TorchRec 概念¶
在本節中,我們將了解 TorchRec 的關鍵概念,這些概念旨在優化使用 PyTorch 的大規模推薦系統。我們將詳細了解每個概念如何運作,並回顧它如何與 TorchRec 的其他部分一起使用。
TorchRec 具有其模組的特定輸入/輸出資料類型,以有效地表示稀疏特徵,包括
JaggedTensor: 圍繞單個稀疏特徵的長度/偏移和數值張量的包裝器。
KeyedJaggedTensor: 有效地表示多個稀疏特徵,可以將其視為多個
JaggedTensor。KeyedTensor: 圍繞
torch.Tensor的包裝器,允許透過鍵存取張量值。
為了實現高性能和效率,典型的 torch.Tensor 在表示稀疏資料時非常沒有效率。TorchRec 引入了這些新的資料類型,因為它們提供了稀疏輸入資料的有效儲存和表示。正如您稍後將看到的,KeyedJaggedTensor 使得在分散式環境中輸入資料的傳輸非常有效,從而帶來了 TorchRec 提供的一個關鍵性能優勢。
在端到端訓練迴圈中,TorchRec 包括以下主要元件
規劃器: 接收嵌入表、環境設置的配置,並為模型生成最佳化的分片計畫。
分片器: 根據分片計畫對模型進行分片,具有不同的分片策略,包括資料平行、表格式、列式、表格式-列式、欄式和表格式-欄式分片。
DistributedModelParallel: 組合分片器、最佳化器,並提供在分散式環境中訓練模型的入口點。
JaggedTensor¶
JaggedTensor 通過長度、數值和偏移來表示稀疏特徵。它被稱為「jagged」,因為它有效地表示了具有可變長度序列的資料。相比之下,典型的 torch.Tensor 假設每個序列都具有相同的長度,但在真實世界資料中通常不是這樣。JaggedTensor 有助於表示此類資料,而無需填充,從而使其非常有效。
主要元件
Lengths:一個整數列表,表示每個實體的元素數量。Offsets:一個整數列表,表示每個序列在扁平化數值張量中的起始索引。這些提供了長度的替代方案。Values:一個 1D 張量,包含每個實體的實際數值,連續儲存。
這是一個簡單的範例,展示了每個元件的外觀
# User interactions:
# - User 1 interacted with 2 items
# - User 2 interacted with 3 items
# - User 3 interacted with 1 item
lengths = [2, 3, 1]
offsets = [0, 2, 5] # Starting index of each user's interactions
values = torch.Tensor([101, 102, 201, 202, 203, 301]) # Item IDs interacted with
jt = JaggedTensor(lengths=lengths, values=values)
# OR
jt = JaggedTensor(offsets=offsets, values=values)
KeyedJaggedTensor¶
KeyedJaggedTensor 通過引入鍵(通常是特徵名稱)來標記不同的特徵組(例如,使用者特徵和項目特徵),擴展了 JaggedTensor 的功能。這是 EmbeddingBagCollection 和 EmbeddingCollection 的 forward 中使用的資料類型,因為它們用於表示表格中的多個特徵。
KeyedJaggedTensor 有一個隱含的批次大小,即特徵的數量除以 lengths 張量的長度。下面的範例的批次大小為 2。與 JaggedTensor 類似,offsets 和 lengths 的功能相同。您也可以透過從 KeyedJaggedTensor 存取 key 來存取特徵的 lengths、offsets 和 values。
keys = ["user_features", "item_features"]
# Lengths of interactions:
# - User features: 2 users, with 2 and 3 interactions respectively
# - Item features: 2 items, with 1 and 2 interactions respectively
lengths = [2, 3, 1, 2]
values = torch.Tensor([11, 12, 21, 22, 23, 101, 102, 201])
# Create a KeyedJaggedTensor
kjt = KeyedJaggedTensor(keys=keys, lengths=lengths, values=values)
# Access the features by key
print(kjt["user_features"])
# Outputs user features
print(kjt["item_features"])
規劃器¶
TorchRec 規劃器有助於確定模型的最佳分片配置。它評估了 embedding 表格分片的各種可能性,並針對效能進行最佳化。規劃器執行以下操作:
評估硬體的記憶體限制。
根據記憶體提取(例如 embedding 查找)估算運算需求。
處理特定於資料的因素。
考慮其他硬體細節,例如頻寬,以產生最佳分片計畫。
為了確保對這些因素的準確考量,規劃器可以整合有關 embedding 表格、約束、硬體資訊和拓撲的資料,以協助產生最佳計畫。
EmbeddingTable 的分片¶
TorchRec sharder 為各種用例提供多種分片策略,我們概述了一些分片策略及其工作方式,以及它們的優點和限制。通常,我們建議使用 TorchRec 規劃器為您產生分片計畫,因為它將找到模型中每個 embedding 表格的最佳分片策略。
每個分片策略都決定了如何分割表格,是否應該切割表格以及如何切割,是否保留某些表格的一個或幾個副本,等等。分片結果中的每個表格部分,無論是一個 embedding 表格還是它的一部分,都稱為一個 shard(分片)。
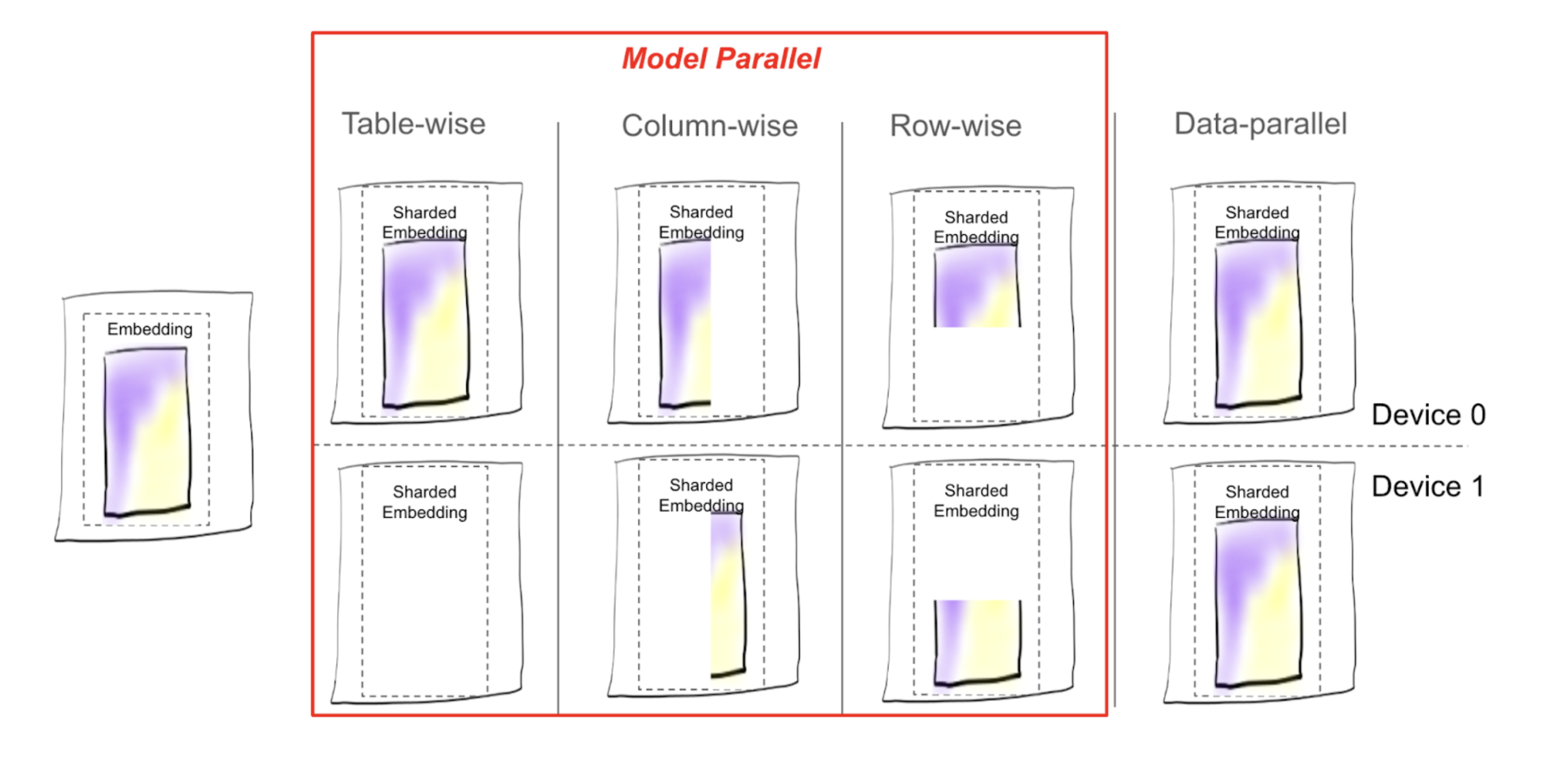
圖 1:視覺化 TorchRec 中提供的不同分片方案下表格分片的放置¶
以下是 TorchRec 中所有可用的分片類型清單:
Table-wise (TW):顧名思義,embedding 表格保持為一個整體,並放置在一個 rank 上。
Column-wise (CW):表格沿著
emb_dim維度分割,例如,emb_dim=256分割為 4 個 shards:[64, 64, 64, 64]。Row-wise (RW):表格沿著
hash_size維度分割,通常在所有 rank 之間平均分割。Table-wise-row-wise (TWRW):表格放置在一個主機上,在該主機上的 rank 之間以 row-wise 方式分割。
Grid-shard (GS):表格以 CW 方式分片,並且每個 CW 分片都以 TWRW 方式放置在一個主機上。
Data parallel (DP):每個 rank 保留表格的副本。
分片後,模組會轉換為它們自身的分片版本,在 TorchRec 中稱為 ShardedEmbeddingCollection 和 ShardedEmbeddingBagCollection。這些模組處理輸入資料的通訊、embedding 查找和梯度。
使用 TorchRec 分片模組進行分散式訓練¶
有了這麼多可用的分片策略,我們如何確定使用哪一種?每種分片方案都存在相關的成本,該成本與模型大小和 GPU 數量相結合,決定了哪種分片策略最適合模型。
在沒有分片的情況下,每個 GPU 都保留 embedding 表格的副本 (DP),主要的成本是計算,其中每個 GPU 在正向傳播中查找其記憶體中的 embedding 向量,並在反向傳播中更新梯度。
透過分片,會增加通訊成本:每個 GPU 需要向其他 GPU 請求 embedding 向量查找,並傳達計算出的梯度。這通常稱為 all2all 通訊。在 TorchRec 中,對於給定 GPU 上的輸入資料,我們確定每個資料部分的 embedding 分片位於何處,並將其傳送到目標 GPU。然後,目標 GPU 將 embedding 向量傳回原始 GPU。在反向傳播中,梯度會傳回目標 GPU,並且分片會相應地使用最佳化器進行更新。
如上所述,分片要求我們傳達輸入資料和 embedding 查找。TorchRec 在三個主要階段處理此問題,我們將其稱為分片 embedding 模組正向傳播,用於 TorchRec 模型的訓練和推論。
Feature All to All/Input distribution (
input_dist)將輸入資料(以
KeyedJaggedTensor的形式)傳達給包含相關 embedding 表格分片的適當裝置
Embedding 查找
使用在 feature all to all 交換後形成的新輸入資料查找 embeddings
Embedding All to All/Output Distribution (
output_dist)將 embedding 查找資料傳達回請求它的適當裝置(依照裝置收到的輸入資料)
反向傳播執行相同的操作,但順序相反。
下圖示範了其工作原理
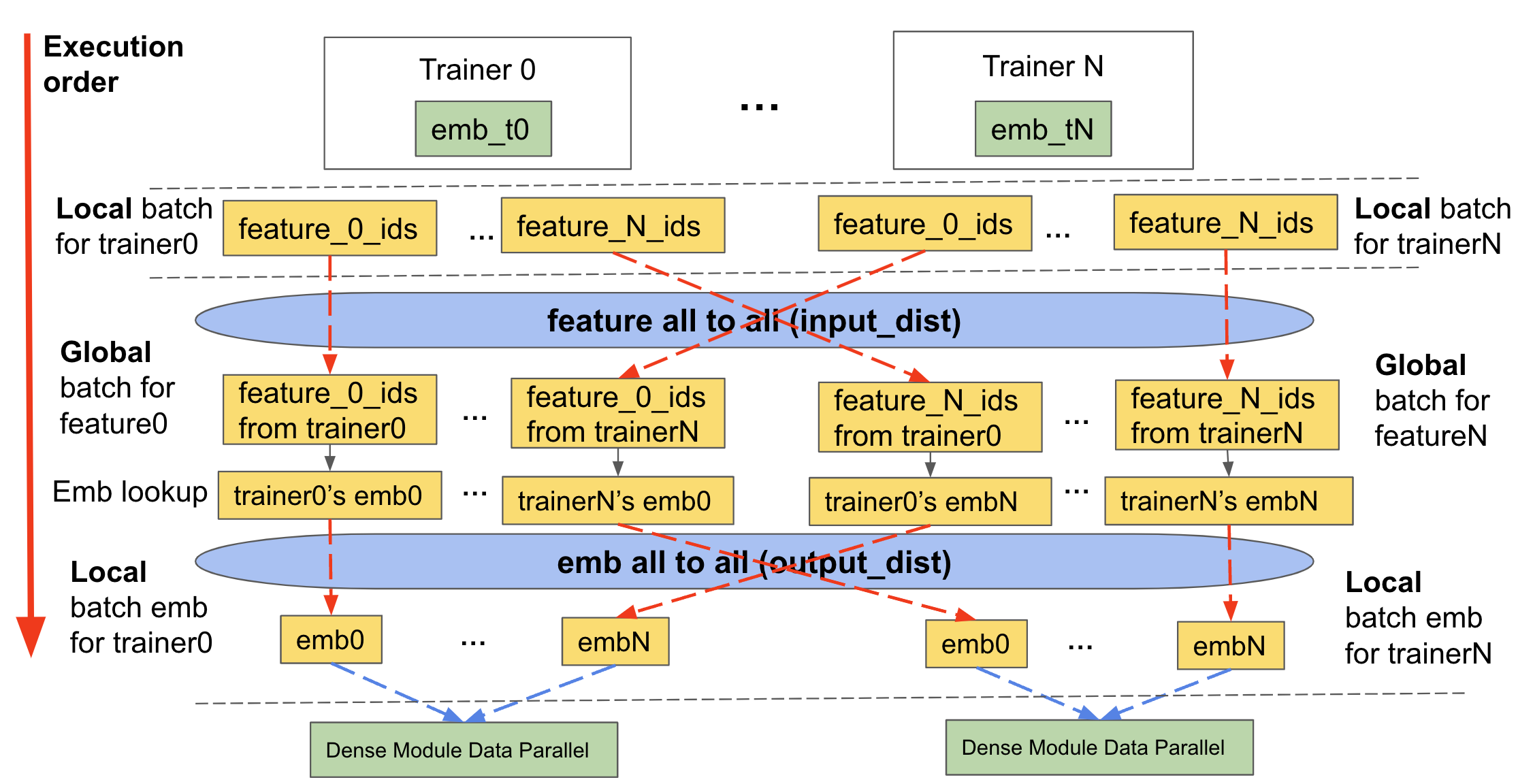
圖 2:table wise 分片表格的正向傳播,包括分片 TorchRec 模組的 input_dist、查找和 output_dist¶
DistributedModelParallel¶
以上所有內容最終匯集成 TorchRec 用於分片和整合計畫的主要入口點。在高層次上,DistributedModelParallel 執行以下操作:
透過設定處理程序群組和指定裝置類型來初始化環境。
如果未提供 sharder,則使用預設 sharder,預設包含
EmbeddingBagCollectionSharder。接收提供的分片計畫,如果未提供,則產生一個。
建立模組的分片版本並替換原始模組,例如,將
EmbeddingCollection轉換為ShardedEmbeddingCollection。預設情況下,使用
DistributedDataParallel包裝DistributedModelParallel,以使模組同時具有模型平行和資料平行功能。
Optimizer¶
TorchRec 模組提供無縫 API 來融合訓練中的反向傳播和最佳化器步驟,從而顯著最佳化效能並減少使用的記憶體,同時提供將不同最佳化器分配給不同模型參數的細微性。
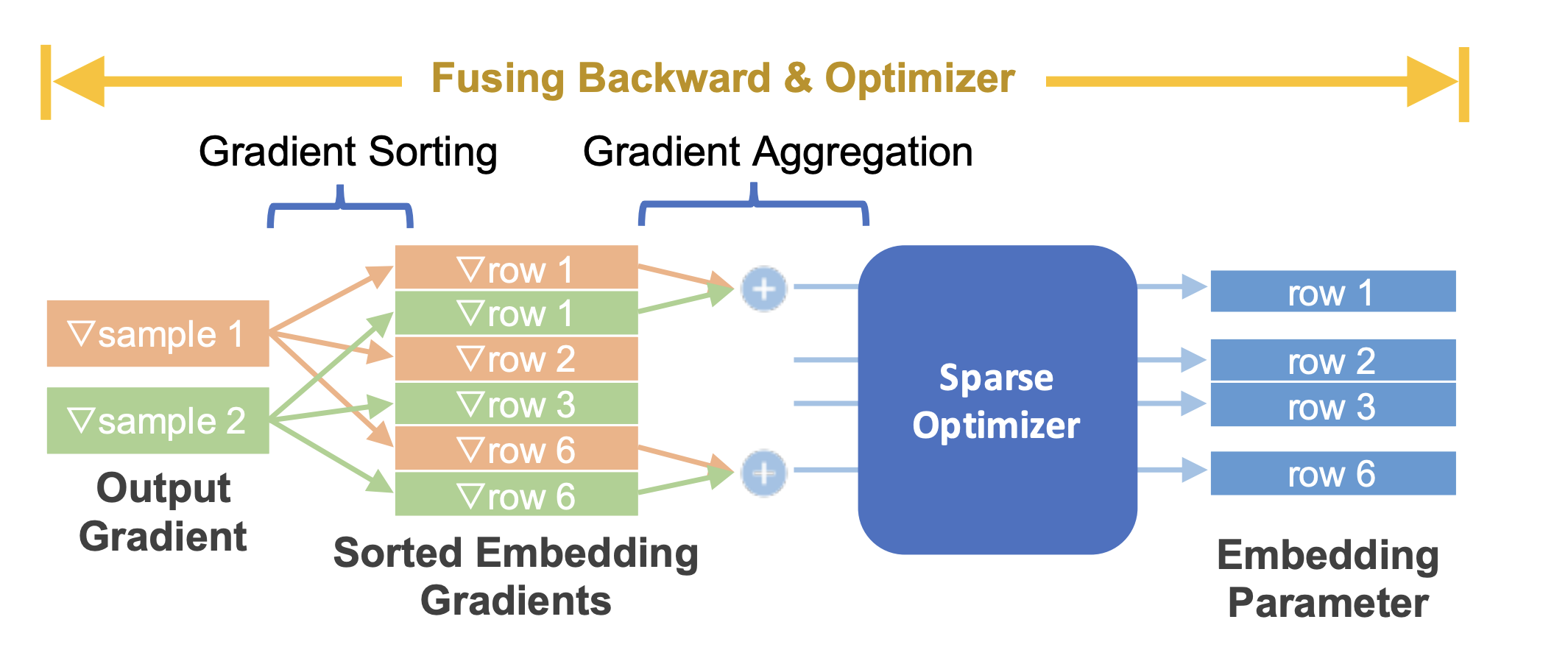
圖 3:融合 embedding 反向傳播與稀疏優化器¶
推論 (Inference)¶
推論環境與訓練環境不同,它們對效能和模型大小非常敏感。TorchRec 推論針對以下兩個主要差異進行了優化:
量化 (Quantization): 推論模型經過量化,以降低延遲並縮小模型大小。此優化讓我們可以使用盡可能少的設備進行推論,以最大限度地減少延遲。
C++ 環境: 為了進一步降低延遲,模型在 C++ 環境中執行。
TorchRec 提供了以下功能,將 TorchRec 模型轉換為可進行推論的狀態:
用於量化模型的 API,包括使用 FBGEMM TBE 自動進行的優化
用於分散式推論的 Embedding 分片
將模型編譯為 TorchScript(與 C++ 相容)
