torchx.schedulers¶
TorchX 排程器定義了現有排程器的插件。與 執行器 一起使用時,它們會將元件作為作業提交到各自的排程器後端。TorchX 開箱支援一些 排程器。您可以透過實作 .. py:class::torchx.schedulers 並在入口點 註冊 它來新增您自己的排程器。
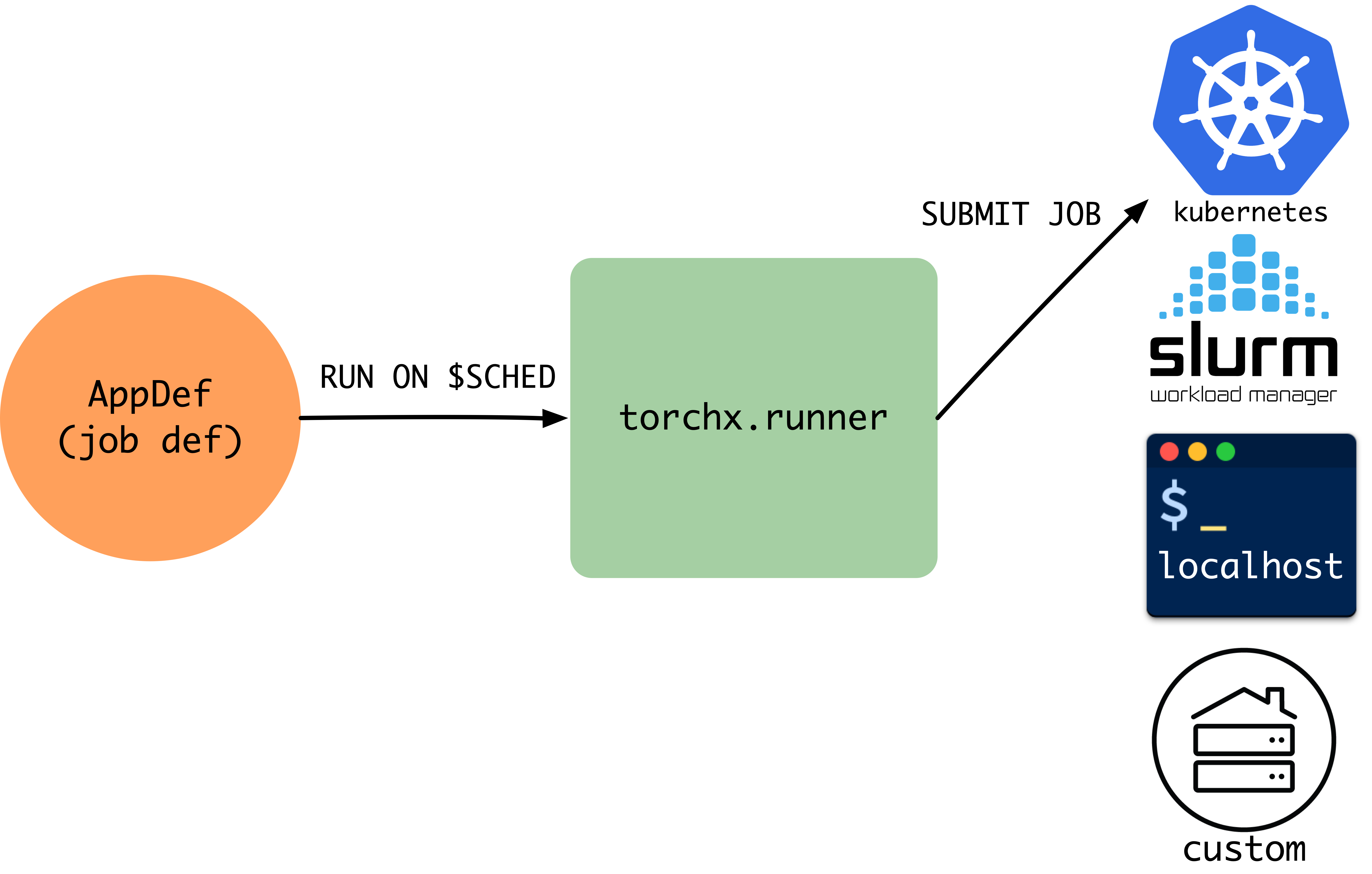
所有排程器¶
排程器函數¶
- torchx.schedulers.get_scheduler_factories() Dict[str, SchedulerFactory][來源]¶
get_scheduler_factories 會傳回所有可用的排程器名稱以及實例化它們的方法。
字典中的第一個排程器會被用作預設排程器。
排程器類別¶
- class torchx.schedulers.Scheduler(backend: str, session_name: str)[來源]¶
抽象化排程器功能的介面。實作者只需要實作那些以
@abc.abstractmethod註釋的方法。- cancel(app_id: str) None[來源]¶
取消/終止應用程式。此方法在同一個執行緒中是冪等的,並且可以在同一個應用程式上安全地呼叫多次。然而,當從同一個應用程式的多個執行緒/程序呼叫時,此方法的確切語義取決於底層排程器 API 的冪等性保證。
備註
此方法不會阻塞應用程式達到已取消狀態。若要確保應用程式達到終止狀態,請使用
waitAPI。
- close() None[來源]¶
僅適用於具有本地狀態的排程器!關閉排程器,釋放任何已配置的資源。關閉後,排程器物件將被視為不再有效,並且對該物件呼叫的任何方法都會導致未定義的行為。
此方法不應引發例外,並且允許在同一個物件上呼叫多次。
備註
僅針對具有本地狀態的排程器實作覆寫此方法 (
torchx/schedulers/local_scheduler.py)。只需包裝遠端排程器用戶端的排程器不需要實作此方法。
- abstract describe(app_id: str) Optional[DescribeAppResponse][來源]¶
描述指定的應用程式。
- 傳回值:
AppDef 描述,如果應用程式不存在,則為
None。
- abstract list() List[ListAppResponse][原始碼]¶
對於在排程器上啟動的應用程式,這個 API 會傳回 ListAppResponse 物件清單,每個物件都包含應用程式 ID 及其狀態。注意:這個 API 處於原型階段,可能會有所變更。
- log_iter(app_id: str, role_name: str, k: int = 0, regex: Optional[str] = None, since: Optional[datetime] = None, until: Optional[datetime] = None, should_tail: bool = False, streams: Optional[Stream] = None) Iterable[str][原始碼]¶
傳回一個迭代器,指向
k``th 副本 的 ``role的日誌行。當所有符合條件的日誌行都被讀取後,迭代器就會結束。如果排程器支援基於時間的遊標來擷取自訂時間範圍的日誌行,則會採用
since、until欄位,否則會忽略這些欄位。未指定since和until等同於取得所有可用的日誌行。如果until為空,則迭代器的行為類似於tail -f,會持續追蹤日誌輸出,直到作業達到終止狀態。日誌的確切定義因排程器而異。某些排程器可能會將 stderr 或 stdout 視為日誌,而其他排程器可能會從日誌檔案中讀取日誌。
行為和假設
如果對不存在的應用程式呼叫,會產生未定義行為。呼叫者應在呼叫此方法之前,使用
exists(app_id)檢查應用程式是否存在。不是狀態性的,使用相同的參數呼叫此方法兩次會傳回一個新的迭代器。先前的迭代進度會遺失。
不保證支援日誌追蹤。並非所有排程器都支援即時日誌迭代(例如,在應用程式執行時追蹤日誌)。有關迭代器行為的詳細資訊,請參閱特定排程器的說明文件。
- 3.1 如果排程器支援日誌追蹤,則應該由
should_tail參數控制。
不保證日誌保留。呼叫此方法時,底層排程器可能已清除此應用程式的日誌記錄。如果是這樣,此方法會引發任意例外狀況。
如果
should_tail為 True,則只有在可存取的日誌行已完全耗盡且應用程式已達到最終狀態時,該方法才會引發StopIteration例外狀況。例如,如果應用程式卡住且未產生任何日誌行,則迭代器會封鎖,直到應用程式最終被終止(透過逾時或手動),此時會引發StopIteration。如果
should_tail為 False,則當沒有更多日誌時,該方法會引發StopIteration。並非所有排程器都必須支援。
某些排程器可能透過支援
__getitem__來支援行遊標(例如,iter[50]會搜尋到第 50 行日誌)。- 空格會被保留,每個新行都應該包含
\n。為了 支援互動式進度條,傳回的行不需要包含
\n,但應該在沒有換行的情況下列印,以便正確處理\r歸位字元。
- 空格會被保留,每個新行都應該包含
- 參數:
streams – 要選擇的 IO 輸出串流。選項之一:combined、stdout、stderr。如果排程器不支援所選的串流,則會引發 ValueError。
- 傳回值:
指定角色副本的日誌行的
Iterator- 引發:
NotImplementedError – 如果排程器不支援日誌迭代
- abstract schedule(dryrun_info: AppDryRunInfo) str[原始碼]¶
與
submit相同,但它採用AppDryRunInfo。建議實作者實作此方法,而不是直接實作submit,因為submit可以透過dryrun_info = self.submit_dryrun(app, cfg) return schedule(dryrun_info)
- class torchx.schedulers.api.DescribeAppResponse(app_id: str = '<NOT_SET>', state: ~torchx.specs.api.AppState = AppState.UNSUBMITTED, num_restarts: int = -1, msg: str = '<NONE>', structured_error_msg: str = '<NONE>', ui_url: ~typing.Optional[str] = None, roles_statuses: ~typing.List[~torchx.specs.api.RoleStatus] = <factory>, roles: ~typing.List[~torchx.specs.api.Role] = <factory>)[source]¶
由
Scheduler.describe(app)API 返回的回應物件。包含排程器已知的應用程式狀態和描述。對於某些排程器實作,此回應物件具有重新建立AppDef物件的必要和充分資訊。對於這些類型的排程器,使用者可以重新執行重新建立的應用程式。否則,使用者只能呼叫非建立方法(例如wait()、status()等)。由於此類別是一個資料類別,並且包含許多成員變數,我們將其用法保持簡單,並提供一個無參數的建構函式,並選擇直接存取成員變數,而不是提供存取器。
如果排程器返回任意訊息,則應填入
msg欄位。如果排程器返回結構化的 JSON,則應填入structured_error_msg欄位。
- class torchx.schedulers.api.ListAppResponse(app_id: str, state: AppState, app_handle: str = '<NOT_SET>')[source]¶
由
scheduler.list()和runner.list()API 返回的回應物件。包含應用程式的 app_id、app_handle 和狀態。應用程式 ID:識別在排程器上提交的應用程式的唯一識別碼。應用程式控點:使用 torchx 執行的應用程式的識別碼,採用類似 {scheduler_backend}://{session_name}/{app_id} 的 URL 格式,由執行程式在排程器上提交作業時建立。ListAppResponse 中的控點資訊由runner.list()填入。此控點可用於使用 torchx CLI 或 torchx 執行程式執行個體進一步描述應用程式。由於此類別是一個具有某些成員變數的資料類別,我們將其用法保持簡單,並選擇直接存取成員變數,而不是提供存取器。
