Pytorch/XLA 概觀¶
本節簡要概述 PyTorch XLA 的基本細節,應有助於讀者更了解程式碼的必要修改和最佳化。
與常規 PyTorch 不同,後者逐行執行程式碼,並且在擷取 PyTorch 張量的值之前不會封鎖執行,PyTorch XLA 的運作方式不同。它會迭代 Python 程式碼,並將 (PyTorch) XLA 張量的運算記錄在中間表示 (IR) 圖表中,直到遇到屏障 (如下所述) 為止。產生 IR 圖表的此過程稱為追蹤 (LazyTensor 追蹤或程式碼追蹤)。然後,PyTorch XLA 將 IR 圖表轉換為稱為 HLO (高階運算碼) 的較低階機器可讀格式。HLO 是特定於 XLA 編譯器的運算表示法,使其能夠為其執行的硬體產生高效的程式碼。HLO 被饋送到 XLA 編譯器以進行編譯和最佳化。然後,PyTorch XLA 會快取編譯結果,以便日後在需要時重複使用。圖表的編譯是在主機 (CPU) 上完成的,主機是執行 Python 程式碼的機器。如果有多個 XLA 裝置,則主機會為每個裝置分別編譯程式碼,除非使用 SPMD (單一程式多重資料)。例如,v4-8 有一個主機和 四個裝置。在這種情況下,主機會為四個裝置中的每一個分別編譯程式碼。在 Pod 切片的情況下,當有多個主機時,每個主機會為其連接的 XLA 裝置執行編譯。如果使用 SPMD,則對於所有裝置,每個主機上的程式碼僅編譯一次 (對於給定的形狀和運算)。

如需更多詳細資訊和範例,請參閱 LazyTensor 指南。
IR 圖表中的運算僅在需要張量值時才會執行。這稱為張量的評估或實體化。有時也稱為延遲評估,它可以顯著提升效能。
Pytorch XLA 中的同步運算,例如列印、記錄、檢查點或回呼會封鎖追蹤,並導致執行速度變慢。在運算需要 XLA 張量的特定值時,例如 print(xla_tensor_z),追蹤會被封鎖,直到主機可以使用該張量的值為止。請注意,僅執行負責計算該張量值的部分圖表。這些運算不會切割 IR 圖表,但它們會透過 TransferFromDevice 觸發主機裝置通訊,這會導致效能降低。
屏障是一個特殊的指令,它告訴 XLA 執行 IR 圖表並實體化張量。這表示 PyTorch XLA 張量將被評估,並且結果將可供主機使用。Pytorch XLA 中使用者公開的屏障是 xm.mark_step(),它會中斷 IR 圖表,並導致程式碼在 XLA 裝置上執行。xm.mark_step 的關鍵屬性之一是,與同步運算不同,它不會在裝置執行圖表時封鎖進一步的追蹤。但是,它確實會封鎖對正在實體化的張量值的存取。
LazyTensor 指南中的範例說明了在新增兩個張量的簡單情況下會發生什麼情況。現在,假設我們有一個 for 迴圈,它新增 XLA 張量並稍後使用該值
for x, y in tensors_on_device:
z += x + y
在沒有屏障的情況下,Python 追蹤將產生一個單一圖表,該圖表包裝張量的加法 len(tensors_on_device) 次。這是因為 for 迴圈未被追蹤捕獲,因此迴圈的每次迭代都將建立一個新的子圖,對應於 z += x+y 的運算,並將其新增到圖表中。以下是當 len(tensors_on_device)=3 時的範例。
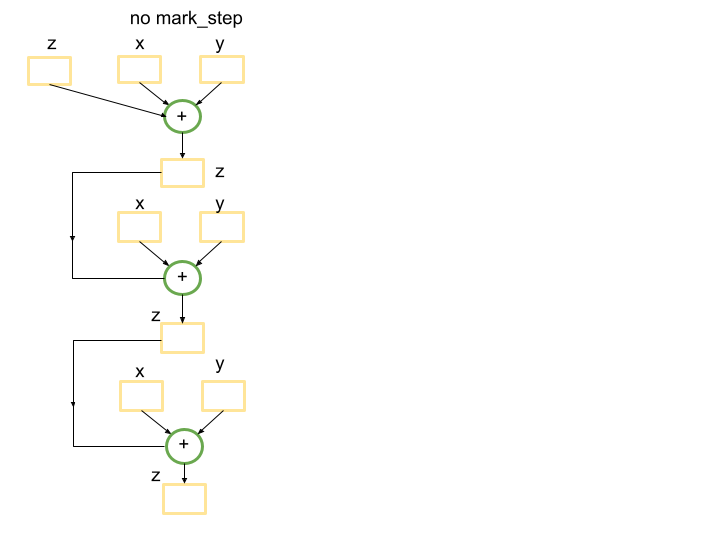
但是,在迴圈末尾引入屏障將產生一個較小的圖表,該圖表將在 for 迴圈內的第一個傳遞期間編譯一次,並將在接下來的 len(tensors_on_device)-1 次迭代中重複使用。屏障將向追蹤發出訊號,表示到目前為止追蹤的圖表可以提交以執行,並且如果之前已看到該圖表,則將重複使用快取的已編譯程式。
for x, y in tensors_on_device:
z += x + y
xm.mark_step()
在這種情況下,將有一個小圖表被使用 len(tensors_on_device)=3 次。
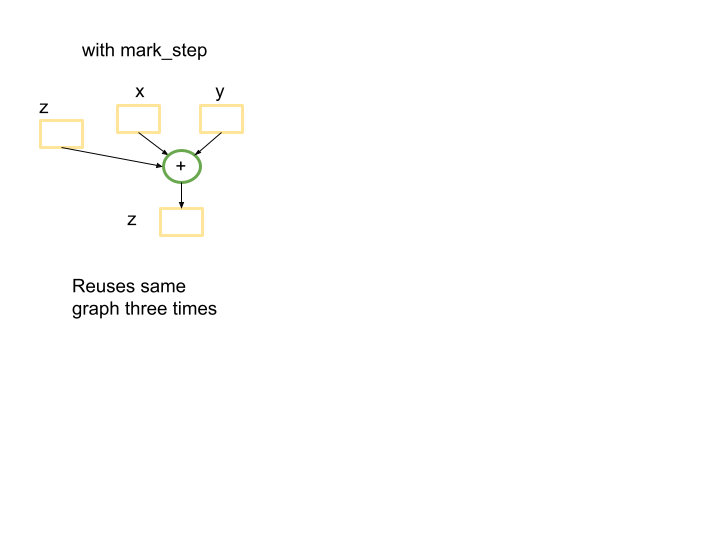
重要的是要強調,在 PyTorch XLA 中,for 迴圈內的 Python 程式碼會被追蹤,並且如果在末尾有一個屏障,則每次迭代都會建構一個新的圖表。這可能是顯著的效能瓶頸。
當相同的運算發生在相同形狀的張量上時,可以重複使用 XLA 圖表。如果輸入或中間張量的形狀發生變化,則 XLA 編譯器將使用新的張量形狀重新編譯新的圖表。這表示如果您有動態形狀,或者您的程式碼沒有重複使用張量圖表,則在 XLA 上執行模型將不適合該用例。將輸入填充為固定形狀可能是協助避免動態形狀的一種選擇。否則,編譯器將花費大量時間來最佳化和融合運算,而這些運算將不會再次使用。
圖表大小和編譯時間之間的權衡也很重要。如果有一個大型 IR 圖表,XLA 編譯器可能會花費大量時間來最佳化和融合運算。這可能會導致非常長的編譯時間。但是,由於在編譯期間執行的最佳化,稍後的執行可能會快得多。
有時值得使用 xm.mark_step() 中斷 IR 圖表。如上所述,這將產生一個較小的圖表,可以稍後重複使用。但是,縮小圖表可能會減少 XLA 編譯器原本可以執行的最佳化。
另一個需要考慮的重點是 MPDeviceLoader。一旦您的程式碼在 XLA 裝置上執行,請考慮使用 XLA MPDeviceLoader 包裝 torch 資料載入器,它會將資料預先載入到裝置以提升效能,並在其中包含 xm.mark_step()。後者會自動中斷資料批次的迭代並將其發送以執行。請注意,如果您未使用 MPDeviceLoader,則可能需要在 optimizer_step() 中設定 barrier=True 以啟用 xm.mark_step() (如果執行訓練工作),或明確新增 xm.mark_step()。
TPU 設定¶
建立具有基礎映像的 TPU 以使用 nightly wheels,或透過指定 RUNTIME_VERSION 從穩定版本使用。
export ZONE=us-central2-b
export PROJECT_ID=your-project-id
export ACCELERATOR_TYPE=v4-8 # v4-16, v4-32, …
export RUNTIME_VERSION=tpu-vm-v4-pt-2.0 # or tpu-vm-v4-base
export TPU_NAME=your_tpu_name
gcloud compute tpus tpu-vm create ${TPU_NAME} \
--zone=${ZONE} \
--accelerator-type=${ACCELERATOR_TYPE} \
--version=${RUNTIME_VERSION} \
--subnetwork=tpusubnet
如果您有單一主機 VM (例如 v4-8),您可以 ssh 連線到您的 VM 並直接從 VM 執行以下命令。否則,在 TPU Pod 的情況下,您可以使用 --worker=all --command="",類似於
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--zone=us-central2-b \
--worker=all \
--command="pip3 install https://storage.googleapis.com/pytorch-xla-releases/wheels/tpuvm/torch-nightly-cp38-cp38-linux_x86_64.whl"
接下來,如果您使用基礎映像,請安裝 nightly 套件和必要的函式庫
pip3 install https://storage.googleapis.com/pytorch-xla-releases/wheels/tpuvm/torch-nightly-cp38-cp38-linux_x86_64.whl
pip3 install https://storage.googleapis.com/pytorch-xla-releases/wheels/tpuvm/torch_xla-nightly-cp38-cp38-linux_x86_64.whl
sudo apt-get install libopenblas-dev -y
sudo apt-get update && sudo apt-get install libgl1 -y # diffusion specific
參考實作¶
AI-Hypercomputer/tpu-recipies 儲存庫包含用於訓練和服務許多 LLM 和擴散模型的範例。
將程式碼轉換為 PyTorch XLA¶
修改程式碼的一般指南
將
cuda替換為xm.xla_device()移除進度列、會存取 XLA 張量值的列印
減少會存取 XLA 張量值的記錄和回呼
使用 MPDeviceLoader 包裝資料載入器
進行效能分析以進一步最佳化程式碼
請記住:每個案例都是獨一無二的,因此您可能需要針對每個案例執行不同的操作。
範例 1. 在單一 TPU 裝置上使用 PyTorch Lightning 進行 Stable Diffusion 推論¶
作為第一個範例,請考慮在 PyTorch Lightning 中 stable diffusion 模型的 推論程式碼,可以從命令列執行,如下所示
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse"
如需參考,以下連結提供了下方描述的修改差異 此處。讓我們逐步了解它們。如上述一般指南中所述,從與 cuda 裝置相關的變更開始。此推論程式碼是為在 GPU 上執行而編寫的,並且可以在多個位置找到 cuda。首先從 此行 移除 model.cuda(),並從 此處 移除 precision_scope。此外,將 此行 中的 cuda 裝置替換為 xla 裝置,類似於以下程式碼
接下來,模型的此特定配置正在使用 FrozenCLIPEmbedder,因此我們也將修改 此行。為了簡化,我們將在本教學中直接定義 device,但您也可以將 device 值傳遞給函式。
import torch_xla.core.xla_model as xm
self.device = xm.xla_device()
程式碼中另一個具有 CUDA 特定程式碼的位置是 DDIM 排程器。在檔案頂部新增 import torch_xla.core.xla_model as xm,然後替換 這些 行
if attr.device != torch.device("cuda"):
attr = attr.to(torch.device("cuda"))
改為
device = xm.xla_device()
attr = attr.to(torch.device(device))
接下來,您可以透過移除列印陳述式、停用進度列以及減少或移除回呼和記錄,來減少裝置 (TPU) 和主機 (CPU) 通訊。這些運算需要裝置停止執行、退回到 CPU、執行記錄/回呼,然後返回裝置。這可能是顯著的效能瓶頸,尤其是在大型模型上。
進行這些變更後,程式碼將在 TPU 上執行。但是,效能會非常慢。這是因為 XLA 編譯器嘗試建構一個單一 (巨大) 圖表,該圖表包裝推論步驟的數量 (在本例中為 50),因為 for 迴圈內沒有屏障。編譯器難以最佳化圖表,這會導致顯著的效能下降。如上所述,使用屏障 (xm.mark_step()) 中斷 for 迴圈將產生一個較小的圖表,該圖表更易於編譯器最佳化。這也將允許編譯器重複使用上一步的圖表,這可以提升效能。
現在,程式碼已準備好在合理的時程內於 TPU 上執行。可以透過擷取效能分析並進一步調查來完成更多最佳化和分析。但是,此處未涵蓋此內容。
注意:如果您在 v4-8 TPU 上執行,則您有 4 個可用的 XLA (TPU) 裝置。如上執行程式碼將僅使用一個 XLA 裝置。為了在所有 4 個裝置上執行,您需要使用 torch_xla.launch() 函式在所有裝置上產生程式碼。我們將在下一個範例中討論 torch_xla.launch。
範例 2. HF Stable Diffusion 推論¶
現在,考慮在 HuggingFace diffusers 函式庫中使用 Stable Diffusion 推論,適用於模型的 SD-XL 和 2.1 版本。如需參考,以下連結提供了下方描述的變更 儲存庫。您可以複製儲存庫並在 TPU VM 上使用以下命令執行推論
(vm)$ git clone https://github.com/pytorch-tpu/diffusers.git
(vm)$ cd diffusers/examples/text_to_image/
(vm)$ python3 inference_tpu_single_device.py
在單一 TPU 裝置上執行¶
本節說明需要對 text_to_image 推論範例程式碼進行的變更,以使其在 TPU 上執行。
原始程式碼使用 Lora 進行推論,但本教學不會使用它。相反地,我們將在初始化管線時將 model_id 引數設定為 stabilityai/stable-diffusion-xl-base-0.9。我們也將使用預設排程器 (DPMSolverMultistepScheduler)。但是,也可以對其他排程器進行類似的變更。
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install . # pip install -e .
cd examples/text_to_image/
pip install -r requirements.txt
pip install invisible_watermark transformers accelerate safetensors
(如果找不到 accelerate,請登出並重新登入。)
登入 HF 並同意模型卡上的 sd-xl 0.9 授權。接下來,前往 帳戶 → 設定 → 存取權杖 並產生新的權杖。複製權杖並在您的 VM 上使用該特定權杖值執行以下命令
(vm)$ huggingface-cli login --token _your_copied_token__
HuggingFace 讀我檔案提供了為在 GPU 上執行而編寫的 PyTorch 程式碼。若要在 TPU 上執行,第一步是將 CUDA 裝置變更為 XLA 裝置。這可以透過將 pipe.to("cuda") 行替換為以下幾行來完成
import torch_xla.core.xla_model as xm
device = xm.xla_device()
pipe.to(device)
此外,重要的是要注意,您第一次使用 XLA 執行推論時,將需要很長時間才能編譯。例如,來自 HuggingFace 的 stable diffusion XL 模型推論的編譯時間可能需要約一個小時才能編譯,而實際推論可能僅需 5 秒,具體取決於批次大小。同樣地,GPT-2 模型可能需要約 10-15 分鐘才能編譯,之後訓練 epoch 時間會變得快得多。這是因為 XLA 會建構將執行的運算圖表,然後針對其執行的特定硬體最佳化此圖表。但是,一旦圖表編譯完成,就可以重複用於後續的推論,這將會快得多。因此,如果您僅執行一次推論,您可能無法從使用 XLA 中受益。但是,如果您多次執行推論,或者如果您在提示清單上執行推論,您將在最初幾次推論後開始看到 XLA 的優勢。例如,如果您在 10 個提示的清單上執行推論,則第一個推論 (可能兩個[^1]) 可能需要很長時間才能編譯,但其餘的推論步驟將會快得多。這是因為 XLA 將重複使用其為第一個推論編譯的圖表。
如果您嘗試在不進行任何其他變更的情況下執行程式碼,您會注意到編譯時間非常長 (>6 小時)。這是因為 XLA 編譯器嘗試為所有排程器步驟一次性建構單一圖表,類似於我們在先前範例中討論的內容。為了使程式碼執行速度更快,我們需要使用 xm.mark_step() 將圖表分解為較小的部分,並在後續步驟中重複使用它們。這發生在 pipe.__call__ 函式中的 這些行 中。停用進度列、移除回呼並在 for 迴圈的末尾新增 xm.mark_step() 可以顯著加速程式碼。變更在此 commit 中提供。
此外,預設使用 DPMSolverMultistepScheduler 排程器的 self.scheduler.step() 函式存在一些問題,這些問題在 PyTorch XLA 注意事項中有所描述。此函式中的 .nonzero() 和 .item() 呼叫會向 CPU 發送張量評估請求,這會觸發裝置主機通訊。這是不可取的,因為它可能會減慢程式碼的速度。在此特定情況下,我們可以透過將索引直接傳遞給函式來避免這些呼叫。這將防止函式向 CPU 發送請求,並將提升程式碼的效能。變更可在 此 commit 中找到。現在程式碼已準備好在 TPU 上執行。
效能分析和效能分析¶
為了進一步調查模型的效能,我們可以依照效能分析指南對其進行效能分析。根據經驗法則,效能分析腳本應以最大批次大小執行,該大小適合 最佳記憶體使用率的記憶體。它也有助於將程式碼的追蹤與裝置執行重疊,這會帶來更佳的裝置使用率。效能分析的持續時間應足夠長,以至少擷取一個步驟。模型在 TPU 上的良好效能表示裝置主機通訊已最小化,並且裝置持續執行程序而沒有閒置時間。
依照指南中的描述,在 inference_tpu_*.py 檔案中啟動伺服器並執行 capture_profile.py 腳本將為我們提供在裝置上執行的程序的資訊。目前,僅對一個 XLA 裝置進行效能分析。為了更了解 TPU 閒置時間 (效能分析中的間隙),應將效能分析追蹤 (xp.Trace()) 新增到程式碼中。xp.Trace() 測量在追蹤包裝的主機上追蹤 Python 程式碼所需的時間。對於此範例,xp.Trace() 追蹤已新增到 管線 和 U-net 模型中,以測量在主機 (CPU) 上執行程式碼特定區段的時間。
如果效能分析中的間隙是由主機上發生的 Python 程式碼追蹤所致,則這可能是瓶頸,並且沒有可以執行的進一步直接最佳化。否則,應進一步分析程式碼以了解注意事項並進一步提升效能。請注意,您無法 xp.Trace() 包裝呼叫 xm.mark_step() 的程式碼部分。
為了說明這一點,我們可以查看已擷取的效能分析,這些效能分析已依照效能分析指南上傳到 TensorBoard。
從 Stable Diffusion 模型版本 2.1 開始
如果我們在不插入任何追蹤的情況下擷取效能分析,我們將看到以下內容
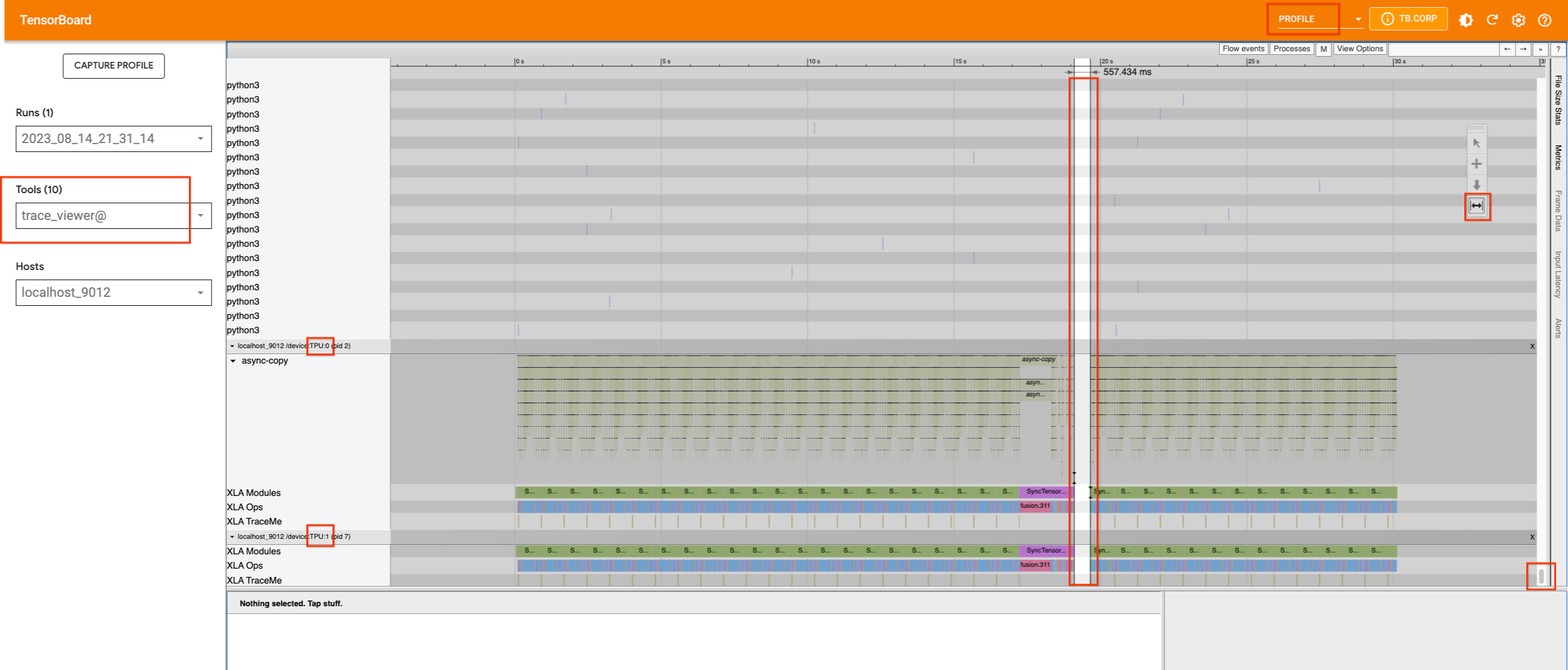
v4-8 上的單一 TPU 裝置 (具有兩個核心) 似乎很忙。它們的使用情況沒有明顯的間隙,除了中間有一個小間隙。如果我們向上捲動以嘗試尋找哪個程序佔用主機,我們將找不到任何資訊。因此,我們將 xp.traces 新增到管線 檔案 以及 U-net 函式。後者可能對此特定用例沒有用處,但它確實示範了如何在不同位置新增追蹤以及如何在 TensorBoard 中顯示其資訊。
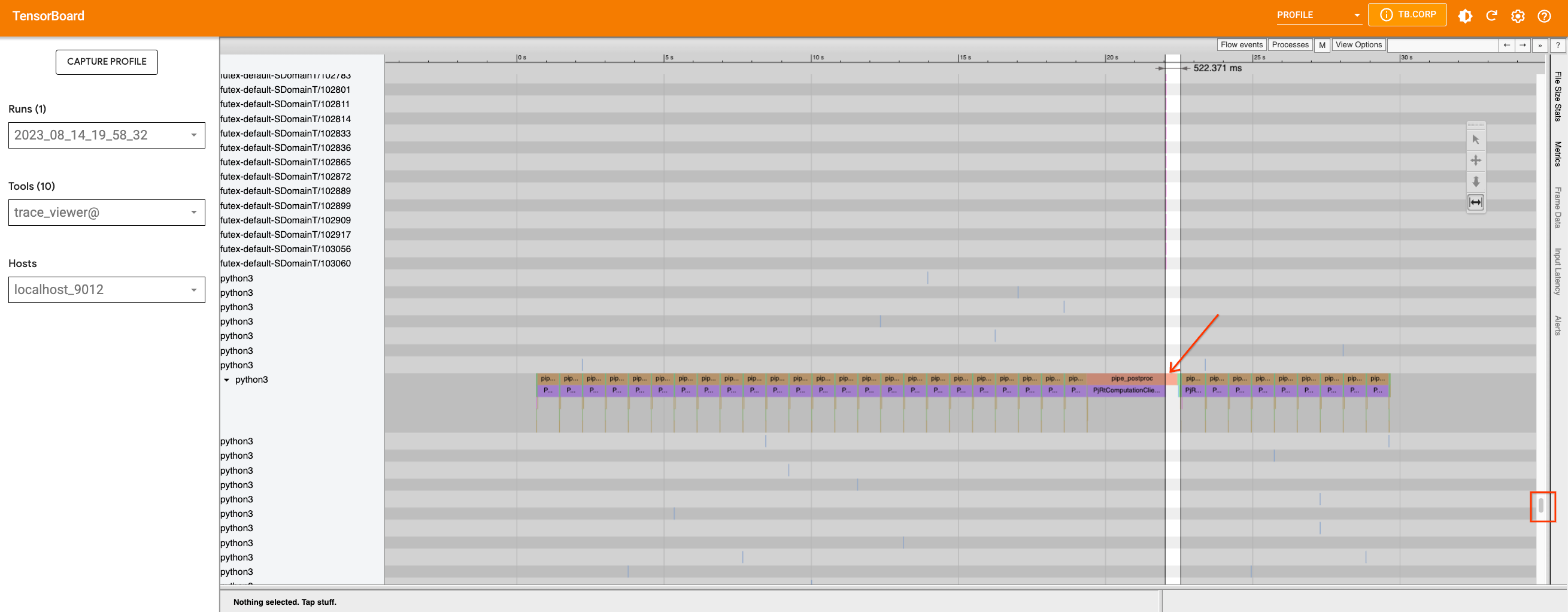
如果我們新增追蹤並使用可以容納在裝置上的最大批次大小 (在本例中為 32) 重新擷取效能分析,我們將看到裝置中的間隙是由在主機上執行的 Python 程序引起的。
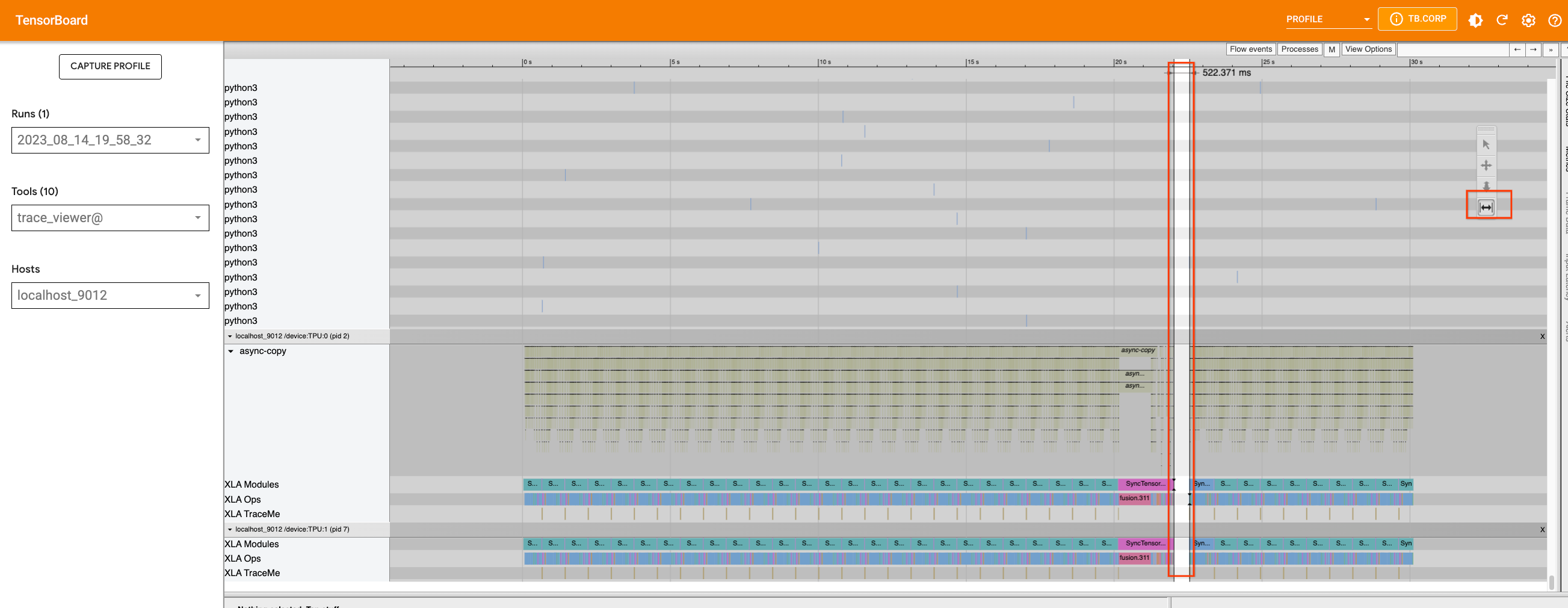
我們可以使用適當的工具來放大時間軸,並查看該期間正在執行的程序。這是在主機上發生 Python 程式碼追蹤時,並且我們目前無法進一步改善追蹤。
現在,讓我們檢查模型的 XL 版本並執行相同的操作。我們將以與 2.1 版本相同的方式將追蹤新增到管線 檔案,並擷取效能分析。
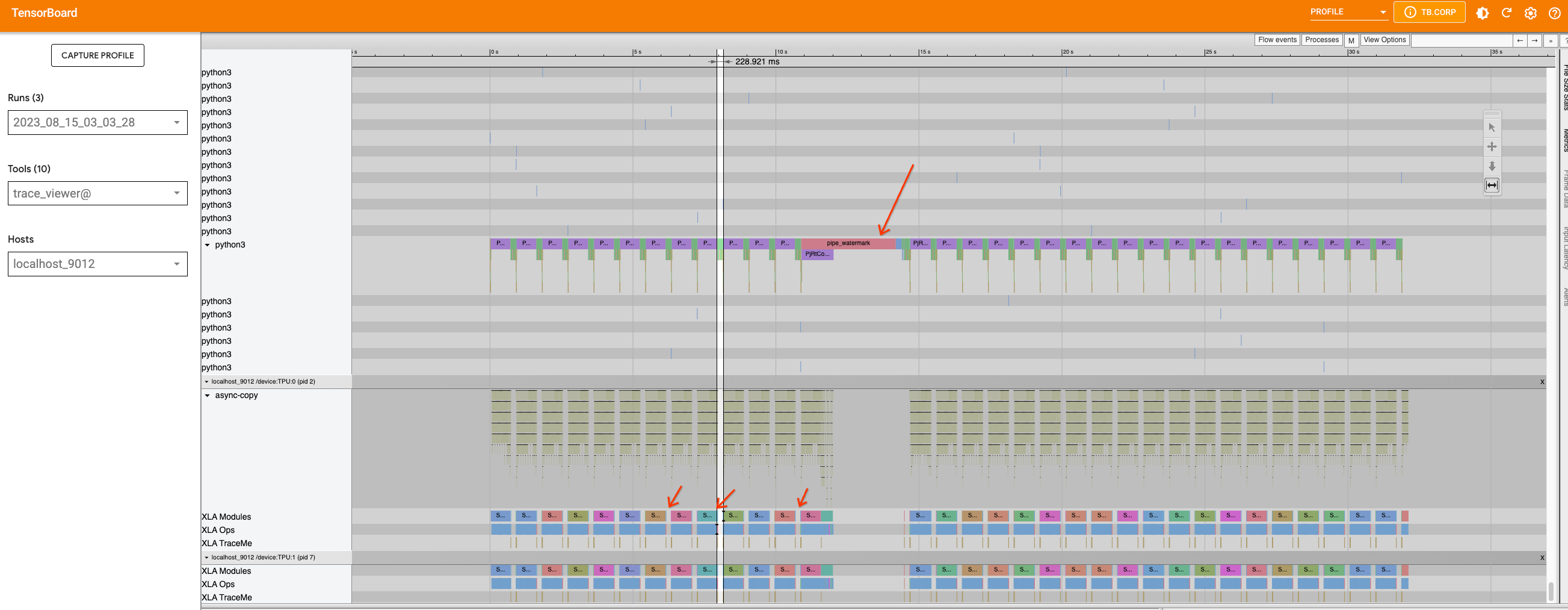
這次,除了由 pipe_watermark 追蹤引起的中間大間隙之外,在 此迴圈內的推論步驟之間還有許多小間隙。
首先仔細查看由 pipe_watermark 引起的大間隙。間隙前面有 TransferFromDevice,表示主機上正在發生某些事情,這些事情正在等待運算完成後才能繼續進行。查看浮水印 程式碼,我們可以看到張量已傳輸到 CPU 並轉換為 Numpy 陣列,以便稍後使用 cv2 和 pywt 函式庫進行處理。由於這部分不容易最佳化,因此我們將保持原樣。
現在,如果我們放大迴圈,我們可以發現迴圈內的圖表被分解為較小的部分,因為發生了 TransferFromDevice 運算。
如果我們調查 U-Net 函式和排程器,我們可以發現 U-Net 程式碼不包含 PyTorch/XLA 的任何最佳化目標。但是,scheduler.step 內部有 .item() 和 .nonzero() 呼叫。我們可以重寫函式以避免這些呼叫。如果我們修正此問題並重新執行效能分析,我們將看不到太大的差異。但是,由於我們減少了導致較小圖表的裝置主機通訊,因此我們允許編譯器更好地最佳化程式碼。scale_model_input 函式具有類似的問題,我們可以透過對 step 函式進行上述變更來修正這些問題。總體而言,由於許多間隙是由 Python 層級程式碼追蹤和圖表建構引起的,因此在目前的 PyTorch XLA 版本中無法最佳化這些間隙,但當 dynamo 在 PyTorch XLA 中啟用時,我們可能會看到改進。
在多個 TPU 裝置上執行¶
若要使用多個 TPU 裝置,您可以使用 torch_xla.launch 函式將您在單一裝置上執行的函式產生到多個裝置。當需要時,torch_xla.launch 函式將在多個 TPU 裝置上啟動程序並同步它們。這可以透過將 index 引數傳遞給在單一裝置上執行的函式來完成。例如,
import torch_xla
def my_function(index):
# function that runs on a single device
torch_xla.launch(my_function, args=(0,))
在此範例中,my_function 函式將在 v4-8 上的 4 個 TPU 裝置上產生,每個裝置都分配一個從 0 到 3 的索引。請注意,預設情況下,launch() 函式將在所有 TPU 裝置上產生程序。如果您只想執行單一程序,請設定引數 launch(..., debug_single_process=True)。
此檔案說明如何使用 xmp.spawn 在多個 TPU 裝置上執行 stable diffusion 2.1 版本。對於此版本,類似於上述變更,已對 管線 檔案進行了變更。
在 Pod 上執行¶
一旦您擁有在單一主機裝置上執行的程式碼,就不需要進一步變更。您可以建立 TPU pod,例如,依照這些指示進行。然後使用以下命令執行您的腳本
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--zone=${ZONE} \
--worker=all \
--command="python3 your_script.py"
注意
0 和 1 是 XLA 中的 magic number,在 HLO 中被視為常數。因此,如果程式碼中有一個可以產生這些值的隨機數字產生器,程式碼將會針對每個值分別編譯。可以使用 XLA_NO_SPECIAL_SCALARS=1 環境變數停用此功能。
