TorchRec 高階架構¶
在本節中,您將了解 TorchRec 的高階架構,該架構旨在利用 PyTorch 優化大規模推薦系統。您將學習 TorchRec 如何使用模型平行化在多個 GPU 之間分配複雜模型,從而增強記憶體管理和 GPU 使用率,並了解 TorchRec 的基本組件和分片策略。
實際上,TorchRec 提供了平行化原始元件,允許混合資料平行化/模型平行化、嵌入表分片、用於產生分片計畫的規劃器、管線化訓練等等。
TorchRec 的平行化策略:模型平行化¶
隨著現代深度學習模型規模的擴大,分散式深度學習已成為成功及時訓練模型所必需的。在這個範例中,已經開發了兩種主要方法:資料平行化和模型平行化。 TorchRec 專注於後者,用於嵌入表的分片。
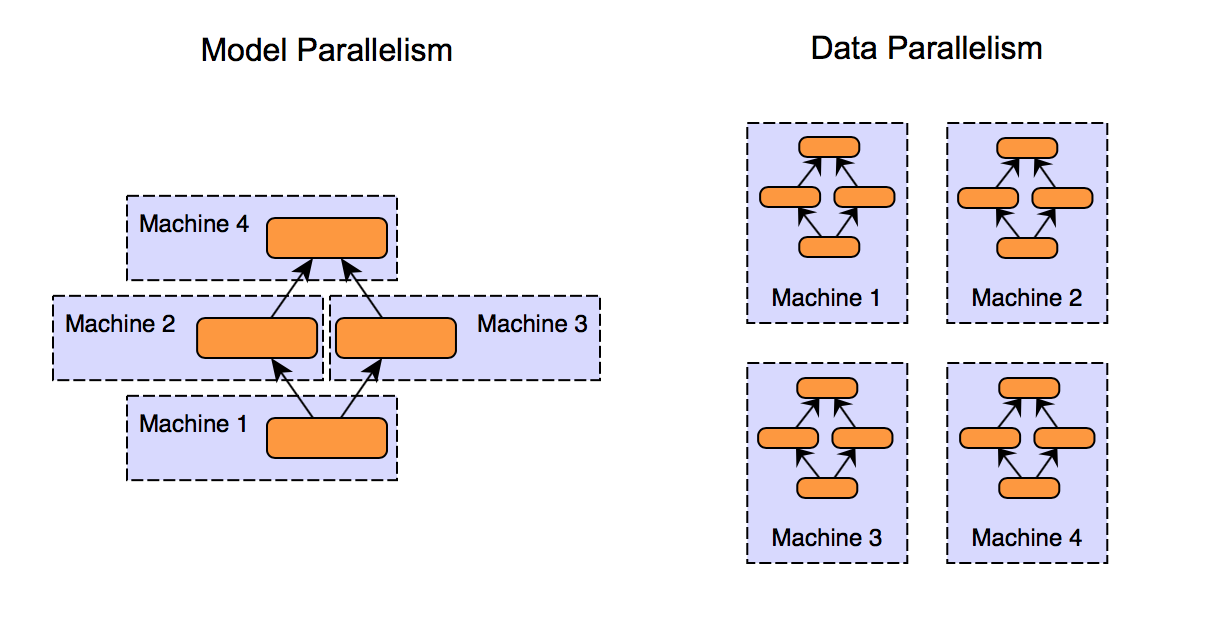
圖 1. 模型平行化和資料平行化方法的比較¶
如上圖所示,模型平行化和資料平行化是兩種在多個 GPU 之間分配工作負載的方法,
模型平行化
將模型分成幾個部分並將它們分配到各個 GPU 上
每個部分獨立處理資料
適用於無法在單個 GPU 上容納的大型模型
資料平行化
在每個 GPU 上分配整個模型的副本
每個 GPU 處理資料的子集並貢獻於整體計算
對於可以在單個 GPU 上容納但需要處理大型資料集的模型有效
模型平行化的優點
優化大型模型的記憶體使用和計算效率
特別適用於具有大型嵌入表的推薦系統
在 DLRM 類型架構中實現嵌入的平行計算
嵌入表¶
為了讓 TorchRec 了解要推薦什麼,我們需要能夠表示實體及其關係,這就是嵌入的用途。嵌入是高維空間中實數的向量,用於表示文字、影像或使用者等複雜資料中的含義。嵌入表是將多個嵌入聚合到一個矩陣中。最常見的是,嵌入表表示為具有維度 (B, N) 的 2D 矩陣。
B 是表儲存的嵌入數量
N 是每個嵌入的維度數量。
B 中的每一個也可以稱為 ID(表示電影標題、使用者、廣告等資訊),當存取 ID 時,我們會傳回相應的嵌入向量,其大小為嵌入維度 N。
還有另一種選擇是池化嵌入 (pooling embeddings)。通常,我們會為給定的特徵查詢多個列,這引發了一個問題:我們該如何處理查詢到的多個嵌入向量?池化是一種常見的技術,透過組合嵌入向量來產生一個嵌入向量,通常是將這些列加總或取平均值。這是 PyTorch 的 nn.Embedding 和 nn.EmbeddingBag 之間的主要區別。
PyTorch 透過 nn.Embedding 和 nn.EmbeddingBag 來表示嵌入。在這些模組的基礎上,TorchRec 引入了 EmbeddingCollection 和 EmbeddingBagCollection,它們是相應 PyTorch 模組的集合。這種擴展使 TorchRec 能夠批次處理表格,並在單一核心呼叫中對多個嵌入執行查找,從而提高效率。
以下是端到端流程圖,描述了嵌入如何在推薦模型的訓練過程中被使用
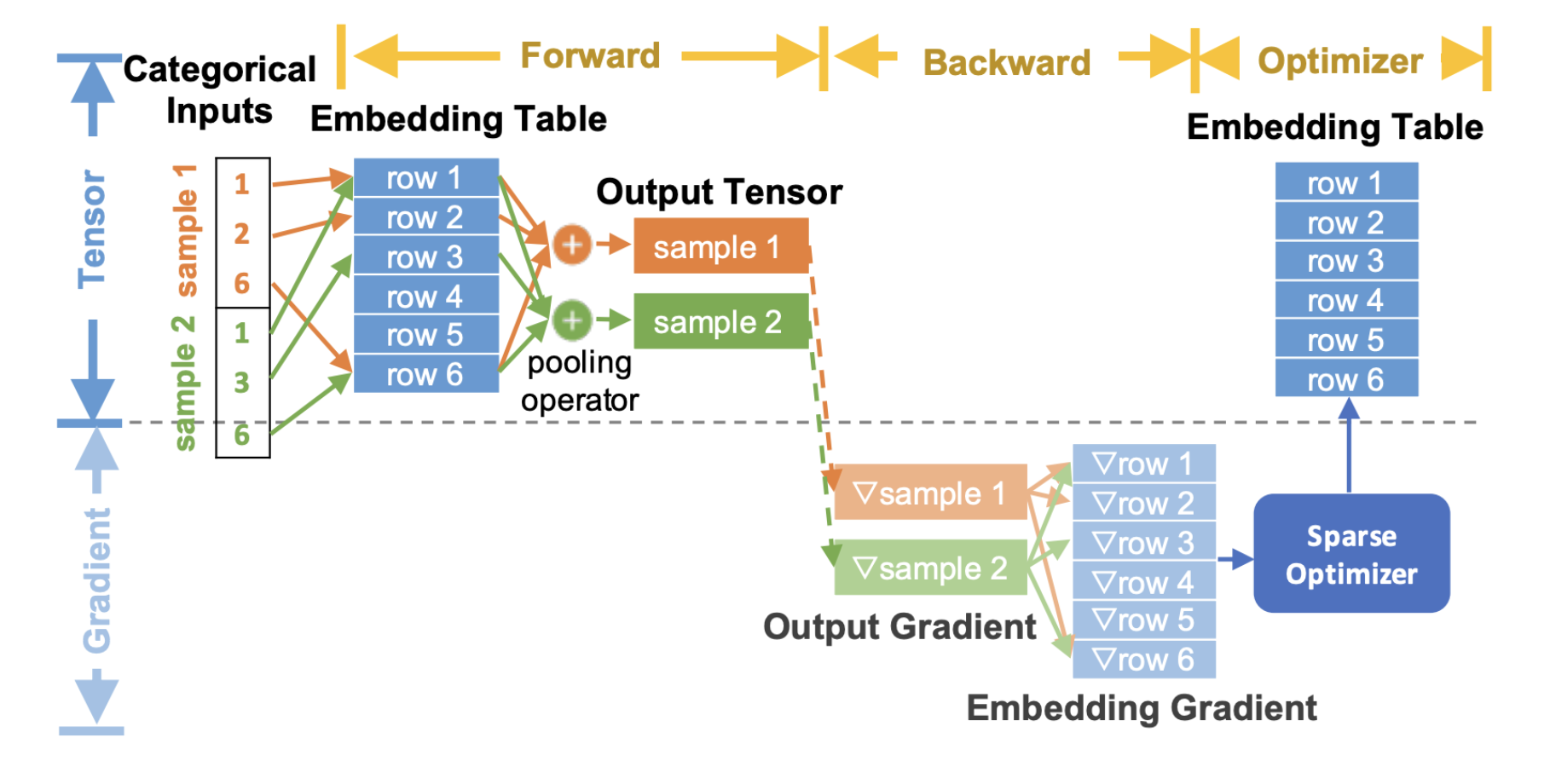
圖 2. TorchRec 端到端嵌入流程¶
在上圖中,我們展示了通用的 TorchRec 端到端嵌入查找過程。
在正向傳播 (forward pass) 中,我們執行嵌入查找和池化。
在反向傳播 (backward pass) 中,我們計算輸出查找的梯度,並將它們傳遞到優化器以更新嵌入表。
請注意,此處的嵌入梯度顯示為灰色,因為我們並未將它們完全具體化到記憶體中,而是將它們與優化器更新融合在一起。 這樣可以顯著減少記憶體使用量,我們將在後面的優化器概念部分詳細介紹。
我們建議您閱讀 TorchRec 概念頁面,以了解所有內容如何端到端地聯繫在一起的基本原理。 它包含許多有用的資訊,可讓您充分利用 TorchRec。
