量化概觀¶
量化是一種降低計算精確度並降低模型記憶體佔用空間的過程。要了解更多資訊,請造訪ExecuTorch 概念頁面。這對於包括穿戴式裝置、嵌入式裝置和微控制器在內的邊緣裝置特別有用,這些裝置通常具有有限的資源,例如處理能力、記憶體和電池壽命。透過使用量化,我們可以使我們的模型更有效率,並使它們能夠在這些裝置上有效地運行。
就流程而言,量化發生在 ExecuTorch 堆疊的早期階段
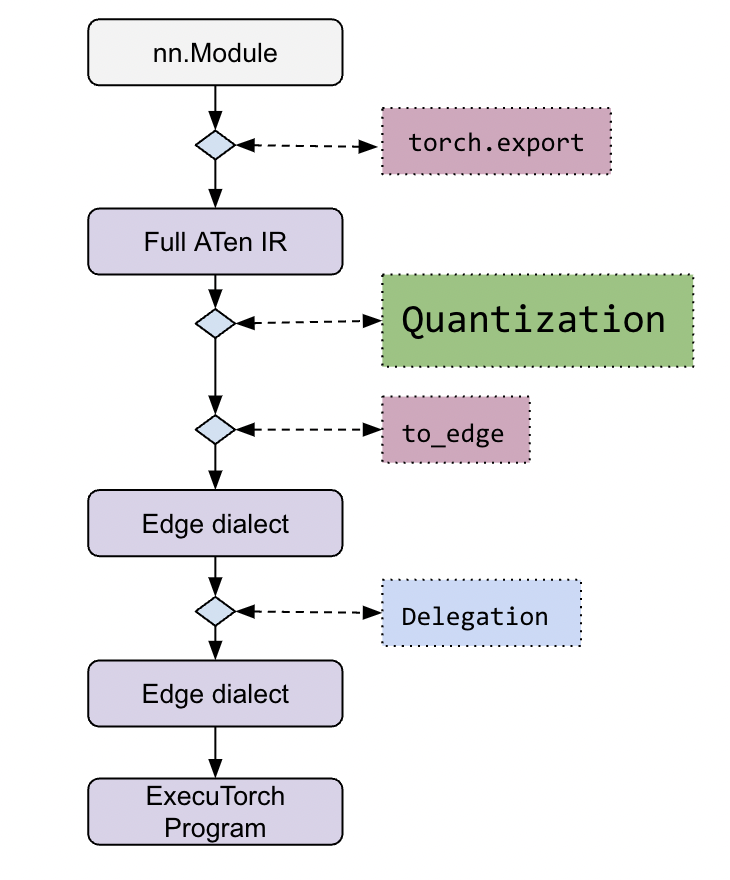
更詳細的工作流程可以在ExecuTorch 教學中找到。
量化通常與實作了量化運算子的執行後端相關聯。因此,每個後端對於如何量化模型都有自己的看法,並以特定於後端的 Quantizer 類別表示。Quantizer 提供 API,用於對使用者如何量化模型進行建模,並將使用者的意圖傳遞給量化工作流程。
後端開發人員需要實作他們自己的 Quantizer,以表達不同的運算子或運算子模式如何在他們的後端中被量化。這是透過量化工作流程提供的 Annotation API 來完成的。由於 Quantizer 也是面向使用者的,它將公開特定的 API,讓建模使用者能夠配置他們希望如何量化模型。每個後端都應該為他們的 Quantizer 提供自己的 API 文件。
建模使用者將使用特定於其目標後端的 Quantizer 來量化他們的模型,例如 XNNPACKQuantizer。
有關使用 XNPACKQuantizer 的量化流程範例,以及更多文件和教學,請參閱 ExecuTorch 教學 中的 Performing Quantization 部分。
原始碼量化:Int8DynActInt4WeightQuantizer¶
除了基於匯出的量化(如上所述),ExecuTorch 想要強調基於原始碼的量化,這是透過 torchao 完成的。與基於匯出的量化不同,基於原始碼的量化會在匯出之前直接修改模型。一個具體的例子是 Int8DynActInt4WeightQuantizer。
此方案表示 4 位元權重量化,並在推論期間對激活進行 8 位元動態量化。
使用 from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer 導入,此類別使用具有指定 dtype 精度和 groupsize 建構的量化實例,來變更提供的 nn.Module。
# Source Quant
from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer
model = Int8DynActInt4WeightQuantizer(precision=torch_dtype, groupsize=group_size).quantize(model)
# Export to ExecuTorch
from executorch.exir import to_edge
from torch.export import export
exported_model = export(model, ...)
et_program = to_edge(exported_model, ...).to_executorch(...)
