


注意
點擊這裡下載完整的範例程式碼
使用 CTC 解碼器的 ASR 推論¶
作者: Caroline Chen
本教學示範如何使用具有詞彙限制和 KenLM 語言模型支援的 CTC 波束搜尋解碼器執行語音辨識推論。我們在一個使用 CTC 損失訓練的預訓練 wav2vec 2.0 模型上示範此操作。
概述¶
波束搜尋解碼的工作原理是透過迭代擴展具有下一個可能字元的文本假設(波束),並且在每個時間步僅維護具有最高分數的假設。語言模型可以被納入到評分計算中,並且新增詞彙限制可以限制假設的下一個可能的符記,以便只能產生來自詞彙表的單字。
底層實作移植自Flashlight的波束搜尋解碼器。有關解碼器最佳化的數學公式可以在Wav2Letter 論文中找到,更詳細的演算法可以在這篇部落格中找到。
使用具有語言模型和詞彙限制的 CTC 波束搜尋解碼器執行 ASR 推論需要以下元件
聲學模型:從音訊波形預測音素的模型
符記:來自聲學模型的可預測符記
詞彙:可能單字和其對應符記序列之間的映射
語言模型 (LM):使用KenLM 函式庫訓練的 n 元語法語言模型,或繼承
CTCDecoderLM的自訂語言模型
聲學模型和設定¶
首先,我們導入必要的工具,並獲取我們要處理的資料。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.6.0
2.6.0
import time
from typing import List
import IPython
import matplotlib.pyplot as plt
from torchaudio.models.decoder import ctc_decoder
from torchaudio.utils import download_asset
我們使用在 LibriSpeech 資料集上微調 10 分鐘的 Wav2Vec 2.0 Base 預訓練模型,該模型可以使用 torchaudio.pipelines.WAV2VEC2_ASR_BASE_10M 載入。 有關在 torchaudio 中運行 Wav2Vec 2.0 語音識別流程的更多詳細信息,請參閱 本教學。
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_10M
acoustic_model = bundle.get_model()
Downloading: "https://download.pytorch.org/torchaudio/models/wav2vec2_fairseq_base_ls960_asr_ll10m.pth" to /root/.cache/torch/hub/checkpoints/wav2vec2_fairseq_base_ls960_asr_ll10m.pth
0%| | 0.00/360M [00:00<?, ?B/s]
4%|4 | 16.0M/360M [00:00<00:05, 68.5MB/s]
9%|8 | 32.0M/360M [00:00<00:06, 55.2MB/s]
13%|#3 | 46.9M/360M [00:00<00:06, 51.9MB/s]
14%|#4 | 52.0M/360M [00:01<00:07, 42.8MB/s]
18%|#7 | 64.0M/360M [00:01<00:06, 50.6MB/s]
22%|##2 | 80.0M/360M [00:01<00:04, 59.0MB/s]
27%|##6 | 96.0M/360M [00:01<00:04, 66.3MB/s]
31%|###1 | 112M/360M [00:01<00:03, 69.0MB/s]
35%|###5 | 127M/360M [00:02<00:03, 77.1MB/s]
37%|###7 | 135M/360M [00:02<00:03, 65.5MB/s]
40%|###9 | 144M/360M [00:02<00:03, 58.2MB/s]
42%|####1 | 150M/360M [00:02<00:03, 56.5MB/s]
43%|####3 | 155M/360M [00:03<00:05, 35.9MB/s]
44%|####4 | 160M/360M [00:03<00:06, 32.4MB/s]
49%|####8 | 175M/360M [00:03<00:04, 40.8MB/s]
50%|####9 | 179M/360M [00:03<00:04, 38.5MB/s]
53%|#####3 | 192M/360M [00:03<00:03, 52.3MB/s]
58%|#####7 | 208M/360M [00:04<00:03, 51.5MB/s]
62%|######1 | 223M/360M [00:04<00:02, 64.2MB/s]
64%|######3 | 230M/360M [00:04<00:02, 45.7MB/s]
67%|######6 | 240M/360M [00:05<00:04, 29.1MB/s]
68%|######7 | 244M/360M [00:05<00:04, 29.3MB/s]
69%|######9 | 249M/360M [00:05<00:03, 31.7MB/s]
71%|#######1 | 256M/360M [00:05<00:03, 33.7MB/s]
72%|#######2 | 260M/360M [00:06<00:03, 27.9MB/s]
76%|#######5 | 272M/360M [00:06<00:02, 38.5MB/s]
80%|#######9 | 287M/360M [00:06<00:01, 55.5MB/s]
82%|########1 | 294M/360M [00:06<00:01, 44.7MB/s]
84%|########4 | 303M/360M [00:06<00:01, 47.1MB/s]
86%|########5 | 308M/360M [00:06<00:01, 44.7MB/s]
89%|########8 | 319M/360M [00:07<00:00, 49.0MB/s]
90%|########9 | 324M/360M [00:07<00:00, 48.0MB/s]
93%|#########2| 335M/360M [00:07<00:00, 60.7MB/s]
95%|#########4| 341M/360M [00:07<00:00, 41.5MB/s]
97%|#########7| 351M/360M [00:08<00:00, 34.0MB/s]
99%|#########8| 355M/360M [00:08<00:00, 31.6MB/s]
100%|##########| 360M/360M [00:08<00:00, 45.7MB/s]
我們將從 LibriSpeech test-other 資料集中載入一個範例。
speech_file = download_asset("tutorial-assets/ctc-decoding/1688-142285-0007.wav")
IPython.display.Audio(speech_file)
此音訊檔案對應的文字稿為:
waveform, sample_rate = torchaudio.load(speech_file)
if sample_rate != bundle.sample_rate:
waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate)
解碼器的檔案與資料¶
接下來,我們載入 token、詞彙和語言模型資料,解碼器使用這些資料來預測聲學模型輸出的單字。 LibriSpeech 資料集的預訓練檔案可以透過 torchaudio 下載,或者使用者可以提供自己的檔案。
Tokens¶
Token 是聲學模型可以預測的可能符號,包括空白符號和靜音符號。它可以作為檔案傳入,其中每行由對應於相同索引的 token 組成,或者作為 token 列表傳入,每個 token 對應於唯一的索引。
# tokens.txt
_
|
e
t
...
['-', '|', 'e', 't', 'a', 'o', 'n', 'i', 'h', 's', 'r', 'd', 'l', 'u', 'm', 'w', 'c', 'f', 'g', 'y', 'p', 'b', 'v', 'k', "'", 'x', 'j', 'q', 'z']
詞彙 (Lexicon)¶
詞彙是單字到其對應 token 序列的映射,用於將解碼器的搜尋空間限制為僅來自詞彙的單字。 詞彙檔案的預期格式是每行一個單字,單字後跟其以空格分隔的 token。
# lexcion.txt
a a |
able a b l e |
about a b o u t |
...
...
語言模型 (Language Model)¶
解碼時可以使用語言模型來改進結果,方法是將代表序列可能性的語言模型分數納入 beam search 計算中。 下面,我們概述了支援解碼的不同形式的語言模型。
沒有語言模型 (No Language Model)¶
若要建立沒有語言模型的解碼器實例,請在初始化解碼器時設定 lm=None。
KenLM¶
這是一個使用 KenLM 函式庫 訓練的 n-gram 語言模型。 可以使用 .arpa 或二進位化的 .bin LM,但建議使用二進位格式以加快載入速度。
本教學中使用的語言模型是使用 LibriSpeech 訓練的 4-gram KenLM。
自訂語言模型 (Custom Language Model)¶
使用者可以使用 CTCDecoderLM 和 CTCDecoderLMState,在 Python 中定義自己的自訂語言模型,無論是統計或神經網路語言模型。
例如,以下程式碼建立了一個 PyTorch torch.nn.Module 語言模型的基本封裝。
from torchaudio.models.decoder import CTCDecoderLM, CTCDecoderLMState
class CustomLM(CTCDecoderLM):
"""Create a Python wrapper around `language_model` to feed to the decoder."""
def __init__(self, language_model: torch.nn.Module):
CTCDecoderLM.__init__(self)
self.language_model = language_model
self.sil = -1 # index for silent token in the language model
self.states = {}
language_model.eval()
def start(self, start_with_nothing: bool = False):
state = CTCDecoderLMState()
with torch.no_grad():
score = self.language_model(self.sil)
self.states[state] = score
return state
def score(self, state: CTCDecoderLMState, token_index: int):
outstate = state.child(token_index)
if outstate not in self.states:
score = self.language_model(token_index)
self.states[outstate] = score
score = self.states[outstate]
return outstate, score
def finish(self, state: CTCDecoderLMState):
return self.score(state, self.sil)
下載預訓練檔案 (Downloading Pretrained Files)¶
可以使用 download_pretrained_files() 下載 LibriSpeech 資料集的預訓練檔案。
注意:此儲存格可能需要幾分鐘才能運行,因為語言模型可能很大
from torchaudio.models.decoder import download_pretrained_files
files = download_pretrained_files("librispeech-4-gram")
print(files)
0%| | 0.00/4.97M [00:00<?, ?B/s]
85%|########5 | 4.25M/4.97M [00:00<00:00, 19.0MB/s]
100%|##########| 4.97M/4.97M [00:00<00:00, 21.7MB/s]
0%| | 0.00/57.0 [00:00<?, ?B/s]
100%|##########| 57.0/57.0 [00:00<00:00, 119kB/s]
0%| | 0.00/2.91G [00:00<?, ?B/s]
0%| | 14.9M/2.91G [00:00<01:16, 40.6MB/s]
1%| | 18.8M/2.91G [00:00<01:30, 34.4MB/s]
1%| | 24.5M/2.91G [00:00<01:27, 35.4MB/s]
1%|1 | 30.9M/2.91G [00:00<01:13, 41.9MB/s]
1%|1 | 35.2M/2.91G [00:01<01:30, 34.0MB/s]
2%|1 | 48.0M/2.91G [00:01<01:09, 44.0MB/s]
2%|2 | 62.9M/2.91G [00:01<01:15, 40.6MB/s]
2%|2 | 67.0M/2.91G [00:01<01:25, 35.6MB/s]
3%|2 | 80.0M/2.91G [00:02<01:12, 42.0MB/s]
3%|3 | 94.9M/2.91G [00:02<01:14, 40.7MB/s]
3%|3 | 98.9M/2.91G [00:02<01:15, 40.1MB/s]
4%|3 | 112M/2.91G [00:02<00:58, 51.2MB/s]
4%|4 | 128M/2.91G [00:02<00:48, 62.0MB/s]
5%|4 | 144M/2.91G [00:03<00:42, 70.0MB/s]
5%|5 | 151M/2.91G [00:03<00:49, 60.5MB/s]
5%|5 | 159M/2.91G [00:03<00:52, 56.5MB/s]
6%|5 | 166M/2.91G [00:03<00:48, 60.4MB/s]
6%|5 | 176M/2.91G [00:03<00:43, 67.7MB/s]
6%|6 | 191M/2.91G [00:03<00:33, 86.5MB/s]
7%|6 | 200M/2.91G [00:03<00:35, 81.4MB/s]
7%|6 | 208M/2.91G [00:04<00:48, 59.5MB/s]
8%|7 | 224M/2.91G [00:04<00:36, 78.4MB/s]
8%|7 | 233M/2.91G [00:04<00:38, 75.7MB/s]
8%|8 | 241M/2.91G [00:04<00:50, 56.7MB/s]
9%|8 | 256M/2.91G [00:04<00:45, 63.2MB/s]
9%|9 | 272M/2.91G [00:05<00:37, 75.0MB/s]
9%|9 | 281M/2.91G [00:05<00:37, 75.7MB/s]
10%|9 | 289M/2.91G [00:05<00:40, 69.6MB/s]
10%|# | 299M/2.91G [00:05<00:44, 63.6MB/s]
10%|# | 306M/2.91G [00:05<00:45, 61.4MB/s]
11%|# | 319M/2.91G [00:05<00:40, 69.7MB/s]
11%|# | 326M/2.91G [00:06<00:46, 59.8MB/s]
11%|#1 | 336M/2.91G [00:06<00:50, 54.7MB/s]
11%|#1 | 342M/2.91G [00:06<00:51, 53.4MB/s]
12%|#1 | 352M/2.91G [00:06<00:51, 53.2MB/s]
12%|#1 | 357M/2.91G [00:06<00:54, 50.4MB/s]
12%|#2 | 367M/2.91G [00:06<00:50, 54.0MB/s]
12%|#2 | 372M/2.91G [00:07<00:58, 46.4MB/s]
13%|#2 | 383M/2.91G [00:07<00:55, 49.2MB/s]
13%|#3 | 388M/2.91G [00:07<01:01, 44.0MB/s]
13%|#3 | 400M/2.91G [00:07<00:51, 52.2MB/s]
14%|#3 | 416M/2.91G [00:07<00:40, 66.9MB/s]
14%|#4 | 432M/2.91G [00:08<00:40, 65.5MB/s]
15%|#4 | 438M/2.91G [00:08<00:43, 61.3MB/s]
15%|#5 | 448M/2.91G [00:08<00:41, 64.7MB/s]
16%|#5 | 464M/2.91G [00:08<00:33, 79.0MB/s]
16%|#5 | 472M/2.91G [00:08<00:38, 68.3MB/s]
16%|#6 | 480M/2.91G [00:08<00:40, 64.3MB/s]
17%|#6 | 496M/2.91G [00:09<00:37, 69.1MB/s]
17%|#6 | 502M/2.91G [00:09<00:47, 55.2MB/s]
17%|#7 | 511M/2.91G [00:09<00:47, 54.1MB/s]
17%|#7 | 516M/2.91G [00:09<01:01, 41.7MB/s]
18%|#7 | 527M/2.91G [00:09<00:56, 45.3MB/s]
18%|#7 | 532M/2.91G [00:10<00:58, 43.7MB/s]
18%|#8 | 544M/2.91G [00:10<00:54, 47.0MB/s]
18%|#8 | 551M/2.91G [00:10<00:50, 50.4MB/s]
19%|#8 | 559M/2.91G [00:10<00:50, 50.6MB/s]
19%|#8 | 564M/2.91G [00:10<00:54, 46.9MB/s]
19%|#9 | 575M/2.91G [00:10<00:41, 60.9MB/s]
20%|#9 | 582M/2.91G [00:10<00:45, 55.9MB/s]
20%|#9 | 591M/2.91G [00:11<00:49, 50.2MB/s]
20%|## | 596M/2.91G [00:11<00:49, 50.1MB/s]
20%|## | 608M/2.91G [00:11<00:42, 58.5MB/s]
21%|## | 623M/2.91G [00:11<00:36, 67.7MB/s]
21%|##1 | 629M/2.91G [00:11<00:41, 59.1MB/s]
21%|##1 | 639M/2.91G [00:12<00:48, 50.8MB/s]
22%|##1 | 644M/2.91G [00:12<00:54, 44.9MB/s]
22%|##2 | 656M/2.91G [00:12<00:47, 51.4MB/s]
22%|##2 | 661M/2.91G [00:12<00:54, 44.5MB/s]
23%|##2 | 672M/2.91G [00:12<00:49, 49.0MB/s]
23%|##2 | 676M/2.91G [00:13<00:59, 40.6MB/s]
23%|##3 | 688M/2.91G [00:13<00:50, 47.3MB/s]
23%|##3 | 692M/2.91G [00:13<01:00, 39.6MB/s]
24%|##3 | 704M/2.91G [00:13<00:47, 49.9MB/s]
24%|##4 | 720M/2.91G [00:13<00:36, 64.7MB/s]
25%|##4 | 734M/2.91G [00:13<00:31, 74.9MB/s]
25%|##4 | 741M/2.91G [00:14<00:42, 54.7MB/s]
25%|##5 | 752M/2.91G [00:14<00:40, 57.8MB/s]
26%|##5 | 768M/2.91G [00:14<00:31, 74.7MB/s]
26%|##6 | 784M/2.91G [00:14<00:30, 75.5MB/s]
27%|##6 | 792M/2.91G [00:14<00:33, 67.7MB/s]
27%|##6 | 800M/2.91G [00:15<00:36, 62.0MB/s]
27%|##7 | 815M/2.91G [00:15<00:33, 67.7MB/s]
28%|##7 | 822M/2.91G [00:15<00:40, 56.0MB/s]
28%|##7 | 831M/2.91G [00:15<00:36, 61.8MB/s]
28%|##8 | 837M/2.91G [00:15<00:40, 55.1MB/s]
28%|##8 | 848M/2.91G [00:15<00:35, 63.6MB/s]
29%|##8 | 864M/2.91G [00:16<00:31, 70.2MB/s]
29%|##9 | 873M/2.91G [00:16<00:29, 74.2MB/s]
30%|##9 | 880M/2.91G [00:16<00:44, 49.8MB/s]
30%|### | 896M/2.91G [00:16<00:37, 58.2MB/s]
31%|### | 912M/2.91G [00:17<00:45, 48.1MB/s]
31%|### | 917M/2.91G [00:17<00:50, 43.1MB/s]
31%|###1 | 928M/2.91G [00:17<00:43, 50.0MB/s]
31%|###1 | 933M/2.91G [00:17<00:47, 45.6MB/s]
32%|###1 | 944M/2.91G [00:17<00:40, 52.8MB/s]
32%|###2 | 960M/2.91G [00:17<00:31, 66.9MB/s]
32%|###2 | 967M/2.91G [00:18<00:39, 53.1MB/s]
33%|###2 | 975M/2.91G [00:18<00:38, 55.3MB/s]
33%|###2 | 981M/2.91G [00:18<00:40, 52.1MB/s]
33%|###3 | 992M/2.91G [00:18<00:36, 57.1MB/s]
34%|###3 | 0.98G/2.91G [00:18<00:26, 78.4MB/s]
34%|###4 | 0.99G/2.91G [00:19<00:33, 61.4MB/s]
34%|###4 | 1.00G/2.91G [00:19<00:33, 61.8MB/s]
35%|###4 | 1.02G/2.91G [00:19<00:26, 77.3MB/s]
35%|###5 | 1.03G/2.91G [00:19<00:21, 93.5MB/s]
36%|###5 | 1.04G/2.91G [00:19<00:31, 62.9MB/s]
36%|###6 | 1.05G/2.91G [00:19<00:37, 52.8MB/s]
36%|###6 | 1.06G/2.91G [00:20<00:29, 67.7MB/s]
37%|###6 | 1.07G/2.91G [00:20<00:46, 42.1MB/s]
37%|###7 | 1.08G/2.91G [00:20<00:46, 42.6MB/s]
38%|###7 | 1.09G/2.91G [00:21<00:41, 47.3MB/s]
38%|###7 | 1.10G/2.91G [00:21<00:48, 40.1MB/s]
38%|###7 | 1.10G/2.91G [00:21<00:48, 39.9MB/s]
38%|###8 | 1.11G/2.91G [00:21<00:45, 42.4MB/s]
38%|###8 | 1.12G/2.91G [00:21<00:35, 53.6MB/s]
39%|###8 | 1.13G/2.91G [00:21<00:41, 45.8MB/s]
39%|###9 | 1.14G/2.91G [00:22<00:31, 59.8MB/s]
39%|###9 | 1.15G/2.91G [00:22<00:33, 56.2MB/s]
40%|###9 | 1.16G/2.91G [00:22<00:35, 53.0MB/s]
40%|#### | 1.17G/2.91G [00:22<00:28, 65.0MB/s]
41%|#### | 1.19G/2.91G [00:22<00:23, 79.5MB/s]
41%|####1 | 1.20G/2.91G [00:22<00:24, 75.7MB/s]
42%|####1 | 1.22G/2.91G [00:23<00:23, 77.9MB/s]
42%|####2 | 1.23G/2.91G [00:23<00:22, 81.1MB/s]
43%|####2 | 1.25G/2.91G [00:23<00:20, 86.3MB/s]
43%|####3 | 1.27G/2.91G [00:23<00:18, 96.4MB/s]
44%|####3 | 1.27G/2.91G [00:23<00:20, 83.9MB/s]
44%|####4 | 1.28G/2.91G [00:23<00:23, 74.3MB/s]
45%|####4 | 1.30G/2.91G [00:24<00:20, 82.9MB/s]
45%|####4 | 1.30G/2.91G [00:24<00:22, 76.6MB/s]
45%|####5 | 1.31G/2.91G [00:24<00:28, 60.2MB/s]
45%|####5 | 1.32G/2.91G [00:24<00:33, 51.6MB/s]
46%|####5 | 1.33G/2.91G [00:24<00:38, 44.1MB/s]
46%|####5 | 1.33G/2.91G [00:25<00:37, 44.8MB/s]
46%|####6 | 1.34G/2.91G [00:25<00:33, 51.0MB/s]
46%|####6 | 1.35G/2.91G [00:25<00:39, 42.7MB/s]
47%|####6 | 1.36G/2.91G [00:25<00:31, 53.2MB/s]
47%|####6 | 1.36G/2.91G [00:25<00:38, 43.3MB/s]
47%|####7 | 1.38G/2.91G [00:25<00:32, 50.0MB/s]
48%|####7 | 1.39G/2.91G [00:26<00:28, 56.6MB/s]
48%|####8 | 1.41G/2.91G [00:26<00:23, 68.2MB/s]
49%|####8 | 1.41G/2.91G [00:26<00:24, 64.7MB/s]
49%|####8 | 1.42G/2.91G [00:26<00:23, 68.5MB/s]
49%|####9 | 1.44G/2.91G [00:26<00:20, 76.3MB/s]
50%|####9 | 1.45G/2.91G [00:27<00:20, 77.0MB/s]
50%|##### | 1.46G/2.91G [00:27<00:25, 61.3MB/s]
50%|##### | 1.47G/2.91G [00:27<00:25, 60.8MB/s]
51%|#####1 | 1.48G/2.91G [00:27<00:20, 75.7MB/s]
51%|#####1 | 1.49G/2.91G [00:27<00:27, 55.8MB/s]
52%|#####1 | 1.50G/2.91G [00:28<00:29, 50.8MB/s]
52%|#####2 | 1.51G/2.91G [00:28<00:30, 48.5MB/s]
52%|#####2 | 1.52G/2.91G [00:28<00:28, 51.9MB/s]
53%|#####2 | 1.53G/2.91G [00:28<00:24, 60.2MB/s]
53%|#####3 | 1.55G/2.91G [00:28<00:26, 55.1MB/s]
53%|#####3 | 1.55G/2.91G [00:29<00:31, 46.0MB/s]
54%|#####3 | 1.56G/2.91G [00:29<00:33, 42.9MB/s]
54%|#####3 | 1.57G/2.91G [00:29<00:34, 41.4MB/s]
54%|#####4 | 1.58G/2.91G [00:29<00:31, 45.6MB/s]
55%|#####4 | 1.59G/2.91G [00:30<00:24, 58.2MB/s]
55%|#####5 | 1.61G/2.91G [00:30<00:19, 71.8MB/s]
56%|#####5 | 1.62G/2.91G [00:30<00:21, 65.8MB/s]
56%|#####5 | 1.62G/2.91G [00:30<00:21, 65.4MB/s]
56%|#####6 | 1.64G/2.91G [00:30<00:22, 60.5MB/s]
57%|#####6 | 1.65G/2.91G [00:31<00:39, 34.3MB/s]
57%|#####6 | 1.65G/2.91G [00:31<00:39, 34.6MB/s]
57%|#####6 | 1.66G/2.91G [00:31<00:44, 30.5MB/s]
57%|#####7 | 1.67G/2.91G [00:31<00:31, 42.8MB/s]
58%|#####7 | 1.68G/2.91G [00:32<00:36, 36.7MB/s]
58%|#####7 | 1.69G/2.91G [00:32<00:28, 46.0MB/s]
58%|#####8 | 1.69G/2.91G [00:32<00:27, 47.0MB/s]
58%|#####8 | 1.70G/2.91G [00:32<00:25, 50.9MB/s]
59%|#####8 | 1.70G/2.91G [00:32<00:25, 50.6MB/s]
59%|#####9 | 1.72G/2.91G [00:32<00:17, 75.1MB/s]
59%|#####9 | 1.73G/2.91G [00:32<00:18, 69.5MB/s]
60%|#####9 | 1.73G/2.91G [00:33<00:24, 51.7MB/s]
60%|#####9 | 1.74G/2.91G [00:33<00:26, 48.0MB/s]
60%|#####9 | 1.75G/2.91G [00:33<00:40, 30.8MB/s]
60%|###### | 1.75G/2.91G [00:33<00:43, 28.7MB/s]
61%|###### | 1.76G/2.91G [00:34<00:27, 44.6MB/s]
61%|###### | 1.77G/2.91G [00:34<00:31, 38.5MB/s]
61%|######1 | 1.78G/2.91G [00:34<00:21, 56.6MB/s]
62%|######1 | 1.80G/2.91G [00:34<00:17, 69.0MB/s]
62%|######2 | 1.80G/2.91G [00:34<00:17, 68.2MB/s]
62%|######2 | 1.81G/2.91G [00:34<00:16, 70.2MB/s]
63%|######2 | 1.82G/2.91G [00:34<00:17, 65.3MB/s]
63%|######2 | 1.83G/2.91G [00:35<00:20, 56.0MB/s]
63%|######2 | 1.83G/2.91G [00:35<00:23, 49.1MB/s]
63%|######3 | 1.84G/2.91G [00:35<00:20, 56.1MB/s]
64%|######3 | 1.86G/2.91G [00:35<00:15, 71.1MB/s]
64%|######4 | 1.87G/2.91G [00:35<00:20, 55.1MB/s]
64%|######4 | 1.87G/2.91G [00:36<00:23, 47.8MB/s]
65%|######4 | 1.88G/2.91G [00:36<00:29, 37.1MB/s]
65%|######4 | 1.89G/2.91G [00:36<00:22, 47.8MB/s]
65%|######5 | 1.90G/2.91G [00:36<00:24, 45.3MB/s]
65%|######5 | 1.91G/2.91G [00:36<00:25, 43.1MB/s]
66%|######5 | 1.91G/2.91G [00:37<00:28, 38.3MB/s]
66%|######6 | 1.92G/2.91G [00:37<00:23, 45.6MB/s]
67%|######6 | 1.94G/2.91G [00:37<00:17, 60.9MB/s]
67%|######6 | 1.94G/2.91G [00:37<00:18, 55.5MB/s]
67%|######7 | 1.95G/2.91G [00:37<00:21, 48.4MB/s]
68%|######7 | 1.97G/2.91G [00:38<00:18, 55.8MB/s]
68%|######7 | 1.97G/2.91G [00:38<00:19, 52.7MB/s]
68%|######8 | 1.98G/2.91G [00:38<00:18, 55.3MB/s]
68%|######8 | 1.99G/2.91G [00:38<00:16, 60.1MB/s]
69%|######8 | 2.00G/2.91G [00:38<00:15, 62.1MB/s]
69%|######8 | 2.00G/2.91G [00:38<00:23, 42.2MB/s]
69%|######9 | 2.01G/2.91G [00:39<00:22, 42.8MB/s]
69%|######9 | 2.02G/2.91G [00:39<00:22, 43.3MB/s]
70%|######9 | 2.03G/2.91G [00:39<00:16, 58.1MB/s]
70%|####### | 2.04G/2.91G [00:39<00:17, 54.2MB/s]
70%|####### | 2.05G/2.91G [00:39<00:17, 51.9MB/s]
70%|####### | 2.05G/2.91G [00:40<00:23, 38.7MB/s]
71%|####### | 2.06G/2.91G [00:40<00:18, 48.7MB/s]
71%|#######1 | 2.08G/2.91G [00:40<00:13, 64.8MB/s]
72%|#######1 | 2.08G/2.91G [00:40<00:15, 57.9MB/s]
72%|#######1 | 2.09G/2.91G [00:40<00:13, 63.3MB/s]
72%|#######2 | 2.10G/2.91G [00:40<00:14, 59.4MB/s]
72%|#######2 | 2.11G/2.91G [00:40<00:12, 67.6MB/s]
73%|#######2 | 2.12G/2.91G [00:41<00:13, 64.5MB/s]
73%|#######3 | 2.12G/2.91G [00:41<00:17, 48.1MB/s]
74%|#######3 | 2.14G/2.91G [00:41<00:14, 56.6MB/s]
74%|#######3 | 2.15G/2.91G [00:41<00:16, 49.7MB/s]
74%|#######4 | 2.16G/2.91G [00:41<00:16, 48.8MB/s]
74%|#######4 | 2.16G/2.91G [00:42<00:16, 49.1MB/s]
74%|#######4 | 2.17G/2.91G [00:42<00:16, 48.1MB/s]
75%|#######4 | 2.17G/2.91G [00:42<00:15, 49.7MB/s]
75%|#######4 | 2.18G/2.91G [00:42<00:15, 51.2MB/s]
75%|#######5 | 2.18G/2.91G [00:42<00:17, 45.7MB/s]
75%|#######5 | 2.19G/2.91G [00:42<00:17, 43.2MB/s]
75%|#######5 | 2.19G/2.91G [00:43<00:25, 30.7MB/s]
76%|#######5 | 2.20G/2.91G [00:43<00:20, 36.8MB/s]
76%|#######5 | 2.21G/2.91G [00:43<00:15, 49.0MB/s]
76%|#######6 | 2.22G/2.91G [00:43<00:12, 59.0MB/s]
77%|#######6 | 2.23G/2.91G [00:43<00:11, 64.9MB/s]
77%|#######6 | 2.24G/2.91G [00:43<00:13, 55.1MB/s]
77%|#######7 | 2.25G/2.91G [00:44<00:14, 50.3MB/s]
77%|#######7 | 2.25G/2.91G [00:44<00:14, 47.5MB/s]
78%|#######7 | 2.26G/2.91G [00:44<00:12, 54.0MB/s]
78%|#######7 | 2.27G/2.91G [00:44<00:15, 45.0MB/s]
78%|#######8 | 2.28G/2.91G [00:44<00:14, 47.1MB/s]
79%|#######8 | 2.30G/2.91G [00:44<00:11, 57.3MB/s]
79%|#######9 | 2.30G/2.91G [00:45<00:11, 55.4MB/s]
79%|#######9 | 2.31G/2.91G [00:45<00:09, 67.2MB/s]
80%|#######9 | 2.32G/2.91G [00:45<00:10, 58.1MB/s]
80%|#######9 | 2.33G/2.91G [00:45<00:11, 52.3MB/s]
80%|######## | 2.33G/2.91G [00:45<00:13, 46.2MB/s]
81%|######## | 2.34G/2.91G [00:45<00:12, 48.2MB/s]
81%|######## | 2.35G/2.91G [00:46<00:15, 37.8MB/s]
81%|######## | 2.35G/2.91G [00:46<00:15, 38.4MB/s]
81%|########1 | 2.36G/2.91G [00:46<00:15, 37.1MB/s]
82%|########1 | 2.38G/2.91G [00:46<00:10, 53.5MB/s]
82%|########2 | 2.39G/2.91G [00:46<00:08, 63.6MB/s]
82%|########2 | 2.40G/2.91G [00:47<00:08, 64.3MB/s]
83%|########2 | 2.41G/2.91G [00:47<00:07, 68.9MB/s]
83%|########2 | 2.41G/2.91G [00:47<00:07, 69.4MB/s]
83%|########3 | 2.42G/2.91G [00:47<00:08, 59.7MB/s]
84%|########3 | 2.44G/2.91G [00:47<00:07, 64.6MB/s]
84%|########3 | 2.44G/2.91G [00:47<00:08, 61.6MB/s]
84%|########4 | 2.45G/2.91G [00:48<00:08, 59.4MB/s]
85%|########4 | 2.47G/2.91G [00:48<00:07, 67.5MB/s]
85%|########5 | 2.47G/2.91G [00:48<00:11, 41.7MB/s]
85%|########5 | 2.48G/2.91G [00:48<00:11, 40.9MB/s]
86%|########5 | 2.50G/2.91G [00:49<00:07, 56.8MB/s]
86%|########6 | 2.51G/2.91G [00:49<00:08, 52.7MB/s]
86%|########6 | 2.52G/2.91G [00:49<00:07, 54.6MB/s]
87%|########6 | 2.53G/2.91G [00:49<00:06, 65.9MB/s]
87%|########7 | 2.55G/2.91G [00:49<00:05, 69.2MB/s]
88%|########7 | 2.55G/2.91G [00:49<00:06, 63.1MB/s]
88%|########8 | 2.56G/2.91G [00:50<00:06, 60.5MB/s]
89%|########8 | 2.58G/2.91G [00:50<00:05, 66.9MB/s]
89%|########8 | 2.58G/2.91G [00:50<00:05, 60.9MB/s]
89%|########9 | 2.59G/2.91G [00:50<00:05, 68.1MB/s]
89%|########9 | 2.60G/2.91G [00:50<00:05, 55.9MB/s]
90%|########9 | 2.61G/2.91G [00:50<00:06, 53.7MB/s]
90%|########9 | 2.61G/2.91G [00:51<00:07, 43.6MB/s]
90%|######### | 2.62G/2.91G [00:51<00:05, 54.1MB/s]
90%|######### | 2.63G/2.91G [00:51<00:05, 50.8MB/s]
91%|######### | 2.64G/2.91G [00:51<00:05, 50.7MB/s]
91%|#########1| 2.66G/2.91G [00:51<00:04, 56.5MB/s]
91%|#########1| 2.66G/2.91G [00:52<00:06, 44.0MB/s]
92%|#########1| 2.67G/2.91G [00:52<00:07, 35.0MB/s]
92%|#########1| 2.67G/2.91G [00:52<00:07, 36.2MB/s]
92%|#########2| 2.69G/2.91G [00:52<00:04, 50.6MB/s]
93%|#########2| 2.69G/2.91G [00:53<00:05, 42.8MB/s]
93%|#########2| 2.70G/2.91G [00:53<00:05, 44.7MB/s]
93%|#########3| 2.71G/2.91G [00:53<00:04, 44.4MB/s]
93%|#########3| 2.72G/2.91G [00:53<00:03, 52.2MB/s]
94%|#########3| 2.72G/2.91G [00:53<00:05, 40.0MB/s]
94%|#########3| 2.73G/2.91G [00:53<00:04, 43.3MB/s]
94%|#########3| 2.73G/2.91G [00:54<00:04, 41.5MB/s]
94%|#########4| 2.74G/2.91G [00:54<00:05, 35.1MB/s]
94%|#########4| 2.75G/2.91G [00:54<00:04, 42.8MB/s]
95%|#########4| 2.75G/2.91G [00:54<00:04, 36.1MB/s]
95%|#########5| 2.77G/2.91G [00:54<00:03, 45.5MB/s]
95%|#########5| 2.77G/2.91G [00:54<00:03, 43.9MB/s]
96%|#########5| 2.78G/2.91G [00:55<00:02, 51.5MB/s]
96%|#########6| 2.80G/2.91G [00:55<00:01, 62.6MB/s]
96%|#########6| 2.80G/2.91G [00:55<00:02, 54.6MB/s]
96%|#########6| 2.81G/2.91G [00:55<00:02, 54.6MB/s]
97%|#########6| 2.81G/2.91G [00:55<00:02, 44.1MB/s]
97%|#########6| 2.82G/2.91G [00:56<00:02, 37.1MB/s]
97%|#########7| 2.83G/2.91G [00:56<00:01, 52.0MB/s]
97%|#########7| 2.83G/2.91G [00:56<00:02, 29.4MB/s]
98%|#########7| 2.84G/2.91G [00:56<00:02, 32.1MB/s]
98%|#########7| 2.84G/2.91G [00:56<00:02, 31.3MB/s]
98%|#########7| 2.85G/2.91G [00:57<00:02, 24.9MB/s]
98%|#########8| 2.86G/2.91G [00:57<00:02, 25.1MB/s]
98%|#########8| 2.86G/2.91G [00:57<00:02, 21.4MB/s]
99%|#########8| 2.88G/2.91G [00:58<00:01, 32.0MB/s]
99%|#########9| 2.89G/2.91G [00:58<00:00, 48.8MB/s]
100%|#########9| 2.90G/2.91G [00:58<00:00, 48.1MB/s]
100%|#########9| 2.91G/2.91G [00:58<00:00, 51.0MB/s]
100%|##########| 2.91G/2.91G [00:58<00:00, 53.2MB/s]
PretrainedFiles(lexicon='/root/.cache/torch/hub/torchaudio/decoder-assets/librispeech-4-gram/lexicon.txt', tokens='/root/.cache/torch/hub/torchaudio/decoder-assets/librispeech-4-gram/tokens.txt', lm='/root/.cache/torch/hub/torchaudio/decoder-assets/librispeech-4-gram/lm.bin')
建構解碼器 (Construct Decoders)¶
在本教學中,我們同時建構一個 beam search 解碼器和一個 greedy 解碼器以進行比較。
Beam Search 解碼器¶
可以使用工廠函式 ctc_decoder() 建構解碼器。 除了前面提到的元件外,它還接收各種 beam search 解碼參數和 token/單字參數。
也可以在沒有語言模型的情況下運行此解碼器,方法是將 None 傳遞到 lm 參數中。
LM_WEIGHT = 3.23
WORD_SCORE = -0.26
beam_search_decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
nbest=3,
beam_size=1500,
lm_weight=LM_WEIGHT,
word_score=WORD_SCORE,
)
Greedy 解碼器¶
class GreedyCTCDecoder(torch.nn.Module):
def __init__(self, labels, blank=0):
super().__init__()
self.labels = labels
self.blank = blank
def forward(self, emission: torch.Tensor) -> List[str]:
"""Given a sequence emission over labels, get the best path
Args:
emission (Tensor): Logit tensors. Shape `[num_seq, num_label]`.
Returns:
List[str]: The resulting transcript
"""
indices = torch.argmax(emission, dim=-1) # [num_seq,]
indices = torch.unique_consecutive(indices, dim=-1)
indices = [i for i in indices if i != self.blank]
joined = "".join([self.labels[i] for i in indices])
return joined.replace("|", " ").strip().split()
greedy_decoder = GreedyCTCDecoder(tokens)
運行推論 (Run Inference)¶
現在我們有了資料、聲學模型和解碼器,我們可以執行推論。 beam search 解碼器的輸出類型為 CTCHypothesis,由預測的 token ID、對應的單字(如果提供了詞彙)、假設分數以及對應於 token ID 的時間步長組成。 回想一下,對應於波形的文字稿為
actual_transcript = "i really was very much afraid of showing him how much shocked i was at some parts of what he said"
actual_transcript = actual_transcript.split()
emission, _ = acoustic_model(waveform)
greedy 解碼器給出以下結果。
greedy_result = greedy_decoder(emission[0])
greedy_transcript = " ".join(greedy_result)
greedy_wer = torchaudio.functional.edit_distance(actual_transcript, greedy_result) / len(actual_transcript)
print(f"Transcript: {greedy_transcript}")
print(f"WER: {greedy_wer}")
Transcript: i reily was very much affrayd of showing him howmuch shoktd i wause at some parte of what he seid
WER: 0.38095238095238093
使用 beam search 解碼器
beam_search_result = beam_search_decoder(emission)
beam_search_transcript = " ".join(beam_search_result[0][0].words).strip()
beam_search_wer = torchaudio.functional.edit_distance(actual_transcript, beam_search_result[0][0].words) / len(
actual_transcript
)
print(f"Transcript: {beam_search_transcript}")
print(f"WER: {beam_search_wer}")
Transcript: i really was very much afraid of showing him how much shocked i was at some part of what he said
WER: 0.047619047619047616
注意
如果沒有為解碼器提供詞彙,則輸出假設的 words 欄位將為空。 若要檢索沒有詞彙的解碼文字稿,您可以執行以下操作來檢索 token 索引,將它們轉換為原始 token,然後將它們連接在一起。
tokens_str = "".join(beam_search_decoder.idxs_to_tokens(beam_search_result[0][0].tokens))
transcript = " ".join(tokens_str.split("|"))
我們看到使用詞彙約束的 beam search 解碼器產生的更準確的結果由真實單字組成,而 greedy 解碼器可能會預測錯誤拼寫的單字,如“affrayd”和“shoktd”。
增量解碼¶
如果輸入語音很長,可以增量方式解碼。
您需要首先使用 decode_begin() 初始化解碼器的內部狀態。
beam_search_decoder.decode_begin()
然後,您可以將 emission 傳遞給 decode_begin()。 在這裡,我們使用相同的 emission,但一次將其一次一幀地傳遞給解碼器。
最後,完成解碼器的內部狀態,並檢索結果。
beam_search_decoder.decode_end()
beam_search_result_inc = beam_search_decoder.get_final_hypothesis()
增量解碼的結果與批次解碼相同。
beam_search_transcript_inc = " ".join(beam_search_result_inc[0].words).strip()
beam_search_wer_inc = torchaudio.functional.edit_distance(
actual_transcript, beam_search_result_inc[0].words) / len(actual_transcript)
print(f"Transcript: {beam_search_transcript_inc}")
print(f"WER: {beam_search_wer_inc}")
assert beam_search_result[0][0].words == beam_search_result_inc[0].words
assert beam_search_result[0][0].score == beam_search_result_inc[0].score
torch.testing.assert_close(beam_search_result[0][0].timesteps, beam_search_result_inc[0].timesteps)
Transcript: i really was very much afraid of showing him how much shocked i was at some part of what he said
WER: 0.047619047619047616
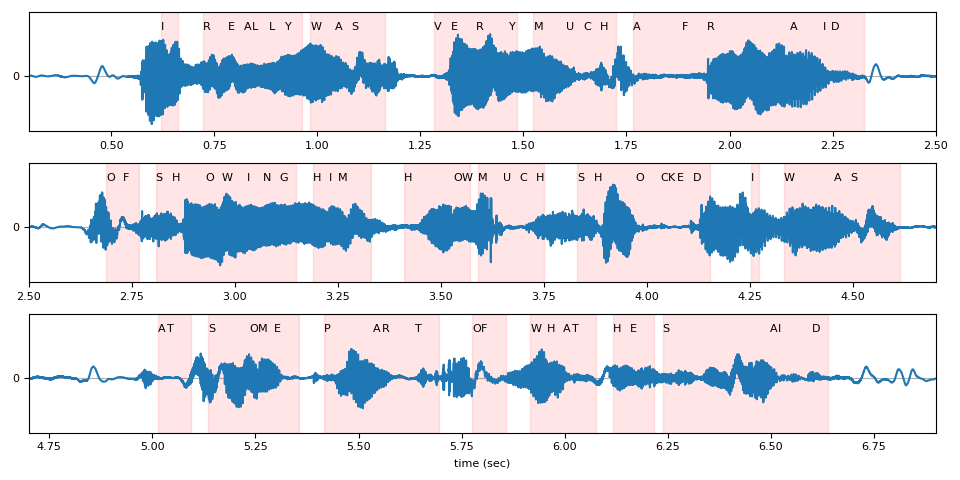
時間步長對齊 (Timestep Alignments)¶
回想一下,結果假設的元件之一是與 token ID 對應的時間步長。
timesteps = beam_search_result[0][0].timesteps
predicted_tokens = beam_search_decoder.idxs_to_tokens(beam_search_result[0][0].tokens)
print(predicted_tokens, len(predicted_tokens))
print(timesteps, timesteps.shape[0])
['|', 'i', '|', 'r', 'e', 'a', 'l', 'l', 'y', '|', 'w', 'a', 's', '|', 'v', 'e', 'r', 'y', '|', 'm', 'u', 'c', 'h', '|', 'a', 'f', 'r', 'a', 'i', 'd', '|', 'o', 'f', '|', 's', 'h', 'o', 'w', 'i', 'n', 'g', '|', 'h', 'i', 'm', '|', 'h', 'o', 'w', '|', 'm', 'u', 'c', 'h', '|', 's', 'h', 'o', 'c', 'k', 'e', 'd', '|', 'i', '|', 'w', 'a', 's', '|', 'a', 't', '|', 's', 'o', 'm', 'e', '|', 'p', 'a', 'r', 't', '|', 'o', 'f', '|', 'w', 'h', 'a', 't', '|', 'h', 'e', '|', 's', 'a', 'i', 'd', '|', '|'] 99
tensor([ 0, 31, 33, 36, 39, 41, 42, 44, 46, 48, 49, 52, 54, 58,
64, 66, 69, 73, 74, 76, 80, 82, 84, 86, 88, 94, 97, 107,
111, 112, 116, 134, 136, 138, 140, 142, 146, 148, 151, 153, 155, 157,
159, 161, 162, 166, 170, 176, 177, 178, 179, 182, 184, 186, 187, 191,
193, 198, 201, 202, 203, 205, 207, 212, 213, 216, 222, 224, 230, 250,
251, 254, 256, 261, 262, 264, 267, 270, 276, 277, 281, 284, 288, 289,
292, 295, 297, 299, 300, 303, 305, 307, 310, 311, 324, 325, 329, 331,
353], dtype=torch.int32) 99
下面,我們將 token 時間步長對齊可視化為相對於原始波形。
def plot_alignments(waveform, emission, tokens, timesteps, sample_rate):
t = torch.arange(waveform.size(0)) / sample_rate
ratio = waveform.size(0) / emission.size(1) / sample_rate
chars = []
words = []
word_start = None
for token, timestep in zip(tokens, timesteps * ratio):
if token == "|":
if word_start is not None:
words.append((word_start, timestep))
word_start = None
else:
chars.append((token, timestep))
if word_start is None:
word_start = timestep
fig, axes = plt.subplots(3, 1)
def _plot(ax, xlim):
ax.plot(t, waveform)
for token, timestep in chars:
ax.annotate(token.upper(), (timestep, 0.5))
for word_start, word_end in words:
ax.axvspan(word_start, word_end, alpha=0.1, color="red")
ax.set_ylim(-0.6, 0.7)
ax.set_yticks([0])
ax.grid(True, axis="y")
ax.set_xlim(xlim)
_plot(axes[0], (0.3, 2.5))
_plot(axes[1], (2.5, 4.7))
_plot(axes[2], (4.7, 6.9))
axes[2].set_xlabel("time (sec)")
fig.tight_layout()
plot_alignments(waveform[0], emission, predicted_tokens, timesteps, bundle.sample_rate)
Beam Search 解碼器參數¶
在本節中,我們將更深入地探討一些不同的參數和權衡。如需完整的可自訂參數列表,請參閱文件。
輔助函式¶
def print_decoded(decoder, emission, param, param_value):
start_time = time.monotonic()
result = decoder(emission)
decode_time = time.monotonic() - start_time
transcript = " ".join(result[0][0].words).lower().strip()
score = result[0][0].score
print(f"{param} {param_value:<3}: {transcript} (score: {score:.2f}; {decode_time:.4f} secs)")
nbest¶
此參數表示要傳回的最佳假設的數量,這是 greedy decoder 無法實現的屬性。例如,透過在稍早建構 beam search decoder 時設定 nbest=3,我們現在可以存取具有前 3 個分數的假設。
for i in range(3):
transcript = " ".join(beam_search_result[0][i].words).strip()
score = beam_search_result[0][i].score
print(f"{transcript} (score: {score})")
i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.824109642502)
i really was very much afraid of showing him how much shocked i was at some parts of what he said (score: 3697.858373688456)
i reply was very much afraid of showing him how much shocked i was at some part of what he said (score: 3695.0157600045172)
beam size (波束大小)¶
beam_size 參數決定了每個解碼步驟後要保留的最佳假設的最大數量。使用較大的波束大小可以探索更大範圍的可能假設,從而產生具有更高分數的假設,但計算成本更高,並且超過某個點後不會提供額外的增益。
在下面的範例中,我們看到隨著波束大小從 1 增加到 5 再到 50,解碼品質有所提高,但請注意,使用波束大小 500 提供的輸出與波束大小 50 相同,同時增加了計算時間。
beam_sizes = [1, 5, 50, 500]
for beam_size in beam_sizes:
beam_search_decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
beam_size=beam_size,
lm_weight=LM_WEIGHT,
word_score=WORD_SCORE,
)
print_decoded(beam_search_decoder, emission, "beam size", beam_size)
beam size 1 : i you ery much afra of shongut shot i was at some arte what he sad (score: 3144.93; 0.0444 secs)
beam size 5 : i rely was very much afraid of showing him how much shot i was at some parts of what he said (score: 3688.02; 0.0496 secs)
beam size 50 : i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.1621 secs)
beam size 500: i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.5372 secs)
beam size token (波束大小 Token)¶
beam_size_token 參數對應於在解碼步驟中要考慮擴展每個假設的 Token 數量。探索更多可能的下一個 Token 會增加潛在假設的範圍,但會增加計算成本。
num_tokens = len(tokens)
beam_size_tokens = [1, 5, 10, num_tokens]
for beam_size_token in beam_size_tokens:
beam_search_decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
beam_size_token=beam_size_token,
lm_weight=LM_WEIGHT,
word_score=WORD_SCORE,
)
print_decoded(beam_search_decoder, emission, "beam size token", beam_size_token)
beam size token 1 : i rely was very much affray of showing him hoch shot i was at some part of what he sed (score: 3584.80; 0.1564 secs)
beam size token 5 : i rely was very much afraid of showing him how much shocked i was at some part of what he said (score: 3694.83; 0.1773 secs)
beam size token 10 : i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3696.25; 0.1958 secs)
beam size token 29 : i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.2272 secs)
beam threshold (波束閥值)¶
beam_threshold 參數用於在每個解碼步驟中修剪儲存的假設集,移除分數與最高分數假設相差大於 beam_threshold 的假設。在選擇較小的閾值以修剪更多假設並減少搜尋空間,以及選擇足夠大的閾值以避免修剪合理的假設之間存在平衡。
beam_thresholds = [1, 5, 10, 25]
for beam_threshold in beam_thresholds:
beam_search_decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
beam_threshold=beam_threshold,
lm_weight=LM_WEIGHT,
word_score=WORD_SCORE,
)
print_decoded(beam_search_decoder, emission, "beam threshold", beam_threshold)
beam threshold 1 : i ila ery much afraid of shongut shot i was at some parts of what he said (score: 3316.20; 0.0277 secs)
beam threshold 5 : i rely was very much afraid of showing him how much shot i was at some parts of what he said (score: 3682.23; 0.0602 secs)
beam threshold 10 : i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.2091 secs)
beam threshold 25 : i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.2304 secs)
language model weight (語言模型權重)¶
lm_weight 參數是要分配給語言模型分數的權重,該分數將與聲學模型分數累加,以確定總體分數。較大的權重會鼓勵模型根據語言模型預測下一個單字,而較小的權重則會更多地權重聲學模型分數。
lm_weights = [0, LM_WEIGHT, 15]
for lm_weight in lm_weights:
beam_search_decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
lm_weight=lm_weight,
word_score=WORD_SCORE,
)
print_decoded(beam_search_decoder, emission, "lm weight", lm_weight)
lm weight 0 : i rely was very much affraid of showing him ho much shoke i was at some parte of what he seid (score: 3834.05; 0.2525 secs)
lm weight 3.23: i really was very much afraid of showing him how much shocked i was at some part of what he said (score: 3699.82; 0.2589 secs)
lm weight 15 : was there in his was at some of what he said (score: 2918.99; 0.2394 secs)
其他參數¶
可以最佳化的其他參數包括以下內容
word_score:單字完成時要新增的分數unk_score:要新增的未知單字外觀分數sil_score:要新增的靜音外觀分數log_add:是否對詞彙 Trie smearing 使用 log add
腳本總執行時間: ( 2 分鐘 57.274 秒)
