ExecuTorch XNNPACK 委派物件¶
這是 ExecuTorch XNNPACK 後端委派物件的高階概觀。這個高效能的委派物件旨在降低 ExecuTorch 模型的 CPU 推論延遲。我們將簡要介紹 XNNPACK 函式庫,並探討委派物件的整體架構和預期用例。
什麼是 XNNPACK?¶
XNNPACK 是一個高度優化的神經網路運算符函式庫,適用於 Android、iOS、Windows、Linux 和 macOS 環境中的 ARM、x86 和 WebAssembly 架構。它是一個開源專案,您可以在 github 上找到更多相關資訊。
什麼是 ExecuTorch 委派物件?¶
委派 (Delegate) 是後端處理並執行 ExecuTorch 程式碼片段的進入點。ExecuTorch 模型中被委派的部分會將執行權交給後端。XNNPACK 後端委派是 ExecuTorch 中眾多可用的委派之一。它利用 XNNPACK 第三方函式庫,在各種 CPU 上有效地加速 ExecuTorch 程式。關於委派以及開發您自己的委派的更多詳細資訊,請參閱此處。建議您在繼續閱讀架構章節之前,先熟悉這些內容。
架構¶
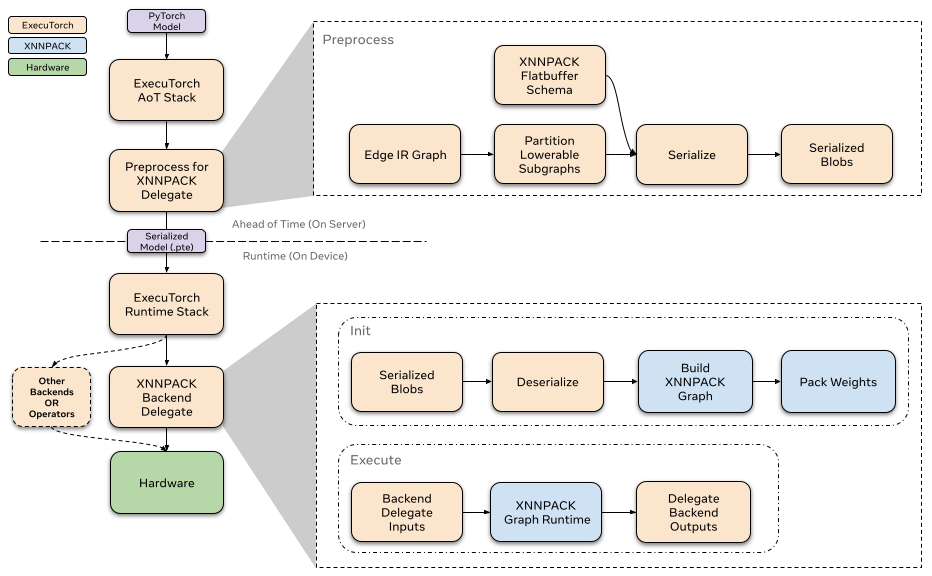
預先 (Ahead-of-time)¶
在 ExecuTorch 匯出流程中,降低到 XNNPACK 委派發生在 to_backend() 階段。在這個階段,模型會由 XnnpackPartitioner 進行分割。圖表中被分割的部分會被轉換為 XNNPACK 特定的圖形表示,然後透過 FlatBuffer 進行序列化。序列化的 FlatBuffer 接著就可以在執行階段由 XNNPACK 後端進行反序列化和執行。

分割器 (Partitioner)¶
分割器由後端委派實作,以標記適合降低的節點。XnnpackPartitioner 使用節點目標和模組元資料來降低。關於分割器的更多參考資料可以在此處找到。
基於模組的分割 (Module-based partitioning)¶
source_fn_stack 嵌入在節點的元資料中,並提供關於這些節點來源的資訊。例如,當模組 (如 torch.nn.Linear) 被捕獲並匯出到 to_edge 時,會產生用於其計算的節點群組。與計算線性模組相關聯的節點群組接著會有 source_fn_stack 為 torch.nn.Linear。基於 `source_fn_stack` 的分割讓我們能夠識別可以透過 XNNPACK 降低的節點群組。
例如,在捕獲 torch.nn.Linear 之後,您會在與線性相關聯的 addmm 節點的元資料中找到以下鍵:
>>> print(linear_node.meta["source_fn_stack"])
'source_fn_stack': ('fn', <class 'torch.nn.modules.linear.Linear'>)
基於運算的分割 (Op-based partitioning)¶
XnnpackPartitioner 也使用運算目標進行分割。它遍歷圖表,並識別可以降低到 XNNPACK 的個別節點。基於模組的分割的一個缺點是,來自於分解 (decompositions) 的運算子可能會被跳過。例如,像 torch.nn.Hardsigmoid 這樣的運算子會被分解為 add、muls、divs 和 clamps。雖然 hardsigmoid 無法降低,但我們可以降低分解後的運算。依賴 source_fn_stack 元資料會跳過這些可降低的項目,因為它們屬於無法降低的模組,因此為了提高模型效能,我們會貪婪地降低基於運算目標以及 source_fn_stack 的運算子。
Passes (遍歷)¶
在任何序列化之前,我們會對子圖應用遍歷 (passes) 來準備圖表。這些遍歷本質上是圖形轉換,有助於提高委派的效能。我們在下面概述了最重要的遍歷及其功能。有關所有遍歷的描述,請參閱此處
Channels Last Reshape (通道優先重塑)
ExecuTorch 張量在傳遞到委派之前往往是連續的,而 XNNPACK 只接受 channels-last 記憶體佈局。此遍歷最小化了插入排列運算子的數量,以傳入 channels-last 記憶體格式。
Conv1d to Conv2d (Conv1d 轉換為 Conv2d)
允許我們透過將 Conv1d 節點轉換為 Conv2d 來委派它們。
Conv and BN Fusion (Conv 和 BN 融合)
將批次正規化 (batch norm) 運算與先前的卷積節點融合。
序列化 (Serialiazation)¶
在從模型分割可降低的子圖之後,XNNPACK 委派會預先處理這些子圖,並透過 FlatBuffer 將它們序列化以供 XNNPACK 後端使用。
執行階段 (Runtime)¶
XNNPACK 後端的執行階段透過自訂的 init 和 execute 函式與 ExecuTorch 執行階段互動。每個委派的子圖都包含在一個單獨序列化的 XNNPACK Blob 中。當模型初始化時,ExecuTorch 會對所有 XNNPACK Blob 調用 init,以從序列化的 FlatBuffer 載入子圖。之後,當模型執行時,每個子圖都透過後端透過自訂的 execute 函式執行。要了解更多關於委派執行階段如何與 ExecuTorch 互動的信息,請參考這個資源。
Init (初始化)¶
當調用 XNNPACK 委派的 init 時,我們會透過 FlatBuffer 反序列化預先處理的 Blob。我們定義節點(運算子)和邊(中間張量)以使用我們預先序列化的資訊來構建 XNNPACK 執行圖。正如我們前面提到的,大部分的處理都是預先完成的,因此在執行階段,我們只需使用序列化的參數連續調用 XNNPACK API。當我們將靜態資料定義到執行圖中時,XNNPACK 會在執行階段執行權重打包,以準備靜態資料(如權重和偏差)以供高效執行。在建立執行圖之後,我們會建立執行階段物件並將其傳遞給 execute。
由於權重打包會在 XNNPACK 內部建立權重的額外副本,因此我們會釋放預先處理的 XNNPACK Blob 內部權重的原始副本,這使我們能夠消除一些記憶體開銷。
Execute (執行)¶
當執行 XNNPACK 子圖時,我們會準備張量輸入和輸出,並將它們饋送到 XNNPACK 執行階段圖形。在執行執行階段圖形之後,輸出指標會填入計算出的張量。
Profiling (效能分析)¶
我們已為 XNNPACK 委派啟用基本分析功能,可以使用以下編譯器標誌 -DENABLE_XNNPACK_PROFILING 啟用。 透過 ExecuTorch 的開發者工具整合,您現在也可以使用開發者工具來分析模型。您可以按照 使用 ExecuTorch 開發者工具分析模型 中的步驟,了解如何分析 ExecuTorch 模型,並使用開發者工具的 Inspector API 來檢視 XNNPACK 的內部分析資訊。
量化¶
XNNPACK 委派也可以用作後端來執行對稱量化模型。對於量化模型委派,我們使用 XNNPACKQuantizer 量化模型。Quantizers 是後端特定的,這意味著 XNNPACKQuantizer 被配置為量化模型,以利用 XNNPACK 函式庫提供的量化運算符。我們不會詳細介紹如何實現您的自定義量化器,您可以按照 這裡 的文檔來完成。 但是,我們將簡要概述如何量化模型以利用 XNNPACK 委派的量化執行。
配置 XNNPACKQuantizer¶
from torch.ao.quantization.quantizer.xnnpack_quantizer import (
XNNPACKQuantizer,
get_symmetric_quantization_config,
)
quantizer = XNNPACKQuantizer()
quantizer.set_global(get_symmetric_quantization_config())
在這裡,我們初始化 XNNPACKQuantizer 並將量化配置設定為對稱量化。當權重以 qmin = -127 和 qmax = 127 對稱量化時,即為對稱量化,這會強制量化零點為零。get_symmetric_quantization_config() 可以使用以下參數配置
is_per_channel權重跨通道量化
is_qat量化感知訓練
is_dynamic動態量化
然後我們可以根據需要配置 XNNPACKQuantizer。 我們在下面設置以下配置作為示例
quantizer.set_global(quantization_config)
.set_object_type(torch.nn.Conv2d, quantization_config) # can configure by module type
.set_object_type(torch.nn.functional.linear, quantization_config) # or torch functional op typea
.set_module_name("foo.bar", quantization_config) # or by module fully qualified name
使用 XNNPACKQuantizer 量化模型¶
配置完量化器後,我們現在可以量化我們的模型
from torch.export import export_for_training
exported_model = export_for_training(model_to_quantize, example_inputs).module()
prepared_model = prepare_pt2e(exported_model, quantizer)
print(prepared_model.graph)
Prepare 執行一些 Conv2d-BN 融合,並在適當的位置插入量化觀察器。 對於訓練後量化,我們通常在此步驟之後校準我們的模型。 我們通過 prepared_model 運行示例,以觀察張量的統計資訊以計算量化參數。
最後,我們在這裡轉換我們的模型
quantized_model = convert_pt2e(prepared_model)
print(quantized_model)
您現在將看到模型的 Q/DQ 表示,這意味著 torch.ops.quantized_decomposed.dequantize_per_tensor 插入到量化運算符輸入,而 torch.ops.quantized_decomposed.quantize_per_tensor 插入到運算符輸出。 範例
def _qdq_quantized_linear(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max,
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max,
bias_fp32,
out_scale, out_zero_point, out_quant_min, out_quant_max
):
x_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max, torch.int8)
weight_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max, torch.int8)
out_fp32 = torch.ops.aten.linear.default(x_fp32, weight_fp32, bias_fp32)
out_i8 = torch.ops.quantized_decomposed.quantize_per_tensor(
out_fp32, out_scale, out_zero_point, out_quant_min, out_quant_max, torch.int8)
return out_i8
您可以在 這裡 閱讀關於 PyTorch 2 量化的更深入解釋。
