


注意
前往結尾下載完整的範例程式碼
匯出至 ExecuTorch 教學¶
作者: Angela Yi
ExecuTorch 是一個統一的機器學習堆疊,用於將 PyTorch 模型降低到邊緣設備。它引入了改進的進入點,以執行模型、設備和/或特定於使用案例的優化,例如後端委派、使用者定義的編譯器轉換、預設或使用者定義的記憶體規劃等。
概括來說,工作流程如下:
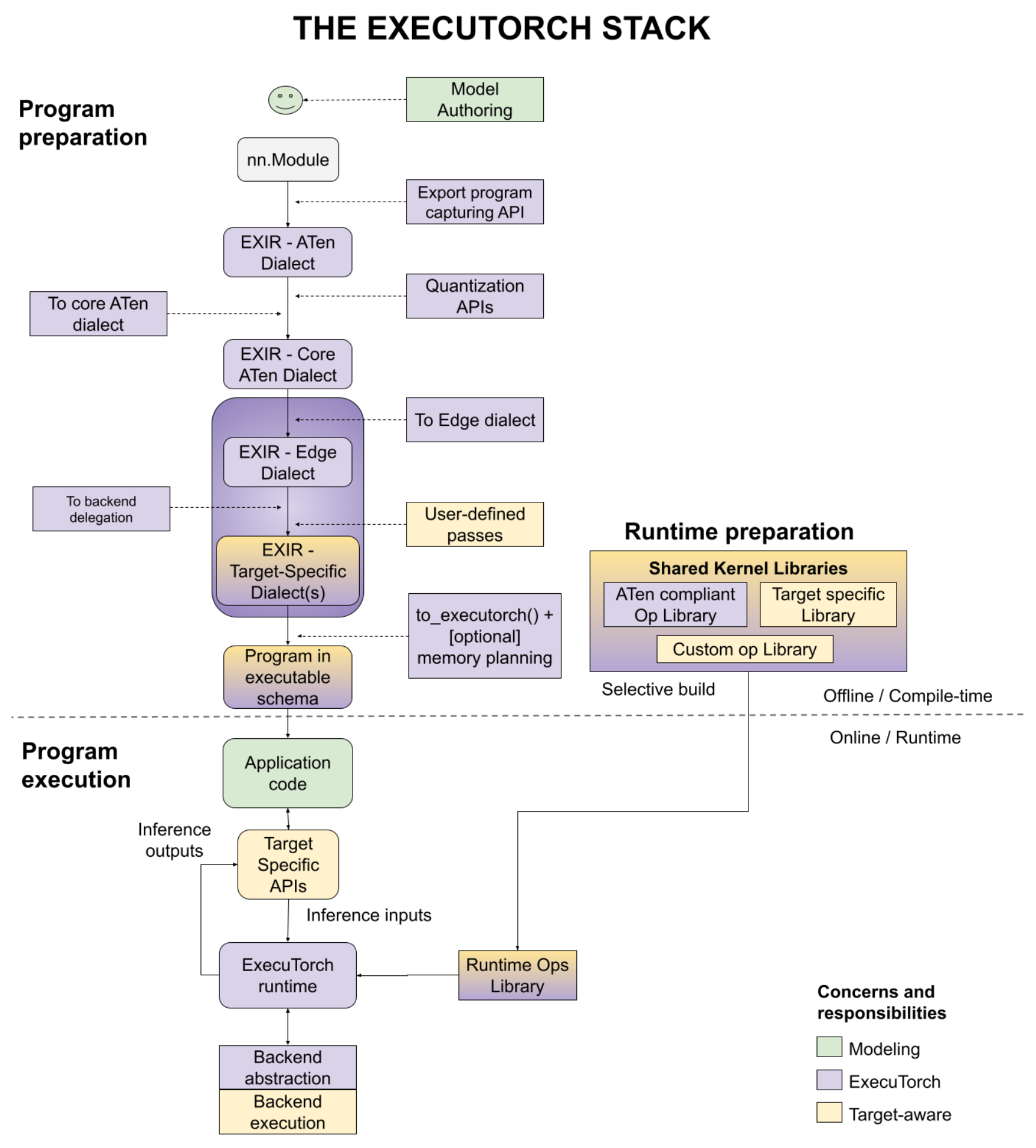
在本教學中,我們將涵蓋「程式準備」步驟中的 API,以將 PyTorch 模型降低為可以載入到設備並在 ExecuTorch 執行階段執行的格式。
先決條件¶
若要執行本教學,您首先需要設定您的 ExecuTorch 環境。
匯出模型¶
注意:匯出 API 仍在變更中,以便更好地與長期匯出狀態保持一致。請參考此issue以取得更多詳細資訊。
降低到 ExecuTorch 的第一步是將給定的模型 (任何可呼叫的物件或 torch.nn.Module) 匯出到圖形表示。這透過 torch.export 來完成,它接受 torch.nn.Module、位置引數的元組,以及可選的關鍵字引數字典 (範例中未顯示) 和動態形狀的清單 (稍後介紹)。
import torch
from torch.export import export, ExportedProgram
class SimpleConv(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = torch.nn.Conv2d(
in_channels=3, out_channels=16, kernel_size=3, padding=1
)
self.relu = torch.nn.ReLU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
a = self.conv(x)
return self.relu(a)
example_args = (torch.randn(1, 3, 256, 256),)
aten_dialect: ExportedProgram = export(SimpleConv(), example_args)
print(aten_dialect)
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
conv2d: "f32[1, 16, 256, 256]" = torch.ops.aten.conv2d.default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1]); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(conv2d); conv2d = None
return (relu,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='relu'), target=None)])
Range constraints: {}
torch.export.export 的輸出是一個完全扁平化的圖形 (表示圖形不包含任何模組層次結構,除了控制流程運算子的情況)。此外,該圖形是純函數式的,表示它不包含具有副作用的運算,例如變異或別名。
有關 torch.export 結果的更多規格,請參閱此處。
torch.export 傳回的圖形僅包含函數式 ATen 運算子 (~2000 個運算),我們將其稱為 ATen Dialect。
表達動態性¶
預設情況下,匯出流程會追蹤程式,假設所有輸入形狀都是靜態的,因此如果我們使用與追蹤時不同的輸入形狀來執行程式,則會發生錯誤
import traceback as tb
class Basic(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
return x + y
example_args = (torch.randn(3, 3), torch.randn(3, 3))
aten_dialect: ExportedProgram = export(Basic(), example_args)
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
# Errors
try:
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 111, in <module>
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 745, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 360, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be equal to 3, but got 2
- 若要表示某些輸入形狀是動態的,我們可以插入動態
形狀到匯出流程。這是透過
DimAPI 完成的
from torch.export import Dim
class Basic(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
return x + y
example_args = (torch.randn(3, 3), torch.randn(3, 3))
dim1_x = Dim("dim1_x", min=1, max=10)
dynamic_shapes = {"x": {1: dim1_x}, "y": {1: dim1_x}}
aten_dialect: ExportedProgram = export(
Basic(), example_args, dynamic_shapes=dynamic_shapes
)
print(aten_dialect)
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[3, s0]", y: "f32[3, s0]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:127 in forward, code: return x + y
add: "f32[3, s0]" = torch.ops.aten.add.Tensor(x, y); x = y = None
return (add,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='y'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='add'), target=None)])
Range constraints: {s0: VR[1, 10]}
請注意,輸入 arg0_1 和 arg1_1 現在具有形狀 (3, s0),其中 s0 是一個符號,表示此維度可以是一系列的值。
此外,我們可以在範圍約束中看到 s0 的值具有 [1, 10] 的範圍,這是由我們的動態形狀指定的。
現在讓我們嘗試使用不同的形狀執行模型
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
# Errors because it violates our constraint that input 0, dim 1 <= 10
try:
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
except Exception:
tb.print_exc()
# Errors because it violates our constraint that input 0, dim 1 == input 1, dim 1
try:
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
tensor([[2., 2.],
[2., 2.],
[2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 154, in <module>
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 745, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 347, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be <= 10, but got 15
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 160, in <module>
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 745, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 302, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[1].shape[1] to be equal to 3, but got 2
解決無法追蹤的程式碼¶
由於我們的目標是從 PyTorch 程式捕獲整個計算圖,我們最終可能會遇到無法追蹤的程式部分。要解決這些問題,torch.export 文件或 torch.export 教學將是最佳去處。
執行量化¶
若要量化模型,我們首先需要使用 torch.export.export_for_training 捕獲圖形,執行量化,然後呼叫 torch.export。torch.export.export_for_training 傳回一個包含 ATen 運算子的圖形,這些運算子對於 Autograd 是安全的,表示它們對於 eager-mode 訓練是安全的,這是量化所需要的。我們將在此層級的圖形稱為 Pre-Autograd ATen Dialect 圖形。
與 FX Graph Mode Quantization 相比,我們需要呼叫兩個新的 API:prepare_pt2e 和 convert_pt2e,而不是 prepare_fx 和 convert_fx。不同之處在於 prepare_pt2e 採用特定於後端的 Quantizer 作為引數,它將使用量化模型所需的資訊來註釋圖形中的節點,以便為特定後端正確量化模型。
from torch.export import export_for_training
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = export_for_training(SimpleConv(), example_args).module()
print("Pre-Autograd ATen Dialect Graph")
print(pre_autograd_aten_dialect)
from torch.ao.quantization.quantize_pt2e import convert_pt2e, prepare_pt2e
from torch.ao.quantization.quantizer.xnnpack_quantizer import (
get_symmetric_quantization_config,
XNNPACKQuantizer,
)
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
prepared_graph = prepare_pt2e(pre_autograd_aten_dialect, quantizer)
# calibrate with a sample dataset
converted_graph = convert_pt2e(prepared_graph)
print("Quantized Graph")
print(converted_graph)
aten_dialect: ExportedProgram = export(converted_graph, example_args)
print("ATen Dialect Graph")
print(aten_dialect)
Pre-Autograd ATen Dialect Graph
GraphModule(
(conv): Module()
)
def forward(self, x):
x, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
conv_weight = self.conv.weight
conv_bias = self.conv.bias
conv2d = torch.ops.aten.conv2d.default(x, conv_weight, conv_bias, [1, 1], [1, 1]); x = conv_weight = conv_bias = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
return pytree.tree_unflatten((relu,), self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/utils.py:408: UserWarning: must run observer before calling calculate_qparams. Returning default values.
warnings.warn(
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/observer.py:1318: UserWarning: must run observer before calling calculate_qparams. Returning default scale and zero point
warnings.warn(
Quantized Graph
GraphModule(
(conv): Module()
)
def forward(self, x):
x, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
_frozen_param0 = self._frozen_param0
dequantize_per_tensor_default = torch.ops.quantized_decomposed.dequantize_per_tensor.default(_frozen_param0, 1.0, 0, -127, 127, torch.int8); _frozen_param0 = None
conv_bias = self.conv.bias
quantize_per_tensor_default_1 = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
dequantize_per_tensor_default_1 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_1, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_1 = None
conv2d = torch.ops.aten.conv2d.default(dequantize_per_tensor_default_1, dequantize_per_tensor_default, conv_bias, [1, 1], [1, 1]); dequantize_per_tensor_default_1 = dequantize_per_tensor_default = conv_bias = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
quantize_per_tensor_default_2 = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
return pytree.tree_unflatten((dequantize_per_tensor_default_2,), self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_bias: "f32[16]", b__frozen_param0: "i8[16, 3, 3, 3]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
dequantize_per_tensor: "f32[16, 3, 3, 3]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(b__frozen_param0, 1.0, 0, -127, 127, torch.int8); b__frozen_param0 = None
# File: <eval_with_key>.203:9 in forward, code: quantize_per_tensor_default_1 = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
quantize_per_tensor: "i8[1, 3, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
dequantize_per_tensor_1: "f32[1, 3, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor = None
conv2d: "f32[1, 16, 256, 256]" = torch.ops.aten.conv2d.default(dequantize_per_tensor_1, dequantize_per_tensor, p_conv_bias, [1, 1], [1, 1]); dequantize_per_tensor_1 = dequantize_per_tensor = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(conv2d); conv2d = None
quantize_per_tensor_1: "i8[1, 16, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
# File: <eval_with_key>.203:14 in forward, code: dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
dequantize_per_tensor_2: "f32[1, 16, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_1, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_1 = None
return (dequantize_per_tensor_2,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='b__frozen_param0'), target='_frozen_param0', persistent=True), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='dequantize_per_tensor_2'), target=None)])
Range constraints: {}
有關如何量化模型以及後端如何實作 Quantizer 的更多資訊,請參閱此處。
降低到 Edge Dialect¶
在將圖形匯出並降低到 ATen Dialect 之後,下一步是降低到 Edge Dialect,在其中將應用於邊緣設備有用但對於一般 (伺服器) 環境不必要的特殊化。這些特殊化包括
DType 特殊化
純量到張量的轉換
將所有運算轉換為
executorch.exir.dialects.edge命名空間。
請注意,此 dialect 仍然與後端 (或目標) 無關。
降低是透過 to_edge API 完成的。
from executorch.exir import EdgeProgramManager, to_edge
example_args = (torch.randn(1, 3, 256, 256),)
aten_dialect: ExportedProgram = export(SimpleConv(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
to_edge() 傳回一個 EdgeProgramManager 物件,其中包含將放置在此設備上的已匯出程式。此資料結構允許使用者匯出多個程式並將它們組合到一個二進位檔案中。如果只有一個程式,預設情況下它將儲存到名稱 "forward"。
class Encode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(5, 10))
class Decode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(10, 5))
encode_args = (torch.randn(1, 10),)
aten_encode: ExportedProgram = export(Encode(), encode_args)
decode_args = (torch.randn(1, 5),)
aten_decode: ExportedProgram = export(Decode(), decode_args)
edge_program: EdgeProgramManager = to_edge(
{"encode": aten_encode, "decode": aten_decode}
)
for method in edge_program.methods:
print(f"Edge Dialect graph of {method}")
print(edge_program.exported_program(method))
Edge Dialect graph of encode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1, 10]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:261 in forward, code: return torch.nn.functional.linear(x, torch.randn(5, 10))
aten_randn_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_randn_default([5, 10], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 5]" = executorch_exir_dialects_edge__ops_aten_mm_default(x, aten_permute_copy_default); x = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
Edge Dialect graph of decode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1, 5]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:266 in forward, code: return torch.nn.functional.linear(x, torch.randn(10, 5))
aten_randn_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_randn_default([10, 5], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 10]" = executorch_exir_dialects_edge__ops_aten_mm_default(x, aten_permute_copy_default); x = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
我們也可以透過 transform API 在已匯出的程式上執行額外的 pass。有關如何編寫轉換的深入文件,請參閱此處。
請注意,由於圖形現在位於 Edge Dialect 中,因此所有 pass 也必須產生有效的 Edge Dialect 圖形 (特別要注意的是,運算子現在位於 executorch.exir.dialects.edge 命名空間中,而不是 torch.ops.aten 命名空間中。
example_args = (torch.randn(1, 3, 256, 256),)
aten_dialect: ExportedProgram = export(SimpleConv(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
from executorch.exir.dialects._ops import ops as exir_ops
from executorch.exir.pass_base import ExportPass
class ConvertReluToSigmoid(ExportPass):
def call_operator(self, op, args, kwargs, meta):
if op == exir_ops.edge.aten.relu.default:
return super().call_operator(
exir_ops.edge.aten.sigmoid.default, args, kwargs, meta
)
else:
return super().call_operator(op, args, kwargs, meta)
transformed_edge_program = edge_program.transform((ConvertReluToSigmoid(),))
print("Transformed Edge Dialect Graph")
print(transformed_edge_program.exported_program())
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
Transformed Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_sigmoid_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_sigmoid_default(aten_convolution_default); aten_convolution_default = None
return (aten_sigmoid_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sigmoid_default'), target=None)])
Range constraints: {}
注意:如果您看到類似 torch._export.verifier.SpecViolationError: Operator torch._ops.aten._native_batch_norm_legit_functional.default is not Aten Canonical 的錯誤,請在 https://github.com/pytorch/executorch/issues 上提交 issue,我們很樂意提供協助!
委派給後端¶
現在,我們可以透過 to_backend API 將圖的一部分或整個圖委派給第三方後端。有關後端委派的詳細文件,包括如何委派給後端以及如何實作後端,請參閱此處。
使用此 API 有三種方法
我們可以降低整個模組。
我們可以取得降低後的模組,並將其插入到另一個更大的模組中。
我們可以將模組分割成可降低的子圖,然後將這些子圖降低到後端。
降低整個模組¶
若要降低整個模組,我們可以將後端名稱、要降低的模組以及編譯規格列表傳遞給 to_backend,以協助後端進行降低過程。
class LowerableModule(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.sin(x)
# Export and lower the module to Edge Dialect
example_args = (torch.ones(1),)
aten_dialect: ExportedProgram = export(LowerableModule(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
to_be_lowered_module = edge_program.exported_program()
from executorch.exir.backend.backend_api import LoweredBackendModule, to_backend
# Import the backend
from executorch.exir.backend.test.backend_with_compiler_demo import ( # noqa
BackendWithCompilerDemo,
)
# Lower the module
lowered_module: LoweredBackendModule = to_backend(
"BackendWithCompilerDemo", to_be_lowered_module, []
)
print(lowered_module)
print(lowered_module.backend_id)
print(lowered_module.processed_bytes)
print(lowered_module.original_module)
# Serialize and save it to a file
save_path = "delegate.pte"
with open(save_path, "wb") as f:
f.write(lowered_module.buffer())
LoweredBackendModule()
BackendWithCompilerDemo
b'1version:0#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>2#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:355 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(x); x = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
在這次呼叫中,to_backend 將傳回一個 LoweredBackendModule。 LoweredBackendModule 的一些重要屬性包括
backend_id:此降低後的模組在運行時所運行的後端名稱processed_bytes:一個二進位 blob,它將告訴後端如何在運行時運行此程式original_module:原始匯出的模組
將降低後的模組組成到另一個模組中¶
在我們想要在多個程式中重複使用此降低後的模組的情況下,我們可以將此降低後的模組與另一個模組組成。
class NotLowerableModule(torch.nn.Module):
def __init__(self, bias):
super().__init__()
self.bias = bias
def forward(self, a, b):
return torch.add(torch.add(a, b), self.bias)
class ComposedModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.non_lowerable = NotLowerableModule(torch.ones(1) * 0.3)
self.lowerable = lowered_module
def forward(self, x):
a = self.lowerable(x)
b = self.lowerable(a)
ret = self.non_lowerable(a, b)
return a, b, ret
example_args = (torch.ones(1),)
aten_dialect: ExportedProgram = export(ComposedModule(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
print("Lowered Module within the graph")
print(exported_program.graph_module.lowered_module_0.backend_id)
print(exported_program.graph_module.lowered_module_0.processed_bytes)
print(exported_program.graph_module.lowered_module_0.original_module)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py:75: UserWarning: Attempted to insert a get_attr Node with no underlying reference in the owning GraphModule! Call GraphModule.add_submodule to add the necessary submodule, GraphModule.add_parameter to add the necessary Parameter, or nn.Module.register_buffer to add the necessary buffer
getattr_node = gm.graph.get_attr(lifted_node)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph.py:1801: UserWarning: Node non_lowerable_bias target non_lowerable.bias bias of non_lowerable does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, c_non_lowerable_bias: "f32[1]", x: "f32[1]"):
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:344 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_0 = self.lowered_module_0
executorch_call_delegate: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, x); lowered_module_0 = x = None
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:344 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_1 = self.lowered_module_0
executorch_call_delegate_1: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, executorch_call_delegate); lowered_module_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:409 in forward, code: return torch.add(torch.add(a, b), self.bias)
aten_add_tensor: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(executorch_call_delegate, executorch_call_delegate_1)
aten_add_tensor_1: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_add_tensor, c_non_lowerable_bias); aten_add_tensor = c_non_lowerable_bias = None
return (executorch_call_delegate, executorch_call_delegate_1, aten_add_tensor_1)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.CONSTANT_TENSOR: 4>, arg=TensorArgument(name='c_non_lowerable_bias'), target='non_lowerable.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate_1'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Lowered Module within the graph
BackendWithCompilerDemo
b'1version:0#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>2#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:355 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(x); x = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
請注意,圖中現在有一個 torch.ops.higher_order.executorch_call_delegate 節點,它正在呼叫 lowered_module_0。此外,lowered_module_0 的內容與我們先前建立的 lowered_module 相同。
分割和降低模組的部分¶
另一個降低流程是將我們要降低的模組和後端特定的分割器傳遞給 to_backend。to_backend 將使用後端特定的分割器來標記模組中可降低的節點,將這些節點分割成子圖,然後為每個子圖建立一個 LoweredBackendModule。
class Foo(torch.nn.Module):
def forward(self, a, x, b):
y = torch.mm(a, x)
z = y + b
a = z - a
y = torch.mm(a, x)
z = y + b
return z
example_args = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
aten_dialect: ExportedProgram = export(Foo(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
from executorch.exir.backend.test.op_partitioner_demo import AddMulPartitionerDemo
delegated_program = to_backend(exported_program, AddMulPartitionerDemo())
print("Delegated program")
print(delegated_program)
print(delegated_program.graph_module.lowered_module_0.original_module)
print(delegated_program.graph_module.lowered_module_1.original_module)
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:455 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(a, x)
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:456 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, b); aten_mm_default = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:457 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(aten_add_tensor, a); aten_add_tensor = a = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:458 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, x); aten_sub_tensor = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:459 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, b); aten_mm_default_1 = b = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, a, x, b); lowered_module_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:457 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem_1, a); getitem_1 = a = None
# No stacktrace found for following nodes
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, aten_sub_tensor, x, b); lowered_module_0 = aten_sub_tensor = x = b = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
return (getitem,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, aten_sub_tensor: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:458 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, x); aten_sub_tensor = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:459 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, b); aten_mm_default_1 = b = None
return [aten_add_tensor_1]
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='aten_sub_tensor'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:455 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(a, x); a = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:456 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, b); aten_mm_default = b = None
return [aten_add_tensor]
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor'), target=None)])
Range constraints: {}
請注意,圖中現在有 2 個 torch.ops.higher_order.executorch_call_delegate 節點,一個包含 add, mul 運算,另一個包含 mul, add 運算。
或者,更具凝聚力的 API 可以透過直接呼叫 to_backend 來降低模組的部分
class Foo(torch.nn.Module):
def forward(self, a, x, b):
y = torch.mm(a, x)
z = y + b
a = z - a
y = torch.mm(a, x)
z = y + b
return z
example_args = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
aten_dialect: ExportedProgram = export(Foo(), example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
delegated_program = edge_program.to_backend(AddMulPartitionerDemo())
print("Delegated program")
print(delegated_program.exported_program())
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, a, x, b); lowered_module_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:491 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem_1, a); getitem_1 = a = None
# No stacktrace found for following nodes
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, aten_sub_tensor, x, b); lowered_module_0 = aten_sub_tensor = x = b = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
return (getitem,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem'), target=None)])
Range constraints: {}
運行使用者定義的 Passes 和記憶體規劃¶
作為降低的最後一個步驟,我們可以使用 to_executorch() API 傳入後端特定的 passes,例如用自訂後端運算子取代一組運算子,以及記憶體規劃 pass,以告訴運行時如何在運行程式之前預先分配記憶體。
提供了一個預設的記憶體規劃 pass,但如果存在後端特定的記憶體規劃 pass,我們也可以選擇它。有關編寫自訂記憶體規劃 pass 的更多資訊,請參閱此處
from executorch.exir import ExecutorchBackendConfig, ExecutorchProgramManager
from executorch.exir.passes import MemoryPlanningPass
executorch_program: ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
memory_planning_pass=MemoryPlanningPass(), # Default memory planning pass
)
)
print("ExecuTorch Dialect")
print(executorch_program.exported_program())
import executorch.exir as exir
ExecuTorch Dialect
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
alloc: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:489 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = torch.ops.aten.mm.out(a, x, out = alloc); alloc = None
# No stacktrace found for following nodes
alloc_1: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:490 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default, b, out = alloc_1); aten_mm_default = alloc_1 = None
# No stacktrace found for following nodes
alloc_2: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:491 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = torch.ops.aten.sub.out(aten_add_tensor, a, out = alloc_2); aten_add_tensor = a = alloc_2 = None
# No stacktrace found for following nodes
alloc_3: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:492 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = torch.ops.aten.mm.out(aten_sub_tensor, x, out = alloc_3); aten_sub_tensor = x = alloc_3 = None
# No stacktrace found for following nodes
alloc_4: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:493 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default_1, b, out = alloc_4); aten_mm_default_1 = b = alloc_4 = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
請注意,在圖中,我們現在看到諸如 torch.ops.aten.sub.out 和 torch.ops.aten.div.out 之類的運算子,而不是 torch.ops.aten.sub.Tensor 和 torch.ops.aten.div.Tensor。
這是因為在運行後端 passes 和記憶體規劃 passes 之間,為了準備圖進行記憶體規劃,在圖上運行了一個 out-variant pass,以將所有運算子轉換為它們的 out variants。運算子的 out variant 將採用一個預先分配的張量到其 out kwarg 中,並將結果儲存在那裡,而不是在核心實作中分配傳回的張量,這使得記憶體規劃器更容易進行張量生命週期分析。
我們還將 alloc 節點插入到圖中,其中包含對特殊的 executorch.exir.memory.alloc 運算子的呼叫。這告訴我們分配 out-variant 運算子輸出的每個張量需要多少記憶體。
儲存到檔案¶
最後,我們可以將 ExecuTorch 程式儲存到檔案,並將其載入到裝置上運行。
以下是一個完整的端到端工作流程的範例
import torch
from torch.export import export, export_for_training, ExportedProgram
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
example_args = (torch.randn(3, 4),)
pre_autograd_aten_dialect = export_for_training(M(), example_args).module()
# Optionally do quantization:
# pre_autograd_aten_dialect = convert_pt2e(prepare_pt2e(pre_autograd_aten_dialect, CustomBackendQuantizer))
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: exir.EdgeProgramManager = exir.to_edge(aten_dialect)
# Optionally do delegation:
# edge_program = edge_program.to_backend(CustomBackendPartitioner)
executorch_program: exir.ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
)
)
with open("model.pte", "wb") as file:
file.write(executorch_program.buffer)
