torchaudio.transforms¶
torchaudio.transforms 模組包含常見的音訊處理和特徵提取。下圖顯示了一些可用轉換之間的關係。
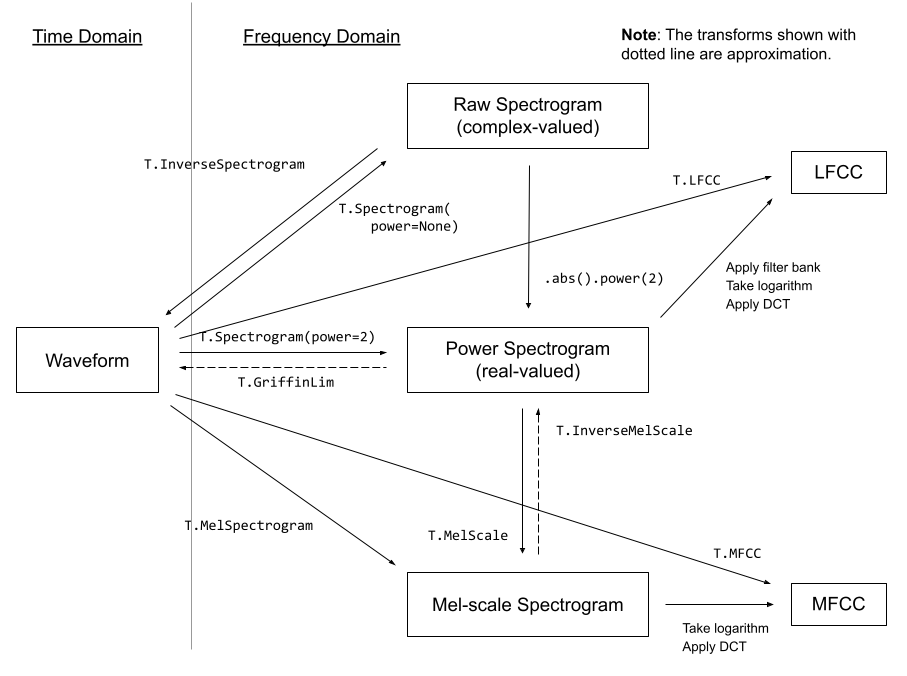
轉換是使用 torch.nn.Module 實作的。 建立處理管線的常用方法是定義自訂的 Module 類別,或使用 torch.nn.Sequential 將 Modules 鏈結在一起,然後將其移動到目標裝置和資料類型。
# Define custom feature extraction pipeline.
#
# 1. Resample audio
# 2. Convert to power spectrogram
# 3. Apply augmentations
# 4. Convert to mel-scale
#
class MyPipeline(torch.nn.Module):
def __init__(
self,
input_freq=16000,
resample_freq=8000,
n_fft=1024,
n_mel=256,
stretch_factor=0.8,
):
super().__init__()
self.resample = Resample(orig_freq=input_freq, new_freq=resample_freq)
self.spec = Spectrogram(n_fft=n_fft, power=2)
self.spec_aug = torch.nn.Sequential(
TimeStretch(stretch_factor, fixed_rate=True),
FrequencyMasking(freq_mask_param=80),
TimeMasking(time_mask_param=80),
)
self.mel_scale = MelScale(
n_mels=n_mel, sample_rate=resample_freq, n_stft=n_fft // 2 + 1)
def forward(self, waveform: torch.Tensor) -> torch.Tensor:
# Resample the input
resampled = self.resample(waveform)
# Convert to power spectrogram
spec = self.spec(resampled)
# Apply SpecAugment
spec = self.spec_aug(spec)
# Convert to mel-scale
mel = self.mel_scale(spec)
return mel
# Instantiate a pipeline
pipeline = MyPipeline()
# Move the computation graph to CUDA
pipeline.to(device=torch.device("cuda"), dtype=torch.float32)
# Perform the transform
features = pipeline(waveform)
請查看涵蓋 trasforms 深入用法的教學。
實用工具¶
將張量從功率/幅度尺度轉換為分貝尺度。 |
|
根據 mu-law 壓縮編碼訊號。 |
|
解碼 mu-law 編碼的訊號。 |
|
將訊號從一個頻率重新取樣到另一個頻率。 |
|
為波形新增淡入和/或淡出效果。 |
|
調整波形的音量。 |
|
根據 ITU-R BS.1770-4 建議測量音訊響度。 |
|
根據訊號雜訊比縮放波形並新增雜訊。 |
|
使用直接方法沿其最後一個維度捲積輸入。 |
|
使用 FFT 沿其最後一個維度捲積輸入。 |
|
調整波形速度。 |
|
應用 Audio augmentation for speech recognition 中介紹的速度擾動擴增 [Ko et al., 2015]。 |
|
沿其最後一個維度去強調波形。 |
|
沿其最後一個維度預強調波形。 |
特徵提取¶
從音訊訊號建立頻譜圖。 |
|
建立反向頻譜圖以從頻譜圖中恢復音訊訊號。 |
|
將一般 STFT 轉換為具有三角形濾波器組的梅爾頻率 STFT。 |
|
從梅爾頻率域估計一般頻率域中的 STFT。 |
|
為原始音訊訊號建立梅爾頻譜圖 (MelSpectrogram)。 |
|
使用 Griffin-Lim 轉換,從線性尺度幅度頻譜圖計算波形。 |
|
從音訊訊號建立梅爾頻率倒頻譜係數 (Mel-frequency cepstrum coefficients)。 |
|
從音訊訊號建立線性頻率倒頻譜係數 (linear-frequency cepstrum coefficients)。 |
|
計算張量的 delta 係數,通常是頻譜圖。 |
|
將波形的音調移動 |
|
對每個語句應用滑動窗口倒頻譜平均值(並可選擇方差)正規化。 |
|
沿時間軸計算每個聲道的頻譜質心。 |
|
語音活動檢測器 (Voice Activity Detector)。 |
擴增 (Augmentations)¶
以下轉換實作了流行的擴增技術,稱為SpecAugment [Park et al., 2019]。
在頻域中將遮罩應用於頻譜圖。 |
|
在時域中將遮罩應用於頻譜圖。 |
|
在給定速率下,在時間上延展 stft,而不修改音調。 |
損失 (Loss)¶
從具有循環神經網絡的序列轉換計算 RNN Transducer 損失 [Graves, 2012]。 |
多聲道 (Multi-channel)¶
計算跨聲道功率譜密度 (PSD) 矩陣。 |
|
最小變異數無失真響應 (MVDR) 模組,使用時頻遮罩執行 MVDR 波束成形。 |
|
基於相對傳遞函數 (RTF) 和雜訊功率譜密度 (PSD) 矩陣的最小變異數無失真響應(MVDR [Capon, 1969])模組。 |
|
基於 Souden et, al. [Souden et al., 2009] 提出的方法的最小變異數無失真響應 (MVDR [Capon, 1969]) 模組。 |
