基本概念¶
這描述了 TorchX 背後的高階概念和專案結構。有關如何建立和執行應用程式的資訊,請參閱 快速入門指南。
專案結構¶
TorchX 中的頂層模組是
torchx.specs:應用程式規格(作業定義)APItorchx.components:預定義的(內建)應用程式規格torchx.workspace:處理修補映像以進行遠端執行torchx.cli:CLI 工具torchx.runner:給定一個應用程式規格,將應用程式作為作業提交到排程器上torchx.schedulers:執行程式支援的後端作業排程器torchx.pipelines:將給定的應用程式規格轉換為機器學習工作流程平台中的「階段」的轉接器torchx.runtime:您可以在撰寫應用程式(而不是應用程式規格)時使用的工具和抽象程式庫
以下是 UML 圖
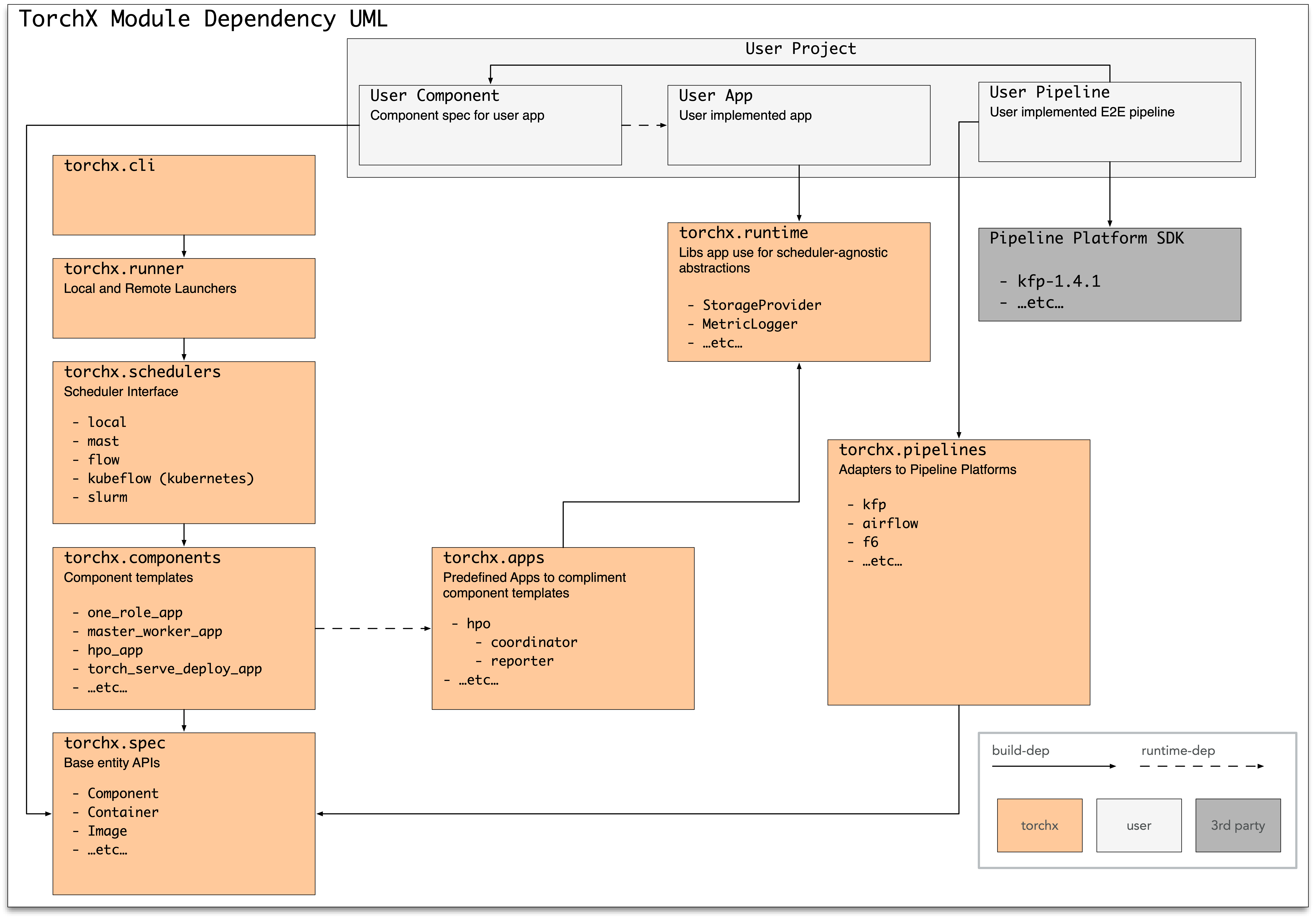
概念¶
AppDefs¶
在 TorchX 中,AppDef 只是具體應用程式之*定義*的結構。在排程器術語中,這是一個 JobDefinition,Kubernetes 中的類似概念是 spec.yaml。為了區別應用程式二進制檔(邏輯)和規格,我們通常將 TorchX AppDef 稱為「應用程式規格」或 specs.AppDef。這是 torchx.runner 和 torchx.pipelines 所理解的通用介面,允許您將應用程式作為獨立作業或作為機器學習工作流程中的一個階段執行。
以下是 specs.AppDef 的簡單範例,它會回應「hello world」
import torchx.specs as specs
specs.AppDef(
name="echo",
roles=[
specs.Role(
name="echo",
entrypoint="/bin/echo",
image="/tmp",
args=["hello world"],
num_replicas=1
)
]
)
如您所見,specs.AppDef 是一個純 Python 資料類別,僅編碼主二進制檔的名稱(入口點)、傳遞給它的參數以及一些其他執行時參數,例如 num_replicas 和有關執行容器的資訊(entrypoint=/bin/echo)。
應用程式規格非常靈活,可以編碼各種應用程式拓撲的規格。例如,num_replicas > 1 表示應用程式是分散式的。指定多個 specs.Roles 可以表示非同質分散式應用程式,例如需要單個「協調器」和多個「工作者」的應用程式。
請參閱 torchx.specs API 文件 以瞭解更多資訊。
使應用程式規格靈活的因素也使其具有許多欄位。好消息是,在大多數情況下,您不必從頭開始建構應用程式規格。相反,您將使用稱為 components 的範本化應用程式規格。
元件¶
TorchX 中的元件只是一個範本化的 spec.AppDef。您可以將它們視為 spec.AppDef 的便捷「工廠方法」。
注意
與應用程式不同,元件並未映射到實際的 Python 資料類別。而是將返回 spec.AppDef 的工廠函數稱為元件。
應用程式規格範本化的粒度各不相同。某些元件(例如上面的 echo 範例)是*立即可執行的*,這意味著它們具有硬編碼的應用程式二進制檔。其他元件(例如 ddp(分散式資料平行))規格僅指定應用程式的拓撲。以下是 ddp 樣式訓練器應用程式規格的一種可能的範本化,它指定了一個同質節點拓撲
import torchx.specs as specs
def ddp(jobname: str, nnodes: int, image: str, entrypoint: str, *script_args: str):
single_gpu = specs.Resources(cpu=4, gpu=1, memMB=1024)
return specs.AppDef(
name=jobname,
roles=[
specs.Role(
name="trainer",
entrypoint=entrypoint,
image=image,
resource=single_gpu,
args=script_args,
num_replicas=nnodes
)
]
)
如您所見,參數化的級別完全取決於元件作者。建立元件的工作量不超過編寫 Python 函數。不要嘗試透過對所有內容進行參數化來過度概括元件。元件的建立既簡單又便宜,您可以根據重複使用案例建立任意數量的元件。
**專業提示 1:**由於元件是 Python 函數,因此元件組合可以透過 Python 函數組合而不是物件組合來實現。但是,**出於可維護性考慮,我們不建議使用元件組合**。
**專業提示 2:**要定義元件之間的依賴關係,請使用工作流程 DSL。請參閱下面的 工作流程轉接器 章節,以瞭解 TorchX 元件如何在工作流程的上下文中使用。
在撰寫自己的元件之前,請瀏覽 TorchX 附帶的 元件 程式庫,看看是否有適合您需求的元件。
執行程式和排程器¶
執行程式 的功能正如您所預期的那樣 - 給定一個應用程式規格,它會透過作業排程器將應用程式作為作業啟動到叢集中。
在 TorchX 中有兩種方法可以訪問執行程式
CLI:
torchx run ~/app_spec.py以程式設計方式:
torchx.runner.get_runner().run(appspec)
請參閱 排程器 以取得執行程式可以將應用程式啟動到的排程器清單。
工作流程轉接器¶
雖然 runner 以獨立作業的方式啟動組件,但 torchx.pipelines 允許將組件插入機器學習流程/工作流程中。對於特定的目標流程平台(例如 kubeflow pipelines),TorchX 定義了一個轉接器,可以將 TorchX 應用程式規格轉換為目標平台中的「階段」表示形式。例如,用於 kubeflow pipelines 的 torchx.pipelines.kfp 轉接器會將應用程式規格轉換為 kfp.ContainerOp(或更準確地說是 kfp「組件規格」yaml)。
在大多數情況下,應用程式規格會映射到流程中的「階段」(或節點)。然而,進階組件,特別是那些本身具有微型控制流程的組件(例如 HPO),可能會映射到「子流程」或「內嵌流程」。這些進階組件如何映射到流程的確切語義取決於目標流程平台。例如,如果流程 DSL 允許從上游階段動態地將階段添加到流程中,則 TorchX 可以利用此類功能將子流程「內嵌」到主流程中。TorchX 通常會盡力將應用程式規格調整為目標流程平台中最「規範」的表示形式。
如需支援的流程平台列表,請參閱 流程。
執行階段¶
重要
torchx.runtime 絕不是使用 TorchX 的必要條件。如果您的基礎架構是固定的,並且不需要您的應用程式在不同類型的排程器和流程中可攜帶,則可以跳過此部分。
您的應用程式(不是應用程式規格,而是實際的應用程式二進制檔案)對 TorchX 具有「零」依賴性(例如,/bin/echo 不使用 TorchX,但可以為其建立 echo_torchx.py 組件)。
注意
torchx.runtime 是您在撰寫應用程式二進制檔案時「應該」使用的「唯一」模組!
但是,因為 TorchX 本質上允許您的應用程式在「任何地方」運行,所以建議您以與排程器/基礎架構無關的方式編寫應用程式。
這通常意味著在與排程器/基礎架構的接觸點添加一個 API 層。例如,以下應用程式「不是」與基礎架構無關的
import boto3
def main(input_path: str):
s3 = boto3.session.Session().client("s3")
path = s3_input_path.split("/")
bucket = path[0]
key = "/".join(path[1:])
s3.download_file(bucket, key, "/tmp/input")
input = torch.load("/tmp/input")
# ...<rest of code omitted for brevity>...
上面的二進制檔案隱含地假設 input_path 是一個 AWS S3 路徑。使此訓練器與儲存無關的一種方法是引入 FileSystem 抽象層。對於檔案系統,像 PyTorch Lightning 這樣的框架已經定義了 io 層(lightning 在底層使用 fsspec)。上面的二進制檔案可以改寫為與儲存無關的 lightning。
import pytorch_lightning.utilities.io as io
def main(input_url: str):
fs = io.get_filesystem(input_url)
with fs.open(input_url, "rb") as f:
input = torch.load(f)
# ...<rest of code omitted for brevity>...
現在可以將 main 稱為 main("s3://foo/bar") 或 main("file://foo/bar"),使其與儲存在各種儲存中的輸入相容。
對於 FileSystem,現有的函式庫定義了檔案系統抽象。在 torchx.runtime 中,您會發現為撰寫與基礎架構無關的應用程式可能需要的各種功能提供抽象的函式庫或指向其他函式庫的指標。理想情況下,torchx.runtime 中的功能會及時向上游傳播到 lightning 等用於撰寫應用程式的函式庫中。但是,為這些抽象找到一個合適的永久存放地可能需要時間,甚至需要建立一個全新的開源軟體專案。在這種情況發生之前,這些功能可以通過 torchx.runtime 模組成熟並供使用者使用。
後續步驟¶
查看 快速入門指南 以瞭解如何建立和執行組件。
