注意
前往結尾以下載完整的範例程式碼
在 Torch-TensorRT 引擎中使用自訂核心¶
我們將示範開發人員如何使用 Torch-TensorRT 在 TensorRT 引擎中包含自訂核心
Torch-TensorRT 支援在 Torch-TensorRT 不知道如何在 TensorRT 中編譯運算的情況下,回退到 PyTorch 運算的實作。然而,這會導致圖形中斷,並降低模型的效能。修正不支援運算的最簡單方法是新增分解 (請參閱:為 Dynamo 前端撰寫 lowering passes) - 其以 Torch-TensorRT 中支援的 PyTorch 運算來定義運算子,或新增轉換器 (請參閱:為 Dynamo 前端撰寫轉換器) - 其以 TensorRT 運算子來定義運算子。
在某些情況下,這兩種方法都不太好,可能是因為運算子是自訂核心,而非標準 PyTorch 的一部分,或者 TensorRT 無法原生支援它。
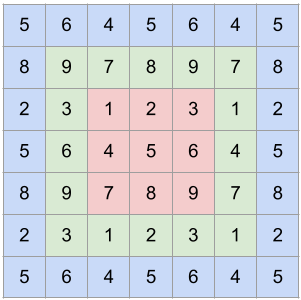
對於這些情況,可以使用 TensorRT 外掛程式來取代 TensorRT 引擎內部的運算子,從而避免圖形中斷造成的效能和資源開銷。為了示範,請考慮圓形填充運算。圓形填充對於深度學習中的圓形卷積等運算很有用。下圖表示原始影像 (紅色) 如何進行一次 (綠色) 和兩次 (藍色) 圓形填充
在 PyTorch 中撰寫自訂運算子¶
假設無論基於何種原因,我們都想使用圓形填充的自訂實作。在本例中,使用以 OpenAI Triton 撰寫的核心來實作
當在 PyTorch 中使用自訂核心時,建議採取額外步驟,將其註冊為 PyTorch 中的正式運算子。這將使在 Torch-TensorRT 中處理運算更容易,並簡化其在 PyTorch 中的使用。這可以作為 C++ 函式庫的一部分或在 Python 中完成。(請參閱:C++ 中的自訂運算 和 Python 自訂運算 以了解更多詳細資訊)
from typing import Any, Sequence
import numpy as np
import torch
import triton
import triton.language as tl
from torch.library import custom_op
# Defining the kernel to be run on the GPU
@triton.jit # type: ignore
def circ_pad_kernel(
X: torch.Tensor,
all_pads_0: tl.int32,
all_pads_2: tl.int32,
all_pads_4: tl.int32,
all_pads_6: tl.int32,
orig_dims_0: tl.int32,
orig_dims_1: tl.int32,
orig_dims_2: tl.int32,
orig_dims_3: tl.int32,
Y: torch.Tensor,
Y_shape_1: tl.int32,
Y_shape_2: tl.int32,
Y_shape_3: tl.int32,
X_len: tl.int32,
Y_len: tl.int32,
BLOCK_SIZE: tl.constexpr,
) -> None:
pid = tl.program_id(0)
i = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask_y = i < Y_len
i3 = i % Y_shape_3
i2 = (i // Y_shape_3) % Y_shape_2
i1 = (i // Y_shape_3 // Y_shape_2) % Y_shape_1
i0 = i // Y_shape_3 // Y_shape_2 // Y_shape_1
j0 = (i0 - all_pads_0 + orig_dims_0) % orig_dims_0
j1 = (i1 - all_pads_2 + orig_dims_1) % orig_dims_1
j2 = (i2 - all_pads_4 + orig_dims_2) % orig_dims_2
j3 = (i3 - all_pads_6 + orig_dims_3) % orig_dims_3
load_idx = (
orig_dims_3 * orig_dims_2 * orig_dims_1 * j0
+ orig_dims_3 * orig_dims_2 * j1
+ orig_dims_3 * j2
+ j3
)
mask_x = load_idx < X_len
x = tl.load(X + load_idx, mask=mask_x)
tl.store(Y + i, x, mask=mask_y)
# The launch code wrapped to expose it as a custom operator in our namespace
@custom_op("torchtrt_ex::triton_circular_pad", mutates_args=()) # type: ignore[misc]
def triton_circular_pad(x: torch.Tensor, padding: Sequence[int]) -> torch.Tensor:
out_dims = np.ones(len(x.shape), dtype=np.int32)
for i in range(np.size(padding) // 2):
out_dims[len(out_dims) - i - 1] = (
x.shape[len(out_dims) - i - 1] + padding[i * 2] + padding[i * 2 + 1]
)
y = torch.empty(tuple(out_dims.tolist()), device=x.device)
N = len(x.shape)
all_pads = np.zeros((N * 2,), dtype=np.int32)
orig_dims = np.array(x.shape, dtype=np.int32)
out_dims = np.array(x.shape, dtype=np.int32)
for i in range(len(padding) // 2):
out_dims[N - i - 1] += padding[i * 2] + padding[i * 2 + 1]
all_pads[N * 2 - 2 * i - 2] = padding[i * 2]
all_pads[N * 2 - 2 * i - 1] = padding[i * 2 + 1]
blockSize = 256
numBlocks = (int((np.prod(out_dims) + blockSize - 1) // blockSize),)
circ_pad_kernel[numBlocks](
x,
all_pads[0],
all_pads[2],
all_pads[4],
all_pads[6],
orig_dims[0],
orig_dims[1],
orig_dims[2],
orig_dims[3],
y,
out_dims[1],
out_dims[2],
out_dims[3],
int(np.prod(orig_dims)),
int(np.prod(out_dims)),
BLOCK_SIZE=256,
)
return y
以上是在 PyTorch 中建立自訂運算子所需的一切。我們現在可以直接將其稱為 torch.ops.torchtrt_ex.triton_circular_pad
測試我們的自訂運算¶
原生 PyTorch 實作
ex_input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3).to("cuda")
padding = (1, 1, 2, 0)
torch.nn.functional.pad(ex_input, padding, "circular")
tensor([[[[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.],
[2., 0., 1., 2., 0.],
[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.]]]], device='cuda:0')
我們的自訂實作
torch.ops.torchtrt_ex.triton_circular_pad(ex_input, padding)
tensor([[[[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.],
[2., 0., 1., 2., 0.],
[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.]]]], device='cuda:0')
我們已經定義了開始在 PyTorch 中使用自訂運算的最低要求,但為了額外步驟讓 Dynamo (在 Torch-TensorRT 中受支援的先決條件) 可以追蹤此運算子,我們需要定義運算的「Fake Tensor」實作。此函式定義了我們的核心對輸入張量產生的影響,以原生 PyTorch 運算來表示。它允許 Dynamo 在無需使用真實資料的情況下計算張量屬性,例如大小、步幅、裝置等 (更多資訊請參閱 此處)。在我們的例子中,我們可以僅使用原生圓形填充運算作為我們的 FakeTensor 實作。
@torch.library.register_fake("torchtrt_ex::triton_circular_pad") # type: ignore[misc]
def _(x: torch.Tensor, padding: Sequence[int]) -> torch.Tensor:
return torch.nn.functional.pad(x, padding, "circular")
# Additionally one may want to define an autograd implementation for the backwards pass to round out the custom op implementation but that is beyond the scope of this tutorial (see https://pytorch.dev.org.tw/docs/main/library.html#torch.library.register_autograd for more)
在模型中使用自訂運算子¶
我們現在可以使用我們的自訂運算來建立模型。以下是一個小型範例,其中同時使用了原生支援的運算子 (卷積) 和我們的自訂運算。
from typing import Sequence
from torch import nn
class MyModel(nn.Module): # type: ignore[misc]
def __init__(self, padding: Sequence[int]):
super().__init__()
self.padding = padding
self.conv = nn.Conv2d(1, 5, kernel_size=3)
def forward(self, x: torch.Tensor) -> torch.Tensor:
padded_x = torch.ops.torchtrt_ex.triton_circular_pad(x, self.padding)
y = self.conv(padded_x)
return y
my_model = MyModel((1, 1, 2, 0)).to("cuda")
my_model(ex_input)
tensor([[[[-0.2604, -0.4232, -0.3041],
[-3.0833, -3.2461, -3.1270],
[-0.2450, -0.4079, -0.2887]],
[[ 0.2828, -0.0373, 1.0332],
[-2.3143, -2.6344, -1.5638],
[-1.1867, -1.5068, -0.4363]],
[[ 1.7937, 1.3488, 2.1350],
[ 0.7966, 0.3517, 1.1379],
[ 3.5537, 3.1088, 3.8950]],
[[-1.0550, -0.6163, -1.0109],
[ 0.5245, 0.9632, 0.5686],
[ 0.3775, 0.8162, 0.4216]],
[[-0.4311, -0.1649, -1.2091],
[-4.3668, -4.1006, -5.1447],
[-5.0352, -4.7689, -5.8131]]]], device='cuda:0')
如果我們嘗試使用 Torch-TensorRT 編譯此模型,我們可以看見 (截至 Torch-TensorRT 2.4.0),已建立許多子圖來在 PyTorch 中執行自訂運算,並在 TensorRT 中執行卷積
import torch_tensorrt as torchtrt
torchtrt.compile(
my_model,
inputs=[ex_input],
dryrun=True, # Check the support of the model without having to build the engines
min_block_size=1,
)
GraphModule(
(_run_on_gpu_0): GraphModule()
(_run_on_acc_1): GraphModule(
(conv): Module()
)
)
++++++++++++++ Dry-Run Results for Graph +++++++++++++++++
The graph consists of 2 Total Operators, of which 1 operators are supported, 50.0% coverage
The following ops are currently unsupported or excluded from conversion, and are listed with their op-count in the graph:
torch.ops.torchtrt_ex.triton_circular_pad.default: 1
The following nodes are currently set to run in Torch:
Node: torch.ops.torchtrt_ex.triton_circular_pad.default, with layer location: __/triton_circular_pad
Note: Some of the above nodes may be supported, but were not included in a TRT graph by the partitioner
Compiled with: CompilationSettings(enabled_precisions={<dtype.f32: 7>}, debug=False, workspace_size=0, min_block_size=1, torch_executed_ops=set(), pass_through_build_failures=False, max_aux_streams=None, version_compatible=False, optimization_level=None, use_python_runtime=False, truncate_double=False, use_fast_partitioner=True, enable_experimental_decompositions=False, device=Device(type=DeviceType.GPU, gpu_id=0), require_full_compilation=False, disable_tf32=False, sparse_weights=False, refit=False, engine_capability=<EngineCapability.STANDARD: 1>, num_avg_timing_iters=1, dla_sram_size=1048576, dla_local_dram_size=1073741824, dla_global_dram_size=536870912, dryrun=True, hardware_compatible=False)
Graph Structure:
Inputs: List[Tensor: (1, 1, 3, 3)@float32]
...
TRT Engine #1 - Submodule name: _run_on_acc_1
Engine Inputs: List[Tensor: (1, 1, 5, 5)@float32]
Number of Operators in Engine: 1
Engine Outputs: Tensor: (1, 5, 3, 3)@float32
...
Outputs: List[Tensor: (1, 5, 3, 3)@float32]
--------- Aggregate Stats ---------
Average Number of Operators per TRT Engine: 1.0
Most Operators in a TRT Engine: 1
********** Recommendations **********
- For minimal graph segmentation, select min_block_size=1 which would generate 1 TRT engine(s)
- The current level of graph segmentation is equivalent to selecting min_block_size=1 which generates 1 TRT engine(s)
我們看到將會有 2 個子圖,一個將透過 PyTorch 執行我們的自訂運算,另一個將透過 TensorRT 執行卷積。此圖形中斷將會是此模型延遲時間的很大一部分。
包裝自訂核心以在 TensorRT 中使用¶
為了解決此圖形中斷問題,第一步是在 TensorRT 中提供我們的核心實作。同樣地,這可以在 C++ 或 Python 中完成。如需關於如何實作 TensorRT 外掛程式的實際詳細資訊,請參閱 此處。從高層次來看,與 PyTorch 類似,您需要定義系統來處理設定運算子、抽象地計算運算的影響、序列化運算和在引擎中呼叫運算實作的實際機制。
import pickle as pkl
from typing import Any, List, Optional, Self
import cupy as cp # Needed to work around API gaps in PyTorch to build torch.Tensors around preallocated CUDA memory
import numpy as np
import tensorrt as trt
class CircularPaddingPlugin(trt.IPluginV2DynamicExt): # type: ignore[misc]
def __init__(
self, field_collection: Optional[List[trt.PluginFieldCollection]] = None
):
super().__init__()
self.pads = []
self.X_shape: List[int] = []
self.num_outputs = 1
self.plugin_namespace = ""
self.plugin_type = "CircularPaddingPlugin"
self.plugin_version = "1"
if field_collection is not None:
assert field_collection[0].name == "pads"
self.pads = field_collection[0].data
def get_output_datatype(
self, index: int, input_types: List[trt.DataType]
) -> trt.DataType:
return input_types[0]
def get_output_dimensions(
self,
output_index: int,
inputs: List[trt.DimsExprs],
exprBuilder: trt.IExprBuilder,
) -> trt.DimsExprs:
output_dims = trt.DimsExprs(inputs[0])
for i in range(np.size(self.pads) // 2):
output_dims[len(output_dims) - i - 1] = exprBuilder.operation(
trt.DimensionOperation.SUM,
inputs[0][len(output_dims) - i - 1],
exprBuilder.constant(self.pads[i * 2] + self.pads[i * 2 + 1]),
)
return output_dims
def configure_plugin(
self,
inp: List[trt.DynamicPluginTensorDesc],
out: List[trt.DynamicPluginTensorDesc],
) -> None:
X_dims = inp[0].desc.dims
self.X_shape = np.zeros((len(X_dims),))
for i in range(len(X_dims)):
self.X_shape[i] = X_dims[i]
def serialize(self) -> bytes:
return pkl.dumps({"pads": self.pads})
def supports_format_combination(
self, pos: int, in_out: List[trt.PluginTensorDesc], num_inputs: int
) -> bool:
assert num_inputs == 1
assert pos < len(in_out)
desc = in_out[pos]
if desc.format != trt.TensorFormat.LINEAR:
return False
# first input should be float16 or float32
if pos == 0:
return bool(
(desc.type == trt.DataType.FLOAT) or desc.type == (trt.DataType.HALF)
)
# output should have the same type as the input
if pos == 1:
return bool((in_out[0].type == desc.type))
return False
def enqueue(
self,
input_desc: List[trt.PluginTensorDesc],
output_desc: List[trt.PluginTensorDesc],
inputs: List[int],
outputs: List[int],
workspace: int,
stream: int,
) -> None:
# Host code is slightly different as this will be run as part of the TRT execution
in_dtype = torchtrt.dtype.try_from(input_desc[0].type).to(np.dtype)
a_mem = cp.cuda.UnownedMemory(
inputs[0], np.prod(input_desc[0].dims) * cp.dtype(in_dtype).itemsize, self
)
c_mem = cp.cuda.UnownedMemory(
outputs[0],
np.prod(output_desc[0].dims) * cp.dtype(in_dtype).itemsize,
self,
)
a_ptr = cp.cuda.MemoryPointer(a_mem, 0)
c_ptr = cp.cuda.MemoryPointer(c_mem, 0)
a_d = cp.ndarray((np.prod(input_desc[0].dims)), dtype=in_dtype, memptr=a_ptr)
c_d = cp.ndarray((np.prod(output_desc[0].dims)), dtype=in_dtype, memptr=c_ptr)
a_t = torch.as_tensor(a_d, device="cuda")
c_t = torch.as_tensor(c_d, device="cuda")
N = len(self.X_shape)
all_pads = np.zeros((N * 2,), dtype=np.int32)
orig_dims = np.array(self.X_shape, dtype=np.int32)
out_dims = np.array(self.X_shape, dtype=np.int32)
for i in range(np.size(self.pads) // 2):
out_dims[N - i - 1] += self.pads[i * 2] + self.pads[i * 2 + 1]
all_pads[N * 2 - 2 * i - 2] = self.pads[i * 2]
all_pads[N * 2 - 2 * i - 1] = self.pads[i * 2 + 1]
all_pads = all_pads.tolist()
orig_dims = orig_dims.tolist()
out_dims = out_dims.tolist()
blockSize = 256
numBlocks = (int((np.prod(out_dims) + blockSize - 1) // blockSize),)
# Call the same kernel implementation we use in PyTorch
circ_pad_kernel[numBlocks](
a_t,
all_pads[0],
all_pads[2],
all_pads[4],
all_pads[6],
orig_dims[0],
orig_dims[1],
orig_dims[2],
orig_dims[3],
c_t,
out_dims[1],
out_dims[2],
out_dims[3],
int(np.prod(orig_dims)),
int(np.prod(out_dims)),
BLOCK_SIZE=256,
)
def clone(self) -> Self:
cloned_plugin = CircularPaddingPlugin()
cloned_plugin.__dict__.update(self.__dict__)
return cloned_plugin
class CircularPaddingPluginCreator(trt.IPluginCreator): # type: ignore[misc]
def __init__(self):
super().__init__()
self.name = "CircularPaddingPlugin"
self.plugin_namespace = ""
self.plugin_version = "1"
self.field_names = trt.PluginFieldCollection(
[trt.PluginField("pads", np.array([]), trt.PluginFieldType.INT32)]
)
def create_plugin(
self, name: str, field_collection: trt.PluginFieldCollection_
) -> CircularPaddingPlugin:
return CircularPaddingPlugin(field_collection)
def deserialize_plugin(self, name: str, data: bytes) -> CircularPaddingPlugin:
pads_dict = pkl.loads(data)
print(pads_dict)
deserialized = CircularPaddingPlugin()
deserialized.__dict__.update(pads_dict)
print(deserialized.pads)
return deserialized
# Register the plugin creator in the TensorRT Plugin Registry
TRT_PLUGIN_REGISTRY = trt.get_plugin_registry()
TRT_PLUGIN_REGISTRY.register_creator(CircularPaddingPluginCreator(), "") # type: ignore[no-untyped-call]
使用 Torch-TensorRT 插入核心¶
現在有了我們的 TensorRT 外掛程式,我們可以建立轉換器,以便 Torch-TensorRT 知道要插入我們的外掛程式來取代我們的自訂圓形填充運算子。關於撰寫轉換器的更多資訊,請參閱 此處
from typing import Dict, Tuple
from torch.fx.node import Argument, Target
from torch_tensorrt.dynamo.conversion import (
ConversionContext,
dynamo_tensorrt_converter,
)
from torch_tensorrt.dynamo.conversion.converter_utils import get_trt_tensor
from torch_tensorrt.fx.converters.converter_utils import set_layer_name
@dynamo_tensorrt_converter(
torch.ops.torchtrt_ex.triton_circular_pad.default
) # type: ignore
# Recall the schema defined above:
# torch.ops.torchtrt_ex.triton_circular_pad.default(Tensor x, IntList padding) -> Tensor
def circular_padding_converter(
ctx: ConversionContext,
target: Target,
args: Tuple[Argument, ...],
kwargs: Dict[str, Argument],
name: str,
):
# How to retrieve a plugin if it is defined elsewhere (e.g. linked library)
plugin_registry = trt.get_plugin_registry()
plugin_creator = plugin_registry.get_plugin_creator(
type="CircularPaddingPlugin", version="1", plugin_namespace=""
)
assert plugin_creator, f"Unable to find CircularPaddingPlugin creator"
# Pass configurations to the plugin implementation
field_configs = trt.PluginFieldCollection(
[
trt.PluginField(
"pads",
np.array(
args[1], dtype=np.int32
), # Arg 1 of `torch.ops.torchtrt_ex.triton_circular_pad` is the int list containing the padding settings. Note: the dtype matters as you are eventually passing this as a c-like buffer
trt.PluginFieldType.INT32,
),
]
)
plugin = plugin_creator.create_plugin(name=name, field_collection=field_configs)
assert plugin, "Unable to create CircularPaddingPlugin"
input_tensor = args[
0
] # Arg 0 `torch.ops.torchtrt_ex.triton_circular_pad` is the input tensor
if not isinstance(input_tensor, trt.ITensor):
# Freeze input tensor if not TensorRT Tensor already
input_tensor = get_trt_tensor(ctx, input_tensor, f"{name}_input")
layer = ctx.net.add_plugin_v2(
[input_tensor], plugin
) # Add the plugin to the network being constructed
layer.name = f"circular_padding_plugin-{name}"
return layer.get_output(0)
最後,我們現在可以完整編譯我們的模型
trt_model = torchtrt.compile(
my_model,
inputs=[ex_input],
min_block_size=1,
)
GraphModule(
(_run_on_acc_0): TorchTensorRTModule()
)
+++++++++++++++ Dry-Run Results for Graph ++++++++++++++++
The graph consists of 2 Total Operators, of which 2 operators are supported, 100.0% coverage
Compiled with: CompilationSettings(enabled_precisions={<dtype.f32: 7>}, debug=True, workspace_size=0, min_block_size=1, torch_executed_ops=set(), pass_through_build_failures=False, max_aux_streams=None, version_compatible=False, optimization_level=None, use_python_runtime=False, truncate_double=False, use_fast_partitioner=True, enable_experimental_decompositions=False, device=Device(type=DeviceType.GPU, gpu_id=0), require_full_compilation=False, disable_tf32=False, sparse_weights=False, refit=False, engine_capability=<EngineCapability.STANDARD: 1>, num_avg_timing_iters=1, dla_sram_size=1048576, dla_local_dram_size=1073741824, dla_global_dram_size=536870912, dryrun=False, hardware_compatible=False)
Graph Structure:
Inputs: List[Tensor: (1, 1, 3, 3)@float32]
...
TRT Engine #1 - Submodule name: _run_on_acc_0
Engine Inputs: List[Tensor: (1, 1, 3, 3)@float32]
Number of Operators in Engine: 2
Engine Outputs: Tensor: (1, 5, 3, 3)@float32
...
Outputs: List[Tensor: (1, 5, 3, 3)@float32]
---------- Aggregate Stats -------------
Average Number of Operators per TRT Engine: 2.0
Most Operators in a TRT Engine: 2
********** Recommendations **********
- For minimal graph segmentation, select min_block_size=2 which would generate 1 TRT engine(s)
- The current level of graph segmentation is equivalent to selecting min_block_size=2 which generates 1 TRT engine(s)
如您所見,現在僅為 TensorRT 引擎建立一個子圖,其中包含我們的自訂核心和原生卷積運算子。
print(trt_model(ex_input))
tensor([[[[-0.2604, -0.4232, -0.3041],
[-3.0833, -3.2461, -3.1270],
[-0.2450, -0.4079, -0.2887]],
[[ 0.2828, -0.0373, 1.0332],
[-2.3143, -2.6344, -1.5638],
[-1.1867, -1.5068, -0.4363]],
[[ 1.7937, 1.3488, 2.1350],
[ 0.7966, 0.3517, 1.1379],
[ 3.5537, 3.1088, 3.8950]],
[[-1.0550, -0.6163, -1.0109],
[ 0.5245, 0.9632, 0.5686],
[ 0.3775, 0.8162, 0.4216]],
[[-0.4311, -0.1649, -1.2091],
[-4.3668, -4.1006, -5.1447],
[-5.0352, -4.7689, -5.8131]]]], device='cuda:0')
我們可以驗證我們的實作是否由 TensorRT 和 PyTorch 正確執行
print(my_model(ex_input) - trt_model(ex_input))
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]], device='cuda:0', grad_fn=<SubBackward0>)
腳本總執行時間: (0 分鐘 0.000 秒)
