


注意
前往結尾以下載完整的範例程式碼。
使用 TorchRL 進行具競爭性的多代理人強化學習 (DDPG) 教學¶
另請參閱
BenchMARL 函式庫提供了使用 TorchRL 的最先進 MARL 演算法實作。
本教學示範如何使用 PyTorch 和 TorchRL 來解決具競爭性的多代理人強化學習 (MARL) 問題。
為了方便使用,本教學將遵循已提供的 使用 TorchRL 進行多代理人強化學習 (PPO) 教學 的一般結構。
在本教學中,我們將使用來自 MADDPG 論文的 *simple_tag* 環境。這個環境是稱為 MultiAgentParticleEnvironments (MPE) 的集合的一部分,該集合是在論文中介紹的。
目前有多個模擬器提供 MPE 環境。在本教學中,我們展示如何在 TorchRL 中訓練這個環境,使用
PettingZoo,在傳統的 CPU 版本環境中;
VMAS,它在 PyTorch 中提供向量化的實作,能夠在 GPU 上模擬多個環境以加速計算。

多代理人 *simple_tag* 情境¶
主要學習
如何在 TorchRL 中使用具競爭性的多代理人環境、它們的規格如何運作以及它們如何與函式庫整合;
如何在 TorchRL 中使用具有多個代理人組別的平行 PettingZoo 和 VMAS 環境;
如何在 TorchRL 中建立不同的多代理人網路架構(例如,使用參數共享、集中式評論員)
我們如何使用
TensorDict來攜帶多代理人多組別資料;我們如何將所有函式庫組件(收集器、模組、重播緩衝區和損失)綁定到一個非策略多代理人 MADDPG/IDDPG 訓練迴圈中。
如果您在 Google Colab 中執行此操作,請確保您安裝了以下相依性
!pip3 install torchrl
!pip3 install vmas
!pip3 install pettingzoo[mpe]==1.24.3
!pip3 install tqdm
深度確定性策略梯度 (DDPG) 是一種非策略 actor-critic 演算法,其中使用來自評論員網路的梯度來優化確定性策略。 如需更多資訊,請參閱 深度確定性策略梯度論文。 這種演算法通常採用非策略訓練。 有關非策略學習的更多資訊,請參閱 Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018。
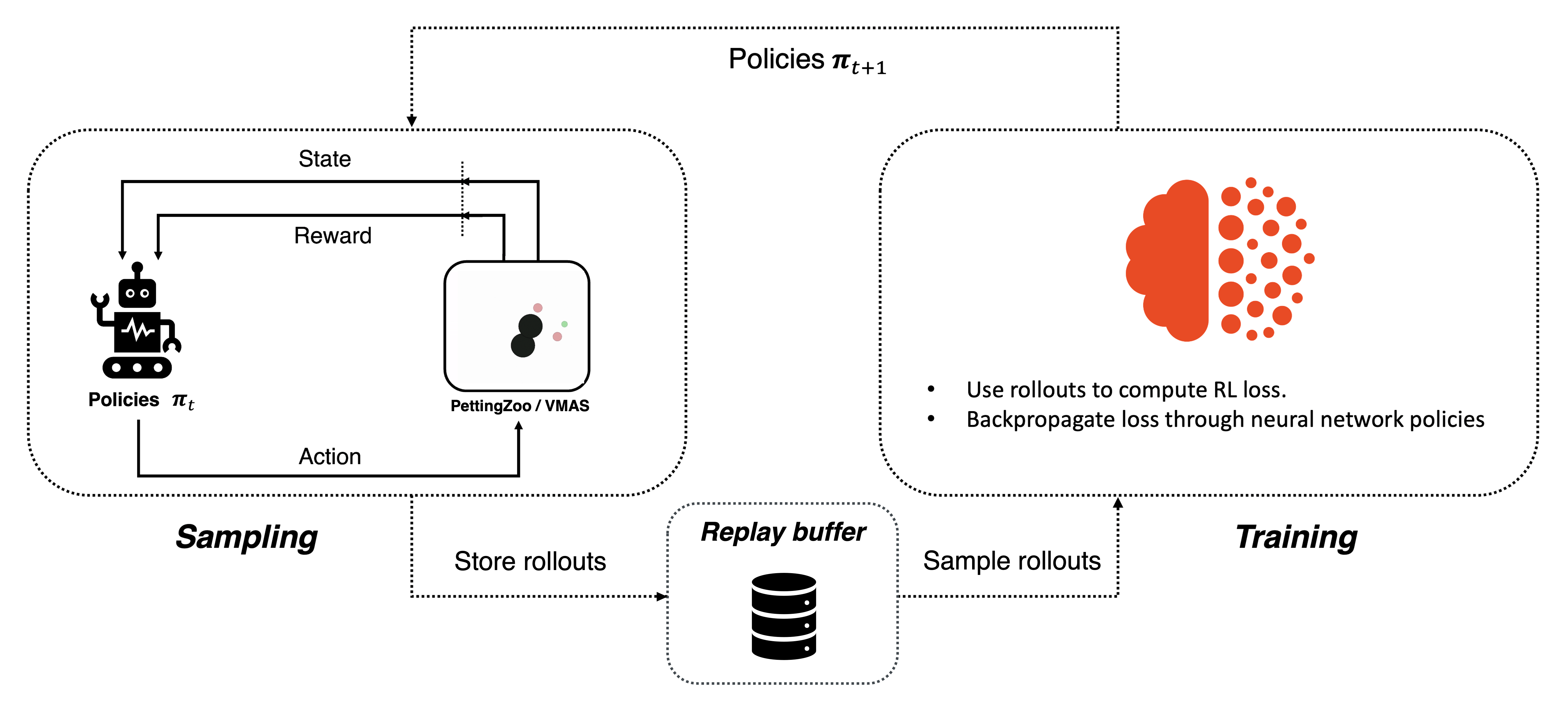
非策略學習¶
這個方法已擴展到多代理學習,如 Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 中所述,該論文介紹了多代理深度確定性策略梯度 (MADDPG) 演算法。在多代理設定中,情況略有不同。我們現在有多個策略 \(\mathbf{\pi}\),每個代理一個策略。策略通常是本地且分散式的。這意味著單個代理的策略將僅基於其觀察結果輸出該代理的動作。在 MARL 文獻中,這被稱為分散式執行。另一方面,評論家 (critic) 存在不同的公式,主要是
在 MADDPG 中,評論家是集中式的,並將系統的全局狀態和全局動作作為輸入。全局狀態可以是全局觀察結果,或者只是代理觀察結果的串聯。全局動作是代理動作的串聯。 MADDPG 可用於執行集中式訓練的上下文中,因為它需要訪問全局資訊。
在 IDDPG 中,評論家僅將一個代理的觀察結果和動作作為輸入。這允許分散式訓練,因為評論家和策略都只需要本地資訊來計算其輸出。
集中式評論家有助於克服多個代理同時學習時的非平穩性,但另一方面,它們可能會受到其龐大輸入空間的影響。在本教程中,我們將能夠訓練這兩種公式,並且我們還將討論參數共享(在代理之間共享網路參數的做法)如何影響每一個公式。
本教程的結構如下
首先,我們將建立一組超參數以供使用。
隨後,我們將建構一個多代理環境,利用 TorchRL 的包裝器來處理 PettingZoo 或 VMAS。
接下來,我們將制定策略和評論家網路,討論各種選擇對參數共享和評論家集中化的影響。
之後,我們將建立取樣收集器和重播緩衝區。
最後,我們將執行我們的訓練迴圈並檢查結果。
如果您在 Colab 或具有 GUI 的機器上操作此程式,您也將有機會在訓練過程之前和之後渲染和視覺化您自己訓練的策略。
導入我們的依賴項
import copy
import tempfile
import torch
from matplotlib import pyplot as plt
from tensordict import TensorDictBase
from tensordict.nn import TensorDictModule, TensorDictSequential
from torch import multiprocessing
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyMemmapStorage, RandomSampler, ReplayBuffer
from torchrl.envs import (
check_env_specs,
ExplorationType,
PettingZooEnv,
RewardSum,
set_exploration_type,
TransformedEnv,
VmasEnv,
)
from torchrl.modules import (
AdditiveGaussianModule,
MultiAgentMLP,
ProbabilisticActor,
TanhDelta,
)
from torchrl.objectives import DDPGLoss, SoftUpdate, ValueEstimators
from torchrl.record import CSVLogger, PixelRenderTransform, VideoRecorder
from tqdm import tqdm
# Check if we're building the doc, in which case disable video rendering
try:
is_sphinx = __sphinx_build__
except NameError:
is_sphinx = False
定義超參數¶
我們為本教程設定超參數。根據可用的資源,您可以選擇在 GPU 或其他裝置上執行策略和模擬器。您可以調整其中一些值來調整計算需求。
# Seed
seed = 0
torch.manual_seed(seed)
# Devices
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
# Sampling
frames_per_batch = 1_000 # Number of team frames collected per sampling iteration
n_iters = 10 # Number of sampling and training iterations
total_frames = frames_per_batch * n_iters
# We will stop training the evaders after this many iterations,
# should be 0 <= iteration_when_stop_training_evaders <= n_iters
iteration_when_stop_training_evaders = n_iters // 2
# Replay buffer
memory_size = 1_000_000 # The replay buffer of each group can store this many frames
# Training
n_optimiser_steps = 100 # Number of optimization steps per training iteration
train_batch_size = 128 # Number of frames trained in each optimiser step
lr = 3e-4 # Learning rate
max_grad_norm = 1.0 # Maximum norm for the gradients
# DDPG
gamma = 0.99 # Discount factor
polyak_tau = 0.005 # Tau for the soft-update of the target network
環境¶
多代理環境模擬多個代理與世界的互動。 TorchRL API 允許整合各種類型的多代理環境。在本教程中,我們將專注於多個代理群組並行互動的環境。也就是說:在每個步驟中,所有代理都會同步獲得觀察結果並採取行動。
此外,TorchRL MARL API 允許將代理分成群組。每個群組將是 tensordict 中的一個單獨條目。群組內代理的資料堆疊在一起。因此,透過選擇如何對代理進行分組,您可以決定哪些資料被堆疊/保持為單獨的條目。分組策略可以在 VMAS 和 PettingZoo 等環境的建構中指定。有關分組的更多資訊,請參閱 MarlGroupMapType。
在simple_tag 環境中,有兩個代理團隊:追逐者(或“對手”)(紅色圓圈)和逃避者(或“代理”)(綠色圓圈)。追逐者因接觸逃避者而獲得獎勵 (+10)。一旦接觸,追逐者團隊將共同獲得獎勵,而受接觸的逃避者將受到相同值的懲罰 (-10)。逃避者比追逐者具有更高的速度和加速度。環境中還有障礙物(黑色圓圈)。代理和障礙物根據均勻隨機分佈生成。代理在具有阻力和彈性碰撞的 2D 連續世界中行動。他們的動作是 2D 連續力,決定他們的加速度。每個代理觀察其位置、速度、相對於所有其他代理和障礙物的位置以及逃避者的速度。
PettingZoo 和 VMAS 版本在獎勵函數方面略有不同,因為 PettingZoo 會懲罰逃避者超出邊界,而 VMAS 則在物理上阻止它。這就是為什麼您會觀察到在 VMAS 中,兩個團隊的獎勵是相同的,只是符號相反,而在 PettingZoo 中,逃避者將獲得較低的獎勵。
我們現在將實例化環境。對於本教程,我們將將劇集限制為 max_steps,之後設定終止標誌。此功能已在 PettingZoo 和 VMAS 模擬器中提供,但 TorchRL StepCounter 轉換可以替代使用。
max_steps = 100 # Environment steps before done
n_chasers = 2
n_evaders = 1
n_obstacles = 2
use_vmas = True # Set this to True for a great performance speedup
if not use_vmas:
base_env = PettingZooEnv(
task="simple_tag_v3",
parallel=True, # Use the Parallel version
seed=seed,
# Scenario specific
continuous_actions=True,
num_good=n_evaders,
num_adversaries=n_chasers,
num_obstacles=n_obstacles,
max_cycles=max_steps,
)
else:
num_vmas_envs = (
frames_per_batch // max_steps
) # Number of vectorized environments. frames_per_batch collection will be divided among these environments
base_env = VmasEnv(
scenario="simple_tag",
num_envs=num_vmas_envs,
continuous_actions=True,
max_steps=max_steps,
device=device,
seed=seed,
# Scenario specific
num_good_agents=n_evaders,
num_adversaries=n_chasers,
num_landmarks=n_obstacles,
)
群組地圖¶
PettingZoo 和 VMAS 環境使用 TorchRL MARL 分組 API。我們可以按照以下方式存取群組地圖,將每個群組映射到其中的代理
print(f"group_map: {base_env.group_map}")
group_map: {'adversary': ['adversary_0', 'adversary_1'], 'agent': ['agent_0']}
正如我們所看到的,它包含 2 個群組:“agents”(逃避者)和“adversaries”(追逐者)。
環境不僅由其模擬器和轉換定義,還由一系列元資料定義,這些元資料描述了在執行期間可以預期什麼。出於效率目的,TorchRL 在環境規範方面非常嚴格,但您可以輕鬆檢查您的環境規範是否足夠。在我們的範例中,模擬器包裝器負責為您的 base_env 設定適當的規範,因此您不必擔心這一點。
有四個規範需要查看
action_spec定義了動作空間;reward_spec定義了獎勵域;done_spec定義了完成域;observation_spec定義了來自環境步驟的所有其他輸出的域;
print("action_spec:", base_env.full_action_spec)
print("reward_spec:", base_env.full_reward_spec)
print("done_spec:", base_env.full_done_spec)
print("observation_spec:", base_env.observation_spec)
action_spec: Composite(
adversary: Composite(
action: BoundedContinuous(
shape=torch.Size([10, 2, 2]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 2])),
agent: Composite(
action: BoundedContinuous(
shape=torch.Size([10, 1, 2]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 1, 2]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 1, 2]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 1])),
device=cpu,
shape=torch.Size([10]))
reward_spec: Composite(
adversary: Composite(
reward: UnboundedContinuous(
shape=torch.Size([10, 2, 1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 2])),
agent: Composite(
reward: UnboundedContinuous(
shape=torch.Size([10, 1, 1]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 1, 1]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 1, 1]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 1])),
device=cpu,
shape=torch.Size([10]))
done_spec: Composite(
done: Categorical(
shape=torch.Size([10, 1]),
space=CategoricalBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
terminated: Categorical(
shape=torch.Size([10, 1]),
space=CategoricalBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
device=cpu,
shape=torch.Size([10]))
observation_spec: Composite(
adversary: Composite(
observation: UnboundedContinuous(
shape=torch.Size([10, 2, 14]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 2, 14]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 2, 14]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 2])),
agent: Composite(
observation: UnboundedContinuous(
shape=torch.Size([10, 1, 12]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([10, 1, 12]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([10, 1, 12]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([10, 1])),
device=cpu,
shape=torch.Size([10]))
使用剛才顯示的命令,我們可以存取每個值的域。
我們可以看到,所有規範都構建為字典,根目錄始終包含群組名稱。此結構將在所有傳入和傳出環境的 tensordict 資料中遵循。此外,每個群組的規範都具有前導形狀 (n_agents_in_that_group)(代理為 1,對手為 2),這意味著該群組的張量資料將始終具有該前導形狀(群組內的代理會堆疊資料)。
查看 done_spec,我們可以發現有些鍵位於代理群組之外("done", "terminated", "truncated"),它們沒有前導多代理維度。這些鍵由所有代理共享,並表示用於重置的環境全局完成狀態。預設情況下,如本例所示,當任何代理完成時,並行 PettingZoo 環境就會完成,但可以透過在 PettingZoo 環境建構中設定 done_on_any 來覆蓋此行為。
為了快速存取 tensordict 中每個這些值的鍵,我們可以簡單地向環境詢問相應的鍵,我們將立即了解哪些是每個代理的,哪些是共享的。此資訊對於告訴所有其他 TorchRL 元件在哪裡可以找到每個值非常有用
print("action_keys:", base_env.action_keys)
print("reward_keys:", base_env.reward_keys)
print("done_keys:", base_env.done_keys)
action_keys: [('adversary', 'action'), ('agent', 'action')]
reward_keys: [('adversary', 'reward'), ('agent', 'reward')]
done_keys: ['done', 'terminated']
轉換 (Transforms)¶
我們可以將任何需要的 TorchRL 轉換附加到我們的環境中。這些轉換將以某種期望的方式修改其輸入/輸出。我們強調,在多代理情境中,明確提供要修改的鍵至關重要。
例如,在這種情況下,我們將實例化一個 RewardSum 轉換,它將對整個 episode 的獎勵進行求和。我們會告訴這個轉換在哪裡可以找到每個獎勵鍵的重置鍵。本質上,我們只是說當 "_reset" tensordict 鍵被設定時,每個群組的 episode 獎勵都應該被重置,這意味著 env.reset() 被呼叫了。轉換後的環境將繼承被包裹環境的裝置和元數據,並根據其包含的轉換序列來轉換這些內容。
env = TransformedEnv(
base_env,
RewardSum(
in_keys=base_env.reward_keys,
reset_keys=["_reset"] * len(base_env.group_map.keys()),
),
)
check_env_specs() 函數會執行一個小的 rollout 並將其輸出與環境規格進行比較。如果沒有引發錯誤,我們可以確信規格已正確定義。
check_env_specs(env)
Rollout¶
為了好玩,讓我們看看一個簡單的隨機 rollout 是什麼樣子的。你可以呼叫 env.rollout(n_steps) 並了解環境輸入和輸出的樣子。動作將自動從動作規格域中隨機抽取。
n_rollout_steps = 5
rollout = env.rollout(n_rollout_steps)
print(f"rollout of {n_rollout_steps} steps:", rollout)
print("Shape of the rollout TensorDict:", rollout.batch_size)
rollout of 5 steps: TensorDict(
fields={
adversary: TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 5, 2, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([10, 5, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 5, 2, 14]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 5, 2]),
device=cpu,
is_shared=False),
agent: TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 5, 1, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([10, 5, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 5, 1, 12]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 5, 1]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([10, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
adversary: TensorDict(
fields={
episode_reward: Tensor(shape=torch.Size([10, 5, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 5, 2, 14]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([10, 5, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 5, 2]),
device=cpu,
is_shared=False),
agent: TensorDict(
fields={
episode_reward: Tensor(shape=torch.Size([10, 5, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 5, 1, 12]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([10, 5, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 5, 1]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([10, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([10, 5]),
device=cpu,
is_shared=False),
terminated: Tensor(shape=torch.Size([10, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([10, 5]),
device=cpu,
is_shared=False)
Shape of the rollout TensorDict: torch.Size([10, 5])
我們可以看到我們的 rollout 的 batch_size 為 (n_rollout_steps)。這意味著其中的所有 tensor 都將具有這個前導維度。
更深入地看,我們可以看到輸出 tensordict 可以按以下方式劃分:
在根目錄 (root) (透過執行
rollout.exclude("next")訪問),我們將找到在第一個 timestep 呼叫 reset 後可用的所有鍵。我們可以透過索引n_rollout_steps維度來查看它們在 rollout 步驟中的演變。在這些鍵中,我們會找到rollout[group_name]tensordicts 中每個代理不同的鍵,它們將具有 batch size(n_rollout_steps, n_agents_in_group),表示它正在儲存額外的代理維度。 group tensordicts 之外的鍵將是共享的鍵。在 next 中 (透過執行
rollout.get("next")訪問)。 我們會發現與根目錄 (root) 相同的結構,但有一些細微的差異,如下所示。
在 TorchRL 中,慣例是 done 和 observations 將同時存在於 root 和 next 中(因為這些在重置時和執行 step 後都可用)。Action 將僅在 root 中可用(因為沒有由 step 產生的 action),而 reward 將僅在 next 中可用(因為重置時沒有 reward)。這種結構遵循 Reinforcement Learning: An Introduction (Sutton and Barto) 中的結構,其中 root 表示時間 \(t\) 的資料,而 next 表示世界步驟中時間 \(t+1\) 的資料。
渲染隨機 Rollout¶
如果你正在使用 Google Colab,或者在一台具有 OpenGL 和 GUI 的機器上,你實際上可以渲染一個隨機 rollout。這將讓你了解一個隨機策略在這個任務中會取得什麼樣的成果,以便與你將自己訓練的策略進行比較!
要渲染 rollout,請按照本教程末尾的 *Render* 部分中的說明進行操作,只需從 env.rollout() 中刪除 policy=agents_exploration_policy 行即可。
策略 (Policy)¶
DDPG 使用確定性策略。這意味著我們的神經網路將輸出要採取的動作。由於動作是連續的,我們使用 Tanh-Delta 分佈來尊重動作空間邊界。這個類別所做的唯一事情是應用 Tanh 轉換以確保動作在域邊界內。
我們需要做出的另一個重要決定是,我們是否希望團隊中的代理 **共享策略參數**。一方面,共享參數意味著他們都將共享相同的策略,這將使他們能夠從彼此的經驗中受益。這也將導致更快的訓練。另一方面,它會使他們的行為同質化,因為他們實際上會共享相同的模型。對於這個例子,我們將啟用共享,因為我們不介意同質性並且可以從計算速度中受益,但在你自己的問題中始終考慮這個決定非常重要!
我們分三個步驟設計策略。
首先:定義一個神經網路 n_obs_per_agent -> n_actions_per_agents
為此,我們使用 MultiAgentMLP,這是一個專門為多代理設計的 TorchRL 模組,具有很多可用的自定義選項。
我們將為每個群組定義不同的策略,並將它們儲存在字典中。
policy_modules = {}
for group, agents in env.group_map.items():
share_parameters_policy = True # Can change this based on the group
policy_net = MultiAgentMLP(
n_agent_inputs=env.observation_spec[group, "observation"].shape[
-1
], # n_obs_per_agent
n_agent_outputs=env.full_action_spec[group, "action"].shape[
-1
], # n_actions_per_agents
n_agents=len(agents), # Number of agents in the group
centralised=False, # the policies are decentralised (i.e., each agent will act from its local observation)
share_params=share_parameters_policy,
device=device,
depth=2,
num_cells=256,
activation_class=torch.nn.Tanh,
)
# Wrap the neural network in a :class:`~tensordict.nn.TensorDictModule`.
# This is simply a module that will read the ``in_keys`` from a tensordict, feed them to the
# neural networks, and write the
# outputs in-place at the ``out_keys``.
policy_module = TensorDictModule(
policy_net,
in_keys=[(group, "observation")],
out_keys=[(group, "param")],
) # We just name the input and output that the network will read and write to the input tensordict
policy_modules[group] = policy_module
第二:將 TensorDictModule 包裹在 ProbabilisticActor 中
我們現在需要建立 TanhDelta 分佈。我們指示 ProbabilisticActor 類別根據策略動作參數建立一個 TanhDelta。我們還提供了此分佈的最小值和最大值,我們從環境規格中收集這些值。
in_keys 的名稱(因此也是上面 TensorDictModule 的 out_keys 的名稱)必須以 TanhDelta 分佈建構子關鍵字參數 (param) 結尾。
policies = {}
for group, _agents in env.group_map.items():
policy = ProbabilisticActor(
module=policy_modules[group],
spec=env.full_action_spec[group, "action"],
in_keys=[(group, "param")],
out_keys=[(group, "action")],
distribution_class=TanhDelta,
distribution_kwargs={
"low": env.full_action_spec[group, "action"].space.low,
"high": env.full_action_spec[group, "action"].space.high,
},
return_log_prob=False,
)
policies[group] = policy
第三:探索 (Exploration)
由於 DDPG 策略是確定性的,我們需要一種在收集過程中執行探索的方法。
為此,我們需要在將策略傳遞給收集器之前,將探索層附加到我們的策略。在這種情況下,我們使用 AdditiveGaussianModule,它將高斯雜訊添加到我們的動作中(如果雜訊使動作超出範圍,則會將其鉗制)。
這個探索包裹器使用一個 sigma 參數,該參數乘以雜訊以確定其幅度。Sigma 可以在整個訓練過程中退火以減少探索。Sigma 將在 annealing_num_steps 中從 sigma_init 變為 sigma_end。
exploration_policies = {}
for group, _agents in env.group_map.items():
exploration_policy = TensorDictSequential(
policies[group],
AdditiveGaussianModule(
spec=policies[group].spec,
annealing_num_steps=total_frames
// 2, # Number of frames after which sigma is sigma_end
action_key=(group, "action"),
sigma_init=0.9, # Initial value of the sigma
sigma_end=0.1, # Final value of the sigma
),
)
exploration_policies[group] = exploration_policy
Critic 網路¶
Critic 網路是 DDPG 演算法的一個關鍵組成部分,即使它沒有在取樣時使用。這個模組將讀取觀察結果和採取的動作,並傳回相應的價值估計。
如同以往,應仔細思考在代理程式群組中共享評論家 (critic) 參數的決策。 一般來說,參數共享可以加速訓練收斂,但有幾個重要的考量因素:
當代理程式具有不同的獎勵函數時,不建議共享,因為評論家需要學習為相同的狀態賦予不同的價值(例如,在混合合作競爭的環境中)。 在這種情況下,由於兩個群組已經在使用獨立的網路,因此共享決策僅適用於群組內的代理程式,我們已經知道它們具有相同的獎勵函數。
在分散式訓練環境中,如果沒有額外的基礎設施來同步參數,則無法執行共享。
在所有其他情況下,如果群組中所有代理程式的獎勵函數(與獎勵有所區別)相同(如目前的情況),則共享可以提供更好的效能。 這可能會以代理程式策略的同質性為代價。 一般來說,判斷哪種選擇更可取的最佳方法是快速實驗兩種選項。
在這裡我們也必須在 MADDPG 和 IDDPG 之間做出選擇
使用 MADDPG,我們將獲得一個具有完全可觀察性的中央評論家(即,它將所有串聯的全局代理程式觀察和動作作為輸入)。 由於我們在模擬器中且訓練是集中式的,因此我們可以這樣做。
使用 IDDPG,我們將擁有一個本地分散式評論家,就像策略一樣。
在任何情況下,評論家的輸出都將具有形狀 (..., n_agents_in_group, 1)。 如果評論家是集中式且共享的,則沿著 n_agents_in_group 維度的所有值都將相同。
與策略一樣,我們為每個群組建立一個評論家網路,並將它們儲存在字典中。
critics = {}
for group, agents in env.group_map.items():
share_parameters_critic = True # Can change for each group
MADDPG = True # IDDPG if False, can change for each group
# This module applies the lambda function: reading the action and observation entries for the group
# and concatenating them in a new ``(group, "obs_action")`` entry
cat_module = TensorDictModule(
lambda obs, action: torch.cat([obs, action], dim=-1),
in_keys=[(group, "observation"), (group, "action")],
out_keys=[(group, "obs_action")],
)
critic_module = TensorDictModule(
module=MultiAgentMLP(
n_agent_inputs=env.observation_spec[group, "observation"].shape[-1]
+ env.full_action_spec[group, "action"].shape[-1],
n_agent_outputs=1, # 1 value per agent
n_agents=len(agents),
centralised=MADDPG,
share_params=share_parameters_critic,
device=device,
depth=2,
num_cells=256,
activation_class=torch.nn.Tanh,
),
in_keys=[(group, "obs_action")], # Read ``(group, "obs_action")``
out_keys=[
(group, "state_action_value")
], # Write ``(group, "state_action_value")``
)
critics[group] = TensorDictSequential(
cat_module, critic_module
) # Run them in sequence
讓我們嘗試我們的策略和評論家模組。 如前所述,使用 TensorDictModule 可以直接讀取環境的輸出以運行這些模組,因為它們知道要讀取哪些資訊以及將資訊寫入何處。
我們可以看到,在每個群組的網路運行後,它們的輸出鍵會新增到群組條目下的資料中。
從這一點開始,已經實例化了特定於多代理程式的元件,我們將簡單地使用與單代理程式學習中相同的元件。 這不是很棒嗎?
reset_td = env.reset()
for group, _agents in env.group_map.items():
print(
f"Running value and policy for group '{group}':",
critics[group](policies[group](reset_td)),
)
Running value and policy for group 'adversary': TensorDict(
fields={
adversary: TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False),
obs_action: Tensor(shape=torch.Size([10, 2, 16]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 2, 14]), device=cpu, dtype=torch.float32, is_shared=False),
param: Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, is_shared=False),
state_action_value: Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 2]),
device=cpu,
is_shared=False),
agent: TensorDict(
fields={
episode_reward: Tensor(shape=torch.Size([10, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 1, 12]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 1]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([10]),
device=cpu,
is_shared=False)
Running value and policy for group 'agent': TensorDict(
fields={
adversary: TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False),
obs_action: Tensor(shape=torch.Size([10, 2, 16]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 2, 14]), device=cpu, dtype=torch.float32, is_shared=False),
param: Tensor(shape=torch.Size([10, 2, 2]), device=cpu, dtype=torch.float32, is_shared=False),
state_action_value: Tensor(shape=torch.Size([10, 2, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 2]),
device=cpu,
is_shared=False),
agent: TensorDict(
fields={
action: Tensor(shape=torch.Size([10, 1, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([10, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False),
obs_action: Tensor(shape=torch.Size([10, 1, 14]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([10, 1, 12]), device=cpu, dtype=torch.float32, is_shared=False),
param: Tensor(shape=torch.Size([10, 1, 2]), device=cpu, dtype=torch.float32, is_shared=False),
state_action_value: Tensor(shape=torch.Size([10, 1, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([10, 1]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([10, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([10]),
device=cpu,
is_shared=False)
資料收集器¶
TorchRL 提供了一組資料收集器類別。 簡而言之,這些類別執行三個操作:重設環境、使用策略和最新觀察計算動作、在環境中執行一個步驟,並重複最後兩個步驟,直到環境發出停止訊號(或達到完成狀態)。
我們將使用最簡單的資料收集器,它具有與環境 rollout 相同的輸出,唯一的區別是它會自動重設已完成的狀態,直到收集到所需的幀數。
我們需要將探索策略饋送給它。 此外,為了像運行一個策略一樣運行所有群組的策略,我們將它們放入一個序列中。 它們不會相互干擾,因為每個群組在不同的位置讀取和寫入鍵。
# Put exploration policies from each group in a sequence
agents_exploration_policy = TensorDictSequential(*exploration_policies.values())
collector = SyncDataCollector(
env,
agents_exploration_policy,
device=device,
frames_per_batch=frames_per_batch,
total_frames=total_frames,
)
重播緩衝區¶
重播緩衝區是離策略 RL 演算法的常見建構塊。 有許多類型的緩衝區,在本教學中,我們使用基本的緩衝區來隨機儲存和取樣 tensordict 資料。
replay_buffers = {}
for group, _agents in env.group_map.items():
replay_buffer = ReplayBuffer(
storage=LazyMemmapStorage(
memory_size, device=device
), # We will store up to memory_size multi-agent transitions
sampler=RandomSampler(),
batch_size=train_batch_size, # We will sample batches of this size
)
replay_buffers[group] = replay_buffer
損失函數¶
為了方便起見,可以使用 DDPGLoss 類別直接從 TorchRL 導入 DDPG 損失。 這是利用 DDPG 最簡單的方法:它隱藏了 DDPG 的數學運算和與之相關的控制流程。
也可以為每個群組設定不同的策略。
losses = {}
for group, _agents in env.group_map.items():
loss_module = DDPGLoss(
actor_network=policies[group], # Use the non-explorative policies
value_network=critics[group],
delay_value=True, # Whether to use a target network for the value
loss_function="l2",
)
loss_module.set_keys(
state_action_value=(group, "state_action_value"),
reward=(group, "reward"),
done=(group, "done"),
terminated=(group, "terminated"),
)
loss_module.make_value_estimator(ValueEstimators.TD0, gamma=gamma)
losses[group] = loss_module
target_updaters = {
group: SoftUpdate(loss, tau=polyak_tau) for group, loss in losses.items()
}
optimisers = {
group: {
"loss_actor": torch.optim.Adam(
loss.actor_network_params.flatten_keys().values(), lr=lr
),
"loss_value": torch.optim.Adam(
loss.value_network_params.flatten_keys().values(), lr=lr
),
}
for group, loss in losses.items()
}
訓練工具¶
我們確實需要定義兩個輔助函數,我們將在訓練迴圈中使用它們。 它們非常簡單,不包含任何重要的邏輯。
def process_batch(batch: TensorDictBase) -> TensorDictBase:
"""
If the `(group, "terminated")` and `(group, "done")` keys are not present, create them by expanding
`"terminated"` and `"done"`.
This is needed to present them with the same shape as the reward to the loss.
"""
for group in env.group_map.keys():
keys = list(batch.keys(True, True))
group_shape = batch.get_item_shape(group)
nested_done_key = ("next", group, "done")
nested_terminated_key = ("next", group, "terminated")
if nested_done_key not in keys:
batch.set(
nested_done_key,
batch.get(("next", "done")).unsqueeze(-1).expand((*group_shape, 1)),
)
if nested_terminated_key not in keys:
batch.set(
nested_terminated_key,
batch.get(("next", "terminated"))
.unsqueeze(-1)
.expand((*group_shape, 1)),
)
return batch
訓練迴圈¶
我們現在擁有編寫訓練迴圈所需的所有元件。 這些步驟包括
- 收集所有群組的資料
- 迴圈遍歷群組
將群組資料儲存在群組緩衝區中
- 迴圈遍歷 epochs
從群組緩衝區取樣
計算取樣資料的損失
反向傳播損失
最佳化
重複
重複
重複
pbar = tqdm(
total=n_iters,
desc=", ".join(
[f"episode_reward_mean_{group} = 0" for group in env.group_map.keys()]
),
)
episode_reward_mean_map = {group: [] for group in env.group_map.keys()}
train_group_map = copy.deepcopy(env.group_map)
# Training/collection iterations
for iteration, batch in enumerate(collector):
current_frames = batch.numel()
batch = process_batch(batch) # Util to expand done keys if needed
# Loop over groups
for group in train_group_map.keys():
group_batch = batch.exclude(
*[
key
for _group in env.group_map.keys()
if _group != group
for key in [_group, ("next", _group)]
]
) # Exclude data from other groups
group_batch = group_batch.reshape(
-1
) # This just affects the leading dimensions in batch_size of the tensordict
replay_buffers[group].extend(group_batch)
for _ in range(n_optimiser_steps):
subdata = replay_buffers[group].sample()
loss_vals = losses[group](subdata)
for loss_name in ["loss_actor", "loss_value"]:
loss = loss_vals[loss_name]
optimiser = optimisers[group][loss_name]
loss.backward()
# Optional
params = optimiser.param_groups[0]["params"]
torch.nn.utils.clip_grad_norm_(params, max_grad_norm)
optimiser.step()
optimiser.zero_grad()
# Soft-update the target network
target_updaters[group].step()
# Exploration sigma anneal update
exploration_policies[group][-1].step(current_frames)
# Stop training a certain group when a condition is met (e.g., number of training iterations)
if iteration == iteration_when_stop_training_evaders:
del train_group_map["agent"]
# Logging
for group in env.group_map.keys():
episode_reward_mean = (
batch.get(("next", group, "episode_reward"))[
batch.get(("next", group, "done"))
]
.mean()
.item()
)
episode_reward_mean_map[group].append(episode_reward_mean)
pbar.set_description(
", ".join(
[
f"episode_reward_mean_{group} = {episode_reward_mean_map[group][-1]}"
for group in env.group_map.keys()
]
),
refresh=False,
)
pbar.update()
episode_reward_mean_adversary = 0, episode_reward_mean_agent = 0: 0%| | 0/10 [00:00<?, ?it/s]
episode_reward_mean_adversary = 1.0, episode_reward_mean_agent = -1.0: 10%|█ | 1/10 [00:02<00:26, 2.96s/it]
episode_reward_mean_adversary = 0.0, episode_reward_mean_agent = 0.0: 20%|██ | 2/10 [00:06<00:24, 3.07s/it]
episode_reward_mean_adversary = 1.0, episode_reward_mean_agent = -1.0: 30%|███ | 3/10 [00:09<00:21, 3.14s/it]
episode_reward_mean_adversary = 0.0, episode_reward_mean_agent = 0.0: 40%|████ | 4/10 [00:12<00:18, 3.15s/it]
episode_reward_mean_adversary = 2.0, episode_reward_mean_agent = -2.0: 50%|█████ | 5/10 [00:15<00:15, 3.15s/it]
episode_reward_mean_adversary = 0.0, episode_reward_mean_agent = 0.0: 60%|██████ | 6/10 [00:18<00:12, 3.13s/it]
episode_reward_mean_adversary = 2.0, episode_reward_mean_agent = -2.0: 70%|███████ | 7/10 [00:21<00:08, 2.86s/it]
episode_reward_mean_adversary = 0.0, episode_reward_mean_agent = 0.0: 80%|████████ | 8/10 [00:23<00:05, 2.69s/it]
episode_reward_mean_adversary = 0.0, episode_reward_mean_agent = 0.0: 90%|█████████ | 9/10 [00:25<00:02, 2.58s/it]
episode_reward_mean_adversary = 1.0, episode_reward_mean_agent = -1.0: 100%|██████████| 10/10 [00:27<00:00, 2.47s/it]
結果¶
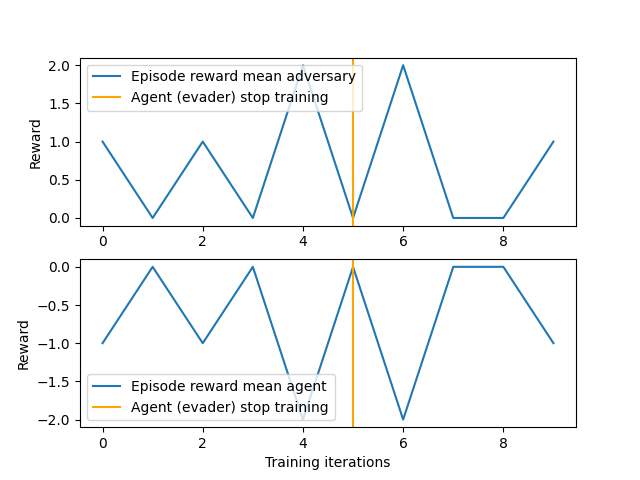
我們可以繪製每個 episode 獲得的平均獎勵。
要使訓練持續更長時間,請增加 n_iters 超參數。
在本地運行此腳本時,您可能需要關閉已開啟的視窗才能繼續執行螢幕的其餘部分。
fig, axs = plt.subplots(2, 1)
for i, group in enumerate(env.group_map.keys()):
axs[i].plot(episode_reward_mean_map[group], label=f"Episode reward mean {group}")
axs[i].set_ylabel("Reward")
axs[i].axvline(
x=iteration_when_stop_training_evaders,
label="Agent (evader) stop training",
color="orange",
)
axs[i].legend()
axs[-1].set_xlabel("Training iterations")
plt.show()
渲染¶
渲染說明適用於 VMAS,也就是在使用 use_vmas=True 運行時。
TorchRL 提供了一些工具來錄製和儲存渲染的影片。 您可以在此處了解有關這些工具的更多資訊。
在下面的程式碼區塊中,我們附加了一個轉換,它將呼叫 VMAS 包裝環境中的 render() 方法,並將幀堆疊儲存到一個 mp4 檔案中,該檔案的位置由自訂記錄器 video_logger 決定。 請注意,此程式碼可能需要一些外部依賴項,例如 torchvision。
if use_vmas and not is_sphinx:
# Replace tmpdir with any desired path where the video should be saved
with tempfile.TemporaryDirectory() as tmpdir:
video_logger = CSVLogger("vmas_logs", tmpdir, video_format="mp4")
print("Creating rendering env")
env_with_render = TransformedEnv(env.base_env, env.transform.clone())
env_with_render = env_with_render.append_transform(
PixelRenderTransform(
out_keys=["pixels"],
# the np.ndarray has a negative stride and needs to be copied before being cast to a tensor
preproc=lambda x: x.copy(),
as_non_tensor=True,
# asking for array rather than on-screen rendering
mode="rgb_array",
)
)
env_with_render = env_with_render.append_transform(
VideoRecorder(logger=video_logger, tag="vmas_rendered")
)
with set_exploration_type(ExplorationType.DETERMINISTIC):
print("Rendering rollout...")
env_with_render.rollout(100, policy=agents_exploration_policy)
print("Saving the video...")
env_with_render.transform.dump()
print("Saved! Saved directory tree:")
video_logger.print_log_dir()
結論和後續步驟¶
在本教學中,我們已經看到了
如何在 TorchRL 中建立競爭性的多群組多代理程式環境、其規格如何運作以及它如何與該函式庫整合;
如何在 TorchRL 中為多個群組建立多代理程式網路架構;
我們如何使用
tensordict.TensorDict攜帶多代理程式多群組資料;我們如何將所有函式庫元件(收集器、模組、重播緩衝區和損失)綁定到多代理程式多群組 MADDPG/IDDPG 訓練迴圈中。
現在您已經精通多代理程式 DDPG,您可以查看 GitHub 儲存庫中的所有 TorchRL 多代理程式實作。 這些是許多 MARL 演算法的純程式碼腳本,例如本教學中看到的那些、QMIX、MADDPG、IQL 以及更多!
也請記住查看我們的教學:使用 TorchRL 教學的多代理程式強化學習 (PPO)。
最後,您可以修改本教學的參數,以嘗試許多其他配置和場景,從而成為 MARL 大師。
PettingZoo 和 VMAS 包含更多情境。以下是一些您可以在 VMAS 中嘗試的可能情境的影片。

腳本總執行時間: (1 分鐘 31.974 秒)
估計記憶體用量: 323 MB
