核心註冊¶
概述¶
在 ExecuTorch 模型匯出的最後階段,我們會將方言 (dialect) 中的運算符降級為 核心 ATen 運算符的out 變體。然後,我們會將這些運算符名稱序列化到模型物件中。在執行階段執行時,對於每個運算符名稱,我們都需要找到實際的核心,也就是執行繁重計算並傳回結果的 C++ 函式。
核心函式庫¶
第一方核心函式庫:¶
可移植核心函式庫是內部預設核心函式庫,涵蓋了大多數核心 ATen 運算符。它易於使用/閱讀,並且以可移植的 C++17 編寫。然而,它並未針對效能進行優化,因為它並未針對任何特定目標進行專業化。因此,我們為 ExecuTorch 使用者提供核心註冊 API,以便輕鬆註冊他們自己的最佳化核心。
最佳化核心函式庫專注於某些運算符的效能,利用現有的第三方函式庫,例如 EigenBLAS。這與可移植核心函式庫搭配使用效果最佳,可在可移植性和效能之間取得良好的平衡。可以在此處找到結合這兩個函式庫的範例。
量化核心函式庫實作了量化和反量化的運算符。這些是核心 ATen 運算符之外的運算符,但對於大多數生產用例至關重要。
自訂核心函式庫:¶
實作核心 ATen 運算符的自訂核心。即使我們沒有核心 ATen 運算符的自訂核心的內部範例,也可以將最佳化核心函式庫視為一個很好的範例。我們最佳化了 add.out 和可移植的 add.out。當使用者結合這兩個函式庫時,我們提供 API 來選擇要用於 add.out 的核心。為了編寫和使用實作核心 ATen 運算符的自訂核心,建議使用 基於 YAML 的方法,因為它提供了對以下項目的全面支援:
結合核心函式庫並定義後備核心;
使用選擇性建置來最小化核心大小。
自訂運算符是 ExecuTorch 使用者在 PyTorch 的 native_functions.yaml 之外定義的任何運算符。
運算符 & 核心合約¶
上述所有核心,無論是內部還是客製化的,都應符合以下要求
符合從運算符架構衍生的呼叫慣例。核心註冊 API 將為自訂核心產生標頭作為參考。
滿足邊緣方言中定義的 dtype 約束。對於具有特定 dtype 作為參數的張量,自訂核心的結果需要符合預期的 dtype。約束在邊緣方言運算符中可用。
給出正確的結果。我們將提供一個測試框架來自動測試自訂核心。
API¶
這些是可用於將核心/自訂核心/自訂運算符註冊到 ExecuTorch 的 API
如果不清楚該使用哪個 API,請參閱最佳實踐。
YAML 條目 API 高階架構¶
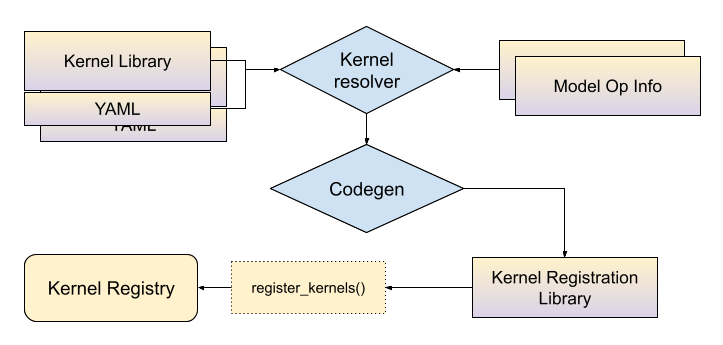
要求 ExecuTorch 使用者提供
具有 C++ 實作的自訂核心函式庫
與函式庫關聯的 YAML 檔案,描述此函式庫實作的運算符。對於部分核心,yaml 檔案還包含有關核心支援的 dtype 和 dim 順序的資訊。更多詳細資訊請參閱 API 區段。
YAML 條目 API 工作流程¶
在建置時,與核心函式庫關聯的 yaml 檔案將與模型運算符資訊(請參閱選擇性建置文件)一起傳遞到核心解析器,結果是運算符名稱和張量元資料的組合與核心符號之間的對應。然後,程式碼產生工具將使用此對應來產生 C++ 繫結,將核心連接到 ExecuTorch 執行階段。ExecuTorch 使用者需要將此產生的函式庫連結到他們的應用程式才能使用這些核心。
在靜態物件初始化時,核心將註冊到 ExecuTorch 核心註冊表中。
在執行階段初始化階段,ExecuTorch 將使用運算符名稱和引數元資料作為鍵來查找核心。例如,對於 "aten::add.out" 和輸入是 dim 順序為 (0, 1, 2, 3) 的浮點張量,ExecuTorch 將進入核心註冊表並查找符合名稱和輸入元資料的核心。
核心 ATen 運算符 Out 變體的 YAML 條目 API¶
頂層屬性
op(如果運算符出現在native_functions.yaml中)或func用於自訂運算符。此鍵的值需要是op鍵的完整運算符名稱(包括過載名稱),或者是完整的運算符架構(命名空間、運算符名稱、運算符過載名稱和架構字串),如果我們描述的是自訂運算符。有關架構語法,請參閱此說明。kernels:定義核心資訊。它由arg_meta和kernel_name組成,它們綁定在一起以描述“對於具有這些元資料的輸入張量,使用此核心”。type_alias(可選): 我們為可能的 dtype 選項提供別名。T0: [Double, Float]表示T0可以是Double或Float其中之一。dim_order_alias(可選): 類似於type_alias,我們為可能的 dim order 選項提供名稱。
kernels 下的屬性
arg_meta: “tensor arg name” 條目的列表。這些鍵的值是 dtype 和 dim order 別名,由相應的kernel_name實作。如果此值為null,則表示該核心將用於所有輸入類型。kernel_name: 將實作此運算子的 C++ 函數的預期名稱。 您可以在此處放置任何您想要的內容,但應遵循將重載名稱中的.替換為底線,並將所有字元轉換為小寫的慣例。 在此範例中,add.out使用名為add_out的 C++ 函數。add.Scalar_out將變成add_scalar_out,其中S為小寫。 我們支援核心的命名空間,但請注意,我們將插入一個native::到最後一級的命名空間。 因此kernel_name中的custom::add_out將指向custom::native::add_out。
運算子條目的一些範例
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::add_out
具有預設核心的 ATen 核心運算子的 out 變體
具有 dtype/dim order 專用核心的 ATen 運算子 (適用於 Double dtype 且 dim order 需要為 (0, 1, 2, 3))
- op: add.out
type_alias:
T0: [Double]
dim_order_alias:
D0: [[0, 1, 2, 3]]
kernels:
- arg_meta:
self: [T0, D0]
other: [T0 , D0]
out: [T0, D0]
kernel_name: torch::executor::add_out
自訂運算元的 YAML 條目 API¶
如上所述,此選項在選擇性建置和合併運算子程式庫等功能方面提供更多支援。
首先,我們需要指定運算子結構描述以及 kernel 區段。 因此,我們使用具有運算子結構描述的 func 而不是 op。 例如,以下是自訂運算元的 yaml 條目
- func: allclose.out(Tensor self, Tensor other, float rtol=1e-05, float atol=1e-08, bool equal_nan=False, bool dummy_param=False, *, Tensor(a!) out) -> Tensor(a!)
kernels:
- arg_meta: null
kernel_name: torch::executor::allclose_out
kernel 區段與核心 ATen 運算元中定義的區段相同。 對於運算子結構描述,我們重複使用此 README.md 中定義的 DSL,但有一些差異
僅限 Out 變體¶
ExecuTorch 僅支援 out 樣式的運算子,其中
呼叫端在最後一個位置以名稱
out提供輸出 Tensor 或 Tensor 列表。C++ 函數修改並傳回相同的
out引數。如果 YAML 檔案中的傳回類型為
()(對應到 void),則 C++ 函數仍應修改out但不需要傳回任何內容。
out引數必須僅限關鍵字,這表示它需要跟在名為*的引數之後,如下面的add.out範例所示。按照慣例,這些 out 運算子使用模式
<name>.out或<name>.<overload>_out命名。
由於所有輸出值都透過 out 參數傳回,因此 ExecuTorch 會忽略實際的 C++ 函數傳回值。 但是,為了保持一致性,當傳回類型為非 void 時,函數應始終傳回 out。
只能傳回 Tensor 或 ()¶
ExecuTorch 僅支援傳回單個 Tensor 或單位類型 () (對應到 void) 的運算子。 它不支援傳回任何其他類型,包括列表、選項、元組或標量 (如 bool)。
支援的引數類型¶
ExecuTorch 不支援核心 PyTorch 支援的所有引數類型。 以下是我們目前支援的引數類型列表
Tensor
int
bool
float
str
Scalar
ScalarType
MemoryFormat
Device
Optional
List
List<Optional
> Optional<List
>
CMake 巨集¶
我們提供建置時巨集來協助使用者建置其核心註冊程式庫。 該巨集採用描述核心程式庫和模型運算子中繼資料的 yaml 檔案,並將產生的 C++ 繫結封裝到 C++ 程式庫中。 該巨集可在 CMake 上使用。
generate_bindings_for_kernels(FUNCTIONS_YAML functions_yaml CUSTOM_OPS_YAML custom_ops_yaml) 採用核心 ATen 運算元 out 變體的 yaml 檔案以及自訂運算元的 yaml 檔案,產生 C++ 繫結以進行核心註冊。 它也取決於由 gen_selected_ops() 產生的選擇性建置成品,有關更多資訊,請參閱選擇性建置文件。 然後 gen_operators_lib 將這些繫結封裝為 C++ 程式庫。 例如
# SELECT_OPS_LIST: aten::add.out,aten::mm.out
gen_selected_ops("" "${SELECT_OPS_LIST}" "")
# Look for functions.yaml associated with portable libs and generate C++ bindings
generate_bindings_for_kernels(FUNCTIONS_YAML ${EXECUTORCH_ROOT}/kernels/portable/functions.yaml)
# Prepare a C++ library called "generated_lib" with _kernel_lib being the portable library, executorch is a dependency of it.
gen_operators_lib("generated_lib" KERNEL_LIBS ${_kernel_lib} DEPS executorch)
# Link "generated_lib" into the application:
target_link_libraries(executorch_binary generated_lib)
我們還提供合併兩個 yaml 檔案的能力,並給定優先順序。 merge_yaml(FUNCTIONS_YAML functions_yaml FALLBACK_YAML fallback_yaml OUTPUT_DIR out_dir) 將 functions_yaml 和 fallback_yaml 合併到單個 yaml 中,如果 functions_yaml 和 fallback_yaml 中有重複的條目,則此巨集將始終採用 functions_yaml 中的條目。
範例
# functions.yaml
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::opt_add_out
Out 回退
# fallback.yaml
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::add_out
合併後的 yaml 將具有 functions.yaml 中的條目。
自訂運算元的 C++ API¶
與 YAML entry API 不同,C++ API 僅使用 C++ 巨集 EXECUTORCH_LIBRARY 和 WRAP_TO_ATEN 進行核心註冊,且不支援選擇性建置。這使得此 API 在開發速度方面更快,因為使用者不必進行 YAML 編寫和調整建置系統。
請參考自定義運算子 API 最佳實踐,以了解應使用哪個 API。
類似於 PyTorch 中的 TORCH_LIBRARY,EXECUTORCH_LIBRARY 採用運算子名稱和 C++ 函數名稱,並將它們註冊到 ExecuTorch 執行期。
準備自定義核心實作¶
為函數變體(用於 AOT 編譯)和 out 變體(用於 ExecuTorch 執行期)定義您的自定義運算子模式。該模式需要遵循 PyTorch ATen 慣例(請參閱 native_functions.yaml)。例如:
custom_linear(Tensor weight, Tensor input, Tensor(?) bias) -> Tensor
custom_linear.out(Tensor weight, Tensor input, Tensor(?) bias, *, Tensor(a!) out) -> Tensor(a!)
然後,使用 ExecuTorch 類型,並使用 API 註冊到 ExecuTorch 執行期,根據模式編寫您的自定義核心。
// custom_linear.h/custom_linear.cpp
#include <executorch/runtime/kernel/kernel_includes.h>
Tensor& custom_linear_out(const Tensor& weight, const Tensor& input, optional<Tensor> bias, Tensor& out) {
// calculation
return out;
}
使用 C++ 巨集將其註冊到 ExecuTorch¶
在上面的範例中附加以下行:
// custom_linear.h/custom_linear.cpp
// opset namespace myop
EXECUTORCH_LIBRARY(myop, "custom_linear.out", custom_linear_out);
現在,我們需要為此運算編寫一些包裝器,以便在 PyTorch 中顯示,但不用擔心,我們不需要重寫核心。為此目的建立一個單獨的 .cpp 檔案。
// custom_linear_pytorch.cpp
#include "custom_linear.h"
#include <torch/library.h>
at::Tensor custom_linear(const at::Tensor& weight, const at::Tensor& input, std::optional<at::Tensor> bias) {
// initialize out
at::Tensor out = at::empty({weight.size(1), input.size(1)});
// wrap kernel in custom_linear.cpp into ATen kernel
WRAP_TO_ATEN(custom_linear_out, 3)(weight, input, bias, out);
return out;
}
// standard API to register ops into PyTorch
TORCH_LIBRARY(myop, m) {
m.def("custom_linear(Tensor weight, Tensor input, Tensor(?) bias) -> Tensor", custom_linear);
m.def("custom_linear.out(Tensor weight, Tensor input, Tensor(?) bias, *, Tensor(a!) out) -> Tensor(a!)", WRAP_TO_ATEN(custom_linear_out, 3));
}
編譯並鏈接自定義核心¶
將其鏈接到 ExecuTorch 執行期:在建置二進位檔/應用程式的 CMakeLists.txt 中,我們需要將 custom_linear.h/cpp 新增到二進位目標中。 我們也可以建置一個動態載入的函式庫(.so 或 .dylib)並將其鏈接。
以下是一個範例:
# For target_link_options_shared_lib
include(${EXECUTORCH_ROOT}/build/Utils.cmake)
# Add a custom op library
add_library(custom_op_lib SHARED ${CMAKE_CURRENT_SOURCE_DIR}/custom_op.cpp)
# Include the header
target_include_directory(custom_op_lib PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}/include)
# Link ExecuTorch library
target_link_libraries(custom_op_lib PUBLIC executorch)
# Define a binary target
add_executable(custom_op_runner PUBLIC main.cpp)
# Link this library with --whole-archive !! IMPORTANT !! this is to avoid the operators being stripped by linker
target_link_options_shared_lib(custom_op_lib)
# Link custom op lib
target_link_libraries(custom_op_runner PUBLIC custom_op_lib)
將其鏈接到 PyTorch 執行期:我們需要將 custom_linear.h、custom_linear.cpp 和 custom_linear_pytorch.cpp 打包到一個動態載入的函式庫(.so 或 .dylib)中,並將其載入到我們的 python 環境中。一種方法是:
import torch
torch.ops.load_library("libcustom_linear.so/dylib")
# Now we have access to the custom op, backed by kernel implemented in custom_linear.cpp.
op = torch.ops.myop.custom_linear.default
自定義運算子 API 最佳實踐¶
鑑於我們有 2 個用於自定義運算子的核心註冊 API,我們應該使用哪個 API? 以下是每個 API 的一些優缺點:
C++ API
優點
只需要變更 C++ 程式碼
類似於 PyTorch 自定義運算子 C++ API
維護成本低
缺點
不支援選擇性建置
沒有集中式帳務
Yaml entry API
優點
支援選擇性建置
為自定義運算子提供集中式位置
它顯示了正在註冊哪些運算子,以及哪些核心綁定到這些運算子(對於應用程式而言)。
缺點
使用者需要建立和維護 yaml 檔案
變更運算子定義相對不靈活
總體而言,如果我們正在建置一個應用程式,並且它使用自定義運算子,則在開發階段建議使用 C++ API,因為它的使用成本較低且變更靈活。 一旦應用程式進入生產階段,自定義運算子定義和建置系統相當穩定,並且需要考慮二進位檔大小,則建議使用 Yaml entry API。
