ExecuTorch 執行階段概述¶
本文檔討論了 ExecuTorch 執行階段的設計,該執行階段在智慧型手機、穿戴裝置和嵌入式裝置等邊緣裝置上執行 ExecuTorch 程式檔案。主要執行 API 的程式碼位於 executorch/runtime/executor/ 下。
在閱讀本文檔之前,我們建議您閱讀 ExecuTorch 如何運作。
在最高層級,ExecuTorch 執行階段負責
載入二進制
.pte程式檔案,這些檔案由模型降低過程的to_executorch()步驟產生。執行一系列實現降低模型的指令。
請注意,截至 2023 年底,ExecuTorch 執行階段僅支援模型推論,尚未支援訓練。
此圖表顯示了匯出和執行 ExecuTorch 程式的高階流程和相關元件。
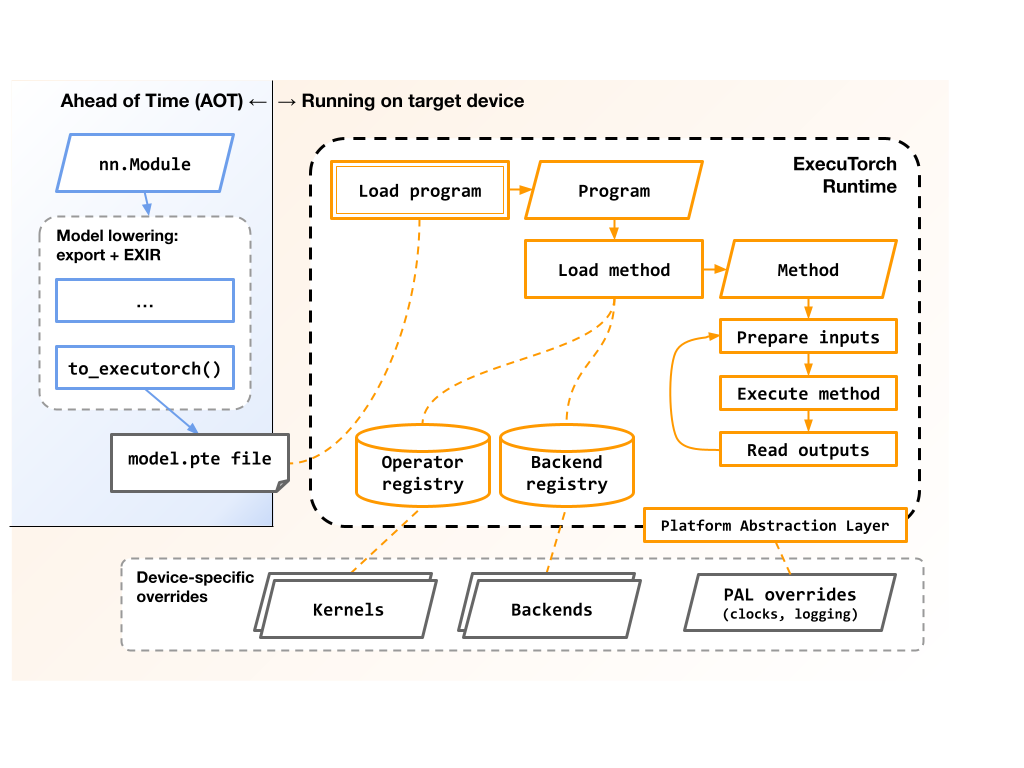
Runtime 也負責以下事項:
管理載入和執行期間使用的記憶體,可能跨越多個記憶體庫,例如 SRAM 和 DRAM。
將符號運算子名稱(如
"aten::add.out")映射到具體的 C++ 函式或核心 (kernels),這些函式或核心實作這些運算子的語意。將模型的預定部分分派到 後端委派 (backend delegates) 進行加速。
選擇性地在載入和執行期間收集 分析資料 (profiling data)。
設計目標¶
ExecuTorch runtime 的設計目的是在各種邊緣裝置上執行,從現代智慧型手機 CPU 到資源受限的微控制器和 DSP。 它具有對 委派 (delegating) 執行到一個或多個後端的一流支援,以利用特定架構的優化和現代異構架構。 它足夠小且可移植,可以直接在裸機嵌入式環境中運行,而無需作業系統、動態記憶體或執行緒。
低執行開銷¶
記憶體¶
在沒有核心或後端的情況下建置時,核心 runtime 函式庫小於 50kB。
常數張量直接指向
.pte檔案資料,避免複製該資料。 這些資料區塊的對齊方式可以在.pte建立時調整。後端委派可以選擇在模型初始化後卸載其預先編譯的資料,從而減少峰值記憶體使用量。
可變張量記憶體佈局是預先計劃好的,並封裝到一小組使用者分配的緩衝區中,從而提供對記憶體位置的精細控制。 這在具有異構記憶體層次結構的系統上特別有用,允許放置到將對資料進行操作的核心附近的 (例如) SRAM 或 DRAM 上。
CPU¶
模型執行是對指令陣列的簡單迴圈,其中大多數是指向核心和後端委派的函式指標。 這使執行開銷保持在較小範圍內,每個操作的數量級為微秒到奈秒。
操作(如“add”或“conv3d”)的實作可以針對特定目標系統進行完全客製化,而無需修改原始模型或產生的
.pte檔案。
熟悉的 PyTorch 語意¶
ExecuTorch 是 PyTorch 堆疊的一流元件,並盡可能重複使用 API 和語意。
ExecuTorch 使用的 C++ 類型與核心 PyTorch 的
c10::和at::函式庫中的對應類型在原始碼上相容,並且 ExecuTorch 提供了aten_bridge以在這兩者之間進行轉換。 這對於已經使用 PyTorch C++ 類型的專案可能很有幫助。運算子(如
aten::add和aten::sigmoid)的語意在 ExecuTorch 和核心 PyTorch 之間是相同的。 ExecuTorch 提供了一個測試框架來確保這一點,並幫助測試這些運算子的未來實作。
可移植的程式碼和架構¶
ExecuTorch runtime 的實作考慮到可移植性,以便使用者可以為各種目標系統建置它。
C++ 語言考量¶
該程式碼與 C++17 相容,以便與舊版工具鏈一起使用。
Runtime 不使用例外或 RTTI,但它並不反對它們。
該程式碼與 GCC 和 Clang 相容,並且也已使用多個專有的嵌入式工具鏈建置。
repo 提供了 CMake 建置系統,以使整合更容易。
作業系統考量¶
Runtime 不進行直接系統呼叫。 對記憶體、檔案、記錄和時脈的所有存取都透過 Runtime 平台抽象層 (PAL) 和注入的介面(如 DataLoader 和 MemoryAllocator)進行抽象。 請參閱 runtime api 參考 以了解更多資訊。
應用程式可以透過 MemoryManager、MemoryAllocator、HierarchicalAllocator 和 DataLoader 類別來控制所有記憶體分配。 核心 runtime 不會直接呼叫 malloc() 或 new,或在幕後分配的類型(如 std::vector)。 這使得可以:
在沒有堆積的環境中運行,但如果需要,仍然可以使用堆積。
避免在模型載入和執行期間在堆積上進行同步。
控制要用於不同類型資料的記憶體區域。 例如,一組可變張量可以存在於 SRAM 中,而另一組可以存在於 DRAM 中。
輕鬆監控 runtime 使用了多少記憶體。
但是,請注意,特定的核心或後端實作可能會使用任意的 runtime 或作業系統功能。 使用者應仔細檢查他們使用的核心和後端函式庫的文件。
執行緒考量¶
核心 runtime 不進行執行緒或鎖定,也不使用執行緒區域變數。 但是,它可以很好地與較高層級的同步配合使用。
每個
Program實例都是不可變的,因此完全執行緒安全 (fully thread-safe)。 多個執行緒可以同時存取單個Program實例。每個
Method實例是可變的,但又是獨立的,因此是有條件的執行緒安全。 多個執行緒可以同時存取和執行獨立的Method實例,但單個實例的存取和執行必須序列化。
但是,請注意:
在
Program::load_method()期間,可能會讀取兩個全域表格:核心註冊表和後端註冊表。實際上,這些表格僅在程序/系統載入時被修改,並且在第一個
Program載入之前實際上是被凍結的。 但是,某些應用程式可能需要注意這些表格,特別是如果它們在程序/系統載入後手動修改它們。
特定的核心或後端實作可能會有它們自己的執行緒限制。 使用者應仔細檢查他們使用的核心和後端函式庫的文件。
延伸閱讀¶
有關 ExecuTorch 運行時的更多詳細資訊,請參閱:
