


注意
按一下這裡下載完整的範例程式碼
使用 MVDR 波束成形的語音增強¶
作者:Zhaoheng Ni
1. 概述¶
本教學說明如何應用最小方差無失真響應 (MVDR) 波束成形來估計使用 TorchAudio 增強的語音。
步驟
透過將乾淨/噪音幅度除以混合幅度來產生理想比率遮罩 (IRM)。
使用
torchaudio.transforms.PSD()估計功率譜密度 (PSD) 矩陣。使用 MVDR 模組 (
torchaudio.transforms.SoudenMVDR()和torchaudio.transforms.RTFMVDR()) 估計增強的語音。比較兩種方法 (
torchaudio.functional.rtf_evd()和torchaudio.functional.rtf_power()) 在計算參考麥克風的相對轉移函數 (RTF) 矩陣的效能。
import torch
import torchaudio
import torchaudio.functional as F
print(torch.__version__)
print(torchaudio.__version__)
import matplotlib.pyplot as plt
import mir_eval
from IPython.display import Audio
2.6.0
2.6.0
2. 準備¶
2.1. 匯入套件¶
首先,我們安裝並匯入必要的套件。
評估語音增強效能需要 mir_eval、pesq 和 pystoi 套件。
# When running this example in notebook, install the following packages.
# !pip3 install mir_eval
# !pip3 install pesq
# !pip3 install pystoi
from pesq import pesq
from pystoi import stoi
from torchaudio.utils import download_asset
2.2. 下載音訊資料¶
多聲道音訊範例選自 ConferencingSpeech 資料集。
原始檔名為
SSB07200001\#noise-sound-bible-0038\#7.86_6.16_3.00_3.14_4.84_134.5285_191.7899_0.4735\#15217\#25.16333303751458\#0.2101221178590021.wav
該檔案由以下檔案產生:
SSB07200001.wav來自 AISHELL-3 (Apache License v.2.0)noise-sound-bible-0038.wav來自 MUSAN (Attribution 4.0 International — CC BY 4.0)
SAMPLE_RATE = 16000
SAMPLE_CLEAN = download_asset("tutorial-assets/mvdr/clean_speech.wav")
SAMPLE_NOISE = download_asset("tutorial-assets/mvdr/noise.wav")
0%| | 0.00/0.98M [00:00<?, ?B/s]
100%|##########| 0.98M/0.98M [00:00<00:00, 53.9MB/s]
0%| | 0.00/1.95M [00:00<?, ?B/s]
100%|##########| 1.95M/1.95M [00:00<00:00, 90.1MB/s]
2.3. 輔助函式¶
def plot_spectrogram(stft, title="Spectrogram"):
magnitude = stft.abs()
spectrogram = 20 * torch.log10(magnitude + 1e-8).numpy()
figure, axis = plt.subplots(1, 1)
img = axis.imshow(spectrogram, cmap="viridis", vmin=-100, vmax=0, origin="lower", aspect="auto")
axis.set_title(title)
plt.colorbar(img, ax=axis)
def plot_mask(mask, title="Mask"):
mask = mask.numpy()
figure, axis = plt.subplots(1, 1)
img = axis.imshow(mask, cmap="viridis", origin="lower", aspect="auto")
axis.set_title(title)
plt.colorbar(img, ax=axis)
def si_snr(estimate, reference, epsilon=1e-8):
estimate = estimate - estimate.mean()
reference = reference - reference.mean()
reference_pow = reference.pow(2).mean(axis=1, keepdim=True)
mix_pow = (estimate * reference).mean(axis=1, keepdim=True)
scale = mix_pow / (reference_pow + epsilon)
reference = scale * reference
error = estimate - reference
reference_pow = reference.pow(2)
error_pow = error.pow(2)
reference_pow = reference_pow.mean(axis=1)
error_pow = error_pow.mean(axis=1)
si_snr = 10 * torch.log10(reference_pow) - 10 * torch.log10(error_pow)
return si_snr.item()
def generate_mixture(waveform_clean, waveform_noise, target_snr):
power_clean_signal = waveform_clean.pow(2).mean()
power_noise_signal = waveform_noise.pow(2).mean()
current_snr = 10 * torch.log10(power_clean_signal / power_noise_signal)
waveform_noise *= 10 ** (-(target_snr - current_snr) / 20)
return waveform_clean + waveform_noise
def evaluate(estimate, reference):
si_snr_score = si_snr(estimate, reference)
(
sdr,
_,
_,
_,
) = mir_eval.separation.bss_eval_sources(reference.numpy(), estimate.numpy(), False)
pesq_mix = pesq(SAMPLE_RATE, estimate[0].numpy(), reference[0].numpy(), "wb")
stoi_mix = stoi(reference[0].numpy(), estimate[0].numpy(), SAMPLE_RATE, extended=False)
print(f"SDR score: {sdr[0]}")
print(f"Si-SNR score: {si_snr_score}")
print(f"PESQ score: {pesq_mix}")
print(f"STOI score: {stoi_mix}")
3. 產生理想比例遮罩 (IRMs)¶
3.1. 載入音訊資料¶
waveform_clean, sr = torchaudio.load(SAMPLE_CLEAN)
waveform_noise, sr2 = torchaudio.load(SAMPLE_NOISE)
assert sr == sr2 == SAMPLE_RATE
# The mixture waveform is a combination of clean and noise waveforms with a desired SNR.
target_snr = 3
waveform_mix = generate_mixture(waveform_clean, waveform_noise, target_snr)
注意:為了提高計算的穩定性,建議將波形表示為雙精度浮點數 (torch.float64 或 torch.double) 值。
3.2. 計算 STFT 係數¶
N_FFT = 1024
N_HOP = 256
stft = torchaudio.transforms.Spectrogram(
n_fft=N_FFT,
hop_length=N_HOP,
power=None,
)
istft = torchaudio.transforms.InverseSpectrogram(n_fft=N_FFT, hop_length=N_HOP)
stft_mix = stft(waveform_mix)
stft_clean = stft(waveform_clean)
stft_noise = stft(waveform_noise)
3.2.1. 可視化混合語音¶
我們使用以下三個指標來評估混合語音或增強語音的品質:
訊號失真比 (SDR)
尺度不變訊號雜訊比 (Si-SNR,或在某些論文中稱為 Si-SDR)
語音品質感知評估 (PESQ)
我們還使用短時客觀可懂度 (STOI) 指標來評估語音的可懂度。
plot_spectrogram(stft_mix[0], "Spectrogram of Mixture Speech (dB)")
evaluate(waveform_mix[0:1], waveform_clean[0:1])
Audio(waveform_mix[0], rate=SAMPLE_RATE)
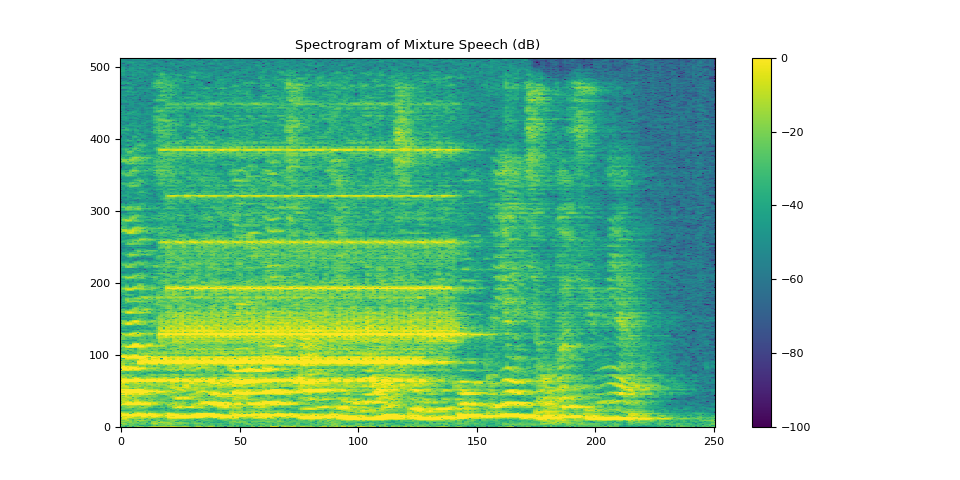
SDR score: 4.140362181778018
Si-SNR score: 4.104058905536078
PESQ score: 2.0084526538848877
STOI score: 0.7724339398714715
3.2.2. 可視化乾淨語音¶
plot_spectrogram(stft_clean[0], "Spectrogram of Clean Speech (dB)")
Audio(waveform_clean[0], rate=SAMPLE_RATE)
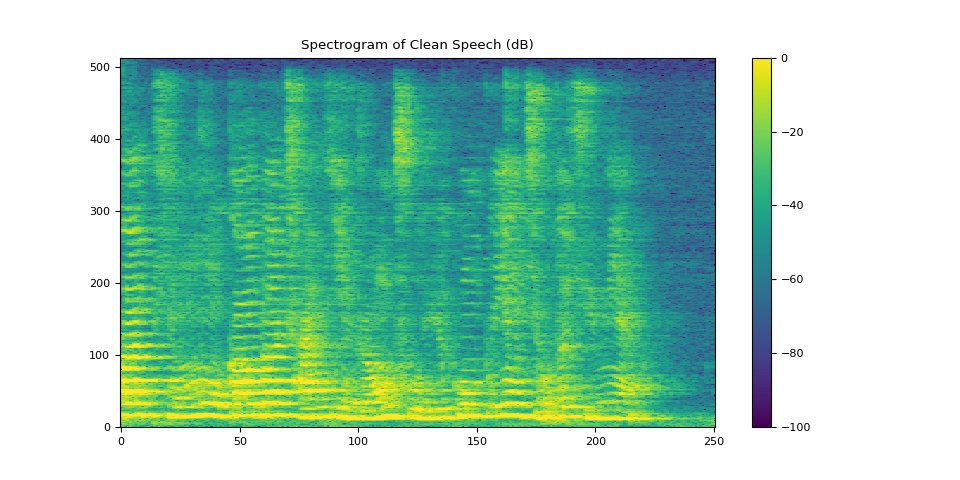
3.2.3. 可視化雜訊¶
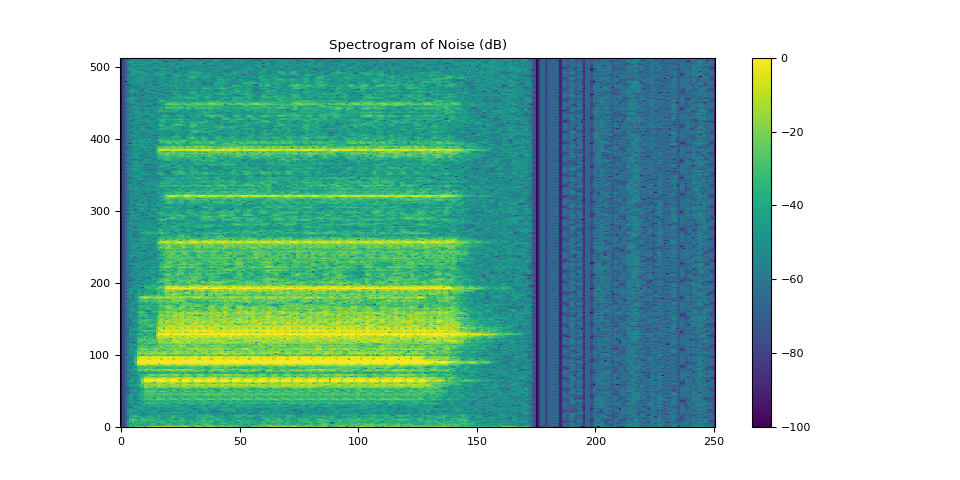
plot_spectrogram(stft_noise[0], "Spectrogram of Noise (dB)")
Audio(waveform_noise[0], rate=SAMPLE_RATE)
3.3. 定義參考麥克風¶
為了演示,我們選擇陣列中的第一個麥克風作為參考通道。 參考通道的選擇可能取決於麥克風陣列的設計。
您也可以應用端到端神經網路,該網路可以估算參考通道和 PSD 矩陣,然後透過 MVDR 模組獲得增強的 STFT 係數。
3.4. 計算 IRMs¶
def get_irms(stft_clean, stft_noise):
mag_clean = stft_clean.abs() ** 2
mag_noise = stft_noise.abs() ** 2
irm_speech = mag_clean / (mag_clean + mag_noise)
irm_noise = mag_noise / (mag_clean + mag_noise)
return irm_speech[REFERENCE_CHANNEL], irm_noise[REFERENCE_CHANNEL]
irm_speech, irm_noise = get_irms(stft_clean, stft_noise)
3.4.1. 可視化目標語音的 IRM¶
plot_mask(irm_speech, "IRM of the Target Speech")
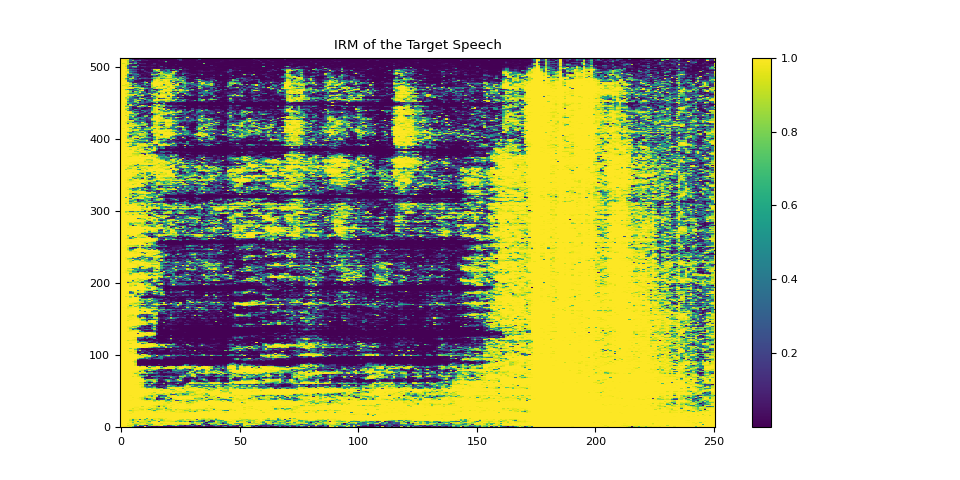
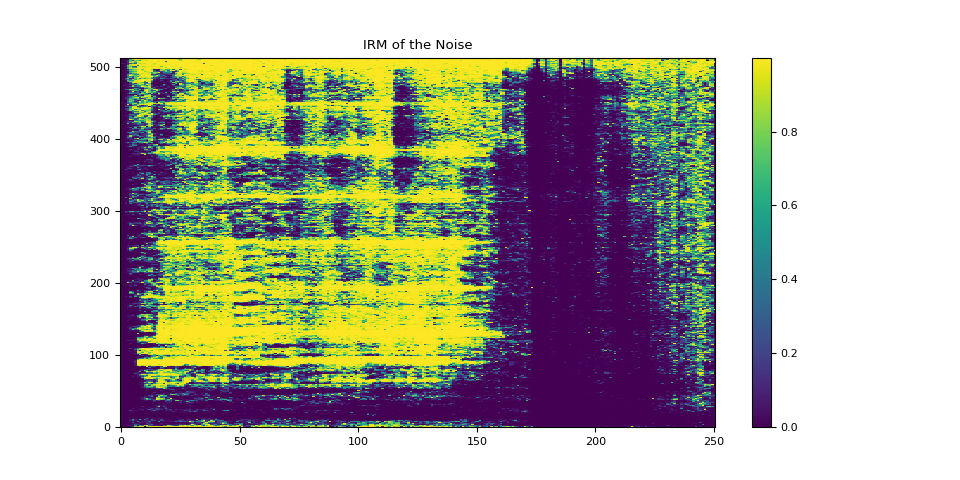
3.4.2. 可視化雜訊的 IRM¶
plot_mask(irm_noise, "IRM of the Noise")
4. 計算 PSD 矩陣¶
torchaudio.transforms.PSD() 給定混合語音的多聲道複數值 STFT 係數和時頻遮罩,計算時不變 PSD 矩陣。
PSD 矩陣的形狀為 (…, freq, channel, channel)。
psd_transform = torchaudio.transforms.PSD()
psd_speech = psd_transform(stft_mix, irm_speech)
psd_noise = psd_transform(stft_mix, irm_noise)
5. 使用 SoudenMVDR 進行波束成形¶
5.1. 應用波束成形¶
torchaudio.transforms.SoudenMVDR() 採用混合語音的多聲道複數值 STFT 係數、目標語音和雜訊的 PSD 矩陣以及參考通道輸入。
輸出是增強語音的單聲道複數值 STFT 係數。 然後,我們可以將此輸出傳遞到 torchaudio.transforms.InverseSpectrogram() 模組來獲得增強的波形。
mvdr_transform = torchaudio.transforms.SoudenMVDR()
stft_souden = mvdr_transform(stft_mix, psd_speech, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_souden = istft(stft_souden, length=waveform_mix.shape[-1])
5.2. SoudenMVDR 的結果¶
plot_spectrogram(stft_souden, "Enhanced Spectrogram by SoudenMVDR (dB)")
waveform_souden = waveform_souden.reshape(1, -1)
evaluate(waveform_souden, waveform_clean[0:1])
Audio(waveform_souden, rate=SAMPLE_RATE)
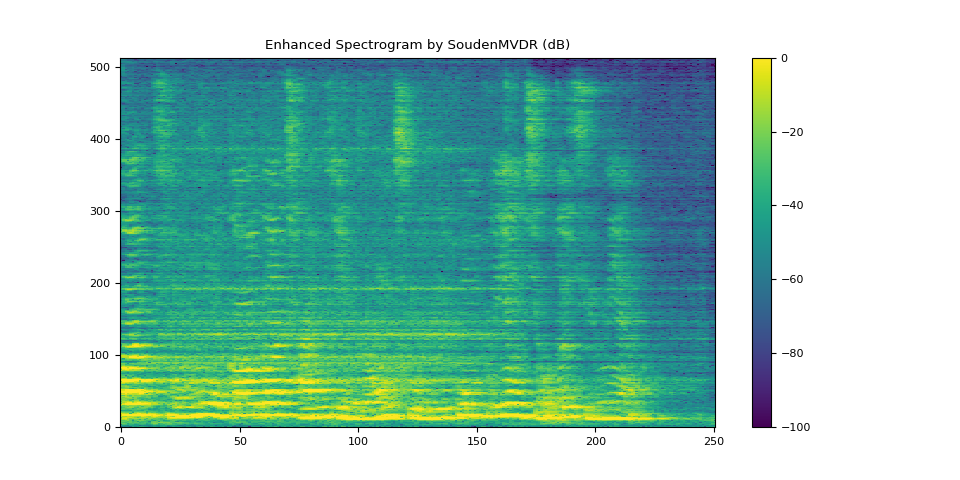
SDR score: 17.946234447508765
Si-SNR score: 12.215202612266587
PESQ score: 3.3447437286376953
STOI score: 0.8712864479161743
6. 使用 RTFMVDR 進行波束成形¶
6.1. 計算 RTF¶
TorchAudio 提供了兩種計算目標語音 RTF 矩陣的方法:
torchaudio.functional.rtf_evd(),它將特徵值分解應用於目標語音的 PSD 矩陣,以取得 RTF 矩陣。torchaudio.functional.rtf_power(),它應用冪迭代法。 您可以使用參數n_iter指定迭代次數。
rtf_evd = F.rtf_evd(psd_speech)
rtf_power = F.rtf_power(psd_speech, psd_noise, reference_channel=REFERENCE_CHANNEL)
6.2. 應用波束成形¶
torchaudio.transforms.RTFMVDR() 採用混合語音的多聲道複數值 STFT 係數、目標語音的 RTF 矩陣、雜訊的 PSD 矩陣以及參考通道輸入。
輸出是增強語音的單聲道複數值 STFT 係數。 然後,我們可以將此輸出傳遞到 torchaudio.transforms.InverseSpectrogram() 模組來獲得增強的波形。
mvdr_transform = torchaudio.transforms.RTFMVDR()
# compute the enhanced speech based on F.rtf_evd
stft_rtf_evd = mvdr_transform(stft_mix, rtf_evd, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_rtf_evd = istft(stft_rtf_evd, length=waveform_mix.shape[-1])
# compute the enhanced speech based on F.rtf_power
stft_rtf_power = mvdr_transform(stft_mix, rtf_power, psd_noise, reference_channel=REFERENCE_CHANNEL)
waveform_rtf_power = istft(stft_rtf_power, length=waveform_mix.shape[-1])
6.3. 使用 rtf_evd 的 RTFMVDR 結果¶
plot_spectrogram(stft_rtf_evd, "Enhanced Spectrogram by RTFMVDR and F.rtf_evd (dB)")
waveform_rtf_evd = waveform_rtf_evd.reshape(1, -1)
evaluate(waveform_rtf_evd, waveform_clean[0:1])
Audio(waveform_rtf_evd, rate=SAMPLE_RATE)
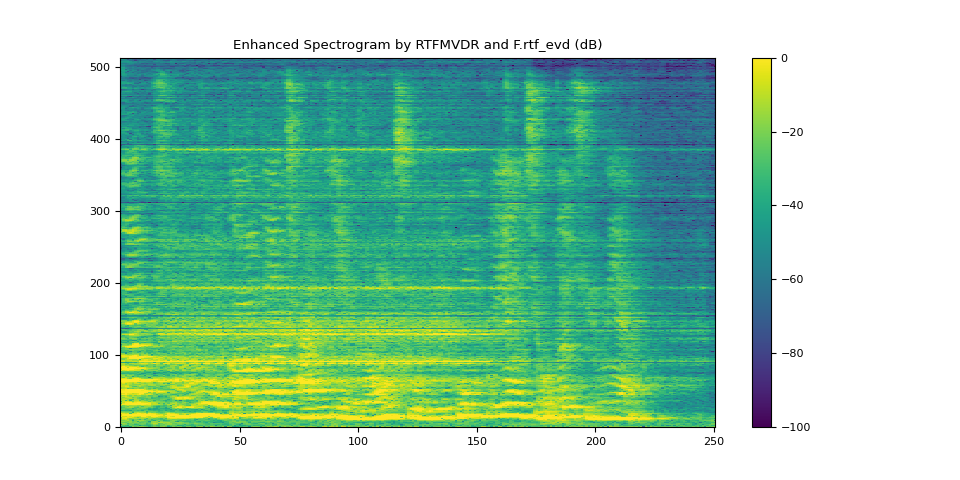
SDR score: 11.880210635280273
Si-SNR score: 10.714419996128061
PESQ score: 3.083890914916992
STOI score: 0.8261544910053075
6.4. 使用 rtf_power 的 RTFMVDR 結果¶
plot_spectrogram(stft_rtf_power, "Enhanced Spectrogram by RTFMVDR and F.rtf_power (dB)")
waveform_rtf_power = waveform_rtf_power.reshape(1, -1)
evaluate(waveform_rtf_power, waveform_clean[0:1])
Audio(waveform_rtf_power, rate=SAMPLE_RATE)
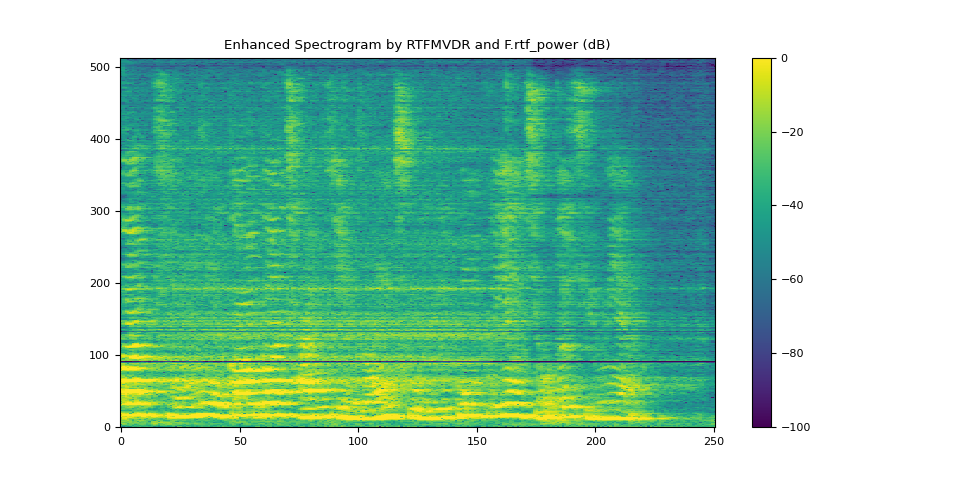
SDR score: 15.424590276934103
Si-SNR score: 13.035440892133451
PESQ score: 3.487997531890869
STOI score: 0.8798278461896808
腳本總運行時間: (0 分鐘 2.176 秒)
