


注意
點擊此處下載完整的範例程式碼
音訊資料擴增¶
作者: Moto Hira
torchaudio 提供多種擴增音訊資料的方法。
在本教學課程中,我們將研究應用效果、濾波器、RIR(房間脈衝響應)和編解碼器的方法。
最後,我們將乾淨的語音合成成電話中的嘈雜語音。
import torch
import torchaudio
import torchaudio.functional as F
print(torch.__version__)
print(torchaudio.__version__)
import matplotlib.pyplot as plt
2.6.0
2.6.0
準備工作¶
首先,我們導入模組並下載本教學課程中使用的音訊資產。
from IPython.display import Audio
from torchaudio.utils import download_asset
SAMPLE_WAV = download_asset("tutorial-assets/steam-train-whistle-daniel_simon.wav")
SAMPLE_RIR = download_asset("tutorial-assets/Lab41-SRI-VOiCES-rm1-impulse-mc01-stu-clo-8000hz.wav")
SAMPLE_SPEECH = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042-8000hz.wav")
SAMPLE_NOISE = download_asset("tutorial-assets/Lab41-SRI-VOiCES-rm1-babb-mc01-stu-clo-8000hz.wav")
0%| | 0.00/427k [00:00<?, ?B/s]
100%|##########| 427k/427k [00:00<00:00, 56.9MB/s]
0%| | 0.00/31.3k [00:00<?, ?B/s]
100%|##########| 31.3k/31.3k [00:00<00:00, 34.5MB/s]
0%| | 0.00/78.2k [00:00<?, ?B/s]
100%|##########| 78.2k/78.2k [00:00<00:00, 61.6MB/s]
應用效果和濾波¶
torchaudio.io.AudioEffector 允許直接將濾波器和編解碼器應用於 Tensor 物件,方式與 ffmpeg 命令類似
AudioEffector 用法 <./effector_tutorial.html> 說明如何使用此類別,詳細資訊請參閱該教學課程。
# Load the data
waveform1, sample_rate = torchaudio.load(SAMPLE_WAV, channels_first=False)
# Define effects
effect = ",".join(
[
"lowpass=frequency=300:poles=1", # apply single-pole lowpass filter
"atempo=0.8", # reduce the speed
"aecho=in_gain=0.8:out_gain=0.9:delays=200:decays=0.3|delays=400:decays=0.3"
# Applying echo gives some dramatic feeling
],
)
# Apply effects
def apply_effect(waveform, sample_rate, effect):
effector = torchaudio.io.AudioEffector(effect=effect)
return effector.apply(waveform, sample_rate)
waveform2 = apply_effect(waveform1, sample_rate, effect)
print(waveform1.shape, sample_rate)
print(waveform2.shape, sample_rate)
torch.Size([109368, 2]) 44100
torch.Size([144642, 2]) 44100
請注意,套用效果後,幀數和頻道數與原始幀數和頻道數不同。 讓我們聽聽音訊。
def plot_waveform(waveform, sample_rate, title="Waveform", xlim=None):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
time_axis = torch.arange(0, num_frames) / sample_rate
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].plot(time_axis, waveform[c], linewidth=1)
axes[c].grid(True)
if num_channels > 1:
axes[c].set_ylabel(f"Channel {c+1}")
if xlim:
axes[c].set_xlim(xlim)
figure.suptitle(title)
def plot_specgram(waveform, sample_rate, title="Spectrogram", xlim=None):
waveform = waveform.numpy()
num_channels, _ = waveform.shape
figure, axes = plt.subplots(num_channels, 1)
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].specgram(waveform[c], Fs=sample_rate)
if num_channels > 1:
axes[c].set_ylabel(f"Channel {c+1}")
if xlim:
axes[c].set_xlim(xlim)
figure.suptitle(title)
原始音訊¶
plot_waveform(waveform1.T, sample_rate, title="Original", xlim=(-0.1, 3.2))
plot_specgram(waveform1.T, sample_rate, title="Original", xlim=(0, 3.04))
Audio(waveform1.T, rate=sample_rate)
已套用效果¶
plot_waveform(waveform2.T, sample_rate, title="Effects Applied", xlim=(-0.1, 3.2))
plot_specgram(waveform2.T, sample_rate, title="Effects Applied", xlim=(0, 3.04))
Audio(waveform2.T, rate=sample_rate)
模擬房間迴響¶
卷積迴響是一種用於使乾淨音訊聽起來像是在不同環境中產生的技術。
例如,使用房間脈衝響應 (RIR),我們可以使乾淨的語音聽起來像是在會議室中說出的。
對於此過程,我們需要 RIR 資料。 以下資料來自 VOiCES 資料集,但您可以錄製自己的資料 - 只需打開麥克風並拍手。
rir_raw, sample_rate = torchaudio.load(SAMPLE_RIR)
plot_waveform(rir_raw, sample_rate, title="Room Impulse Response (raw)")
plot_specgram(rir_raw, sample_rate, title="Room Impulse Response (raw)")
Audio(rir_raw, rate=sample_rate)
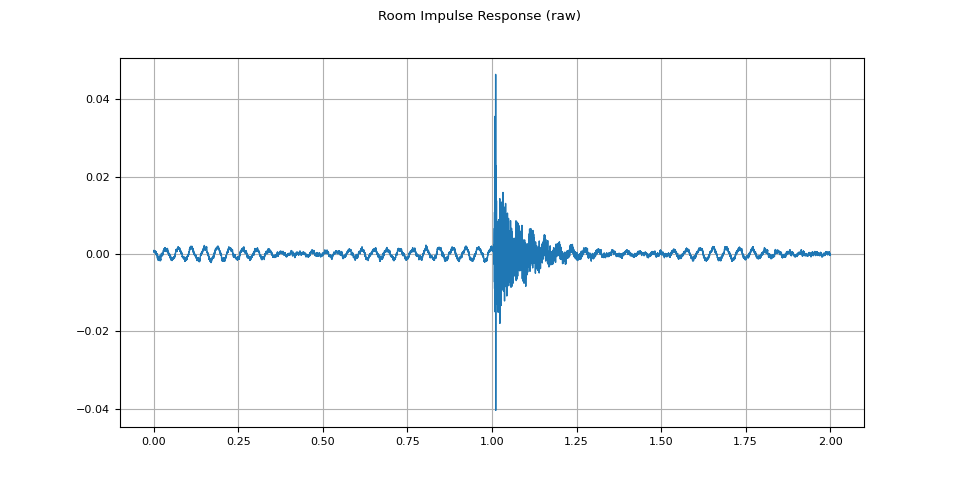
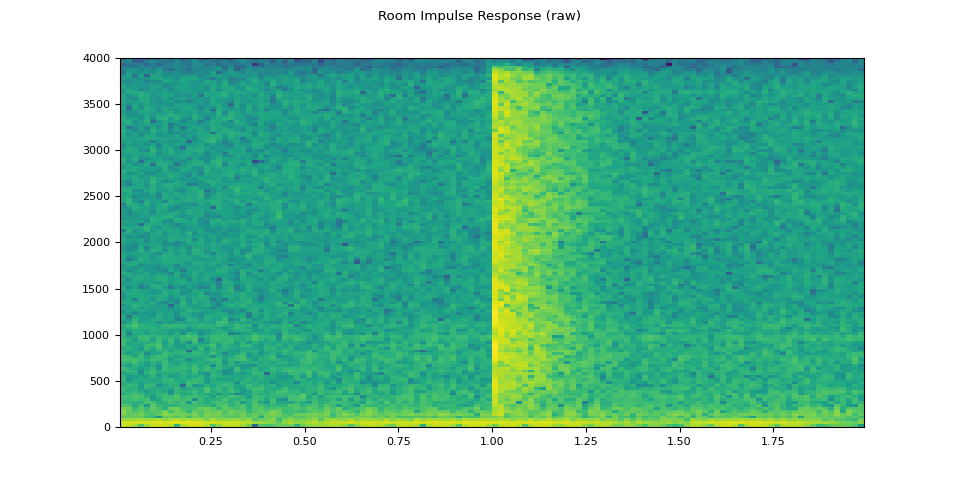
首先,我們需要清理 RIR。 我們提取主要脈衝並通過其功率對其進行歸一化。
rir = rir_raw[:, int(sample_rate * 1.01) : int(sample_rate * 1.3)]
rir = rir / torch.linalg.vector_norm(rir, ord=2)
plot_waveform(rir, sample_rate, title="Room Impulse Response")
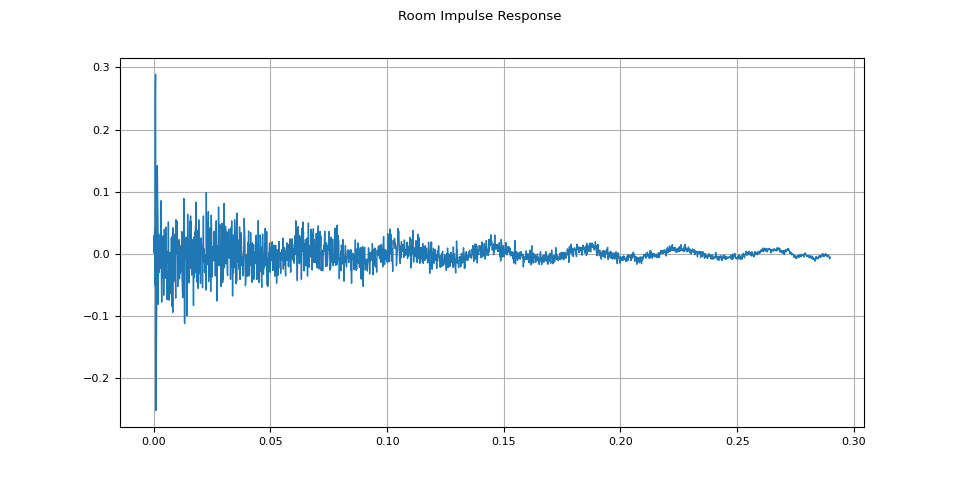
然後,使用 torchaudio.functional.fftconvolve(),我們將語音訊號與 RIR 進行卷積。
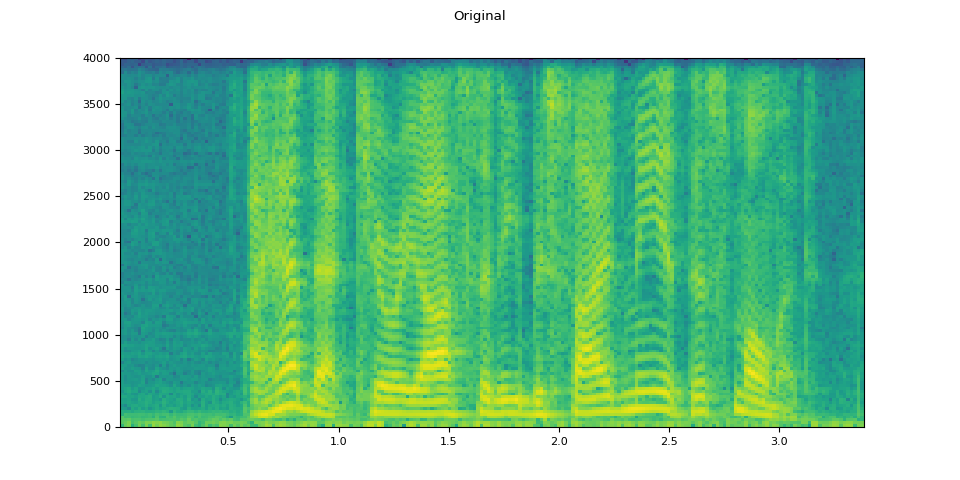
原始音訊¶
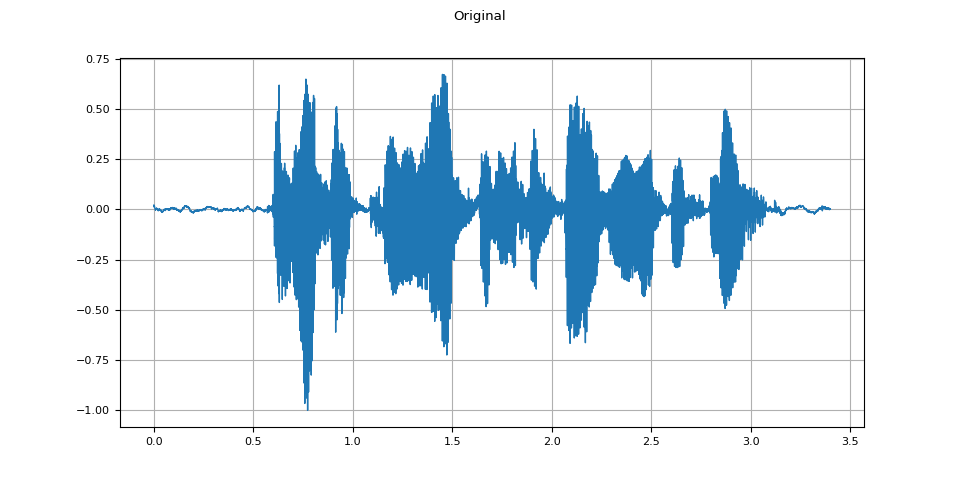
plot_waveform(speech, sample_rate, title="Original")
plot_specgram(speech, sample_rate, title="Original")
Audio(speech, rate=sample_rate)
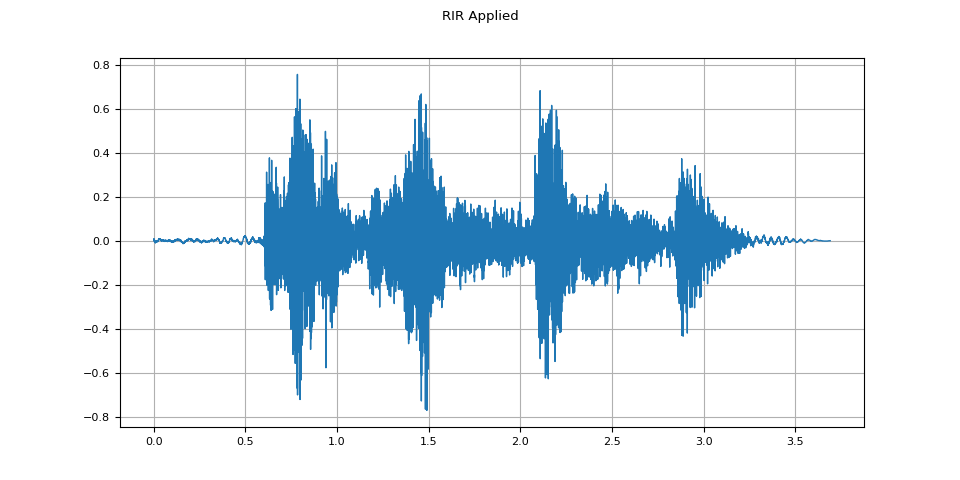
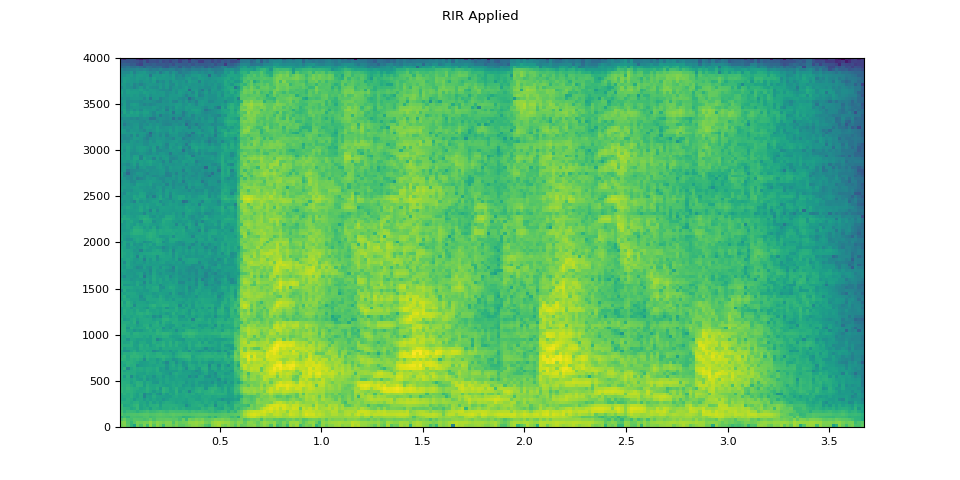
RIR (室內脈衝響應) 應用¶
plot_waveform(augmented, sample_rate, title="RIR Applied")
plot_specgram(augmented, sample_rate, title="RIR Applied")
Audio(augmented, rate=sample_rate)
加入背景噪音¶
為了將背景噪音加入至音訊資料中,我們可以根據所需的訊噪比 (SNR) 將一個噪音張量加到代表音訊資料的張量上 [維基百科],它決定了輸出中音訊資料相對於噪音的強度。
$$ \mathrm{SNR} = \frac{P_{signal}}{P_{noise}} $$
$$ \mathrm{SNR_{dB}} = 10 \log _{{10}} \mathrm {SNR} $$
為了根據訊噪比將噪音加入到音訊資料中,我們使用 torchaudio.functional.add_noise()。
speech, _ = torchaudio.load(SAMPLE_SPEECH)
noise, _ = torchaudio.load(SAMPLE_NOISE)
noise = noise[:, : speech.shape[1]]
snr_dbs = torch.tensor([20, 10, 3])
noisy_speeches = F.add_noise(speech, noise, snr_dbs)
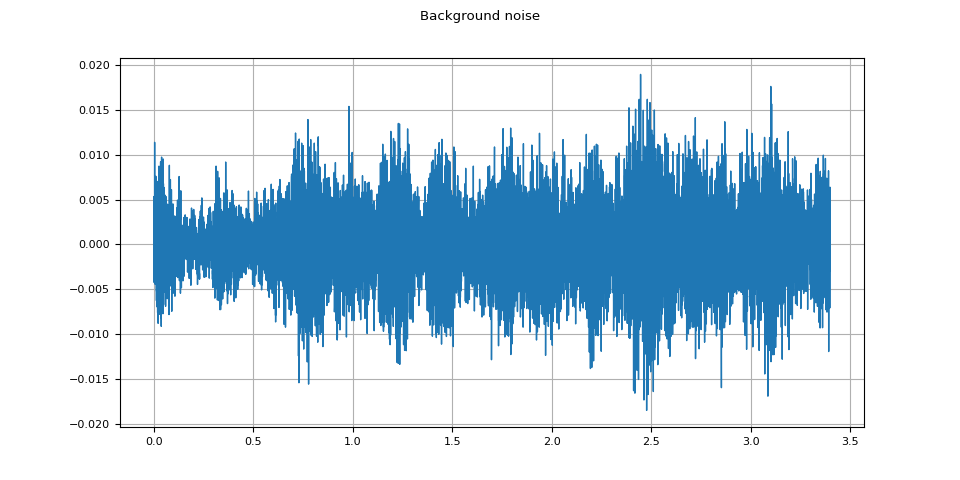
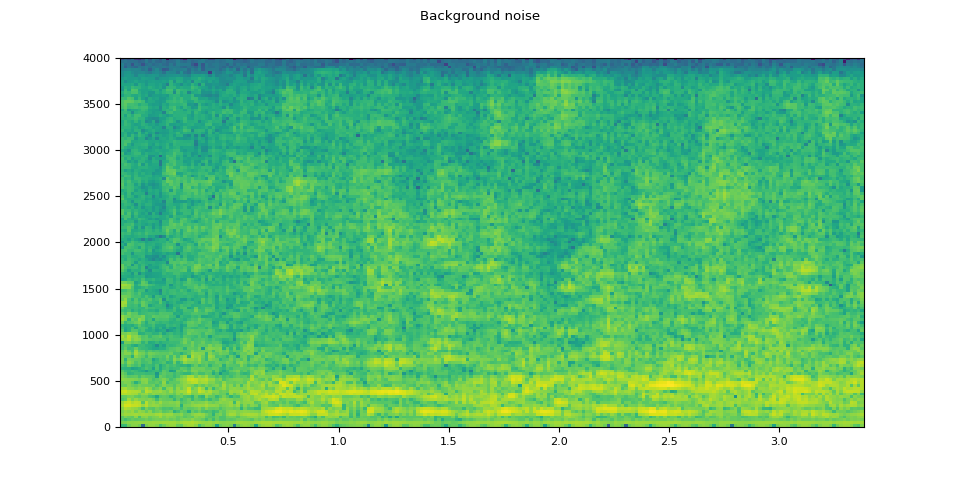
背景噪音¶
plot_waveform(noise, sample_rate, title="Background noise")
plot_specgram(noise, sample_rate, title="Background noise")
Audio(noise, rate=sample_rate)
訊噪比 20 dB¶
snr_db, noisy_speech = snr_dbs[0], noisy_speeches[0:1]
plot_waveform(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
plot_specgram(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
Audio(noisy_speech, rate=sample_rate)
![SNR: 20 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_014.png)
![SNR: 20 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_015.png)
訊噪比 10 dB¶
snr_db, noisy_speech = snr_dbs[1], noisy_speeches[1:2]
plot_waveform(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
plot_specgram(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
Audio(noisy_speech, rate=sample_rate)
![SNR: 10 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_016.png)
![SNR: 10 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_017.png)
訊噪比 3 dB¶
snr_db, noisy_speech = snr_dbs[2], noisy_speeches[2:3]
plot_waveform(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
plot_specgram(noisy_speech, sample_rate, title=f"SNR: {snr_db} [dB]")
Audio(noisy_speech, rate=sample_rate)
![SNR: 3 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_018.png)
![SNR: 3 [dB]](../_images/sphx_glr_audio_data_augmentation_tutorial_019.png)
將編解碼器應用於張量物件¶
torchaudio.io.AudioEffector 也可以將編解碼器應用於張量物件。
waveform, sample_rate = torchaudio.load(SAMPLE_SPEECH, channels_first=False)
def apply_codec(waveform, sample_rate, format, encoder=None):
encoder = torchaudio.io.AudioEffector(format=format, encoder=encoder)
return encoder.apply(waveform, sample_rate)
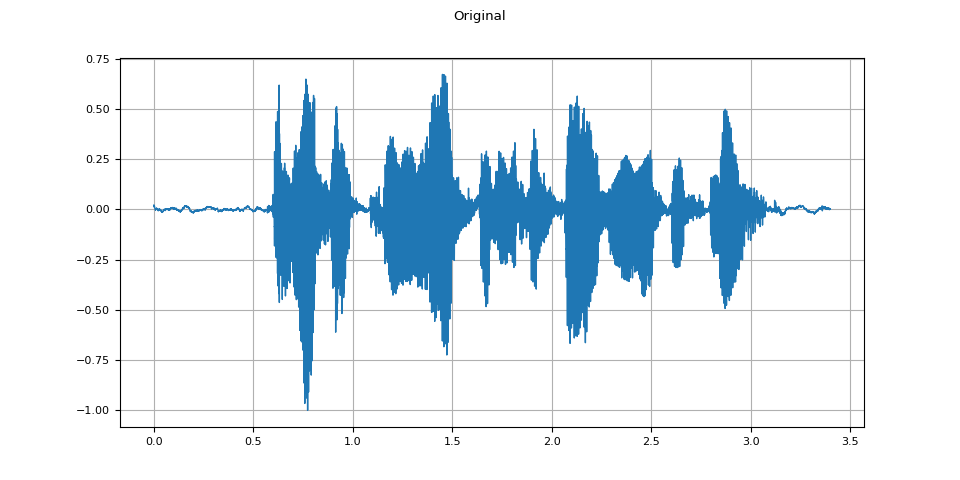
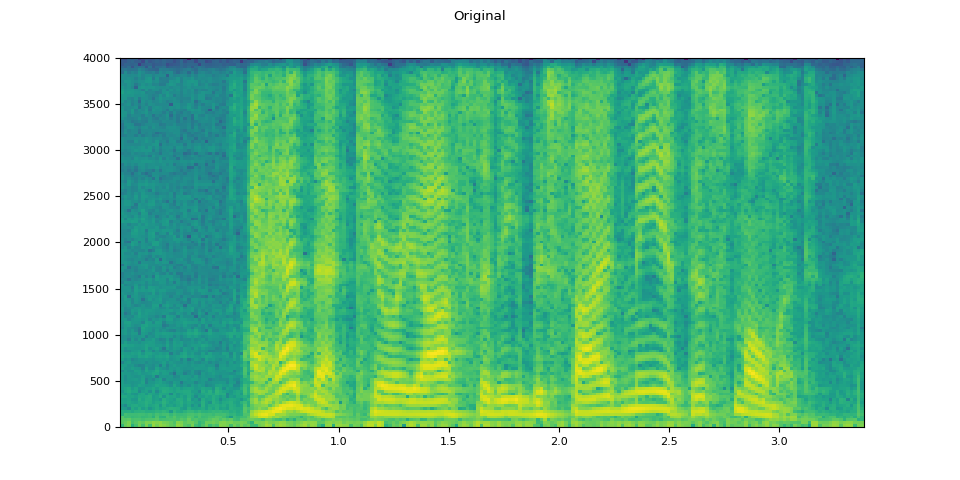
原始音訊¶
plot_waveform(waveform.T, sample_rate, title="Original")
plot_specgram(waveform.T, sample_rate, title="Original")
Audio(waveform.T, rate=sample_rate)
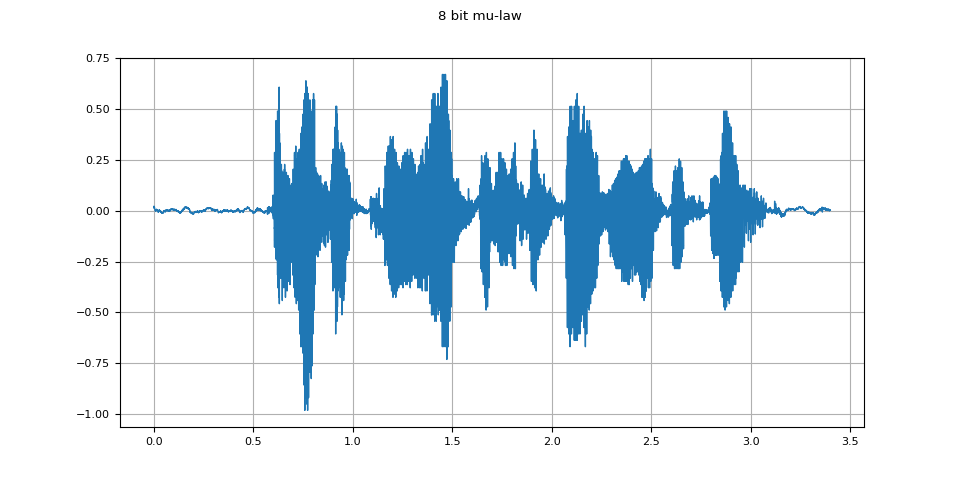
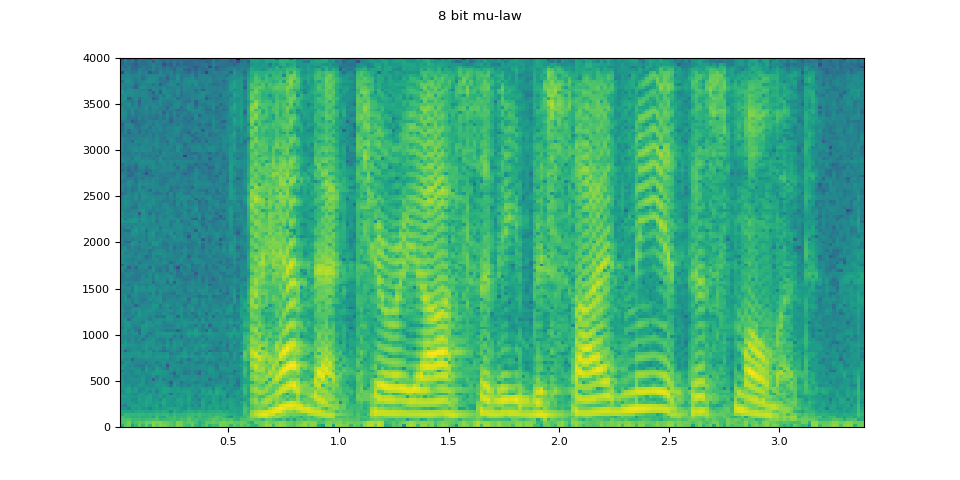
8 位元 mu-law¶
mulaw = apply_codec(waveform, sample_rate, "wav", encoder="pcm_mulaw")
plot_waveform(mulaw.T, sample_rate, title="8 bit mu-law")
plot_specgram(mulaw.T, sample_rate, title="8 bit mu-law")
Audio(mulaw.T, rate=sample_rate)
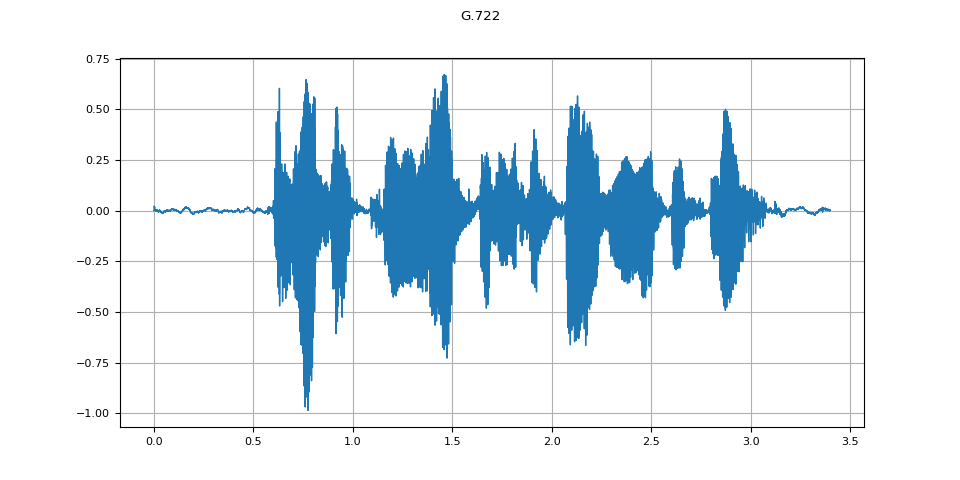
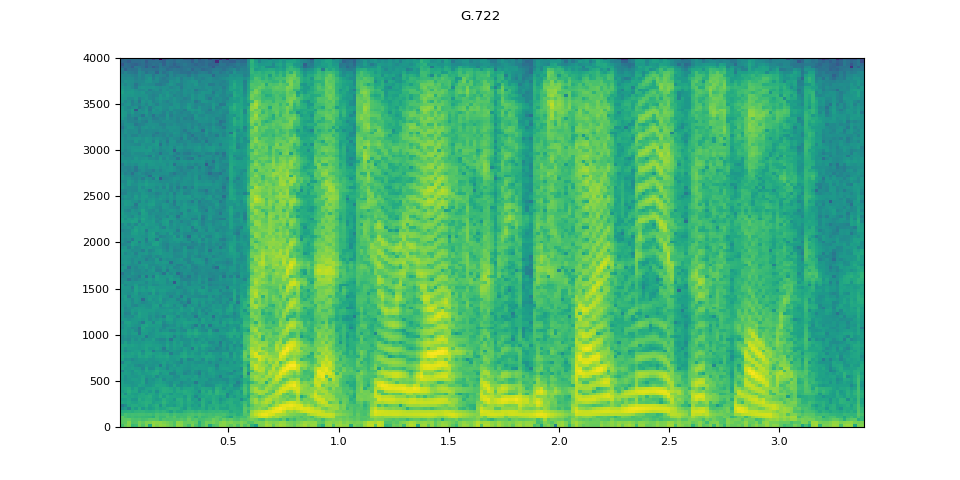
G.722¶
g722 = apply_codec(waveform, sample_rate, "g722")
plot_waveform(g722.T, sample_rate, title="G.722")
plot_specgram(g722.T, sample_rate, title="G.722")
Audio(g722.T, rate=sample_rate)
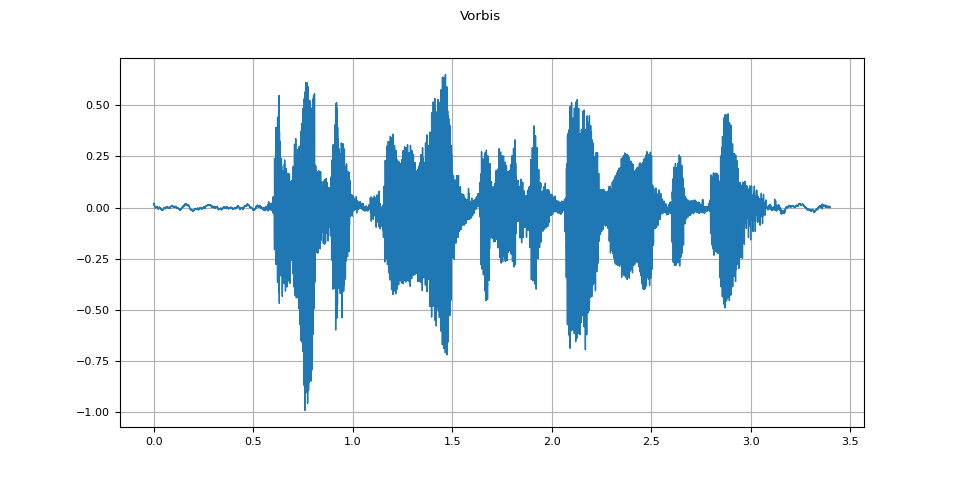
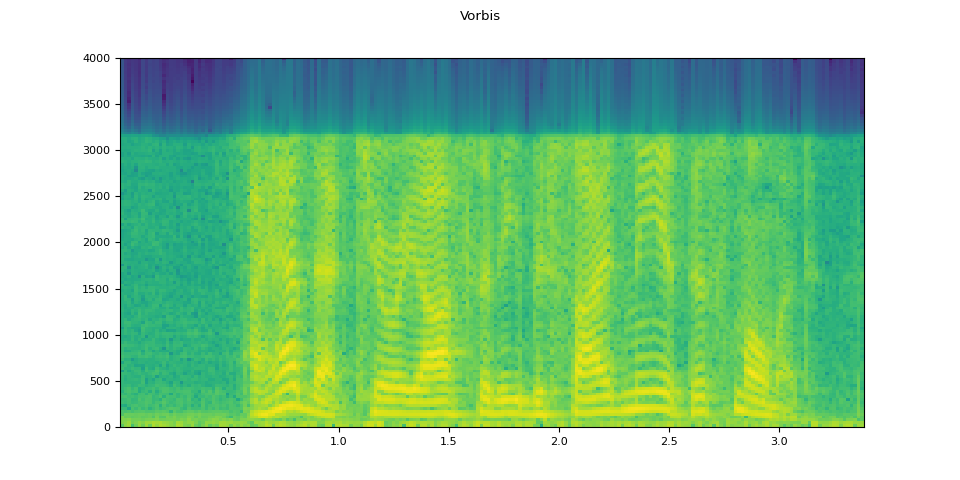
Vorbis¶
vorbis = apply_codec(waveform, sample_rate, "ogg", encoder="vorbis")
plot_waveform(vorbis.T, sample_rate, title="Vorbis")
plot_specgram(vorbis.T, sample_rate, title="Vorbis")
Audio(vorbis.T, rate=sample_rate)
模擬電話錄音¶
結合先前的技術,我們可以模擬聽起來像是在一個迴音房間裡,有人在背景噪音中透過電話交談的音訊。
sample_rate = 16000
original_speech, sample_rate = torchaudio.load(SAMPLE_SPEECH)
plot_specgram(original_speech, sample_rate, title="Original")
# Apply RIR
rir_applied = F.fftconvolve(speech, rir)
plot_specgram(rir_applied, sample_rate, title="RIR Applied")
# Add background noise
# Because the noise is recorded in the actual environment, we consider that
# the noise contains the acoustic feature of the environment. Therefore, we add
# the noise after RIR application.
noise, _ = torchaudio.load(SAMPLE_NOISE)
noise = noise[:, : rir_applied.shape[1]]
snr_db = torch.tensor([8])
bg_added = F.add_noise(rir_applied, noise, snr_db)
plot_specgram(bg_added, sample_rate, title="BG noise added")
# Apply filtering and change sample rate
effect = ",".join(
[
"lowpass=frequency=4000:poles=1",
"compand=attacks=0.02:decays=0.05:points=-60/-60|-30/-10|-20/-8|-5/-8|-2/-8:gain=-8:volume=-7:delay=0.05",
]
)
filtered = apply_effect(bg_added.T, sample_rate, effect)
sample_rate2 = 8000
plot_specgram(filtered.T, sample_rate2, title="Filtered")
# Apply telephony codec
codec_applied = apply_codec(filtered, sample_rate2, "g722")
plot_specgram(codec_applied.T, sample_rate2, title="G.722 Codec Applied")
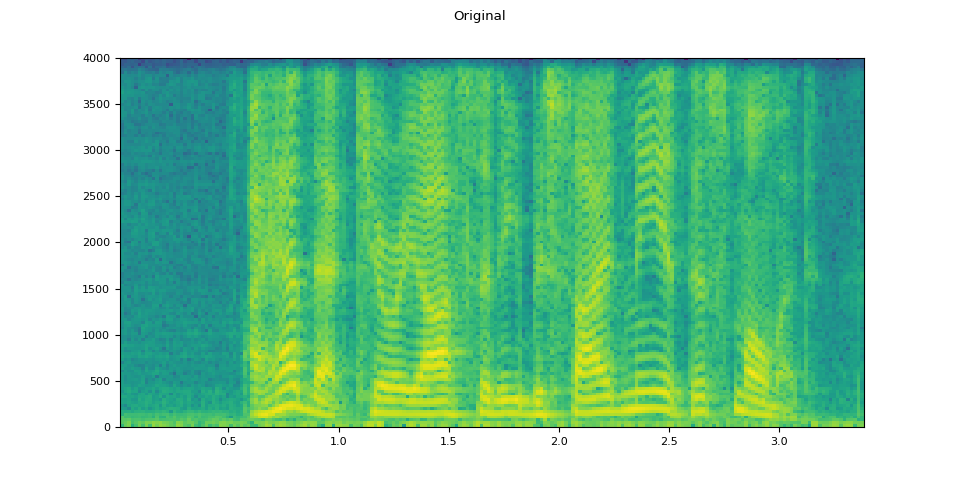
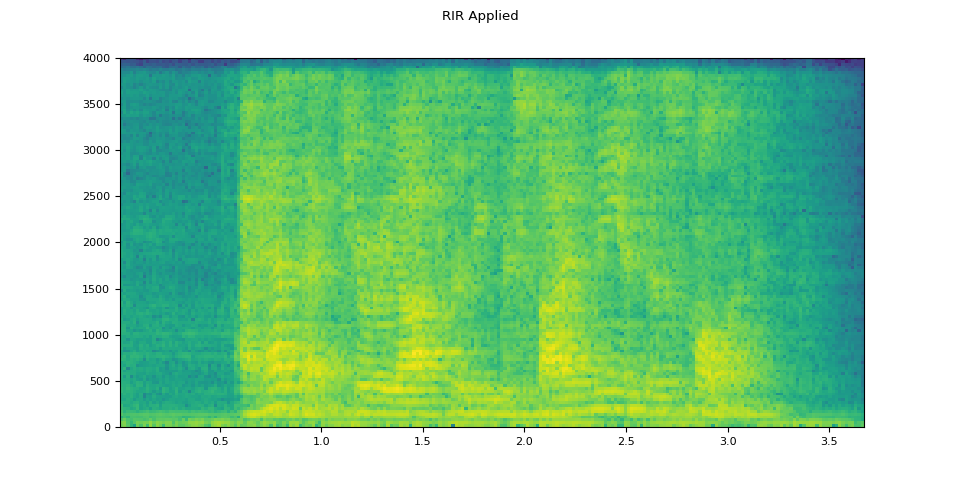
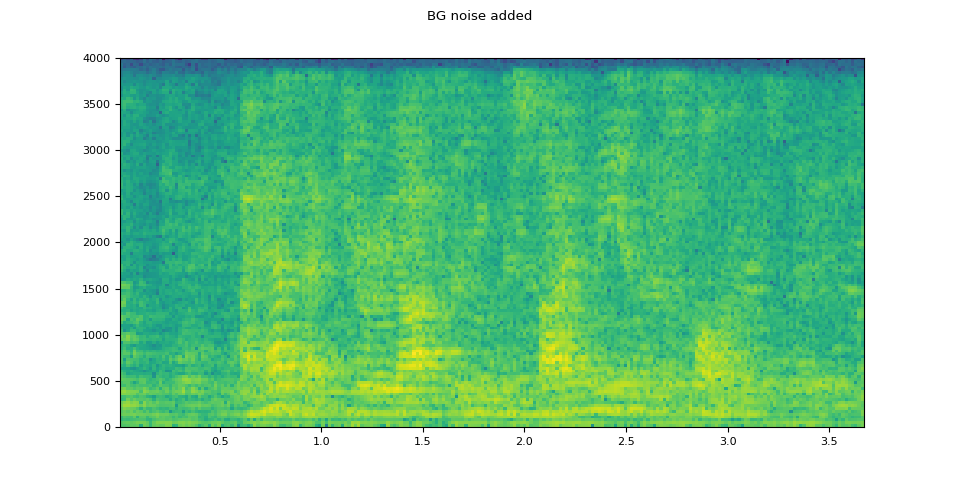
原始語音¶
Audio(original_speech, rate=sample_rate)
RIR (室內脈衝響應) 應用¶
Audio(rir_applied, rate=sample_rate)
加入背景噪音¶
Audio(bg_added, rate=sample_rate)
已濾波¶
Audio(filtered.T, rate=sample_rate2)
編解碼器應用¶
Audio(codec_applied.T, rate=sample_rate2)
腳本的總執行時間: ( 0 分鐘 14.991 秒)
