


注意
跳到結尾以下載完整的範例程式碼。
遞迴 DQN:訓練遞迴策略¶
如何在 TorchRL 的 Actor 中加入 RNN
如何將基於記憶體的策略與重播緩衝區和損失模組一起使用
PyTorch v2.0.0
gym[mujoco]
tqdm
概述¶
基於記憶體的策略不僅在觀察結果是部分可觀察的情況下至關重要,而且在必須考慮時間維度才能做出明智的決策時也至關重要。
長期以來,遞迴神經網路一直是基於記憶體的策略的熱門工具。 其想法是在兩個連續步驟之間將遞迴狀態保存在記憶體中,並將其與目前的觀察結果一起用作策略的輸入。
本教學示範如何使用 TorchRL 在策略中加入 RNN。
主要學習內容
在 TorchRL 的 Actor 中加入 RNN;
將基於記憶體的策略與重播緩衝區和損失模組一起使用。
在 TorchRL 中使用 RNN 的核心思想是使用 TensorDict 作為從一個步驟到另一個步驟的隱藏狀態的資料載體。 我們將建立一個策略,該策略從目前的 TensorDict 中讀取先前的遞迴狀態,並將目前的遞迴狀態寫入下一個狀態的 TensorDict 中
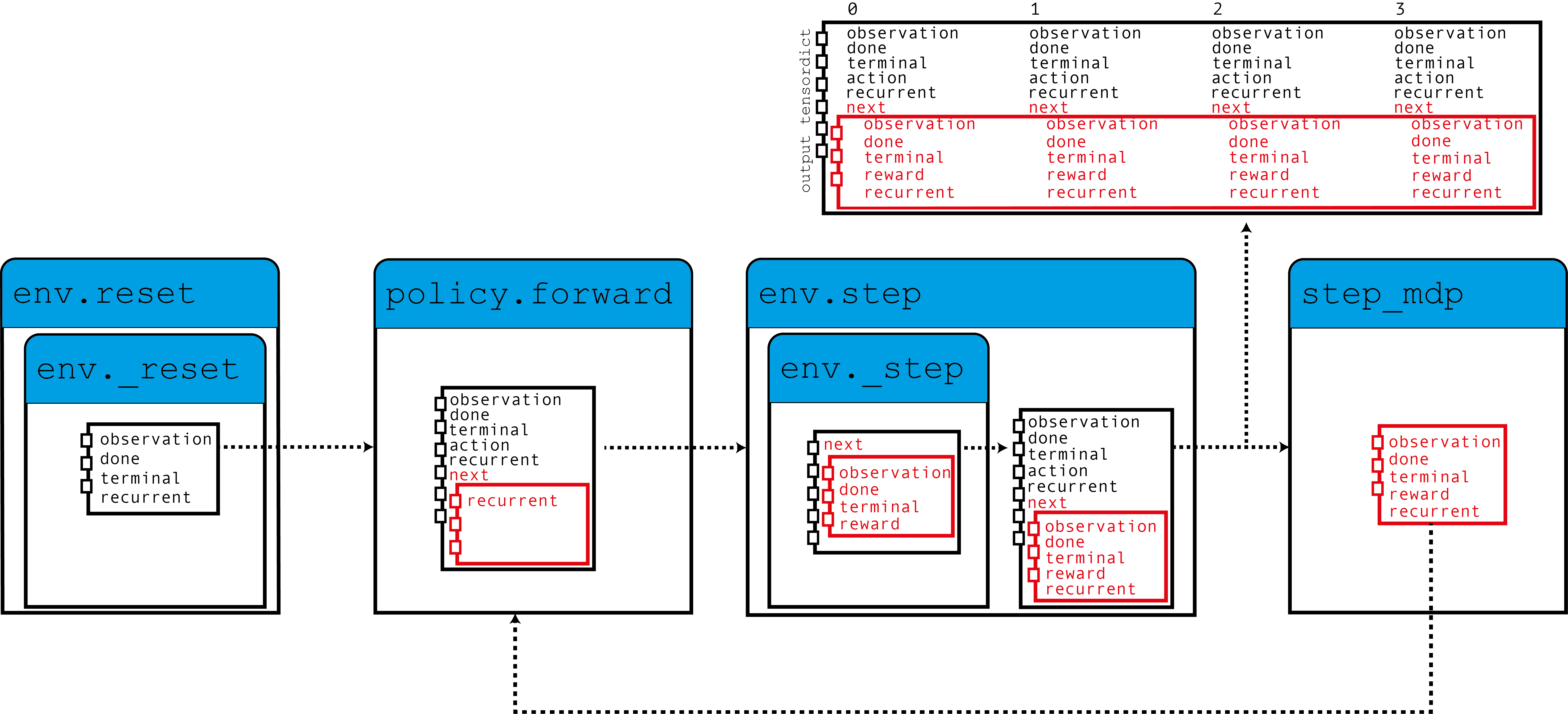
如圖所示,我們的環境使用歸零的遞迴狀態來填入 TensorDict,這些狀態由策略與觀察結果一起讀取,以產生一個動作,以及將用於下一步的遞迴狀態。 當呼叫 step_mdp() 函數時,下一個狀態的遞迴狀態會被帶到目前的 TensorDict。 讓我們看看這在實務中是如何實作的。
如果您在 Google Colab 中執行此操作,請確保安裝以下相依性
!pip3 install torchrl
!pip3 install gym[mujoco]
!pip3 install tqdm
設定¶
import torch
import tqdm
from tensordict.nn import (
TensorDictModule as Mod,
TensorDictSequential,
TensorDictSequential as Seq,
)
from torch import nn
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyMemmapStorage, TensorDictReplayBuffer
from torchrl.envs import (
Compose,
ExplorationType,
GrayScale,
InitTracker,
ObservationNorm,
Resize,
RewardScaling,
set_exploration_type,
StepCounter,
ToTensorImage,
TransformedEnv,
)
from torchrl.envs.libs.gym import GymEnv
from torchrl.modules import ConvNet, EGreedyModule, LSTMModule, MLP, QValueModule
from torchrl.objectives import DQNLoss, SoftUpdate
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
環境¶
與往常一樣,第一步是建立我們的環境:它有助於我們定義問題並相應地建立策略網路。 在本教學中,我們將執行 CartPole gym 環境的單個基於像素的實例,其中包含一些自訂轉換:轉換為灰階、調整大小為 84x84、縮小獎勵和正規化觀察結果。
注意
StepCounter 轉換是附屬的。 由於 CartPole 任務的目標是使軌跡盡可能長,因此計算步數可以幫助我們追蹤策略的效能。
兩個轉換對於本教學的目的而言很重要
InitTracker將會透過在 TensorDict 中新增一個"is_init"布林遮罩,來標記對reset()的呼叫。這個遮罩會追蹤哪些步驟需要重置 RNN 隱藏狀態。TensorDictPrimer轉換器更偏技術性。使用 RNN 策略並非必要。然而,它會指示環境(以及隨後的收集器)預期會有額外的鍵。一旦新增後,對 env.reset() 的呼叫將會用零張量填充 primer 中指示的條目。由於知道這些張量是策略所預期的,收集器會在收集期間傳遞它們。最終,我們會將隱藏狀態儲存在重播緩衝區中,這將有助於我們引導損失模組中 RNN 運算的計算(否則將以 0 開始)。總結:不包含這個轉換器不會對我們策略的訓練產生巨大的影響,但它會使遞迴鍵從收集的資料和重播緩衝區中消失,進而導致稍微不那麼理想的訓練。幸運的是,我們提出的LSTMModule配備了一個輔助方法來為我們建構該轉換器,所以我們可以等到建構它!
env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, device=device),
Compose(
ToTensorImage(),
GrayScale(),
Resize(84, 84),
StepCounter(),
InitTracker(),
RewardScaling(loc=0.0, scale=0.1),
ObservationNorm(standard_normal=True, in_keys=["pixels"]),
),
)
如同往常,我們需要手動初始化我們的正規化常數
env.transform[-1].init_stats(1000, reduce_dim=[0, 1, 2], cat_dim=0, keep_dims=[0])
td = env.reset()
策略¶
我們的策略將有 3 個組成部分:一個 ConvNet 主幹網路、一個 LSTMModule 記憶體層,以及一個淺層 MLP 區塊,它將 LSTM 輸出映射到動作值。
卷積網路¶
我們建構一個卷積網路,並搭配一個 torch.nn.AdaptiveAvgPool2d,它會將輸出壓縮成一個大小為 64 的向量。ConvNet 可以協助我們完成這件事
feature = Mod(
ConvNet(
num_cells=[32, 32, 64],
squeeze_output=True,
aggregator_class=nn.AdaptiveAvgPool2d,
aggregator_kwargs={"output_size": (1, 1)},
device=device,
),
in_keys=["pixels"],
out_keys=["embed"],
)
我們在批次的資料上執行第一個模組,以收集輸出向量的大小
n_cells = feature(env.reset())["embed"].shape[-1]
LSTM 模組¶
TorchRL 提供一個專門的 LSTMModule 類別,將 LSTM 整合到您的程式碼庫中。它是一個 TensorDictModuleBase 子類別:因此,它有一組 in_keys 和 out_keys,表示在模組執行期間,預期要讀取和寫入/更新的值。該類別帶有可自訂的預定義值,用於這些屬性,以方便其建構。
注意
使用限制:該類別支援幾乎所有 LSTM 功能,例如 dropout 或多層 LSTM。但是,為了遵守 TorchRL 的慣例,這個 LSTM 的 batch_first 屬性必須設定為 True,這不是 PyTorch 中的預設值。但是,我們的 LSTMModule 更改了這種預設行為,所以我們用原生呼叫就可以正常運作。
此外,LSTM 不能將 bidirectional 屬性設定為 True,因為這在線上設定中將無法使用。在這種情況下,預設值是正確的。
lstm = LSTMModule(
input_size=n_cells,
hidden_size=128,
device=device,
in_key="embed",
out_key="embed",
)
讓我們看看 LSTM 模組類別,特別是它的 in 和 out_keys
print("in_keys", lstm.in_keys)
print("out_keys", lstm.out_keys)
in_keys ['embed', 'recurrent_state_h', 'recurrent_state_c', 'is_init']
out_keys ['embed', ('next', 'recurrent_state_h'), ('next', 'recurrent_state_c')]
我們可以發現這些值包含我們指定為 in_key(和 out_key)的鍵,以及遞迴鍵名稱。out_keys 前面加上了 "next" 字首,表示它們需要寫入 "next" TensorDict 中。我們使用這個慣例(可以透過傳遞 in_keys/out_keys 參數來覆蓋),以確保對 step_mdp() 的呼叫將會將遞迴狀態移動到根 TensorDict,使其在後續呼叫期間可供 RNN 使用(請參閱簡介中的圖)。
如前所述,我們還有一個可選的轉換器要新增到我們的環境中,以確保遞迴狀態傳遞到緩衝區。make_tensordict_primer() 方法正是這樣做的
env.append_transform(lstm.make_tensordict_primer())
TransformedEnv(
env=GymEnv(env=CartPole-v1, batch_size=torch.Size([]), device=cpu),
transform=Compose(
ToTensorImage(keys=['pixels']),
GrayScale(keys=['pixels']),
Resize(w=84, h=84, interpolation=InterpolationMode.BILINEAR, keys=['pixels']),
StepCounter(keys=[]),
InitTracker(keys=[]),
RewardScaling(loc=0.0000, scale=0.1000, keys=['reward']),
ObservationNorm(keys=['pixels']),
TensorDictPrimer(primers=Composite(
recurrent_state_h: UnboundedContinuous(
shape=torch.Size([1, 128]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
recurrent_state_c: UnboundedContinuous(
shape=torch.Size([1, 128]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([])), default_value={'recurrent_state_h': 0.0, 'recurrent_state_c': 0.0}, random=None)))
就這樣!我們可以列印環境,以檢查在新增 primer 後一切看起來是否正常
print(env)
TransformedEnv(
env=GymEnv(env=CartPole-v1, batch_size=torch.Size([]), device=cpu),
transform=Compose(
ToTensorImage(keys=['pixels']),
GrayScale(keys=['pixels']),
Resize(w=84, h=84, interpolation=InterpolationMode.BILINEAR, keys=['pixels']),
StepCounter(keys=[]),
InitTracker(keys=[]),
RewardScaling(loc=0.0000, scale=0.1000, keys=['reward']),
ObservationNorm(keys=['pixels']),
TensorDictPrimer(primers=Composite(
recurrent_state_h: UnboundedContinuous(
shape=torch.Size([1, 128]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
recurrent_state_c: UnboundedContinuous(
shape=torch.Size([1, 128]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([])), default_value={'recurrent_state_h': 0.0, 'recurrent_state_c': 0.0}, random=None)))
MLP¶
我們使用單層 MLP 來表示將用於我們策略的動作值。
並用零填充偏差
mlp[-1].bias.data.fill_(0.0)
mlp = Mod(mlp, in_keys=["embed"], out_keys=["action_value"])
使用 Q 值來選擇一個動作¶
我們策略的最後一部分是 Q-Value 模組。Q-Value 模組 QValueModule 將讀取由我們的 MLP 產生的 "action_values" 鍵,並從中收集具有最大值的動作。我們唯一需要做的是指定動作空間,這可以通過傳遞字符串或動作規範來完成。這允許我們使用 Categorical(有時稱為「稀疏」)編碼或其 one-hot 版本。
qval = QValueModule(action_space=None, spec=env.action_spec)
注意
TorchRL 也提供了一個包裝類別 torchrl.modules.QValueActor,它將一個模組與一個 QValueModule 一起包裝在一個 Sequential 中,就像我們在這裡顯式地做的一樣。這樣做沒有什麼優勢,而且過程也不太透明,但最終結果將與我們在這裡所做的相似。
我們現在可以將所有東西放在一個 TensorDictSequential 中
stoch_policy = Seq(feature, lstm, mlp, qval)
DQN 是一個確定性演算法,探索是其中至關重要的一部分。我們將使用一個 \(\epsilon\)-greedy 策略,epsilon 為 0.2,並逐漸衰減至 0。這種衰減是通過調用 step() 來實現的(請參閱下面的訓練迴圈)。
exploration_module = EGreedyModule(
annealing_num_steps=1_000_000, spec=env.action_spec, eps_init=0.2
)
stoch_policy = TensorDictSequential(
stoch_policy,
exploration_module,
)
使用模型來計算損失¶
我們構建的模型非常適合在序列環境中使用。然而,torch.nn.LSTM 類別可以使用 cuDNN 優化的後端在 GPU 設備上更快地運行 RNN 序列。我們不想錯過這樣一個加速訓練迴圈的機會!要使用它,我們只需要告訴 LSTM 模組在損失函數中使用時以「recurrent-mode」運行。由於我們通常想要擁有兩個 LSTM 模組副本,因此我們通過調用一個 set_recurrent_mode() 方法來做到這一點,該方法將返回 LSTM 的一個新實例(具有共享權重),該實例將假定輸入數據本質上是序列性的。
policy = Seq(feature, lstm.set_recurrent_mode(True), mlp, qval)
由於我們仍然有一些未初始化的參數,我們應該在創建優化器等之前初始化它們。
policy(env.reset())
TensorDict(
fields={
action: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.int64, is_shared=False),
action_value: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.float32, is_shared=False),
chosen_action_value: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
embed: Tensor(shape=torch.Size([128]), device=cpu, dtype=torch.float32, is_shared=False),
is_init: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
recurrent_state_c: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False),
pixels: Tensor(shape=torch.Size([1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
DQN 損失函數¶
我們的 DQN 損失函數需要我們傳遞策略,再次傳遞動作空間。雖然這看起來很多餘,但它很重要,因為我們要確保 DQNLoss 和 QValueModule 類別是相容的,但彼此不強烈依賴。
要使用 Double-DQN,我們需要一個 delay_value 參數,它將創建一個不可微分的網路參數副本,用作目標網路。
loss_fn = DQNLoss(policy, action_space=env.action_spec, delay_value=True)
由於我們正在使用 double DQN,因此我們需要更新目標參數。我們將使用一個 SoftUpdate 實例來執行此工作。
updater = SoftUpdate(loss_fn, eps=0.95)
optim = torch.optim.Adam(policy.parameters(), lr=3e-4)
收集器和重播緩衝區¶
我們構建了最簡單的數據收集器。我們將嘗試使用一百萬幀來訓練我們的演算法,每次擴展緩衝區 50 幀。緩衝區將被設計為存儲 2 萬個 50 步的軌跡。在每個優化步驟(每次數據收集 16 次)中,我們將從緩衝區中收集 4 個項目,總共 200 個轉換。我們將使用一個 LazyMemmapStorage 存儲來將數據保存在磁碟上。
注意
為了提高效率,我們僅在此處運行數千次迭代。在實際設置中,幀總數應設置為 1M。
collector = SyncDataCollector(env, stoch_policy, frames_per_batch=50, total_frames=200)
rb = TensorDictReplayBuffer(
storage=LazyMemmapStorage(20_000), batch_size=4, prefetch=10
)
訓練迴圈¶
為了追蹤進度,我們將每 50 次數據收集在環境中運行策略一次,並在訓練後繪製結果。
utd = 16
pbar = tqdm.tqdm(total=collector.total_frames)
longest = 0
traj_lens = []
for i, data in enumerate(collector):
if i == 0:
print(
"Let us print the first batch of data.\nPay attention to the key names "
"which will reflect what can be found in this data structure, in particular: "
"the output of the QValueModule (action_values, action and chosen_action_value),"
"the 'is_init' key that will tell us if a step is initial or not, and the "
"recurrent_state keys.\n",
data,
)
pbar.update(data.numel())
# it is important to pass data that is not flattened
rb.extend(data.unsqueeze(0).to_tensordict().cpu())
for _ in range(utd):
s = rb.sample().to(device, non_blocking=True)
loss_vals = loss_fn(s)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
longest = max(longest, data["step_count"].max().item())
pbar.set_description(
f"steps: {longest}, loss_val: {loss_vals['loss'].item(): 4.4f}, action_spread: {data['action'].sum(0)}"
)
exploration_module.step(data.numel())
updater.step()
with set_exploration_type(ExplorationType.DETERMINISTIC), torch.no_grad():
rollout = env.rollout(10000, stoch_policy)
traj_lens.append(rollout.get(("next", "step_count")).max().item())
0%| | 0/200 [00:00<?, ?it/s]Let us print the first batch of data.
Pay attention to the key names which will reflect what can be found in this data structure, in particular: the output of the QValueModule (action_values, action and chosen_action_value),the 'is_init' key that will tell us if a step is initial or not, and the recurrent_state keys.
TensorDict(
fields={
action: Tensor(shape=torch.Size([50, 2]), device=cpu, dtype=torch.int64, is_shared=False),
action_value: Tensor(shape=torch.Size([50, 2]), device=cpu, dtype=torch.float32, is_shared=False),
chosen_action_value: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.float32, is_shared=False),
collector: TensorDict(
fields={
traj_ids: Tensor(shape=torch.Size([50]), device=cpu, dtype=torch.int64, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False),
done: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
embed: Tensor(shape=torch.Size([50, 128]), device=cpu, dtype=torch.float32, is_shared=False),
is_init: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
is_init: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([50, 1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False),
pixels: Tensor(shape=torch.Size([50, 1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False)
25%|██▌ | 50/200 [00:00<00:01, 130.78it/s]
25%|██▌ | 50/200 [00:11<00:01, 130.78it/s]
steps: 9, loss_val: 0.0006, action_spread: tensor([46, 4]): 25%|██▌ | 50/200 [00:31<00:01, 130.78it/s]
steps: 9, loss_val: 0.0006, action_spread: tensor([46, 4]): 50%|█████ | 100/200 [00:32<00:37, 2.64it/s]
steps: 11, loss_val: 0.0004, action_spread: tensor([44, 6]): 50%|█████ | 100/200 [01:03<00:37, 2.64it/s]
steps: 11, loss_val: 0.0004, action_spread: tensor([44, 6]): 75%|███████▌ | 150/200 [01:04<00:24, 2.01it/s]
steps: 17, loss_val: 0.0004, action_spread: tensor([12, 38]): 75%|███████▌ | 150/200 [01:35<00:24, 2.01it/s]
steps: 17, loss_val: 0.0004, action_spread: tensor([12, 38]): 100%|██████████| 200/200 [01:35<00:00, 1.81it/s]
steps: 17, loss_val: 0.0003, action_spread: tensor([43, 7]): 100%|██████████| 200/200 [02:07<00:00, 1.81it/s]
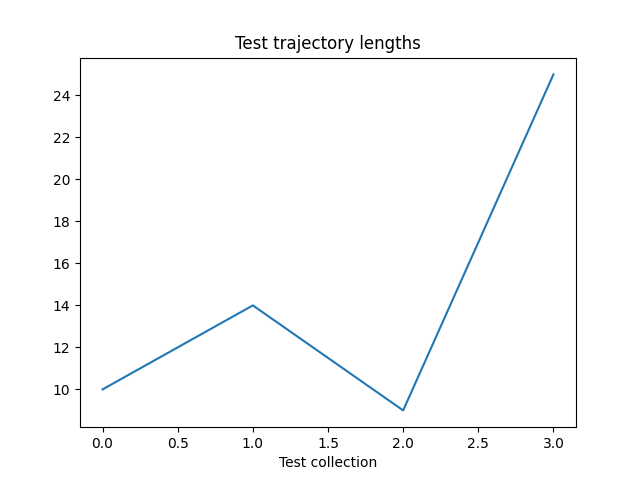
讓我們繪製我們的結果
if traj_lens:
from matplotlib import pyplot as plt
plt.plot(traj_lens)
plt.xlabel("Test collection")
plt.title("Test trajectory lengths")
結論¶
我們已經了解了如何在 TorchRL 中的策略中加入 RNN。您現在應該能夠
創建一個充當
TensorDictModule的 LSTM 模組通過
InitTracker轉換向 LSTM 模組指示需要重置將此模組加入策略和損失模組中
確保收集器知道循環狀態條目,以便可以將它們與其餘數據一起儲存在重播緩衝區中
延伸閱讀¶
TorchRL 文檔可以在此處找到。
腳本的總運行時間:(3 分鐘 8.564 秒)
預估記憶體使用量: 2233 MB
