


注意
跳到結尾以下載完整的範例程式碼。
TorchRL 環境¶
環境在 RL 設定中扮演著關鍵角色,通常與監督式和非監督式設定中的資料集有些相似。 RL 社群已經相當熟悉 OpenAI gym API,它提供了一種建構、初始化環境並與之互動的彈性方式。 然而,還有許多其他的函式庫存在,並且與它們互動的方式可能與 *gym* 的預期大不相同。
讓我們從描述 TorchRL 如何與 gym 互動開始,這將作為其他框架的介紹。
Gym 環境¶
要執行本教學課程的這一部分,您需要安裝最新版本的 gym 函式庫,以及 atari 套件。 您可以透過安裝以下套件來完成此操作
為了統一所有框架,torchrl 環境建構在 __init__ 方法中,並使用一個名為 _build_env 的私有方法,該方法會將引數和關鍵字引數傳遞給根函式庫建構器。
對於 gym 來說,這意味著建構環境就像
import torch
from matplotlib import pyplot as plt
from tensordict import TensorDict
可以透過此命令存取可用的環境清單
list(GymEnv.available_envs)[:10]
['ALE/Adventure-ram-v5', 'ALE/Adventure-v5', 'ALE/AirRaid-ram-v5', 'ALE/AirRaid-v5', 'ALE/Alien-ram-v5', 'ALE/Alien-v5', 'ALE/Amidar-ram-v5', 'ALE/Amidar-v5', 'ALE/Assault-ram-v5', 'ALE/Assault-v5']
環境規格¶
與其他框架一樣,TorchRL 環境具有指示觀測、動作、完成和獎勵的空間的屬性。 因為經常會檢索多個觀測,所以我們希望觀測規格的類型為 CompositeSpec。 獎勵和動作沒有此限制
print("Env observation_spec: \n", env.observation_spec)
print("Env action_spec: \n", env.action_spec)
print("Env reward_spec: \n", env.reward_spec)
Env observation_spec:
Composite(
observation: BoundedContinuous(
shape=torch.Size([3]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=None,
shape=torch.Size([]))
Env action_spec:
BoundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous)
Env reward_spec:
UnboundedContinuous(
shape=torch.Size([1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous)
這些規格提供了一系列有用的工具:可以斷言樣本是否在定義的空間中。 我們也可以使用一些啟發式方法將樣本投影到空間中(如果它超出空間),並在該空間中生成隨機(可能均勻分佈)的數字
action = torch.ones(1) * 3
print("action is in bounds?\n", bool(env.action_spec.is_in(action)))
print("projected action: \n", env.action_spec.project(action))
action is in bounds?
False
projected action:
tensor([2.])
print("random action: \n", env.action_spec.rand())
random action:
tensor([-1.3541])
在這些規格中,done_spec 值得特別注意。 在 TorchRL 中,所有環境至少寫入兩種型別的軌跡結束訊號:"terminated"(指示馬可夫決策過程已達到最終狀態 - __episode__ 已完成)和 "done",指示這是 __trajectory__ 的最後一步(但不一定是任務的結束)。 一般來說,當 "terminal" 為 False 時,"done" 條目為 True 是由 "truncated" 訊號引起的。 Gym 環境說明了這三個訊號
print(env.done_spec)
Composite(
done: Categorical(
shape=torch.Size([1]),
space=CategoricalBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
terminated: Categorical(
shape=torch.Size([1]),
space=CategoricalBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
truncated: Categorical(
shape=torch.Size([1]),
space=CategoricalBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
device=None,
shape=torch.Size([]))
環境也封裝了一個 env.state_spec 屬性,其類型為 CompositeSpec,其中包含環境的所有輸入規格,但動作除外。 對於有狀態的環境(例如 gym),這大部分時間都是空的。 對於無狀態環境(例如 Brax),這也應該包括先前狀態的表示形式,或環境的任何其他輸入(包括重置時的輸入)。
播種、重置和步驟¶
環境的基本操作包含 (1) set_seed, (2) reset 以及 (3) step。
讓我們看看這些方法在 TorchRL 中是如何運作的
torch.manual_seed(0) # make sure that all torch code is also reproductible
env.set_seed(0)
reset_data = env.reset()
print("reset data", reset_data)
reset data TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
現在我們可以在環境中執行一個 step。由於我們沒有策略,我們可以簡單地生成一個隨機的 action
policy = TensorDictModule(env.action_spec.rand, in_keys=[], out_keys=["action"])
policy(reset_data)
tensordict_out = env.step(reset_data)
預設情況下,step 返回的 tensordict 與輸入相同...
assert tensordict_out is reset_data
... 但帶有新的鍵
tensordict_out
TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
我們剛才所做的事情(使用 action_spec.rand() 進行隨機 step)也可以通過簡單的快捷方式來完成。
env.rand_step()
TensorDict(
fields={
action: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
新的鍵 ("next", "observation") (就像 "next" tensordict 下的所有鍵一樣) 在 TorchRL 中有一個特殊的作用:它們表示它們來自於具有相同名稱但沒有前綴的鍵之後。
我們提供了一個函數 step_mdp,它在 tensordict 中執行一個 step:它返回一個新的 tensordict,更新後使得 *t < -t’*
from torchrl.envs.utils import step_mdp
tensordict_out.set("some other key", torch.randn(1))
tensordict_tprime = step_mdp(tensordict_out)
print(tensordict_tprime)
print(
(
tensordict_tprime.get("observation")
== tensordict_out.get(("next", "observation"))
).all()
)
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
some other key: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
tensor(True)
我們可以觀察到 step_mdp 已經移除了所有與時間相關的鍵值對,但不包括 "some other key"。 此外,新的 observation 與先前的 observation 相符。
最後,請注意 env.reset 方法也接受一個 tensordict 來更新
tensordict = TensorDict({}, [])
assert env.reset(tensordict) is tensordict
tensordict
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
Rollouts¶
TorchRL 提供的通用環境類別允許您輕鬆地為給定數量的 step 執行 rollouts
tensordict_rollout = env.rollout(max_steps=20, policy=policy)
print(tensordict_rollout)
TensorDict(
fields={
action: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([20, 3]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([20]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([20, 3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([20, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([20]),
device=None,
is_shared=False)
結果的 tensordict 具有 batch_size 為 [20],這是 trajectory 的長度。 我們可以檢查 observation 是否與它們的下一個值相符
(
tensordict_rollout.get("observation")[1:]
== tensordict_rollout.get(("next", "observation"))[:-1]
).all()
tensor(True)
frame_skip¶
在某些情況下,使用 frame_skip 參數將相同的 action 用於多個連續的 frame 很有用。
結果的 tensordict 將僅包含在序列中觀察到的最後一個 frame,但 rewards 將在 frame 數量上進行加總。
如果環境在此過程中達到 done 狀態,它將停止並返回截斷鏈的結果。
env = GymEnv("Pendulum-v1", frame_skip=4)
env.reset()
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
Rendering¶
Rendering 在許多 RL 設定中扮演著重要的角色,這就是為什麼 torchrl 中的通用環境類別提供了一個 from_pixels 關鍵字參數,允許使用者快速請求基於圖像的環境
env = GymEnv("Pendulum-v1", from_pixels=True)
tensordict = env.reset()
env.close()
plt.imshow(tensordict.get("pixels").numpy())
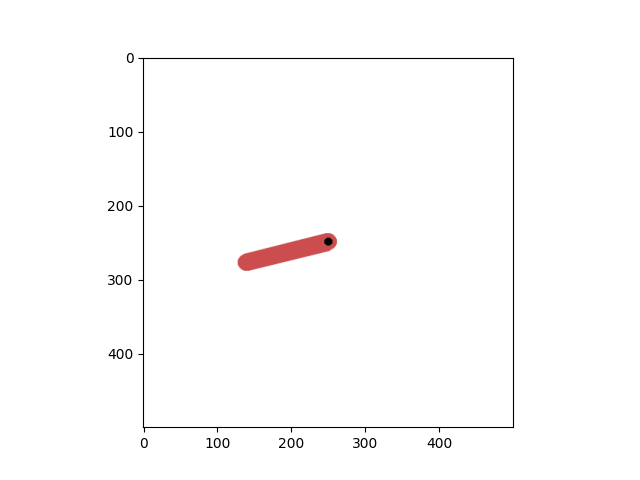
<matplotlib.image.AxesImage object at 0x7fb1c4b85e10>
讓我們看看 tensordict 包含什麼
tensordict
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([500, 500, 3]), device=cpu, dtype=torch.uint8, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
我們仍然有一個 "state",它描述了 "observation" 在先前案例中使用的描述(命名差異來自於 gym 現在返回一個字典,如果存在,TorchRL 會從字典中獲取名稱,否則它會將 step 輸出命名為 "observation":簡而言之,這是由於 gym 環境 step 方法返回的物件類型不一致造成的)。
也可以通過僅請求像素來捨棄這個補充輸出
env = GymEnv("Pendulum-v1", from_pixels=True, pixels_only=True)
env.reset()
env.close()
某些環境僅提供基於圖像的格式
env = GymEnv("ALE/Pong-v5")
print("from pixels: ", env.from_pixels)
print("tensordict: ", env.reset())
env.close()
from pixels: True
tensordict: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([210, 160, 3]), device=cpu, dtype=torch.uint8, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
DeepMind Control environments¶
- 要執行本教學的此部分,請確保已安裝 dm_control
$ pip install dm_control
我們也為 DM Control suite 提供了一個 wrapper。同樣,建立環境也很容易:首先讓我們看看可以存取哪些環境。 現在,available_envs 返回一個 envs 和可能的 tasks 的 dict
from matplotlib import pyplot as plt
from torchrl.envs.libs.dm_control import DMControlEnv
DMControlEnv.available_envs
[('acrobot', ['swingup', 'swingup_sparse']), ('ball_in_cup', ['catch']), ('cartpole', ['balance', 'balance_sparse', 'swingup', 'swingup_sparse', 'three_poles', 'two_poles']), ('cheetah', ['run']), ('finger', ['spin', 'turn_easy', 'turn_hard']), ('fish', ['upright', 'swim']), ('hopper', ['stand', 'hop']), ('humanoid', ['stand', 'walk', 'run', 'run_pure_state']), ('manipulator', ['bring_ball', 'bring_peg', 'insert_ball', 'insert_peg']), ('pendulum', ['swingup']), ('point_mass', ['easy', 'hard']), ('reacher', ['easy', 'hard']), ('swimmer', ['swimmer6', 'swimmer15']), ('walker', ['stand', 'walk', 'run']), ('dog', ['fetch', 'run', 'stand', 'trot', 'walk']), ('humanoid_CMU', ['run', 'stand', 'walk']), ('lqr', ['lqr_2_1', 'lqr_6_2']), ('quadruped', ['escape', 'fetch', 'run', 'walk']), ('stacker', ['stack_2', 'stack_4'])]
env = DMControlEnv("acrobot", "swingup")
tensordict = env.reset()
print("result of reset: ", tensordict)
env.close()
result of reset: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
orientations: Tensor(shape=torch.Size([4]), device=cpu, dtype=torch.float64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
velocity: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.float64, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
當然,我們也可以使用基於像素的環境
env = DMControlEnv("acrobot", "swingup", from_pixels=True, pixels_only=True)
tensordict = env.reset()
print("result of reset: ", tensordict)
plt.imshow(tensordict.get("pixels").numpy())
env.close()
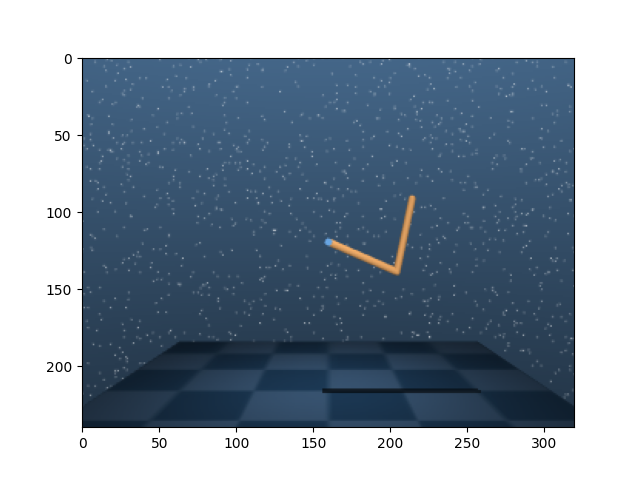
result of reset: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([240, 320, 3]), device=cpu, dtype=torch.uint8, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
Transforming envs¶
通常在讓策略讀取或儲存在 buffer 中之前,會預先處理環境的輸出。
- 在許多情況下,RL 社群已採用了以下類型的 wrapping 方案
$ env_transformed = wrapper1(wrapper2(env))
來轉換環境。這有許多優點:它使得存取環境規格變得顯而易見(外部 wrapper 是外部世界的真理來源),並且它使得與向量化環境交互變得容易。 然而,它也使得存取內部環境變得困難:假設有人想要從鏈中移除一個 wrapper(例如 wrapper2),此操作需要我們收集
$ env0 = env.env.env
$ env_transformed_bis = wrapper1(env0)
TorchRL 採用使用 transform 序列的立場,就像在其他 pytorch 領域 libraries (例如 torchvision) 中所做的那樣。 此方法也類似於在 torch.distribution 中轉換 distributions 的方式,其中 TransformedDistribution 物件圍繞 base_dist distribution 和 (transform 序列) transforms 建立。
from torchrl.envs.transforms import ToTensorImage, TransformedEnv
# ToTensorImage transforms a numpy-like image into a tensor one,
env = DMControlEnv("acrobot", "swingup", from_pixels=True, pixels_only=True)
print("reset before transform: ", env.reset())
env = TransformedEnv(env, ToTensorImage())
print("reset after transform: ", env.reset())
env.close()
reset before transform: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([240, 320, 3]), device=cpu, dtype=torch.uint8, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
reset after transform: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([3, 240, 320]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
要組合 transform,只需使用 Compose 類別
from torchrl.envs.transforms import Compose, Resize
env = DMControlEnv("acrobot", "swingup", from_pixels=True, pixels_only=True)
env = TransformedEnv(env, Compose(ToTensorImage(), Resize(32, 32)))
env.reset()
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([3, 32, 32]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
也可以一次新增一個 transform
TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([1, 32, 32]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
正如預期的那樣,metadata 也會更新
print("original obs spec: ", env.base_env.observation_spec)
print("current obs spec: ", env.observation_spec)
original obs spec: Composite(
pixels: UnboundedDiscrete(
shape=torch.Size([240, 320, 3]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([240, 320, 3]), device=cpu, dtype=torch.uint8, contiguous=True),
high=Tensor(shape=torch.Size([240, 320, 3]), device=cpu, dtype=torch.uint8, contiguous=True)),
device=cpu,
dtype=torch.uint8,
domain=discrete),
device=None,
shape=torch.Size([]))
current obs spec: Composite(
pixels: UnboundedContinuous(
shape=torch.Size([1, 32, 32]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([1, 32, 32]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([1, 32, 32]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=None,
shape=torch.Size([]))
如果需要,我們也可以連接 tensors
from torchrl.envs.transforms import CatTensors
env = DMControlEnv("acrobot", "swingup")
print("keys before concat: ", env.reset())
env = TransformedEnv(
env,
CatTensors(in_keys=["orientations", "velocity"], out_key="observation"),
)
print("keys after concat: ", env.reset())
keys before concat: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
orientations: Tensor(shape=torch.Size([4]), device=cpu, dtype=torch.float64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
velocity: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.float64, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
keys after concat: TensorDict(
fields={
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([6]), device=cpu, dtype=torch.float64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=None,
is_shared=False)
此功能使得修改應用於環境輸入和輸出的 transforms 集合變得容易。 實際上,transforms 在執行 step 之前和之後都會執行:對於 pre-step pass,鍵的 in_keys_inv 列表將傳遞給 _inv_apply_transform 方法。 這種 transform 的一個範例是將浮點 action(來自神經網路的輸出)轉換為 double dtype(wrapped 環境需要)。 執行 step 之後,將在 in_keys 鍵列表指示的鍵上執行 _apply_transform 方法。
環境 transforms 的另一個有趣特性是,它們允許使用者在 wrapped 案例中檢索等效於 env.env 的物件,或者換句話說,父環境。 可以通過呼叫 transform.parent 來檢索父環境:返回的環境將由一個 TransformedEnvironment 組成,其中包含所有 transforms,直到(但不包括)目前的 transform。 這將用於例如 NoopResetEnv 案例,當重置時,它會執行以下步驟:在該環境中隨機執行一定數量的 steps 之前,重置父環境。
env = DMControlEnv("acrobot", "swingup")
env = TransformedEnv(env)
env.append_transform(
CatTensors(in_keys=["orientations", "velocity"], out_key="observation")
)
env.append_transform(GrayScale())
print("env: \n", env)
print("GrayScale transform parent env: \n", env.transform[1].parent)
print("CatTensors transform parent env: \n", env.transform[0].parent)
env:
TransformedEnv(
env=DMControlEnv(env=acrobot, task=swingup, batch_size=torch.Size([])),
transform=Compose(
CatTensors(in_keys=['orientations', 'velocity'], out_key=observation),
GrayScale(keys=['pixels'])))
GrayScale transform parent env:
TransformedEnv(
env=DMControlEnv(env=acrobot, task=swingup, batch_size=torch.Size([])),
transform=Compose(
CatTensors(in_keys=['orientations', 'velocity'], out_key=observation)))
CatTensors transform parent env:
TransformedEnv(
env=DMControlEnv(env=acrobot, task=swingup, batch_size=torch.Size([])),
transform=Compose(
))
Environment device¶
Transforms 可以在 device 上工作,當操作的計算需求中等或很高時,這可以帶來顯著的加速。 這些包括 ToTensorImage、Resize、GrayScale 等。
有人可能會合理地問,這對封裝的環境端意味著什麼。對於常規環境來說,影響很小:操作仍然會在它們應該發生的設備上發生。torchrl 中的環境設備屬性指示輸入數據應該在哪個設備上,以及輸出數據將會在哪個設備上。從該設備到其他設備的轉換是 torchrl 環境類別的責任。將資料儲存在 GPU 上的主要優勢在於 (1) 如上所述的轉換加速,以及 (2) 在多處理設定中,工作者之間共享資料。
from torchrl.envs.transforms import CatTensors, GrayScale, TransformedEnv
env = DMControlEnv("acrobot", "swingup")
env = TransformedEnv(env)
env.append_transform(
CatTensors(in_keys=["orientations", "velocity"], out_key="observation")
)
if torch.has_cuda and torch.cuda.device_count():
env.to("cuda:0")
env.reset()
平行執行環境¶
TorchRL 提供了平行執行環境的工具。預期各種環境會讀取並傳回形狀和資料類型相似的張量(但可以設計遮罩函式,以便在這些張量形狀不同時使其成為可能)。創建這種環境非常容易。讓我們看看最簡單的情況
from torchrl.envs import ParallelEnv
def env_make():
return GymEnv("Pendulum-v1")
parallel_env = ParallelEnv(3, env_make) # -> creates 3 envs in parallel
parallel_env = ParallelEnv(
3, [env_make, env_make, env_make]
) # similar to the previous command
SerialEnv 類別與 ParallelEnv 類似,只是環境是依序執行的。這主要用於除錯目的。
ParallelEnv 實例以延遲模式建立:環境只有在被呼叫時才會開始執行。這允許我們在進程之間移動 ParallelEnv 物件,而無需過多擔心執行中的進程。ParallelEnv 可以透過呼叫 start、reset 或直接呼叫 step 來啟動(如果不需要先呼叫 reset)。
parallel_env.reset()
TensorDict(
fields={
done: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3, 3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([3, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([3]),
device=None,
is_shared=False)
可以檢查平行環境是否具有正確的批次大小。按照慣例,batch_size 的第一部分表示批次,第二部分表示時間範圍。讓我們用 rollout 方法檢查一下
parallel_env.rollout(max_steps=20)
TensorDict(
fields={
action: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([3, 20, 3]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([3, 20]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([3, 20, 3]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([3, 20, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([3, 20]),
device=None,
is_shared=False)
關閉平行環境¶
重要提示:在關閉程式之前,關閉平行環境非常重要。通常,即使是常規環境,最好也使用呼叫 close 來關閉函式。在某些情況下,如果未執行此操作,TorchRL 會拋出錯誤(通常會在程式結束時,當環境超出範圍時!)
parallel_env.close()
設定種子 (Seeding)¶
在設定平行環境的種子時,我們面臨的困難是我們不想為所有環境提供相同的種子。TorchRL 使用的啟發式方法是,我們以馬可夫方式產生給定輸入種子的確定性種子鏈,以便可以從其任何元素重建它。所有 set_seed 方法都將傳回要使用的下一個種子,以便可以輕鬆地保持鏈的進行,並給定上一個種子。當多個收集器都包含一個 ParallelEnv 實例,並且我們希望每個子子環境都具有不同的種子時,這非常有用。
out_seed = parallel_env.set_seed(10)
print(out_seed)
del parallel_env
3288080526
存取環境屬性¶
有時,封裝的環境具有感興趣的屬性。首先,請注意 TorchRL 環境封裝器包含存取此屬性的工具。這是一個範例
from time import sleep
from uuid import uuid1
def env_make():
env = GymEnv("Pendulum-v1")
env._env.foo = f"bar_{uuid1()}"
env._env.get_something = lambda r: r + 1
return env
env = env_make()
# Goes through env._env
env.foo
'bar_c6313b92-90c7-11ef-a49b-0242ac110002'
parallel_env = ParallelEnv(3, env_make) # -> creates 3 envs in parallel
# env has not been started --> error:
try:
parallel_env.foo
except RuntimeError:
print("Aargh what did I do!")
sleep(2) # make sure we don't get ahead of ourselves
Aargh what did I do!
if parallel_env.is_closed:
parallel_env.start()
foo_list = parallel_env.foo
foo_list # needs to be instantiated, for instance using list
<torchrl.envs.batched_envs._dispatch_caller_parallel object at 0x7fb1c4b87a30>
list(foo_list)
['bar_caa4671c-90c7-11ef-a4ef-0242ac110002', 'bar_ca9e607e-90c7-11ef-bf1d-0242ac110002', 'bar_caa59c2c-90c7-11ef-95b4-0242ac110002']
同樣,也可以存取方法
something = parallel_env.get_something(0)
print(something)
[1, 1, 1]
parallel_env.close()
del parallel_env
平行環境的 kwargs¶
可能需要為各種環境提供 kwargs。這可以在建構時或之後實現
from torchrl.envs import ParallelEnv
def env_make(env_name):
env = TransformedEnv(
GymEnv(env_name, from_pixels=True, pixels_only=True),
Compose(ToTensorImage(), Resize(64, 64)),
)
return env
parallel_env = ParallelEnv(
2,
[env_make, env_make],
create_env_kwargs=[{"env_name": "ALE/AirRaid-v5"}, {"env_name": "ALE/Pong-v5"}],
)
tensordict = parallel_env.reset()
plt.figure()
plt.subplot(121)
plt.imshow(tensordict[0].get("pixels").permute(1, 2, 0).numpy())
plt.subplot(122)
plt.imshow(tensordict[1].get("pixels").permute(1, 2, 0).numpy())
parallel_env.close()
del parallel_env
from matplotlib import pyplot as plt
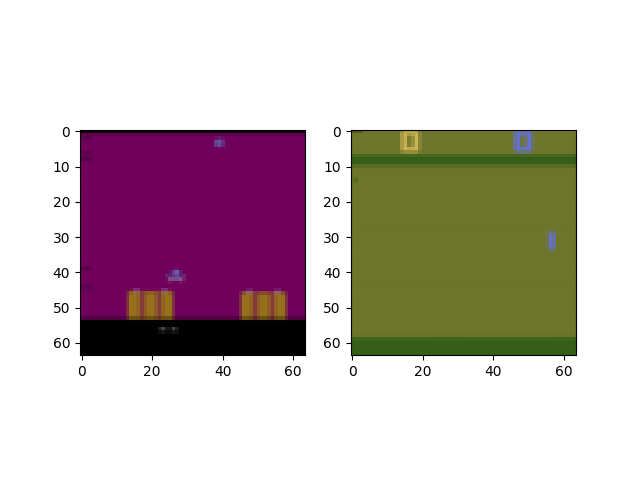
轉換平行環境¶
有兩種等效的轉換平行環境的方法:在每個進程中單獨轉換,或在主進程上轉換。甚至可以同時進行。因此,可以仔細考慮轉換設計,以利用設備功能(例如,在 cuda 設備上轉換)並在主進程上向量化操作(如果可能)。
from torchrl.envs import (
Compose,
GrayScale,
ParallelEnv,
Resize,
ToTensorImage,
TransformedEnv,
)
def env_make(env_name):
env = TransformedEnv(
GymEnv(env_name, from_pixels=True, pixels_only=True),
Compose(ToTensorImage(), Resize(64, 64)),
) # transforms on remote processes
return env
parallel_env = ParallelEnv(
2,
[env_make, env_make],
create_env_kwargs=[{"env_name": "ALE/AirRaid-v5"}, {"env_name": "ALE/Pong-v5"}],
)
parallel_env = TransformedEnv(parallel_env, GrayScale()) # transforms on main process
tensordict = parallel_env.reset()
print("grayscale tensordict: ", tensordict)
plt.figure()
plt.subplot(121)
plt.imshow(tensordict[0].get("pixels").permute(1, 2, 0).numpy())
plt.subplot(122)
plt.imshow(tensordict[1].get("pixels").permute(1, 2, 0).numpy())
parallel_env.close()
del parallel_env
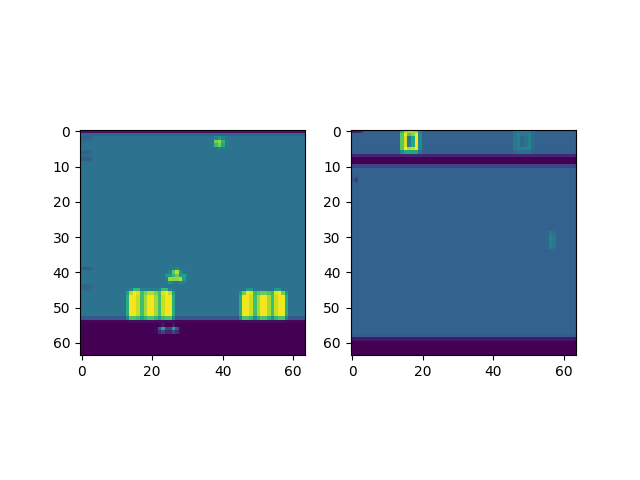
grayscale tensordict: TensorDict(
fields={
done: Tensor(shape=torch.Size([2, 1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([2, 1, 64, 64]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([2, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([2, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([2]),
device=None,
is_shared=False)
VecNorm¶
在 RL 中,我們經常面臨在將資料輸入模型之前對資料進行正規化的問題。有時,我們可以從環境中收集的資料(例如,使用隨機策略或示範)中獲得正規化統計資料的良好近似值。然而,最好「即時」正規化資料,逐步更新正規化常數,使其與迄今為止觀察到的情況一致。當我們預期正規化統計資料會隨著任務中效能的變化而變化,或者當環境由於外部因素而演變時,這特別有用。
注意:此功能應謹慎用於離線學習,因為舊資料會因為使用先前有效的正規化統計資料進行正規化而被「棄用」。在線上學習設定中,此功能也會使學習變得不穩定,並可能產生意想不到的影響。因此,建議使用者謹慎地依賴此功能,並將其與給定正規化常數固定版本的情況下正規化的資料進行比較。
在常規設定中,使用 VecNorm 非常容易
from torchrl.envs.libs.gym import GymEnv
from torchrl.envs.transforms import TransformedEnv, VecNorm
env = TransformedEnv(GymEnv("Pendulum-v1"), VecNorm())
tensordict = env.rollout(max_steps=100)
print("mean: :", tensordict.get("observation").mean(0)) # Approx 0
print("std: :", tensordict.get("observation").std(0)) # Approx 1
mean: : tensor([-0.1122, 0.2134, -0.1901])
std: : tensor([1.1596, 1.1628, 1.0870])
在平行環境中,事情稍微複雜一些,因為我們需要在進程之間共享執行統計資料。我們建立了一個類別 EnvCreator,它負責查看環境建立方法,檢索要在環境類別中於進程之間共享的 tensordict,並在建立後將每個進程指向正確的、共享的 tensordict
from torchrl.envs import EnvCreator, ParallelEnv
from torchrl.envs.libs.gym import GymEnv
from torchrl.envs.transforms import TransformedEnv, VecNorm
make_env = EnvCreator(lambda: TransformedEnv(GymEnv("CartPole-v1"), VecNorm(decay=1.0)))
env = ParallelEnv(3, make_env)
make_env.state_dict()["_extra_state"]["td"]["observation_count"].fill_(0.0)
make_env.state_dict()["_extra_state"]["td"]["observation_ssq"].fill_(0.0)
make_env.state_dict()["_extra_state"]["td"]["observation_sum"].fill_(0.0)
tensordict = env.rollout(max_steps=5)
print("tensordict: ", tensordict)
print("mean: :", tensordict.get("observation").view(-1, 3).mean(0)) # Approx 0
print("std: :", tensordict.get("observation").view(-1, 3).std(0)) # Approx 1
Traceback (most recent call last):
File "/pytorch/rl/docs/source/reference/generated/tutorials/torchrl_envs.py", line 697, in <module>
make_env.state_dict()["_extra_state"]["td"]["observation_count"].fill_(0.0)
KeyError: 'td'
計數略高於步驟數(因為我們沒有使用任何衰減)。兩者之間的差異是由於 ParallelEnv 建立了一個虛擬環境來初始化共享的 TensorDict,該 TensorDict 用於從分配的環境中收集資料。這種微小的差異通常會在整個訓練過程中被吸收。
print(
"update counts: ",
make_env.state_dict()["_extra_state"]["td"]["observation_count"],
)
env.close()
del env
腳本的總執行時間:(3 分鐘 27.917 秒)
估計的記憶體使用量: 2965 MB
