


注意
點擊此處下載完整的範例程式碼
CTC 強制對齊 API 教學¶
作者: Xiaohui Zhang, Moto Hira
強制對齊是一個將語音與文本轉錄對齊的過程。本教學展示如何使用 torchaudio.functional.forced_align() 將文本轉錄與語音對齊,該函數是隨著 將語音技術擴展到 1,000 多種語言 的工作一起開發的。
forced_align() 具有自訂的 CPU 和 CUDA 實作,它們比上面的 vanilla Python 實作更有效能,並且更準確。它還可以處理遺失的文本轉錄,使用特殊的 <star> 符號。
還有一個高階 API,torchaudio.pipelines.Wav2Vec2FABundle,它封裝了本教學中解釋的預處理/後處理,並且可以輕鬆執行強制對齊。多語資料的強制對齊 使用此 API 來說明如何對齊非英語文本轉錄。
準備工作¶
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.6.0
2.6.0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
cuda
import IPython
import matplotlib.pyplot as plt
import torchaudio.functional as F
首先,我們準備要使用的語音資料和文本轉錄。
SPEECH_FILE = torchaudio.utils.download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
waveform, _ = torchaudio.load(SPEECH_FILE)
TRANSCRIPT = "i had that curiosity beside me at this moment".split()
產生 emission¶
forced_align() 接受 emission 和 token 序列,並輸出 token 的時間戳記及其分數。
Emission 表示基於 frame 的 token 機率分佈,並且可以透過將波形傳遞給聲學模型來獲得。
Token 是 transcript(語音轉錄文本)的數值表示。有很多種 token 化 transcript 的方法,但在這裡,我們簡單地將字母映射為整數,這也是我們將要使用的聲學模型在訓練時構建 label 的方式。
我們將使用預訓練的 Wav2Vec2 模型,torchaudio.pipelines.MMS_FA,來獲取 emission 並 token 化 transcript。
bundle = torchaudio.pipelines.MMS_FA
model = bundle.get_model(with_star=False).to(device)
with torch.inference_mode():
emission, _ = model(waveform.to(device))
Downloading: "https://dl.fbaipublicfiles.com/mms/torchaudio/ctc_alignment_mling_uroman/model.pt" to /root/.cache/torch/hub/checkpoints/model.pt
0%| | 0.00/1.18G [00:00<?, ?B/s]
3%|2 | 30.5M/1.18G [00:00<00:03, 319MB/s]
5%|5 | 61.0M/1.18G [00:00<00:03, 317MB/s]
8%|7 | 91.8M/1.18G [00:00<00:03, 319MB/s]
10%|# | 122M/1.18G [00:00<00:03, 308MB/s]
13%|#3 | 161M/1.18G [00:00<00:03, 342MB/s]
16%|#6 | 195M/1.18G [00:00<00:03, 347MB/s]
19%|#9 | 233M/1.18G [00:00<00:02, 365MB/s]
22%|##2 | 268M/1.18G [00:00<00:02, 333MB/s]
26%|##5 | 308M/1.18G [00:00<00:02, 357MB/s]
29%|##8 | 348M/1.18G [00:01<00:02, 375MB/s]
32%|###2 | 390M/1.18G [00:01<00:02, 392MB/s]
36%|###5 | 427M/1.18G [00:01<00:02, 376MB/s]
39%|###8 | 464M/1.18G [00:01<00:02, 364MB/s]
41%|####1 | 499M/1.18G [00:01<00:02, 360MB/s]
44%|####4 | 534M/1.18G [00:01<00:01, 364MB/s]
47%|####7 | 569M/1.18G [00:01<00:01, 360MB/s]
50%|##### | 607M/1.18G [00:01<00:01, 369MB/s]
53%|#####3 | 642M/1.18G [00:01<00:01, 368MB/s]
57%|#####6 | 680M/1.18G [00:01<00:01, 376MB/s]
59%|#####9 | 716M/1.18G [00:02<00:01, 375MB/s]
63%|######2 | 753M/1.18G [00:02<00:01, 377MB/s]
66%|######5 | 789M/1.18G [00:02<00:01, 374MB/s]
69%|######8 | 828M/1.18G [00:02<00:01, 383MB/s]
72%|#######1 | 864M/1.18G [00:02<00:00, 382MB/s]
75%|#######5 | 906M/1.18G [00:02<00:00, 397MB/s]
79%|#######8 | 947M/1.18G [00:02<00:00, 408MB/s]
82%|########1 | 986M/1.18G [00:02<00:00, 408MB/s]
85%|########5 | 1.00G/1.18G [00:02<00:00, 397MB/s]
89%|########8 | 1.04G/1.18G [00:03<00:00, 417MB/s]
92%|#########2| 1.08G/1.18G [00:03<00:00, 372MB/s]
95%|#########5| 1.12G/1.18G [00:03<00:00, 370MB/s]
98%|#########8| 1.15G/1.18G [00:03<00:00, 362MB/s]
100%|##########| 1.18G/1.18G [00:03<00:00, 369MB/s]
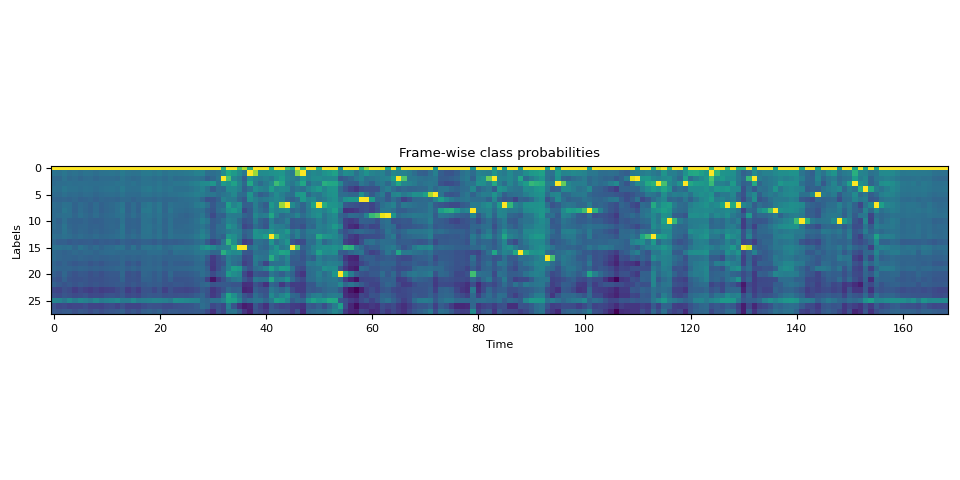
Token 化 transcript¶
我們建立一個字典,將每個 label 映射到 token。
LABELS = bundle.get_labels(star=None)
DICTIONARY = bundle.get_dict(star=None)
for k, v in DICTIONARY.items():
print(f"{k}: {v}")
-: 0
a: 1
i: 2
e: 3
n: 4
o: 5
u: 6
t: 7
s: 8
r: 9
m: 10
k: 11
l: 12
d: 13
g: 14
h: 15
y: 16
b: 17
p: 18
w: 19
c: 20
v: 21
j: 22
z: 23
f: 24
': 25
q: 26
x: 27
將 transcript 轉換為 token 非常簡單,如下:
tokenized_transcript = [DICTIONARY[c] for word in TRANSCRIPT for c in word]
for t in tokenized_transcript:
print(t, end=" ")
print()
2 15 1 13 7 15 1 7 20 6 9 2 5 8 2 7 16 17 3 8 2 13 3 10 3 1 7 7 15 2 8 10 5 10 3 4 7
計算 alignment (對齊)¶
Frame-level alignment (幀級對齊)¶
現在我們調用 TorchAudio 的 forced alignment (強制對齊) API 來計算 frame-level alignment。關於函數簽名的詳細信息,請參考 forced_align()。
def align(emission, tokens):
targets = torch.tensor([tokens], dtype=torch.int32, device=device)
alignments, scores = F.forced_align(emission, targets, blank=0)
alignments, scores = alignments[0], scores[0] # remove batch dimension for simplicity
scores = scores.exp() # convert back to probability
return alignments, scores
aligned_tokens, alignment_scores = align(emission, tokenized_transcript)
現在讓我們看看輸出。
for i, (ali, score) in enumerate(zip(aligned_tokens, alignment_scores)):
print(f"{i:3d}:\t{ali:2d} [{LABELS[ali]}], {score:.2f}")
0: 0 [-], 1.00
1: 0 [-], 1.00
2: 0 [-], 1.00
3: 0 [-], 1.00
4: 0 [-], 1.00
5: 0 [-], 1.00
6: 0 [-], 1.00
7: 0 [-], 1.00
8: 0 [-], 1.00
9: 0 [-], 1.00
10: 0 [-], 1.00
11: 0 [-], 1.00
12: 0 [-], 1.00
13: 0 [-], 1.00
14: 0 [-], 1.00
15: 0 [-], 1.00
16: 0 [-], 1.00
17: 0 [-], 1.00
18: 0 [-], 1.00
19: 0 [-], 1.00
20: 0 [-], 1.00
21: 0 [-], 1.00
22: 0 [-], 1.00
23: 0 [-], 1.00
24: 0 [-], 1.00
25: 0 [-], 1.00
26: 0 [-], 1.00
27: 0 [-], 1.00
28: 0 [-], 1.00
29: 0 [-], 1.00
30: 0 [-], 1.00
31: 0 [-], 1.00
32: 2 [i], 1.00
33: 0 [-], 1.00
34: 0 [-], 1.00
35: 15 [h], 1.00
36: 15 [h], 0.93
37: 1 [a], 1.00
38: 0 [-], 0.96
39: 0 [-], 1.00
40: 0 [-], 1.00
41: 13 [d], 1.00
42: 0 [-], 1.00
43: 0 [-], 0.97
44: 7 [t], 1.00
45: 15 [h], 1.00
46: 0 [-], 0.98
47: 1 [a], 1.00
48: 0 [-], 1.00
49: 0 [-], 1.00
50: 7 [t], 1.00
51: 0 [-], 1.00
52: 0 [-], 1.00
53: 0 [-], 1.00
54: 20 [c], 1.00
55: 0 [-], 1.00
56: 0 [-], 1.00
57: 0 [-], 1.00
58: 6 [u], 1.00
59: 6 [u], 0.96
60: 0 [-], 1.00
61: 0 [-], 1.00
62: 0 [-], 0.53
63: 9 [r], 1.00
64: 0 [-], 1.00
65: 2 [i], 1.00
66: 0 [-], 1.00
67: 0 [-], 1.00
68: 0 [-], 1.00
69: 0 [-], 1.00
70: 0 [-], 1.00
71: 0 [-], 0.96
72: 5 [o], 1.00
73: 0 [-], 1.00
74: 0 [-], 1.00
75: 0 [-], 1.00
76: 0 [-], 1.00
77: 0 [-], 1.00
78: 0 [-], 1.00
79: 8 [s], 1.00
80: 0 [-], 1.00
81: 0 [-], 1.00
82: 0 [-], 0.99
83: 2 [i], 1.00
84: 0 [-], 1.00
85: 7 [t], 1.00
86: 0 [-], 1.00
87: 0 [-], 1.00
88: 16 [y], 1.00
89: 0 [-], 1.00
90: 0 [-], 1.00
91: 0 [-], 1.00
92: 0 [-], 1.00
93: 17 [b], 1.00
94: 0 [-], 1.00
95: 3 [e], 1.00
96: 0 [-], 1.00
97: 0 [-], 1.00
98: 0 [-], 1.00
99: 0 [-], 1.00
100: 0 [-], 1.00
101: 8 [s], 1.00
102: 0 [-], 1.00
103: 0 [-], 1.00
104: 0 [-], 1.00
105: 0 [-], 1.00
106: 0 [-], 1.00
107: 0 [-], 1.00
108: 0 [-], 1.00
109: 0 [-], 0.64
110: 2 [i], 1.00
111: 0 [-], 1.00
112: 0 [-], 1.00
113: 13 [d], 1.00
114: 3 [e], 0.85
115: 0 [-], 1.00
116: 10 [m], 1.00
117: 0 [-], 1.00
118: 0 [-], 1.00
119: 3 [e], 1.00
120: 0 [-], 1.00
121: 0 [-], 1.00
122: 0 [-], 1.00
123: 0 [-], 1.00
124: 1 [a], 1.00
125: 0 [-], 1.00
126: 0 [-], 1.00
127: 7 [t], 1.00
128: 0 [-], 1.00
129: 7 [t], 1.00
130: 15 [h], 1.00
131: 0 [-], 0.79
132: 2 [i], 1.00
133: 0 [-], 1.00
134: 0 [-], 1.00
135: 0 [-], 1.00
136: 8 [s], 1.00
137: 0 [-], 1.00
138: 0 [-], 1.00
139: 0 [-], 1.00
140: 0 [-], 1.00
141: 10 [m], 1.00
142: 0 [-], 1.00
143: 0 [-], 1.00
144: 5 [o], 1.00
145: 0 [-], 1.00
146: 0 [-], 1.00
147: 0 [-], 1.00
148: 10 [m], 1.00
149: 0 [-], 1.00
150: 0 [-], 1.00
151: 3 [e], 1.00
152: 0 [-], 1.00
153: 4 [n], 1.00
154: 0 [-], 1.00
155: 7 [t], 1.00
156: 0 [-], 1.00
157: 0 [-], 1.00
158: 0 [-], 1.00
159: 0 [-], 1.00
160: 0 [-], 1.00
161: 0 [-], 1.00
162: 0 [-], 1.00
163: 0 [-], 1.00
164: 0 [-], 1.00
165: 0 [-], 1.00
166: 0 [-], 1.00
167: 0 [-], 1.00
168: 0 [-], 1.00
注意
alignment 以 emission 的 frame 坐標表示,這與原始 waveform (波形) 不同。
它包含 blank token(空白 token)和 repeated token(重複 token)。以下是對 non-blank token(非空白 token)的解釋。
31: 0 [-], 1.00
32: 2 [i], 1.00 "i" starts and ends
33: 0 [-], 1.00
34: 0 [-], 1.00
35: 15 [h], 1.00 "h" starts
36: 15 [h], 0.93 "h" ends
37: 1 [a], 1.00 "a" starts and ends
38: 0 [-], 0.96
39: 0 [-], 1.00
40: 0 [-], 1.00
41: 13 [d], 1.00 "d" starts and ends
42: 0 [-], 1.00
注意
當相同的 token 出現在 blank token 之後,它不被視為重複,而是作為一個新的出現。
a a a b -> a b
a - - b -> a b
a a - b -> a b
a - a b -> a a b
^^^ ^^^
Token-level alignment (token 級對齊)¶
下一步是解決重複問題,以便每個 alignment 不依賴於先前的 alignment。 torchaudio.functional.merge_tokens() 計算 TokenSpan 對象,該對象表示 transcript 中的哪個 token 出現在哪個時間跨度。
token_spans = F.merge_tokens(aligned_tokens, alignment_scores)
print("Token\tTime\tScore")
for s in token_spans:
print(f"{LABELS[s.token]}\t[{s.start:3d}, {s.end:3d})\t{s.score:.2f}")
Token Time Score
i [ 32, 33) 1.00
h [ 35, 37) 0.96
a [ 37, 38) 1.00
d [ 41, 42) 1.00
t [ 44, 45) 1.00
h [ 45, 46) 1.00
a [ 47, 48) 1.00
t [ 50, 51) 1.00
c [ 54, 55) 1.00
u [ 58, 60) 0.98
r [ 63, 64) 1.00
i [ 65, 66) 1.00
o [ 72, 73) 1.00
s [ 79, 80) 1.00
i [ 83, 84) 1.00
t [ 85, 86) 1.00
y [ 88, 89) 1.00
b [ 93, 94) 1.00
e [ 95, 96) 1.00
s [101, 102) 1.00
i [110, 111) 1.00
d [113, 114) 1.00
e [114, 115) 0.85
m [116, 117) 1.00
e [119, 120) 1.00
a [124, 125) 1.00
t [127, 128) 1.00
t [129, 130) 1.00
h [130, 131) 1.00
i [132, 133) 1.00
s [136, 137) 1.00
m [141, 142) 1.00
o [144, 145) 1.00
m [148, 149) 1.00
e [151, 152) 1.00
n [153, 154) 1.00
t [155, 156) 1.00
Word-level alignment (詞級對齊)¶
現在讓我們將 token-level alignment 分組為 word-level alignment。
def unflatten(list_, lengths):
assert len(list_) == sum(lengths)
i = 0
ret = []
for l in lengths:
ret.append(list_[i : i + l])
i += l
return ret
word_spans = unflatten(token_spans, [len(word) for word in TRANSCRIPT])
Audio previews (音訊預覽)¶
# Compute average score weighted by the span length
def _score(spans):
return sum(s.score * len(s) for s in spans) / sum(len(s) for s in spans)
def preview_word(waveform, spans, num_frames, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / num_frames
x0 = int(ratio * spans[0].start)
x1 = int(ratio * spans[-1].end)
print(f"{transcript} ({_score(spans):.2f}): {x0 / sample_rate:.3f} - {x1 / sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=sample_rate)
num_frames = emission.size(1)
# Generate the audio for each segment
print(TRANSCRIPT)
IPython.display.Audio(SPEECH_FILE)
['i', 'had', 'that', 'curiosity', 'beside', 'me', 'at', 'this', 'moment']
preview_word(waveform, word_spans[0], num_frames, TRANSCRIPT[0])
i (1.00): 0.644 - 0.664 sec
preview_word(waveform, word_spans[1], num_frames, TRANSCRIPT[1])
had (0.98): 0.704 - 0.845 sec
preview_word(waveform, word_spans[2], num_frames, TRANSCRIPT[2])
that (1.00): 0.885 - 1.026 sec
preview_word(waveform, word_spans[3], num_frames, TRANSCRIPT[3])
curiosity (1.00): 1.086 - 1.790 sec
preview_word(waveform, word_spans[4], num_frames, TRANSCRIPT[4])
beside (0.97): 1.871 - 2.314 sec
preview_word(waveform, word_spans[5], num_frames, TRANSCRIPT[5])
me (1.00): 2.334 - 2.414 sec
preview_word(waveform, word_spans[6], num_frames, TRANSCRIPT[6])
at (1.00): 2.495 - 2.575 sec
preview_word(waveform, word_spans[7], num_frames, TRANSCRIPT[7])
this (1.00): 2.595 - 2.756 sec
preview_word(waveform, word_spans[8], num_frames, TRANSCRIPT[8])
moment (1.00): 2.837 - 3.138 sec
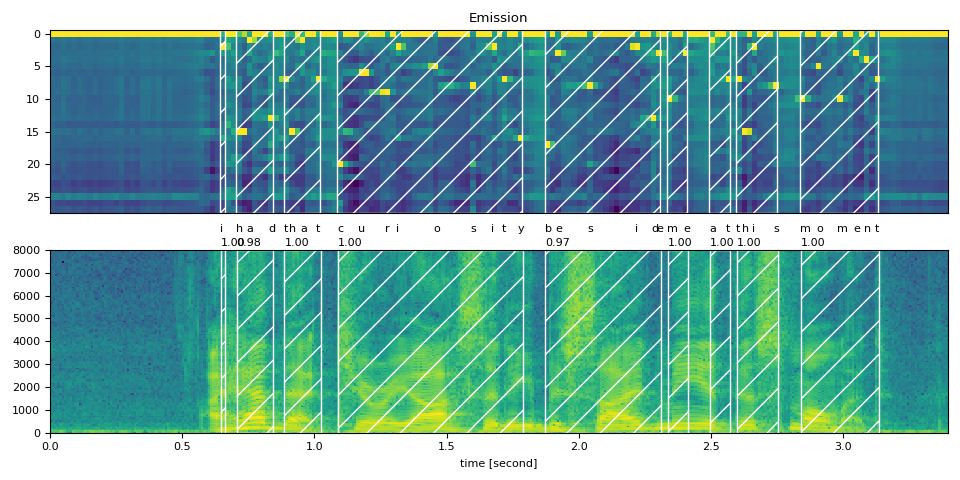
Visualization (可視化)¶
現在讓我們看看 alignment 結果,並將原始語音分割成單詞。
def plot_alignments(waveform, token_spans, emission, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / emission.size(1) / sample_rate
fig, axes = plt.subplots(2, 1)
axes[0].imshow(emission[0].detach().cpu().T, aspect="auto")
axes[0].set_title("Emission")
axes[0].set_xticks([])
axes[1].specgram(waveform[0], Fs=sample_rate)
for t_spans, chars in zip(token_spans, transcript):
t0, t1 = t_spans[0].start + 0.1, t_spans[-1].end - 0.1
axes[0].axvspan(t0 - 0.5, t1 - 0.5, facecolor="None", hatch="/", edgecolor="white")
axes[1].axvspan(ratio * t0, ratio * t1, facecolor="None", hatch="/", edgecolor="white")
axes[1].annotate(f"{_score(t_spans):.2f}", (ratio * t0, sample_rate * 0.51), annotation_clip=False)
for span, char in zip(t_spans, chars):
t0 = span.start * ratio
axes[1].annotate(char, (t0, sample_rate * 0.55), annotation_clip=False)
axes[1].set_xlabel("time [second]")
axes[1].set_xlim([0, None])
fig.tight_layout()
plot_alignments(waveform, word_spans, emission, TRANSCRIPT)
對 blank token 的不一致處理¶
將 token-level alignment 分割成單詞時,您會注意到某些 blank token 的處理方式不同,這使得對結果的解釋有些模糊。
當我們繪製分數時,這很容易看到。 下圖顯示了單詞區域和非單詞區域,以及非空白 token 的 frame-level 分數。
def plot_scores(word_spans, scores):
fig, ax = plt.subplots()
span_xs, span_hs = [], []
ax.axvspan(word_spans[0][0].start - 0.05, word_spans[-1][-1].end + 0.05, facecolor="paleturquoise", edgecolor="none", zorder=-1)
for t_span in word_spans:
for span in t_span:
for t in range(span.start, span.end):
span_xs.append(t + 0.5)
span_hs.append(scores[t].item())
ax.annotate(LABELS[span.token], (span.start, -0.07))
ax.axvspan(t_span[0].start - 0.05, t_span[-1].end + 0.05, facecolor="mistyrose", edgecolor="none", zorder=-1)
ax.bar(span_xs, span_hs, color="lightsalmon", edgecolor="coral")
ax.set_title("Frame-level scores and word segments")
ax.set_ylim(-0.1, None)
ax.grid(True, axis="y")
ax.axhline(0, color="black")
fig.tight_layout()
plot_scores(word_spans, alignment_scores)
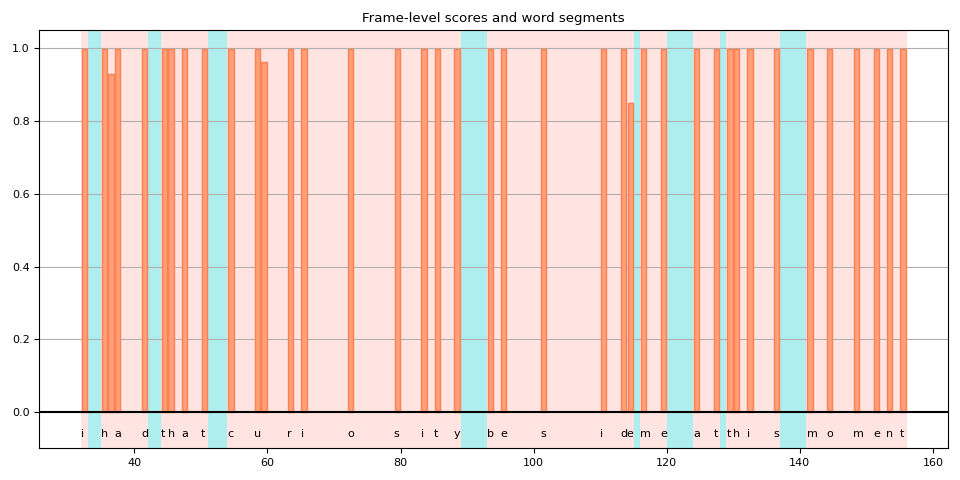
在此圖中,blank token 是那些沒有垂直條的突出顯示區域。 您可以看到有些 blank token 被解釋為單詞的一部分(紅色突出顯示),而另一些(藍色突出顯示)則不然。
其中一個原因是模型在訓練時沒有單詞邊界的 label。 Blank token 不僅被視為重複,還被視為單詞之間的沉默。
但是,隨之而來的是一個問題。 單詞結束後或附近的 frame 應該保持沉默還是重複?
在上面的例子中,如果你回到前面 spectrogram (聲譜圖) 和單詞區域的圖,你會看到在 "curiosity" 中的 "y" 之後,在多個頻率桶中仍然有一些活動。
如果將該 frame 包含在單詞中,是否會更準確?
不幸的是,CTC 沒有提供針對此問題的全面解決方案。 用 CTC 訓練的模型已知會表現出“peaky”(峰值)響應,也就是說,它們傾向於在 label 出現時出現峰值,但該峰值不會持續到 label 的持續時間。(注意:預訓練的 Wav2Vec2 模型傾向於在 label 出現的開始處出現峰值,但情況並非總是如此。)
[Zeyer et al., 2021] 對 CTC 的峰值行為進行了深入分析。 我們鼓勵那些有興趣了解更多的人參考該論文。 以下是該論文的一段引述,這正是我們在這裡面臨的問題。
在某些情況下,峰值行為可能會成為問題, 例如,當應用程式需要不使用空白 label 時, 例如,要獲得音素到轉錄的具有意義的時間準確對齊。
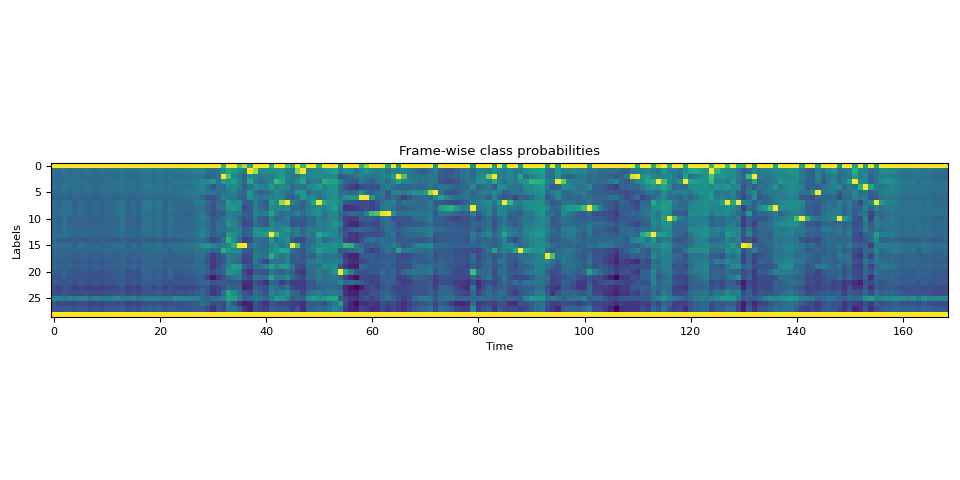
Advanced (進階): 處理帶有 <star> token 的 transcript¶
現在讓我們看看當 transcript 部分遺失時,我們如何使用 <star> token 來提高 alignment 品質,該 token 能夠對任何 token 進行建模。
在這裡,我們使用與上面相同的英文示例。 但是我們從 transcript 中刪除了開頭的文本 “i had that curiosity beside me at”。 將音訊與此類 transcript 對齊會導致現有單詞 "this" 的錯誤對齊。 但是,可以使用 <star> token 對遺失的文本進行建模,從而減輕此問題。
首先,我們擴展字典以包含 <star> token。
DICTIONARY["*"] = len(DICTIONARY)
接下來,我們使用與 <star> token 對應的額外維度來擴展 emission tensor。
star_dim = torch.zeros((1, emission.size(1), 1), device=emission.device, dtype=emission.dtype)
emission = torch.cat((emission, star_dim), 2)
assert len(DICTIONARY) == emission.shape[2]
plot_emission(emission[0])
以下函數組合了所有過程,並一次性從 emission 計算單詞片段。
def compute_alignments(emission, transcript, dictionary):
tokens = [dictionary[char] for word in transcript for char in word]
alignment, scores = align(emission, tokens)
token_spans = F.merge_tokens(alignment, scores)
word_spans = unflatten(token_spans, [len(word) for word in transcript])
return word_spans
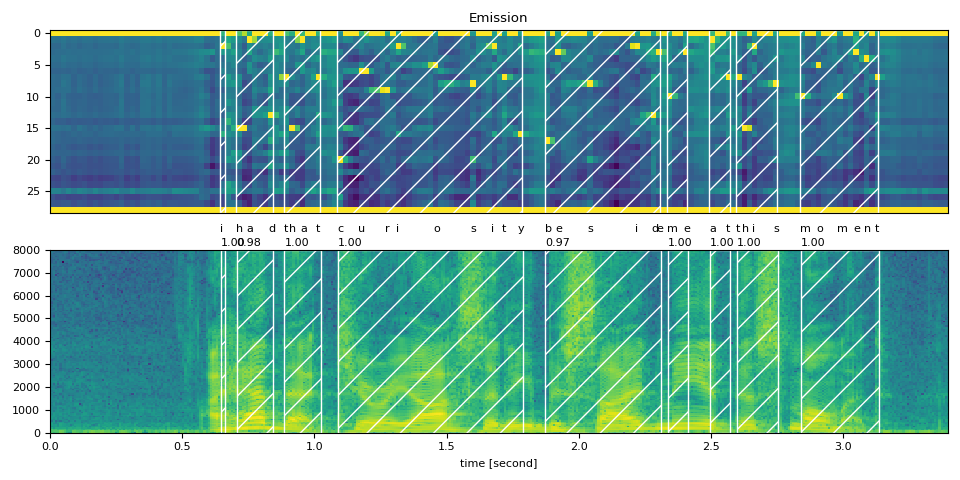
Full Transcript (完整 transcript)¶
word_spans = compute_alignments(emission, TRANSCRIPT, DICTIONARY)
plot_alignments(waveform, word_spans, emission, TRANSCRIPT)
Partial Transcript (部分 transcript) 帶有 <star> token¶
現在,我們將 transcript 的第一部分替換為 <star> token。
transcript = "* this moment".split()
word_spans = compute_alignments(emission, transcript, DICTIONARY)
plot_alignments(waveform, word_spans, emission, transcript)
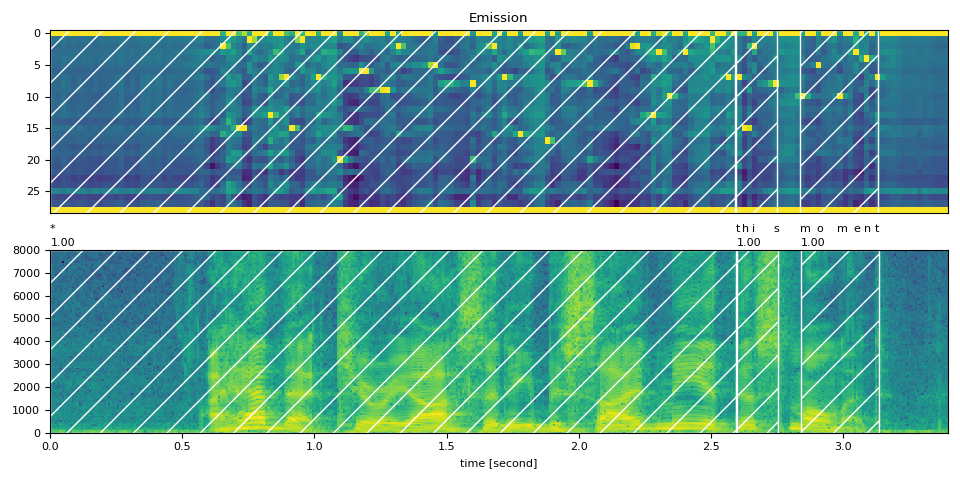
preview_word(waveform, word_spans[0], num_frames, transcript[0])
* (1.00): 0.000 - 2.595 sec
preview_word(waveform, word_spans[1], num_frames, transcript[1])
this (1.00): 2.595 - 2.756 sec
preview_word(waveform, word_spans[2], num_frames, transcript[2])
moment (1.00): 2.837 - 3.138 sec
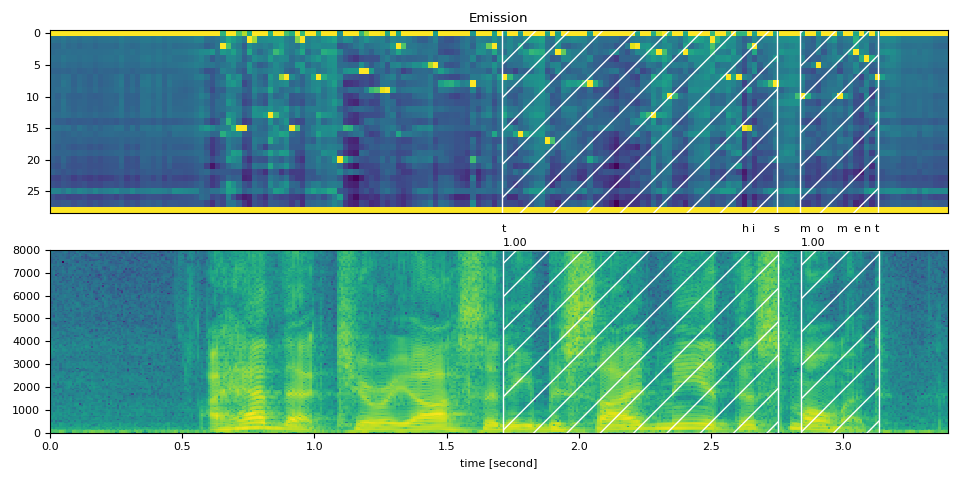
Partial Transcript (部分 transcript) 沒有 <star> token¶
作為比較,以下對齊了部分轉錄內容,但未使用 <star> token。這演示了 <star> token 在處理刪除錯誤方面的效果。
transcript = "this moment".split()
word_spans = compute_alignments(emission, transcript, DICTIONARY)
plot_alignments(waveform, word_spans, emission, transcript)
結論¶
在本教學中,我們研究了如何使用 torchaudio 的強制對齊 API 來對齊和分割語音檔案,並展示了一種進階用法:當轉錄中存在錯誤時,引入 <star> token 如何提高對齊準確度。
致謝¶
感謝 Vineel Pratap 和 Zhaoheng Ni 開發並開源強制對齊器 API。
腳本總執行時間: (0 分鐘 6.927 秒)
