ExecuTorch 概念¶
本頁提供 ExecuTorch 文件中使用的關鍵概念和術語的總覽。 目的是幫助讀者理解 PyTorch Edge 和 ExecuTorch 中使用的術語和概念。
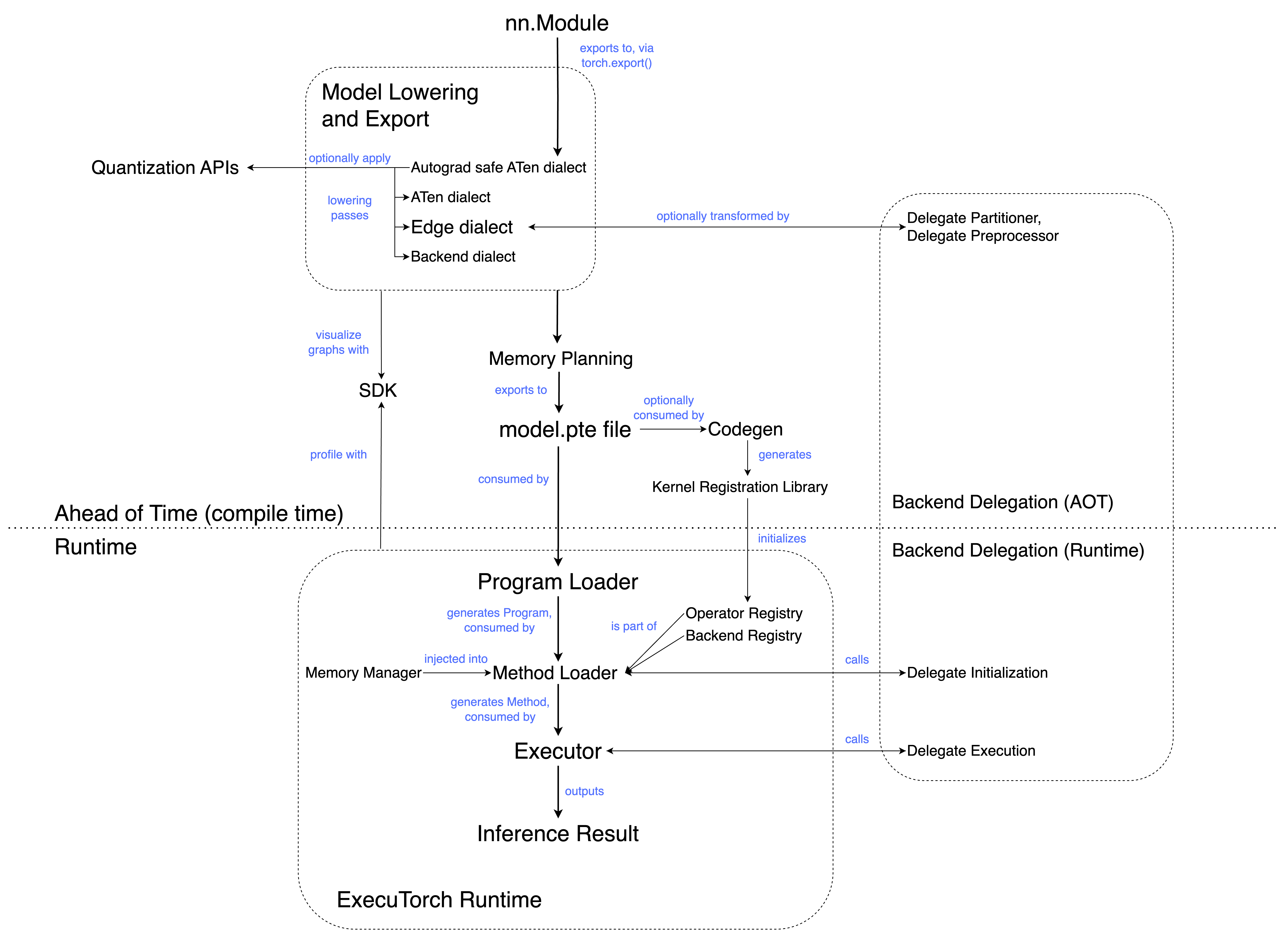
AOT (提前編譯)¶
AOT 通常指的是在執行前發生的程式準備。 在高階層級上,ExecuTorch 工作流程分為 AOT 編譯和執行階段。 AOT 步驟涉及編譯成中繼表示 (IR),以及選擇性的轉換和最佳化。
ATen 方言 (Dialect)¶
ATen 方言是将 eager 模組匯出為圖形表示法的直接結果。它是 ExecuTorch 編譯流程的入口點;在匯出為 ATen 方言後,後續的 pass 可以降低到 Core ATen 方言 和 Edge 方言。
ATen 方言是一個有效的 EXIR,並具有其他屬性。它包含函數式 ATen 運算符、高階運算符 (例如控制流程運算符) 和已註冊的自定義運算符。
ATen 方言的目標是尽可能忠实地捕捉用戶的程式。
ATen 模式¶
ATen 模式使用 PyTorch 核心中的 Tensor 的 ATen 實現 (at::Tensor) 和相關類型,例如 ScalarType。 這與 ETensor 模式形成對比,後者使用 ExecuTorch 的較小 Tensor 實現 (executorch::runtime::etensor::Tensor) 和相關類型,例如 executorch::runtime::etensor::ScalarType。
在這個配置中,可以使用依賴於完整
at::TensorAPI 的 ATen 核心。ATen 核心傾向於進行動態記憶體分配,並且通常具有額外的彈性 (以及因此產生的開銷) 來處理行動/嵌入式客戶端不需要的情況。例如,CUDA 支援、稀疏張量支援和 dtype 提升。
注意:ATen 模式目前正在開發中 (WIP)。
Autograd 安全的 ATen 方言¶
Autograd 安全的 ATen 方言僅包含可微分的 ATen 運算符,以及高階運算符 (控制流程運算) 和已註冊的自定義運算符。
後端 (Backend)¶
一個特定的硬體 (例如 GPU、NPU) 或軟體堆疊 (例如 XNNPACK),它使用圖形或其中的一部分,並具有效能和效率優勢。
後端方言 (Backend Dialect)¶
後端方言是将 Edge 方言匯出到特定後端的直接結果。 它是目標感知的,並且可能包含僅對目標後端有意義的運算符或子模組。 這種方言允許引入不符合 Core ATen 運算符集合中定義的模式,並且未在 ATen 或 Edge 方言中顯示的目標特定運算符。
後端註冊表 (Backend registry)¶
一個將後端名稱映射到後端介面的表。 這允許在運行時通過名稱呼叫後端。
後端特定運算符 (Backend Specific Operator)¶
這些是不屬於 ATen 方言或 Edge 方言的運算符。 後端特定運算符僅由 Edge 方言之後發生的 pass 引入 (請參閱後端方言)。 這些運算符特定於目標後端,並且通常會執行得更快。
程式碼生成 (Codegen)¶
在高層次上,程式碼生成執行兩項任務; 生成 核心註冊 (kernel registration) 函式庫,並可選地運行 選擇性建置 (selective build)。
核心註冊函式庫將運算符名稱 (在模型中引用) 與相應的核心實現 (來自核心函式庫) 連接起來。
選擇性建置 API 從模型和/或其他來源收集運算符資訊,並且僅包含它們所需的運算符。 這可以減少二進制檔的大小。
程式碼生成的輸出是一組 C++ 綁定 (各種 .h、.cpp 檔案),它們將核心函式庫和 ExecuTorch 運行時膠合在一起。
Core ATen 方言¶
Core ATen 方言包含核心 ATen 運算符,以及高階運算符 (控制流程) 和已註冊的自定義運算符。
核心 ATen 運算符 / 正規 ATen 運算符集合 (Canonical ATen operator set)¶
PyTorch ATen 運算符函式庫的一個精選子集。 使用核心 ATen 分解表匯出時,不會分解核心 ATen 運算符。 它們作為後端或編譯器應期望從上游獲得的基準 ATen 運算符的參考。
Core ATen 分解表 (Core ATen Decomposition Table)¶
分解運算符意味著將其表示為其他運算符的組合。 在 AOT 過程中,採用預設的分解決表,將 ATen 運算符分解為核心 ATen 運算符。 這被稱為 Core ATen 分解表。
自定義運算符 (Custom operator)¶
這些是不屬於 ATen 函式庫的運算符,但它們出現在 eager 模式 中。 註冊的自定義運算符會註冊到當前的 PyTorch eager 模式運行時中,通常使用 TORCH_LIBRARY 呼叫。 它們最有可能與特定的目標模型或硬體平台相關聯。 例如,torchvision::roi_align 是 torchvision 廣泛使用的自定義運算符 (不針對特定的硬體)。
資料載入器 (DataLoader)¶
一個介面,使 ExecuTorch 運行時能夠從檔案或其他資料來源讀取資料,而無需直接依賴於作業系統概念,如檔案或記憶體分配。
委派 (Delegation)¶
將程式的部分(或全部)在特定的後端(例如 XNNPACK)上執行,而程式的其餘部分(如果有的話)則在基本的 ExecuTorch 運行環境上執行。委派使我們能夠利用專業後端和硬體的效能和效率優勢。
維度順序 (Dim Order)¶
ExecuTorch 引入 Dim Order 來描述張量的記憶體格式,方法是傳回維度的排列,從最外層到最內層。
例如,對於具有記憶體格式 [N, C, H, W] 或 連續 (contiguous) 記憶體格式的張量,其維度順序將為 [0, 1, 2, 3]。
此外,對於具有記憶體格式 [N, H, W, C] 或 channels_last 記憶體格式的張量,我們傳回 [0, 2, 3, 1] 作為其維度順序。
目前,ExecuTorch 僅支援 連續 (contiguous) 和 channels_last 記憶體格式的維度順序表示。
DSP (數位訊號處理器)¶
一種專門的微處理器晶片,其架構針對數位訊號處理進行了最佳化。
dtype¶
資料類型,張量中資料的類型(例如,浮點數、整數等)。
動態量化 (Dynamic Quantization)¶
一種量化方法,其中張量在推論期間即時量化。這與 靜態量化 (static quantization) 相反,在靜態量化中,張量在推論之前量化。
動態形狀 (Dynamic shapes)¶
指的是模型在推論期間接受具有不同形狀的輸入的能力。例如,ATen op unique_consecutive 和自定義 op MaskRCNN 具有資料相關的輸出形狀。此類運算子很難進行記憶體規劃,因為即使對於相同的輸入形狀,每次調用也可能產生不同的輸出形狀。為了支援 ExecuTorch 中的動態形狀,核心可以使用客戶端提供的 MemoryAllocator 來分配張量資料。
Eager 模式¶
Python 執行環境,其中模型中的運算子在遇到時立即執行。例如,Jupyter / Colab notebooks 在 eager 模式下運行。這與圖模式 (graph mode) 相反,在圖模式下,運算子首先被合成到一個圖中,然後被編譯和執行。
Edge Dialect¶
具有以下屬性的 EXIR 的一種方言 (dialect)
所有運算子都來自預定義的運算子集合,稱為“Edge Operators”或已註冊的自定義運算子。
圖的輸入和輸出,以及每個節點的輸入和輸出,必須是 Tensor。所有 Scalar 類型都會轉換為 Tensor。
Edge dialect 引入了對 Edge 設備有用的專門化,但不一定適用於一般(伺服器)匯出。但是,Edge dialect 不包含針對特定硬體的專門化,除了原始 Python 程式中已存在的那些專門化。
Edge operator¶
具有 dtype 專門化的 ATen 運算子。
ExecuTorch¶
PyTorch Edge 平台中統一的 ML 軟體堆疊,專為高效的設備上推論而設計。 ExecuTorch 定義了一個工作流程,用於準備(匯出和轉換)並在 Edge 設備(如行動裝置、穿戴式裝置和嵌入式設備)上執行 PyTorch 程式。
ExecuTorch 方法 (ExecuTorch Method)¶
等效於 nn.Module Python 方法的可執行檔案。例如,forward() Python 方法將編譯為 ExecuTorch Method。
ExecuTorch 程式 (ExecuTorch Program)¶
ExecuTorch Program 將字串名稱(如 forward)映射到特定的 ExecuTorch Method 條目。
executor_runner¶
ExecuTorch 運行環境的範例封裝器,其中包括所有運算子和後端。
EXIR¶
來自 torch.export 的 EXport Intermediate Representation (IR)。 包含模型的計算圖。 所有 EXIR 圖都是有效的 FX graphs。
ExportedProgram¶
torch.export 的輸出,它將 PyTorch 模型(通常是 nn.Module)的計算圖與模型使用的參數或權重捆綁在一起。
flatbuffer¶
記憶體高效的跨平台序列化函式庫。 在 ExecuTorch 的上下文中,eager 模式的 Pytorch 模型會匯出到 flatbuffer,這是 ExecuTorch 運行環境使用的格式。
框架稅 (Framework tax)¶
各種載入和初始化任務的成本(非推論)。 例如,載入程式、初始化執行器、核心和後端委派分派以及運行環境記憶體利用率。
函數式 ATen 運算子 (Functional ATen operators)¶
沒有任何副作用的 ATen 運算子。
圖 (Graph)¶
EXIR 圖是以 DAG(有向無環圖)形式表示的 PyTorch 程式。 圖中的每個節點代表特定的計算或操作,並且該圖的邊由節點之間的引用組成。 注意:所有 EXIR 圖都是有效的 FX graphs。
圖模式 (Graph mode)¶
在圖模式中,運算子會先被合成到一個圖中,然後會將這個圖整體編譯並執行。這與立即模式 (eager mode) 相反,在立即模式中,運算子會在遇到時立即執行。圖模式通常能提供更高的效能,因為它允許進行運算子融合 (operator fusion) 等最佳化。
高階運算子 (Higher Order Operators)¶
高階運算子 (HOP) 是一種運算子,它
接受 Python 函式作為輸入、傳回 Python 函式作為輸出,或兩者皆有。
就像所有 PyTorch 運算子一樣,高階運算子也有針對後端和功能的選擇性實作。這讓我們可以為高階運算子註冊自動微分公式 (autograd formula),或定義高階運算子在 ProxyTensor 追蹤下的行為。
混合量化 (Hybrid Quantization)¶
一種量化技術,模型的不同部分會根據計算複雜度和對準確度損失的敏感度,採用不同的量化技術。模型的某些部分可能不會被量化以保留準確度。
中介表示法 (Intermediate Representation, IR)¶
程式在原始語言和目標語言之間的表示法。通常,它是編譯器或虛擬機器內部用於表示原始碼的資料結構。
核心 (Kernel)¶
運算子的實作。針對不同的後端/輸入等,同一個運算子可以有多種實作。
核心註冊表 / 運算子註冊表 (Kernel registry / Operator registry)¶
一個包含核心名稱和其對應實作之間映射的表格。這讓 ExecuTorch 執行期 (runtime) 能夠在執行期間解析對核心的引用。
降低 (Lowering)¶
將模型轉換為在各種後端上執行的過程。之所以稱為「降低 (lowering)」,是因為它使程式碼更接近硬體。在 ExecuTorch 中,降低 (lowering) 作為後端委派 (backend delegation) 的一部分執行。
記憶體規劃 (Memory planning)¶
為模型分配和管理記憶體的過程。在 ExecuTorch 中,記憶體規劃傳遞 (pass) 會在圖形儲存到 flatbuffer 之前執行。這會為每個張量 (tensor) 分配一個記憶體 ID 和在緩衝區中的偏移量 (offset),標記張量的儲存起始位置。
節點 (Node)¶
EXIR 圖中的節點代表特定的計算或運算,並且在 Python 中使用 torch.fx.Node 類別表示。
運算子 (Operator)¶
作用於張量的函數。這是抽象概念;核心 (kernel) 是實作。針對不同的後端/輸入等,同一個運算子可以有多種實作。
運算子融合 (Operator fusion)¶
運算子融合是將多個運算子組合成一個複合運算子的過程,由於減少了核心啟動次數和記憶體讀/寫次數,因此可以加快計算速度。這是圖模式相對於立即模式的效能優勢。
Out 變體 (Out variant)¶
運算子的 out 變體不是在核心實作中分配傳回的張量,而是會接收一個預先分配的張量到其 out kwarg 中,並將結果儲存在該處。
這使得記憶體規劃器更容易執行張量生命週期分析。在 ExecuTorch 中,out 變體傳遞會在記憶體規劃之前執行。
PAL (平台抽象層, Platform Abstraction Layer)¶
提供了一種讓執行環境覆寫操作的方式,例如:
獲取目前時間。
印出日誌陳述 (log statement)。
使程序/系統 panic。如果預設的 PAL 實作不適用於特定的客戶端系統,則可以覆寫它。
部分核心 (Partial kernels)¶
支援張量資料類型和/或維度順序子集的核心。
分割器 (Partitioner)¶
模型的某些部分可能會委派給在最佳化後端上執行。分割器將圖形分割成適當的子網路,並標記它們以進行委派。
ETensor 模式 (ETensor mode)¶
ETensor 模式使用 ExecuTorch 較小的張量實作 (executorch::runtime::etensor::Tensor) 以及相關類型 (executorch::runtime::etensor::ScalarType 等)。這與 ATen 模式相反,ATen 模式使用 ATen 的張量實作 (at::Tensor) 和相關類型 (ScalarType 等)。
executorch::runtime::etensor::Tensor,也稱為 ETensor,是at::Tensor在原始碼上相容的子集。針對 ETensor 編寫的程式碼可以針對at::Tensor進行建置。ETensor 不擁有或分配自己的記憶體。為了支援動態形狀,核心可以使用客戶端提供的 MemoryAllocator 分配張量資料。
可攜式核心 (Portable kernels)¶
可攜式核心是編寫為與 ETensor 相容的運算子實作。由於 ETensor 與 at::Tensor 相容,因此可攜式核心可以針對 at::Tensor 進行建置,並在與 ATen 核心相同的模型中使用。可攜式核心是
與 ATen 運算子簽章相容
以可攜式 C++ 編寫,因此它們可以為任何目標建置
編寫為參考實作,優先考慮清晰度和簡潔性而不是最佳化
通常比 ATen 核心小
編寫為避免使用 new/malloc 動態分配記憶體。
程式 (Program)¶
描述 ML 模型的程式碼和資料集。
程式原始碼 (Program source code)¶
描述程式的 Python 原始碼。它可以是一個 Python 函數,或 PyTorch 立即模式 nn.Module 中的一個方法。
PTQ (訓練後量化, Post Training Quantization)¶
一種量化技術,其中模型在訓練完成後進行量化(通常是為了提高效能)。PTQ 在訓練後應用量化流程,而 QAT 則在訓練期間應用量化流程。
QAT (量化感知訓練, Quantization Aware Training)¶
模型在量化後可能會降低準確度。相較於例如 PTQ,QAT 透過在訓練時模擬量化的影響,可以實現更高的準確度。在訓練期間,所有權重和激活值都會被「假量化」;浮點數值會被捨入以模擬 int8 值,但所有計算仍然使用浮點數執行。因此,訓練期間的所有權重調整都會「意識到」模型最終將被量化。QAT 在訓練期間應用量化流程,這與 PTQ 在訓練後才應用量化流程形成對比。
