述優化將我們的 top-1 準確度提高了 0.364 個點。請注意,為了結合不同的 LR 策略,我們使用了新引入的 SequentialLR scheduler。
TrivialAugment
原始模型是使用基本的擴增轉換進行訓練的,例如 Random resized crops 和 horizontal flips。提高我們準確性的一個簡單方法是應用更複雜的“自動擴增”技術。對我們來說效果最好的是 TrivialAugment [9],它非常簡單,可以被認為是“無參數的”,這意味著它可以幫助我們進一步減少我們的搜尋空間。
以下是在上一步的基礎上應用的更新
auto_augment='ta_wide',
與上一步相比,使用 TrivialAugment 將我們的 top-1 準確度提高了 0.312 個點。
長時間訓練
當我們的配方包含隨機行為的成分時,更長的訓練週期是有益的。更具體地說,當我們開始添加越來越多的引入雜訊的技術時,增加 epoch 的數量變得至關重要。請注意,在我們探索的早期階段,我們使用了相對較短的週期,約為 200 個 epoch,後來當我們開始縮小大多數參數範圍時,增加到 400 個,最後在配方的最終版本中增加到 600 個 epoch。
下面我們看到在上一步的基礎上應用的更新
epochs=600,
這在上一步的基礎上進一步將我們的 top-1 準確度提高了 1.8 個點。這是我們在這個迭代過程中將觀察到的最大增長。值得注意的是,這個單一優化的效果被誇大了,並且有些誤導。僅僅在舊的 baseline 之上增加 epoch 的數量不會產生如此顯著的改進。然而,LR 優化與強大的擴增策略相結合,有助於模型從更長的週期中受益。同樣值得一提的是,我們在過程的早期引入長時間的訓練週期,是因為在下一步中,我們將引入需要明顯更多 epoch 才能提供良好結果的技術。
隨機擦除
另一種已知有助於提高分類準確性的資料擴增技術是隨機擦除 [10], [11]。它通常與自動擴增方法配對使用,由於其正規化效果,通常會產生額外的準確性改進。在我們的實驗中,我們僅透過網格搜尋調整了應用該方法的機率,並發現將其機率保持在較低水平(通常約為 10%)是有益的。
以下是在上一步的基礎上引入的額外參數
random_erase=0.1,
應用隨機擦除會使我們的 Acc@1 進一步提高 0.190 個點。
標籤平滑
減少過擬合的一個好技術是阻止模型變得過於自信。這可以透過使用標籤平滑 [12] 來軟化 ground truth 來實現。有一個單一參數控制平滑程度(越高越強),我們需要指定。雖然可以透過網格搜尋來優化它,但我們發現 0.05-0.15 左右的值會產生相似的結果,因此為了避免過擬合,我們使用了與引入它的論文中相同的值。
下面我們可以找到在此步驟中添加的額外配置
label_smoothing=0.1,
我們使用 PyTorch 新引入的 CrossEntropyLoss label_smoothing 參數,這將我們的準確性額外提高了 0.318 個點。
Mixup 和 Cutmix
Mixup 和 Cutmix 是兩種常用於產生 SOTA (state-of-the-art) 結果的資料擴增技術 [13], [14]。它們藉由軟化標籤和影像,提供強大的正規化效果。在我們的設定中,我們發現以相同機率隨機應用其中一種方法是有益的。每種方法都使用一個超參數 alpha 進行參數化,該參數控制從中抽樣平滑機率的 Beta 分佈的形狀。我們進行了非常有限的網格搜尋,主要關注論文中提出的常用值。
您將在下方找到這兩種技術的 alpha 參數的最佳值
mixup_alpha=0.2,
cutmix_alpha=1.0,
應用 Mixup 將我們的準確度提高了 0.118 個百分點,並將其與 Cutmix 結合使用,可以額外提高 0.278 個百分點。
權重衰減 (Weight Decay) 調整
我們的標準配方使用 L2 正規化來減少過擬合。權重衰減參數控制正規化的程度(值越大強度越高),並且預設情況下會普遍應用於模型的所有學習參數。在此配方中,我們對標準方法應用了兩個最佳化。首先,我們執行網格搜尋以調整權重衰減的參數,其次,我們停用歸一化層 (Normalization layers) 參數的權重衰減。
您可以在下方找到我們配方的權重衰減的最佳配置
weight_decay=2e-05,
norm_weight_decay=0.0,
上述更新使我們的準確度進一步提高了 0.526 個百分點,為調整權重衰減對模型性能具有顯著影響這一已知事實提供了額外的實驗證據。我們將歸一化參數與其餘參數分離的方法受到了 ClassyVision 方法的啟發。
FixRes 緩解
在我們的實驗早期確定的一個重要特性是,如果在驗證期間使用的解析度從訓練的 224x224 增加,模型的性能會顯著提高。FixRes 論文 [5] 詳細研究了這種效應,並提出了兩種緩解措施:a) 可以嘗試降低訓練解析度,以便最大化驗證解析度的準確度,或者 b) 可以對模型進行雙階段訓練微調,以便在目標解析度上進行調整。由於我們不想引入雙階段訓練,因此我們選擇了選項 a)。這意味著我們將訓練裁剪大小從 224 減小,並使用網格搜尋來找到使 224x224 解析度的驗證最大化的裁剪大小。
您可以在下方看到我們配方中使用的最佳值
val_crop_size=224,
train_crop_size=176,
上述最佳化使我們的準確度額外提高了 0.160 個百分點,並將我們的訓練速度提高了 10%。
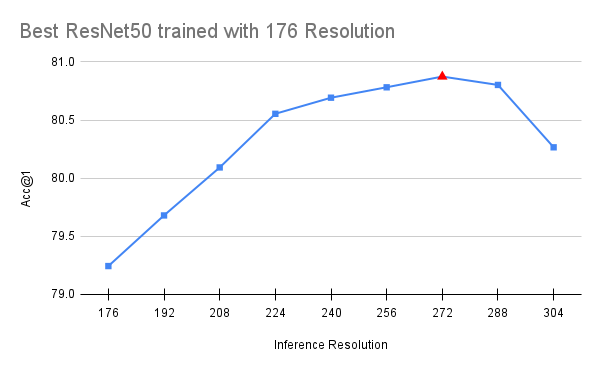
值得注意的是,FixRes 效應仍然存在,這意味著當我們提高解析度時,模型在驗證時的性能會繼續更好。此外,進一步減小訓練裁剪大小實際上會損害準確度。這在直覺上是有道理的,因為在關鍵細節開始從圖片中消失之前,人們只能降低這麼多的解析度。最後,我們應該注意,上述 FixRes 緩解措施似乎有益於深度與 ResNet50 相似的模型。具有更大感受野的更深層變體似乎受到輕微的負面影響(通常為 0.1-0.2 個百分點)。因此,我們認為這是配方中的可選部分。下方我們可視化使用 176 和 224 解析度訓練的模型的最佳可用檢查點(使用完整配方)的性能

指數移動平均 (EMA)
EMA 是一種技術,可以提高模型的準確度,而無需增加其複雜性或推論時間。它對模型權重執行指數移動平均,從而提高準確度和更穩定的模型。平均每隔幾個迭代發生一次,其衰減參數通過網格搜尋進行調整。
您可以在下方看到我們配方的最佳值
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
與上一步相比,使用 EMA 使我們的準確度提高了 0.254 個百分點。請注意,TorchVision 的 EMA 實現建立在 PyTorch 的 AveragedModel 類之上,主要的區別在於它不僅平均模型參數,還平均其緩衝區。此外,我們還採用了 Pycls 的技巧,這使我們能夠以不依賴 epoch 數的方式參數化衰減。
推論調整大小 (Inference Resize) 調整
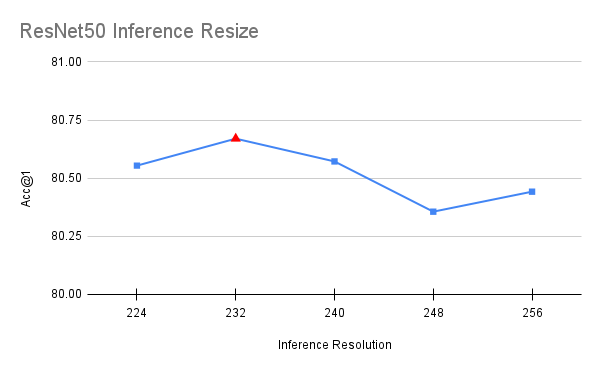
與該過程中涉及使用不同參數訓練模型的所有其他步驟不同,此最佳化是在最終模型之上完成的。在推論期間,影像會調整為特定解析度,然後從中提取一個中央 224x224 裁剪。原始配方使用 256 的調整大小,這導致了與 FixRes 論文 [5] 中描述的相似差異。通過將此調整大小值更接近目標推論解析度,可以提高準確度。為了選擇值,我們在間隔 [224, 256] 之間以步長 8 運行簡短的網格搜尋。為了避免過擬合,使用一半的驗證集選擇該值,並使用另一半進行確認。
您可以在下方看到我們配方中使用的最佳值
val_resize_size=232,
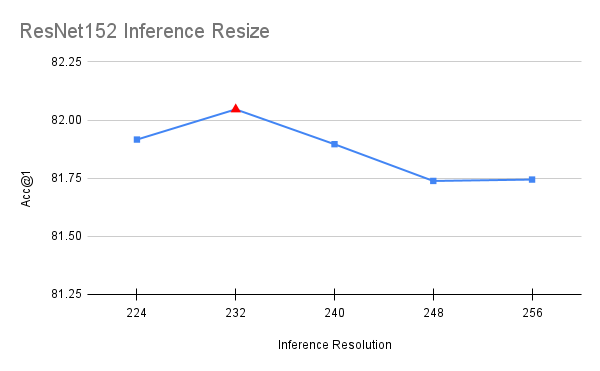
以上是一個使我們的準確度提高了 0.224 個百分點的最佳化。值得注意的是,ResNet50 的最佳值也最適合 ResNet101、ResNet152 和 ResNeXt50,這暗示它可以在模型之間推廣

[更新] 重複擴增 (Repeated Augmentation)
重複擴增 [15], [16] 是另一種可以提高整體準確度的技術,已被其他強大配方使用,例如 [6], [7]。社群貢獻者 Tal Ben-Nun 透過建議使用 4 次重複訓練模型,進一步改進了我們的原始配方。他的貢獻是在本文發布之後。
您可以在下方看到我們配方中使用的最佳值
ra_sampler=True,
ra_reps=4,
以上是最終的最佳化,使我們的準確度提高了 0.184 個百分點。
已測試但未採用的最佳化
在我們研究的早期階段,我們嘗試了其他技術、配置和最佳化。由於我們的目標是使我們的配方盡可能簡單,因此我們決定不包含任何沒有提供顯著改進的東西。以下是我們採取但未納入最終配方的一些方法
- 最佳化器 (Optimizers): 使用更複雜的最佳化器,例如 Adam、RMSProp 或帶有 Nesterov 動量的 SGD,並沒有提供比帶有動量的 vanilla SGD 顯著更好的結果。
- LR 排程器 (LR Schedulers): 我們嘗試了不同的 LR 排程器方案,例如 StepLR 和 Exponential。雖然後者往往與 EMA 配合使用效果更好,但它通常需要額外的超參數,例如定義最小 LR 才能良好工作。相反,我們只是使用餘弦退火將 LR 衰減到零,並選擇具有最高準確度的檢查點。
- 自動擴增 (Automatic Augmentations): 我們嘗試了不同的擴增策略,例如 AutoAugment 和 RandAugment。這些都沒有優於更簡單的無參數 TrivialAugment。
- 插值 (Interpolation): 使用雙立方或最近鄰插值並沒有提供比雙線性顯著更好的結果。
- 歸一化層 (Normalization layers): 使用 Sync Batch Norm 並沒有產生比使用常規 Batch Norm 顯著更好的結果。
致謝
我們要感謝 Piotr Dollar、Mannat Singh 和 Hugo Touvron 在配方開發過程中提供他們的見解和回饋,以及他們之前對我們配方所基於的研究工作。 他們的支持對於實現上述結果至關重要。 此外,我們要感謝 Prabhat Roy、Kai Zhang、Yiwen Song、Joel Schlosser、Ilqar Ramazanli、Francisco Massa、Mannat Singh、Xiaoliang Dai、Samuel Gabriel、Allen Goodman 和 Tal Ben-Nun 對 Batteries Included 專案的貢獻。
參考文獻
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. “Deep Residual Learning for Image Recognition”。
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li. “Bag of Tricks for Image Classification with Convolutional Neural Networks”
- Piotr Dollár, Mannat Singh, Ross Girshick. “Fast and Accurate Model Scaling”
- Tete Xiao, Mannat Singh, Eric Mintun, Trevor Darrell, Piotr Dollár, Ross Girshick. “Early Convolutions Help Transformers See Better”
- Hugo Touvron, Andrea Vedaldi, Matthijs Douze, Hervé Jégou. “Fixing the train-test resolution discrepancy
- Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. “Training data-efficient image transformers & distillation through attention”
- Ross Wightman, Hugo Touvron, Hervé Jégou. “ResNet strikes back: An improved training procedure in timm”
- Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, Vaishaal Shankar. “Do ImageNet Classifiers Generalize to ImageNet?”
- Samuel G. Müller, Frank Hutter. “TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation”
- Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, Yi Yang. “Random Erasing Data Augmentation”
- Terrance DeVries, Graham W. Taylor. “Improved Regularization of Convolutional Neural Networks with Cutout”
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, Zbigniew Wojna. “Rethinking the Inception Architecture for Computer Vision”
- Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz. “mixup: Beyond Empirical Risk Minimization”
- Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. “CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features”
- Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, Daniel Soudry. “Augment your batch: better training with larger batches”
- Maxim Berman, Hervé Jégou, Andrea Vedaldi, Iasonas Kokkinos, Matthijs Douze. “Multigrain: a unified image embedding for classes and instances”
