torch.compile 疑難排解¶
您嘗試在您的 PyTorch 模型上使用 torch.compile 以提高其效能,但它未如預期運作。可能效能沒有提升、發生崩潰,或編譯時間太長。本文提供提示、解決方法和偵錯工具,以協助您克服這些挑戰。
目錄
設定期望¶
torch.compile 設計為通用 PyTorch 編譯器。 與先前的編譯器解決方案 TorchScript 不同,torch.compile 需要較少的程式碼變更,這表示通常不需要從頭開始重寫模型。 它還可以更優雅地管理不受支援的程式碼 - 不受支援的程式碼導致失去優化機會,而不是崩潰。
在理想情況下,可以簡單地將 torch.compile 應用於任何 PyTorch 模型並享受自動加速。 但是,實際上,程式碼複雜性可能導致以下三種情況之一
torch.compile無縫運作,提供加速。需要進行一些程式碼修改。
torch.compile不會崩潰或花費太長時間,但您可能看不到顯著的效能提升。需要對程式碼進行廣泛的變更。
我們預計大多數程式碼將屬於情境 (1) 和 (2)。 本文件提供了一些提示,按參與程度排列,以幫助解決情境 (2) 中的程式碼問題。
術語¶
以下術語與 torch.compile 問題的疑難排解相關。
圖形中斷¶
torch.compile 追蹤您的程式碼並嘗試將您的 PyTorch 程式碼捕獲到 PyTorch 運算符的單個計算圖(FX 圖形)中。 但是,這並非總是可能的。 當遇到無法追蹤的程式碼時,會發生「圖形中斷」。 圖形中斷涉及編譯到目前為止已確定的 FX 圖形、執行不受支援的程式碼,然後在不受支援的程式碼之後使用新的 FX 圖形恢復追蹤。 由於計算圖被分解,我們失去了優化機會,因此模型程式碼應盡可能避免圖形中斷。 圖形中斷發生在以下情況:
資料相關的 if 語句
許多 Python 內建函數
C 函數
以下是由於 Python 內建庫中的函數 copy.deepcopy 導致圖形中斷的範例(確切輸出可能有所不同)。
import torch
@torch.compile
def fn(x):
x = x + 1
with open("test.txt", "r") as f:
return x + len(f.read())
fn(torch.ones(3, 3))
$TORCH_LOGS="graph_breaks" python playground.py
Graph break in user code at /data/users/williamwen/pytorch/playground.py:7
Reason: Unsupported: builtin: open [<class 'torch._dynamo.variables.constant.ConstantVariable'>, <class 'torch._dynamo.variables.constant.ConstantVariable'>] False
User code traceback:
File "/data/users/williamwen/pytorch/playground.py", line 7, in fn
with open("test.txt", "r") as f:
Traceback (most recent call last):
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 635, in wrapper
return inner_fn(self, inst)
^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 2414, in CALL
self._call(inst)
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 2408, in _call
self.call_function(fn, args, kwargs)
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 962, in call_function
self.push(fn.call_function(self, args, kwargs)) # type: ignore[arg-type]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/variables/builtin.py", line 997, in call_function
return handler(tx, args, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/variables/builtin.py", line 831, in <lambda>
return lambda *args: unimplemented(error_msg)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/exc.py", line 313, in unimplemented
raise Unsupported(msg, case_name=case_name)
torch._dynamo.exc.Unsupported: builtin: open [<class 'torch._dynamo.variables.constant.ConstantVariable'>, <class 'torch._dynamo.variables.constant.ConstantVariable'>] False
Guard¶
torch.compile 在我們追蹤程式碼時,會對運行時值做出一些假設。 在追蹤期間,我們會產生「guard」,它們是針對這些假設的運行時檢查。 Guard 在未來對編譯函數的調用中運行,以確定我們是否可以重複使用先前編譯的程式碼。 運行時檢查的範例包括常數值、類型和物件 ID。
以下是產生的 guard 範例。 TENSOR_MATCH guard 檢查輸入的類型、裝置、dtype、形狀等。
import torch
@torch.compile
def fn(x):
return x + 1
fn(torch.ones(3, 3))
$ TORCH_LOGS="guards" python playground.py
GUARDS:
TREE_GUARD_MANAGER:
+- RootGuardManager
| +- DEFAULT_DEVICE: utils_device.CURRENT_DEVICE == None # _dynamo/output_graph.py:471 in init_ambient_guards
| +- GLOBAL_STATE: ___check_global_state()
| +- TORCH_FUNCTION_MODE_STACK: ___check_torch_function_mode_stack()
| +- GuardManager: source=L['x'], accessed_by=DictGetItemGuardAccessor(x)
| | +- TENSOR_MATCH: check_tensor(L['x'], Tensor, DispatchKeySet(CPU, BackendSelect, ADInplaceOrView, AutogradCPU), torch.float32, device=None, requires_grad=False, size=[3, 3], stride=[3, 1]) # return x + 1 # playground.py:6 in fn
| | +- NO_HASATTR: hasattr(L['x'], '_dynamo_dynamic_indices') == False # return x + 1 # playground.py:6 in fn
重新編譯¶
如果先前編譯的程式碼的每個實例的 guard 都失敗,則 torch.compile 必須「重新編譯」該函數,需要再次追蹤原始程式碼。
在下面的範例中,由於檢查張量參數形狀的 guard 失敗,因此需要重新編譯。
import torch
@torch.compile
def fn(x):
return x + 1
fn(torch.ones(3, 3))
fn(torch.ones(4, 4))
$ TORCH_LOGS="recompiles" python playground.py
Recompiling function fn in /data/users/williamwen/pytorch/playground.py:3
triggered by the following guard failure(s):
- 0/0: tensor 'L['x']' size mismatch at index 0. expected 3, actual 4
動態形狀¶
torch.compile 最初假設張量形狀是靜態/常數,並基於這些假設進行 guard。 透過使用「動態形狀」,我們可以讓 torch.compile 產生可以接受具有不同形狀的張量輸入的編譯程式碼 - 我們避免了每次形狀不同時都重新編譯。 預設情況下,自動動態形狀已啟用 torch.compile(dynamic=None) - 如果由於形狀不符導致編譯失敗,則會嘗試使用動態形狀重新編譯。 也可以完全啟用動態形狀 dynamic=True 或停用 dynamic=False。
在下面,我們啟用動態形狀,並注意到我們不再需要重新編譯。
import torch
@torch.compile(dynamic=True)
def fn(x):
return x + 1
fn(torch.ones(3, 3))
fn(torch.ones(4, 4))
$ TORCH_LOGS="dynamic,recompiles" python playground.py
create_symbol s0 = 3 for L['x'].size()[0] [2, int_oo] at playground.py:5 in fn (_dynamo/variables/builder.py:2718 in <lambda>), for more info run with TORCHDYNAMO_EXTENDED_DEBUG_CREATE_SYMBOL="s0"
produce_guards
produce_guards
有關動態形狀的更多資訊,請參閱 動態形狀手冊。
記錄工具¶
tlparse / TORCH_TRACE¶
tlparse / TORCH_TRACE 是一對工具,用於產生如下所示的編譯報告:https://web.mit.edu/~ezyang/Public/bhack-20240609-tlparse/index.html。
追蹤非常容易收集。 若要收集追蹤,請使用以下命令執行您的重現命令:
TORCH_TRACE="/tmp/tracedir" python foo.py
pip install tlparse
tlparse /tmp/tracedir
即使您正在執行分散式工作,此方法也有效,為每個排名提供追蹤。 它將打開您的瀏覽器,其中包含類似於上面產生的 HTML。 如果您要為沒有獨立重現的複雜問題提交錯誤報告,您仍然可以透過附加在 /tmp/tracedir 中產生的追蹤日誌來極大地幫助 PyTorch 開發人員。
警告
追蹤日誌包含您的所有模型程式碼。 如果您正在使用的模型很敏感,請勿共用追蹤日誌。 追蹤日誌不包含權重。
tlparse 的輸出主要目標是 PyTorch 開發者,且日誌格式易於上傳並在 GitHub 上分享。不過,即使您不是 PyTorch 開發者,您仍然可以從中提取有用的資訊。我們建議從報告中的內嵌說明文字開始,其中說明了其內容。以下是您可以從 tlparse 獲得的一些見解:
透過查看堆疊 trie,了解編譯了哪些模型程式碼?如果您不熟悉正在編譯的程式碼庫,這特別有用!
有多少個圖形中斷 / 不同的編譯區域?(每個不同的編譯都是一個獨立的顏色編碼區塊,例如 [0/0])。可能發生圖形中斷的幀為淺綠色 [2/4]。如果有很多幀,這很可疑,表示您發生了一些災難性的圖形中斷,或者您的程式碼不太適合
torch.compile。我重新編譯了特定幀多少次?重新編譯很多次的內容看起來會像這樣:[10/0] [10/1] [10/2] - 如果某個東西被重新編譯了很多次,這非常可疑,值得深入研究,即使它不是您問題的根本原因。
是否有編譯錯誤?發生錯誤的幀看起來會像 [0/1]。
我為給定幀產生了哪些中間編譯器產品?例如,您可以查看高階產生的 FX 圖形或產生的 Triton 程式碼。
特定幀是否有相關資訊?您可以在
compilation_metrics中找到這些資訊。
TORCH_LOGS¶
您可以使用 TORCH_LOGS 環境變數來選擇性地啟用 torch.compile 堆疊的某些部分來記錄日誌。實際上,TORCH_LOGS 是 tlparse 的日誌來源。 TORCH_LOGS 環境變數的格式如下:
TORCH_LOGS="<option1>,<option2>,..." python foo.py
有用的高階選項包括:
graph_breaks:記錄使用者程式碼中圖形中斷的位置以及圖形中斷的原因guards:記錄產生的 guardrecompiles:記錄重新編譯的函式以及導致重新編譯的失敗 guarddynamic:記錄與動態形狀相關的內容
此外,您可以使用 torch._logging.set_logs 以程式方式設定日誌記錄選項
import logging
torch._logging.set_logs(graph_breaks=True)
...
更多 TORCH_LOGS 選項詳述如下。如需完整的選項列表,請參閱torch._logging 和 torch._logging.set_logs。
tlparse 與 TORCH_LOGS¶
通常,我們建議在遇到問題時首先使用 tlparse。 tlparse 非常適合於除錯大型模型並獲得模型編譯方式的高階概觀。另一方面,當我們已經知道哪個 torch.compile 元件導致問題時,TORCH_LOGS 更適用於小型範例和細粒度的除錯細節。
簡單的解決方法¶
在這裡,我們描述了一些涉及少量程式碼修改或更改某些 torch.compile 設定來解決 torch.compile 問題的解決方法。
在哪裡應用 torch.compile?¶
我們建議將 torch.compile 應用於最高層級的函式,該函式不會引起過多的問題。通常,它是您的訓練或評估步驟,包含最佳化器但不包含迴圈,您的頂層 nn.Module,或某些子 nn.Module。 torch.compile 尤其不能很好地處理分佈式包裝函式模組(例如 DDP 或 FSDP),因此請考慮將 torch.compile 應用於傳遞給包裝函式的內部模組。
# inference
model = ...
opt_model = torch.compile(model)
for _ in range(N_ITERS):
inp = ...
out = opt_model(inp)
# training
model = ...
opt = torch.optim.Adam(model.parameters())
@torch.compile
def train(mod, data):
opt.zero_grad(True)
pred = mod(data[0])
loss = torch.nn.CrossEntropyLoss()(pred, data[1])
loss.backward()
opt.step()
for _ in range(N_ITERS):
inp = ...
train(model, inp)
# DistributedDataParallel
model = ...
opt_model = torch.compile(model)
model_ddp = DistributedDataParallel(opt_model, ...)
for _ in range(N_ITERS):
inp = ...
out = model_ddp(inp)
停用和抑制錯誤¶
對於某些模型架構,模型中有些部分特別難以編譯 - 要么有很多圖形中斷,要么發生崩潰。您可能想要明確停用模型中的這些有問題的部分,以便您可以將 torch.compile 應用於有效的部件。您可以使用 @torch.compiler.disable 裝飾器來執行此操作。當 torch.compile 嘗試呼叫停用的函式時,它會中斷圖形並跳過追蹤停用的函式,在呼叫後恢復追蹤。預設情況下,從停用的函式進行的所有遞迴呼叫也會被停用。使用 recursive=False 選項以允許編譯遞迴呼叫。
def bad1_inner(...):
# skipped
@torch.compiler.disable
def bad1_outer(...):
# skipped
bad1_inner(...)
def bad2_inner(...)
# traced
@torch.compiler.disable(recursive=False)
def bad2_outer(...):
# skipped
bad2_inner(...)
@torch.compile
def fn(...):
# graph break
bad1_outer(...)
...
# graph break
bad2_outer(...)
例如,我們使用 torch.compiler.disable 在推薦模型中停用稀疏架構上的 torch.compile,因為稀疏架構很難編譯。預處理和日誌記錄函式是通常會導致大量圖形中斷並且無法從編譯中獲得價值的其他函式範例。
如果您遇到編譯器崩潰並且想要繼續,則可以設定 torch._dynamo.config.suppress_errors = True。當編譯器崩潰時,我們將只會跳過追蹤該函式並稍後再試。這不是最佳做法 - 最好最終根據需要手動新增停用註釋。
解決圖形中斷¶
為了最大化最佳化機會,減少圖形中斷的數量非常重要。回想一下,您可以使用 tlparse 或 TORCH_LOGS="graph_breaks" 查看正在發生的圖形中斷。通常,圖形中斷是由於以下原因之一引起的:
您嘗試做一些從根本上無法追蹤的事情,例如資料相關的控制流程。
您嘗試做一些尚未支援的事情。例如,我們目前對追蹤使用內建 Python
inspect模組的程式碼的支援有限。您的程式碼中存在錯誤。例如,您可能嘗試使用不正確的參數數量呼叫函式。
圖形中斷日誌會告訴您使用者程式碼位置以及圖形中斷的原因。不幸的是,如果不深入了解 Dynamo,許多圖形中斷是不可操作的。甚至很難確定這三個原因中的哪一個是導致圖形中斷的真正原因。我們正在努力使圖形中斷訊息更具可操作性。
此外,遺失最佳化機會的影響在不同的圖表斷點之間有所不同。例如,發生在模型 forward 中間的圖表斷點,其負面影響可能大於發生在 forward 開始時的預處理部分的圖表斷點。因此,重點不是要防止每一個斷點,而是要防止那些會造成顯著效能損失的斷點。
如果圖表斷點訊息沒有建議任何動作,您懷疑圖表斷點的原因是 (2),並且您認為該圖表斷點正在造成效能損失,請將該圖表斷點回報為 issue。如果一個函式有很多圖表斷點,請考慮停用該函式的編譯,因為圖表斷點的額外成本可能會變得過高。
以下是一些常見的圖表斷點以及一些解決方法。
資料相依操作¶
torch.compile 會在資料相依操作上產生圖表斷點,例如資料相依的控制流程 (if-statements、具有張量的迴圈) 和直接的張量資料存取 (.item、.data_ptr)。
import torch
@torch.compile
def fn(x):
y = x.sum()
if y > 0:
return x + y.item()
return x - y.item()
fn(torch.ones(3, 3))
$ TORCH_LOGS="graph_breaks" python playground.py
Graph break in user code at /data/users/williamwen/pytorch/playground.py:6
Reason: Data-dependent jump
User code traceback:
File "/data/users/williamwen/pytorch/playground.py", line 6, in fn
if y > 0:
Graph break in user code at /data/users/williamwen/pytorch/playground.py:7
Reason: Unsupported: Tensor.item
User code traceback:
File "/data/users/williamwen/pytorch/playground.py", line 7, in torch_dynamo_resume_in_fn_at_6
return x + y.item()
Traceback (most recent call last):
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 616, in wrapper
return inner_fn(self, inst)
^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 2288, in CALL
self._call(inst)
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 2282, in _call
self.call_function(fn, args, kwargs)
File "/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py", line 838, in call_function
self.push(fn.call_function(self, args, kwargs)) # type: ignore[arg-type]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/variables/misc.py", line 1038, in call_function
return self.obj.call_method(tx, self.name, args, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/variables/tensor.py", line 527, in call_method
result = handler_method(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/williamwen/pytorch/torch/_dynamo/variables/tensor.py", line 773, in method_item
unimplemented("Tensor.item")
File "/data/users/williamwen/pytorch/torch/_dynamo/exc.py", line 304, in unimplemented
raise Unsupported(msg, case_name=case_name)
torch._dynamo.exc.Unsupported: Tensor.item
這些圖表斷點的通用解決方法是避免執行資料相依操作。一些特定的解決方法是
如果您的控制流程實際上不依賴於資料值,請考慮修改您的程式碼以對常數執行控制流程。
# old
x = torch.randn(3, 3)
@torch.compile
def fn(y):
if x.sum() > 0:
return y + x
else:
return y - x
# new
x = torch.randn(3, 3)
cond = (x.sum() > 0).item()
@torch.compile
def fn(y):
if cond:
return y + x
else:
return y - x
使用高階操作,例如
torch.cond(https://pytorch.dev.org.tw/docs/main/cond.html) 來取代資料相依的控制流程
# old
@torch.compile
def fn(x):
if x.sum() > 0:
return x + 1
return x - 1
# new
@torch.compile
def fn(x):
return torch.cond(
x.sum() > 0,
lambda x: x + 1,
lambda x: x - 1,
(x,),
)
如果您有
.item()呼叫,請嘗試torch._dynamo.config.capture_scalar_outputs = True或TORCHDYNAMO_CAPTURE_SCALAR_OUTPUTS=1將函式中有問題的部分包裝在自定義 op 中
自定義 Ops¶
如果您有 torch.compile 難以追蹤的程式碼,無論是因為缺少支援還是根本的不相容,您可以考慮將有問題的程式碼包裝在自定義 op 中。
自定義 op 需要一些額外的工作才能與 torch.compile 相容。有關更多詳細信息,請參閱 https://pytorch.dev.org.tw/tutorials/advanced/custom_ops_landing_page.html。
列印¶
列印/記錄/發出警告將會導致圖表斷點。如果您有一個進行大量記錄呼叫的函式,例如,一個記錄關於訓練迭代資料的函式,請考慮對其應用 torch.compiler.disable。
或者,您可以嘗試使用 torch._dynamo.config.reorderable_logging_functions。此配置用於重新排序記錄函式,以便它們在追蹤函式的末尾被呼叫,從而避免圖表斷點。但是,如果發生突變,例如,記錄的內容可能會有所不同。
import torch
torch._dynamo.config.reorderable_logging_functions.add(print)
@torch.compile
def fn(x):
x += 1
print("log!")
return torch.sin(x)
fn(torch.ones(3, 3))
$ TORCH_LOGS="graph_breaks" python playground.py
log!
不正確的程式碼¶
您的程式碼可能不正確,或者遇到來自 torch.compile 外部的錯誤。在下面的程式碼中,我們在 torch.sin 呼叫中輸入錯誤,提供了額外的參數。
import torch
@torch.compile
def fn(x):
y = torch.sin(x, x)
return y
fn(torch.ones(3, 3))
$ TORCH_LOGS="graph_breaks" python playground.py
Graph break in user code at /data/users/williamwen/pytorch/playground.py:5
Reason: Unsupported: TypeError <built-in method sin of type object at 0x7fd6fd764600>: sin() takes 1 positional argument but 2 were given
User code traceback:
File "/data/users/williamwen/pytorch/playground.py", line 5, in fn
y = torch.sin(x, x)
...
很難從日誌中判斷錯誤是由您的程式碼引起的,還是因為 torch.compile 的錯誤。為了區分,我們建議嘗試在沒有 torch.compile 的情況下運行您的程式碼,看看是否仍然會遇到錯誤。
處理重新編譯¶
您可以使用 tlparse 或 TORCH_LOGS=recompiles 來檢視重新編譯及其原因。
是否啟用動態形狀?¶
由於形狀不匹配而導致的重新編譯採用以下形式
tensor 'L['x']' size mismatch at index 0. expected 3, actual 4
確保 torch.compile 的 dynamic 選項未設定為 False。預設選項 dynamic=None 只會在第一次編譯後嘗試動態形狀。您可以設定 dynamic=True 來預先編譯成盡可能動態的形狀。
有關動態形狀的更多資訊,請參閱 動態形狀手冊。
變更快取大小限制¶
函式可以重新編譯的次數有一個限制,由 torch._dynamo.config.cache_size_limit 和 torch._dynamo.config.accumulated_cache_size_limit 決定。如果超過任一限制,我們將不會再次嘗試編譯該函式,而是會 eager 執行該函式。torch.compile 也會發出警告,其中包含受影響的函式以及達到哪個限制。在下面的範例中,每個函式呼叫都會導致重新編譯的嘗試。當我們達到快取大小限制 (8) 時,我們將停止嘗試重新編譯。
import torch
@torch.compile(dynamic=False)
def fn(x):
return x + 1
for i in range(1, 10):
fn(torch.ones(i))
$ python playground.py
torch._dynamo hit config.cache_size_limit (8)
function: 'fn' (/data/users/williamwen/pytorch/playground.py:5)
last reason: 0/0: tensor 'L['x']' size mismatch at index 0. expected 1, actual 9
如果您知道重新編譯的次數有一個合理的常數上限,您可以提高快取大小限制。如果重新編譯的成本超過編譯的好處,您可以考慮降低快取大小限制。
用張量包裝常數¶
預設情況下,int / float 變數被視為常數,並受到如此的保護。在下面的範例中,我們對每個函式呼叫都有一個重新編譯。
import torch
@torch.compile
def fn(x, c):
return x + c
for i in range(1, 10):
fn(torch.ones(i), 0.5 + i)
$ TORCH_LOGS="recompiles" python playground.py
Recompiling function fn in /data/users/williamwen/pytorch/playground.py:3
triggered by the following guard failure(s):
- 0/7: L['c'] == 8.5
- 0/6: L['c'] == 7.5
- 0/5: L['c'] == 6.5
- 0/4: L['c'] == 5.5
- 0/3: L['c'] == 4.5
- 0/2: L['c'] == 3.5
- 0/1: L['c'] == 2.5
- 0/0: L['c'] == 1.5
torch._dynamo hit config.cache_size_limit (8)
function: 'fn' (/data/users/williamwen/pytorch/playground.py:3)
last reason: 0/0: L['c'] == 1.5
特別是,對於 LR scheduler,使用常數初始化可能會導致重新編譯
import torch
mod = torch.nn.Linear(3, 3)
opt = torch.optim.Adam(mod.parameters(), lr=0.01)
sched = torch.optim.lr_scheduler.ExponentialLR(opt, 0.9)
@torch.compile
def fn(inp):
opt.zero_grad(True)
out = mod(inp).sum()
out.backward()
opt.step()
sched.step()
for i in range(1, 10):
fn(torch.ones(3, 3))
$ TORCH_LOGS="recompiles" python playground.py
Recompiling function step in /data/users/williamwen/pytorch/torch/optim/adam.py:189
triggered by the following guard failure(s):
- 3/7: L['self'].param_groups[0]['lr'] == 0.004782969000000002
- 3/6: L['self'].param_groups[0]['lr'] == 0.005314410000000002
- 3/5: L['self'].param_groups[0]['lr'] == 0.005904900000000002
- 3/4: L['self'].param_groups[0]['lr'] == 0.006561000000000002
- 3/3: L['self'].param_groups[0]['lr'] == 0.007290000000000001
- 3/2: L['self'].param_groups[0]['lr'] == 0.008100000000000001
- 3/1: L['self'].param_groups[0]['lr'] == 0.009000000000000001
- 3/0: L['self'].param_groups[0]['lr'] == 0.01
torch._dynamo hit config.cache_size_limit (8)
function: 'step' (/data/users/williamwen/pytorch/torch/optim/adam.py:189)
last reason: 3/0: L['self'].param_groups[0]['lr'] == 0.01
在這兩個範例中,我們可以將 float 變數包裝在張量中,以防止重新編譯。
# first example
for i in range(1, 10):
fn(torch.ones(i), torch.tensor(0.5 + i))
# second example
opt = torch.optim.Adam(mod.parameters(), lr=torch.tensor(0.01))
sched = torch.optim.lr_scheduler.ExponentialLR(opt, torch.tensor(0.9))
回報 Issue¶
如果上面提供的解決方法不足以讓 torch.compile 正常工作,那麼您應該考慮向 PyTorch 回報 issue。但是您可以做一些事情來讓我們的生活更加輕鬆。
消融¶
使用 torch.compile 的 backend= 選項,檢查 torch.compile 堆疊的哪個元件導致了問題。特別是,嘗試
torch.compile(fn, backend="eager"),這僅運行 TorchDynamo,torch.compile的圖表捕獲元件。torch.compile(fn, backend="aot_eager"),這運行 TorchDynamo 和 AOTAutograd,它們還會在編譯期間產生向後圖。torch.compile(fn, backend="aot_eager_decomp_partition"),此設定會執行 TorchDynamo 和 AOTAutograd,並進行運算子分解/分割。torch.compile(fn, backend="inductor"),此設定會執行 TorchDynamo、AOTAutograd 和 TorchInductor,TorchInductor 是一個後端 ML 編譯器,可產生已編譯的核心。
如果只有在使用 Inductor 後端時才會失敗,您可以額外測試各種 Inductor 模式
torch.compile(fn, backend="inductor", mode="default")torch.compile(fn, backend="inductor", mode="reduce-overhead")torch.compile(fn, backend="inductor", mode="max-autotune")
您也可以檢查動態形狀是否導致任何後端出現問題
torch.compile(fn, dynamic=True)(始終使用動態形狀)torch.compile(fn, dynamic=False)(永遠不要使用動態形狀)torch.compile(fn, dynamic=None)(自動動態形狀)
二分法 (Bisecting)¶
您是否嘗試過最新的 nightly 版本?過去某個版本能正常運作,但現在卻不行了嗎?您可以使用二分法來確定您的問題最早出現在哪個 nightly 版本中嗎?二分法對於效能、準確性或編譯時間的衰退特別有幫助,因為這些問題的根源並不明顯。
建立重現 (Reproducer)¶
建立重現需要花費大量精力,如果您沒有時間這樣做,完全沒有問題。但是,如果您是一位對 torch.compile 內部結構不熟悉的熱心使用者,建立獨立的重現可以極大地影響我們修復錯誤的能力。如果沒有重現,您的錯誤報告必須包含足夠的資訊,以便我們識別問題的根本原因並從頭開始編寫重現。
以下是重現清單,依偏好程度從高到低排序
獨立、小型重現: 一個沒有外部依賴、程式碼少於 100 行的腳本,執行時可以重現問題。
獨立、大型重現: 即使它很大,但能夠獨立運作也是一個巨大的優勢!
具有可管理依賴項的非獨立重現: 例如,如果您可以在執行
pip install transformers後執行腳本來重現問題,這就是可管理的。 我們很可能會執行它並進行調查。需要大量設定的非獨立重現: 這可能涉及下載資料集、多個環境設定步驟,或需要 Docker 映像的特定系統庫版本。設定越複雜,我們就越難以重新建立環境。
注意
Docker 簡化了設定,但也使環境變更變得複雜,因此它不是一個完美的解決方案,但如果必要,我們會使用它。
在某種程度上,可以在單個進程中運行的重現優於需要多進程訓練的重現(但再次聲明,如果您只有一個多進程重現,我們也會接受!)。
此外,以下是一個非詳盡的清單,列出了您可以在問題中檢查並嘗試在重現中複製的各個方面
Autograd。您是否有
requires_grad=True的張量輸入?您是否在輸出上呼叫了backward()?動態形狀。您是否設定了
dynamic=True?或者您是否使用不同的形狀多次執行了測試程式碼?自訂運算子。實際工作流程中是否涉及自訂運算子?您可以使用 Python 自訂運算子 API 複製它的一些重要特性嗎?
設定。您是否設定了所有相同的設定?這包括
torch._dynamo.config和torch._inductor.config設定,以及torch.compile的引數,如backend/mode。上下文管理器。您是否複製了任何作用中的上下文管理器?這可能是
torch.no_grad、自動混合精度、TorchFunctionMode/TorchDispatchMode、activation checkpointing、編譯後的 autograd 等。張量子類別。是否涉及張量子類別?
最小化器 (Minifier)¶
最小化器是一個早期的 torch.compile 工具,它在給定一個嘗試運行或編譯時會崩潰的 FX 圖的情況下,找到一個也會崩潰的子圖,並輸出執行該子圖操作的程式碼。 本質上,最小化器為某種類型的 torch.compile 相關崩潰找到一個最小的重現。 這假設我們能夠成功地追蹤程式碼。
不幸的是,現在大多數時候,最小化器無法按預期運作,可能需要替代方法。 這可能是因為可以通過這種方式自動重現的錯誤通常更容易修復,並且已經得到解決,留下更複雜的問題,這些問題不容易重現。 但是,嘗試使用最小化器非常簡單,因此即使它可能不會成功,也值得一試。
可以在此處找到操作最小化器的說明。 如果編譯器崩潰,您可以設定 TORCHDYNAMO_REPRO_AFTER="dynamo" 或 TORCHDYNAMO_REPRO_AFTER="aot"。aot 選項更有可能成功,儘管它可能無法識別 AOTAutograd 問題。 這將產生 repro.py 檔案,這可能有助于診斷問題。 對於與準確性相關的問題,請考慮設定 TORCHDYNAMO_REPRO_LEVEL=4。 請注意,這可能並不總是能夠成功識別有問題的子圖。
更深入的除錯¶
本節提供用於獨立除錯 torch.compile 問題或更深入了解 torch.compile 堆疊的工具和技術。這些方法比上述方法更複雜,並且 PyTorch 開發人員經常使用它們來除錯實際的 torch.compile 問題。
以下是堆疊的高階概述:
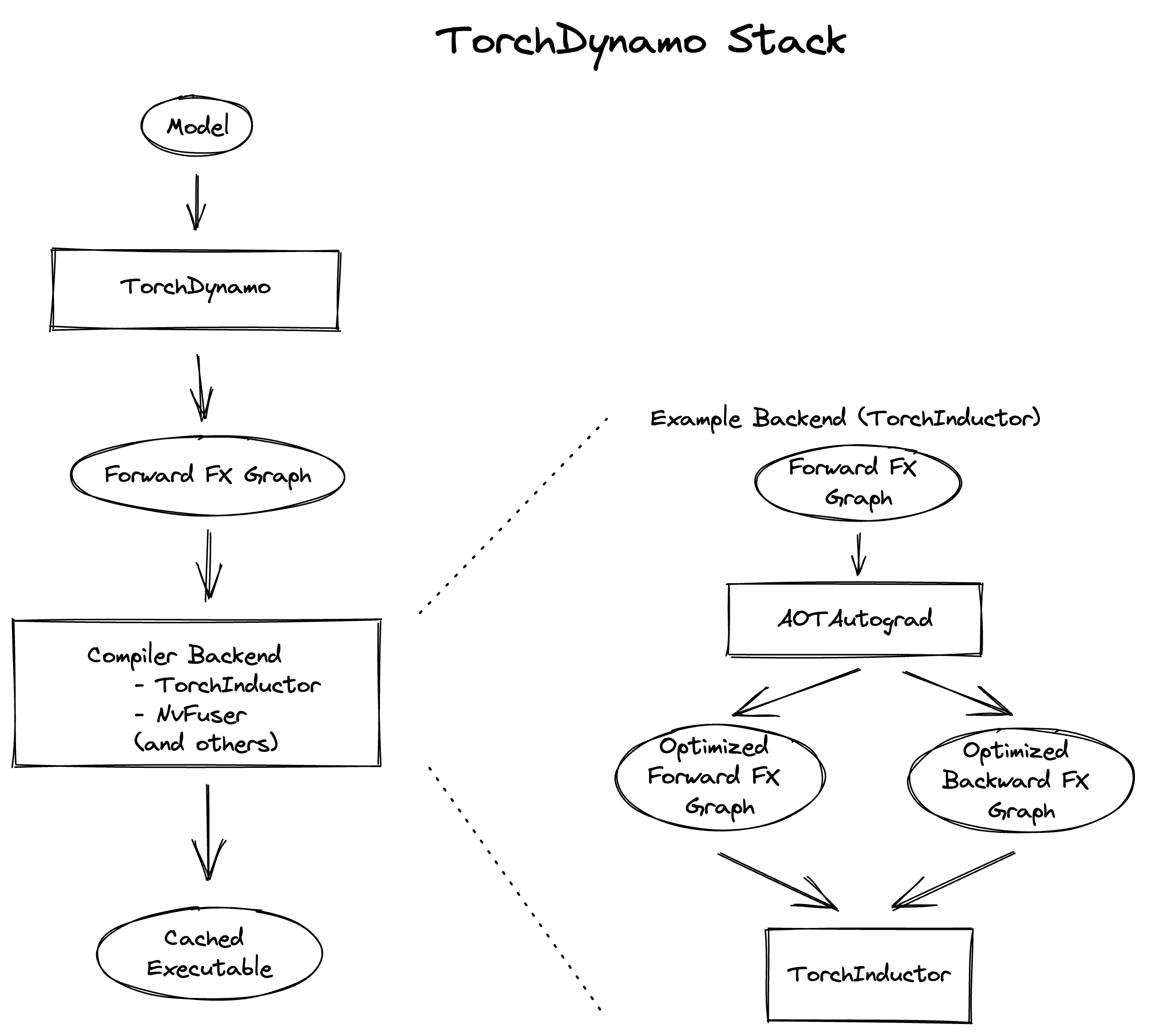
堆疊包含三個主要組件:TorchDynamo、AOTAutograd 和 Inductor。我們的除錯策略涉及首先識別錯誤發生的組件,然後單獨除錯該組件。要確定哪個組件負責該問題,請參閱上面 報告問題 下的 消融 部分。有關除錯特定組件的指導,請參閱以下各節。
TorchDynamo¶
記錄 Dynamo 正在追蹤的內容¶
TORCH_LOGS=trace_bytecode 選項使您可以查看 Dynamo 正在追蹤的精確位元組碼指令,以及 Python 解釋器堆疊的符號表示。當遇到圖形中斷或崩潰時,建議檢查最後幾個追蹤的位元組碼指令。
您也可以使用 TORCH_LOGS=trace_source 來查看 Dynamo 正在追蹤的原始碼行。將其與 trace_bytecode 結合使用可以查看每個追蹤的位元組碼指令對應的原始碼行。
最後,您可以使用 TORCH_LOGS=graph_code 來查看代表 Dynamo 追蹤的 FX 圖的 Python 程式碼。您可以查看此程式碼以仔細檢查是否正在追蹤正確的運算。
import torch
def g(x, y):
return x + y
@torch.compile(backend="eager")
def f(x):
x = torch.sin(x)
x = g(x, x)
return x
f(torch.ones(3, 3))
$ TORCH_LOGS="trace_bytecode,trace_source,graph_code" python playground.py
TRACE starts_line /data/users/williamwen/pytorch/playground.py:6 in f ()
@torch.compile(backend="eager")
TRACE RESUME 0 []
TRACE starts_line /data/users/williamwen/pytorch/playground.py:8 in f (f)
x = torch.sin(x)
TRACE LOAD_GLOBAL torch []
TRACE LOAD_ATTR sin [NullVariable(), PythonModuleVariable(<module 'torch' from '/data/users/williamwen/pytorch/torch/__init__.py'>)]
TRACE LOAD_FAST x [NullVariable(), TorchInGraphFunctionVariable(<built-in method sin of type object at 0x7f00f6964600>)]
TRACE CALL 1 [NullVariable(), TorchInGraphFunctionVariable(<built-in method sin of type object at 0x7f00f6964600>), LazyVariableTracker()]
TRACE STORE_FAST x [TensorVariable()]
TRACE starts_line /data/users/williamwen/pytorch/playground.py:9 in f (f)
x = g(x, x)
TRACE LOAD_GLOBAL g []
TRACE LOAD_FAST x [NullVariable(), UserFunctionVariable()]
TRACE LOAD_FAST x [NullVariable(), UserFunctionVariable(), TensorVariable()]
TRACE CALL 2 [NullVariable(), UserFunctionVariable(), TensorVariable(), TensorVariable()]
TRACE starts_line /data/users/williamwen/pytorch/playground.py:3 in g (g) (inline depth: 1)
def g(x, y):
TRACE RESUME 0 []
TRACE starts_line /data/users/williamwen/pytorch/playground.py:4 in g (g) (inline depth: 1)
return x + y
TRACE LOAD_FAST x []
TRACE LOAD_FAST y [TensorVariable()]
TRACE BINARY_OP 0 [TensorVariable(), TensorVariable()]
TRACE RETURN_VALUE None [TensorVariable()]
TRACE STORE_FAST x [TensorVariable()]
TRACE starts_line /data/users/williamwen/pytorch/playground.py:10 in f (f)
return x
TRACE LOAD_FAST x []
TRACE RETURN_VALUE None [TensorVariable()]
TRACED GRAPH
===== __compiled_fn_1 =====
/data/users/williamwen/pytorch/torch/fx/_lazy_graph_module.py class GraphModule(torch.nn.Module):
def forward(self, L_x_: "f32[3, 3][3, 1]cpu"):
l_x_ = L_x_
# File: /data/users/williamwen/pytorch/playground.py:8 in f, code: x = torch.sin(x)
x: "f32[3, 3][3, 1]cpu" = torch.sin(l_x_); l_x_ = None
# File: /data/users/williamwen/pytorch/playground.py:4 in g, code: return x + y
x_1: "f32[3, 3][3, 1]cpu" = x + x; x = None
return (x_1,)
為 Dynamo 追蹤設定中斷點¶
有時在 Dynamo/使用者程式碼中插入中斷點,以查看 Dynamo 在追蹤使用者程式碼時的狀態會很有幫助。不幸的是,以正常的 Python 方式插入中斷點將導致 TorchDynamo 中的圖形中斷,因此我們將無法在我們打算設定中斷點的位置查看 Dynamo 的狀態。
設定中斷點的第一種方法是在 Dynamo 原始碼中插入它。建議放置中斷點的三個位置是:
在
torch/_dynamo/symbolic_convert.py中,在以有問題的位元組碼指令命名的函式處設定中斷點,例如def CALL_FUNCTION和def STORE_ATTR。您可以根據輸入有條件地設定中斷點,例如指令的argval,或堆疊頂部物件的名稱,因為某些位元組碼運算碼經常被使用。在圖形中斷或錯誤的起源處設定中斷點。通常,圖形中斷是從對
unimplemented(...)的呼叫發出的。在
torch/_dynamo/variables/builder.py, function:_wrap中設定中斷點。您可能需要根據輸入有條件地設定中斷點。此函式確定如何以符號表示給定值。如果您懷疑某個值表示不正確,請考慮在此處設定中斷點。
插入中斷點的第二種方法是使用 torch._dynamo.comptime.comptime.breakpoint。
from torch._dynamo.comptime import comptime
@torch.compile
def f(...):
...
comptime.breakpoint()
...
comptime 中斷點很方便,因為它使您能夠檢查正在追蹤的使用者程式碼中特定位置的 Dynamo 狀態。它不需要您在 Dynamo 原始碼中插入中斷點,也不需要您根據變數有條件地設定中斷點。
觸發 comptime 中斷點時,您可以執行以下操作:
ctx.print_bt()列印使用者堆疊追蹤ctx.print_locals()列印所有目前的區域變數ctx.print_graph()列印目前追蹤的圖ctx.disas()列印目前追蹤函式的位元組碼使用標準
pdb指令,例如bt/u/d/n/s/r,- 您可以向上移動pdb堆疊以檢查更多 Dynamo 內部結構
import torch
from torch._dynamo.comptime import comptime
@torch.compile(backend="eager")
def f(x):
y = x + 1
comptime.breakpoint()
y = y + 1
return y
f(torch.ones(3, 3))
$ python playground.py
--Return--
> /data/users/williamwen/pytorch/torch/_dynamo/comptime.py(392)inner()->None
-> builtins.breakpoint()
(Pdb) ctx.print_bt()
File "/data/users/williamwen/pytorch/playground.py", line 7, in f
comptime.breakpoint()
(Pdb) ctx.print_locals()
x = FakeTensor(..., size=(3, 3))
y = FakeTensor(..., size=(3, 3))
(Pdb) bt
...
/data/users/williamwen/pytorch/torch/_dynamo/symbolic_convert.py(826)call_function()
-> self.push(fn.call_function(self, args, kwargs)) # type: ignore[arg-type]
/data/users/williamwen/pytorch/torch/_dynamo/variables/misc.py(331)call_function()
-> func(ComptimeContext(tx))
> /data/users/williamwen/pytorch/torch/_dynamo/comptime.py(392)inner()->None
-> builtins.breakpoint()
(Pdb) ctx.print_graph()
def forward(self, L_x_: "f32[3, 3]"):
l_x_ = L_x_
# File: /data/users/williamwen/pytorch/playground.py:6 in f, code: y = x + 1
y: "f32[3, 3]" = l_x_ + 1; l_x_ = y = None
AOTAutograd¶
AOTAutograd 錯誤通常很難除錯 - 我們建議您直接提交問題。AOTAutograd 記錄輸出主要有助於查看 Inductor 的輸入是什麼。
TORCH_LOGS 選項摘要¶
有用的 TORCH_LOGS 選項摘要如下:
選項 |
描述 |
|---|---|
+all |
輸出所有 |
+dynamo |
輸出 TorchDynamo 的除錯日誌 |
+aot |
輸出 AOTAutograd 的除錯日誌 |
+inductor |
從 TorchInductor 輸出除錯日誌 |
dynamic |
輸出動態形狀的日誌 |
graph_code |
輸出 Dynamo 產生的 FX 圖表的 Python 程式碼 |
graph_sizes |
輸出 Dynamo 產生的 FX 圖表的張量大小 |
trace_bytecode |
輸出 Dynamo 正在追蹤的位元組碼指令,以及 Dynamo 正在追蹤的符號解釋器堆疊 |
trace_source |
輸出 Dynamo 目前正在追蹤的原始碼中的程式碼行 |
bytecode |
輸出 Dynamo 產生的位元組碼 |
guards |
輸出產生的 guards |
recompiles |
輸出重新編譯的原因 (僅顯示第一個失敗的 guard 檢查) |
recompiles_verbose |
輸出發生重新編譯時所有失敗的 guard 檢查 |
aot_graphs |
輸出 AOTAutograd 產生的圖表 |
aot_joint_graphs |
輸出 AOTAutograd 產生的聯合正向-反向圖表 |
output_code |
輸出 Inductor 產生的程式碼 |
kernel_code |
輸出 Inductor 針對每個核心產生的程式碼 |
schedule |
輸出 Inductor 排程日誌 |
perf_hints |
輸出 Inductor 效能提示日誌 |
fusion |
輸出 Inductor 融合日誌 |
如需選項的完整清單,請參閱 torch._logging 和 torch._logging.set_logs。
