


Holistic Trace Analysis 簡介¶
建立於:2024 年 1 月 2 日 | 最後更新:2024 年 1 月 5 日 | 最後驗證:2024 年 11 月 5 日
作者: Anupam Bhatnagar
在本教學中,我們將示範如何使用 Holistic Trace Analysis (HTA) 來分析分散式訓練任務的追蹤。 若要開始,請依照下列步驟操作。
安裝 HTA¶
我們建議使用 Conda 環境來安裝 HTA。 若要安裝 Anaconda,請參閱官方 Anaconda 文件。
使用 pip 安裝 HTA
pip install HolisticTraceAnalysis
(可選但建議) 設定 Conda 環境
# create the environment env_name conda create -n env_name # activate the environment conda activate env_name # When you are done, deactivate the environment by running ``conda deactivate``
入門¶
啟動 Jupyter 筆記本,並將 trace_dir 變數設定為追蹤的位置。
from hta.trace_analysis import TraceAnalysis
trace_dir = "/path/to/folder/with/traces"
analyzer = TraceAnalysis(trace_dir=trace_dir)
時間分解¶
為了有效地利用 GPU,務必了解它們在特定任務上花費時間的方式。 它們主要用於計算、通訊、記憶體事件,還是閒置? 時間分解功能提供對這三個類別中花費時間的詳細分析。
閒置時間 - GPU 閒置。
計算時間 - GPU 用於矩陣乘法或向量運算。
非計算時間 - GPU 用於通訊或記憶體事件。
為了實現高訓練效率,程式碼應最大化計算時間,並最小化閒置時間和非計算時間。 以下函數產生一個 DataFrame,提供每個等級的詳細時間使用量分解。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
time_spent_df = analyzer.get_temporal_breakdown()
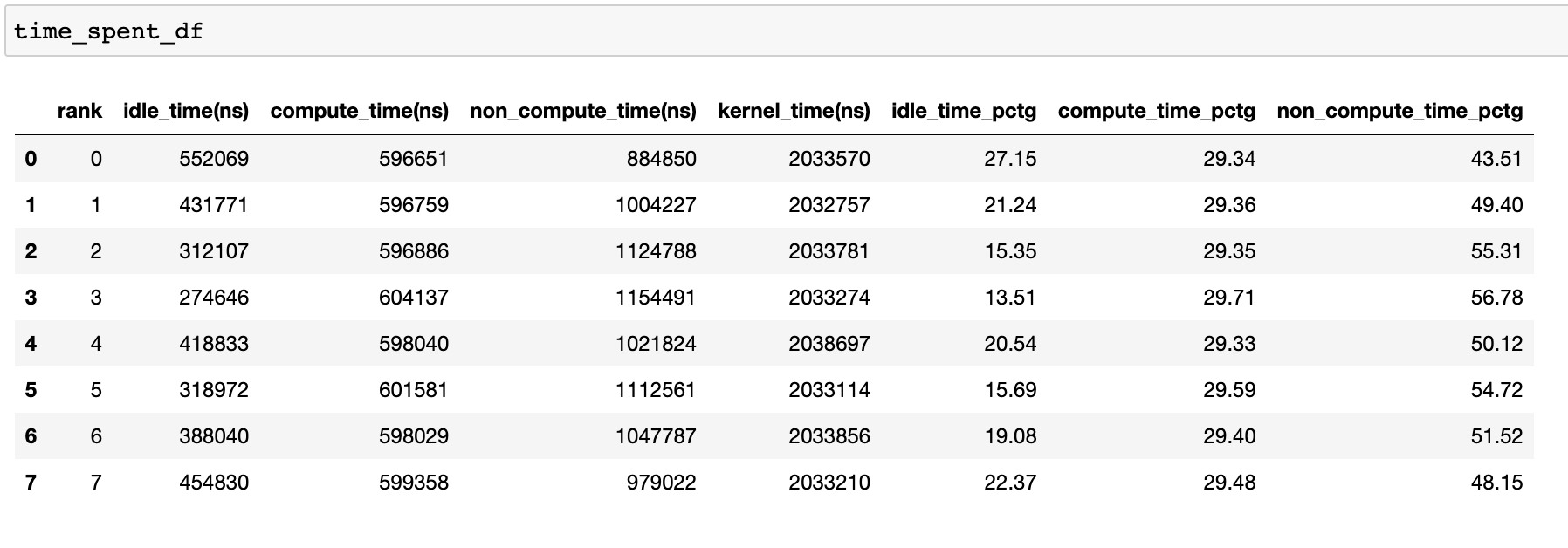
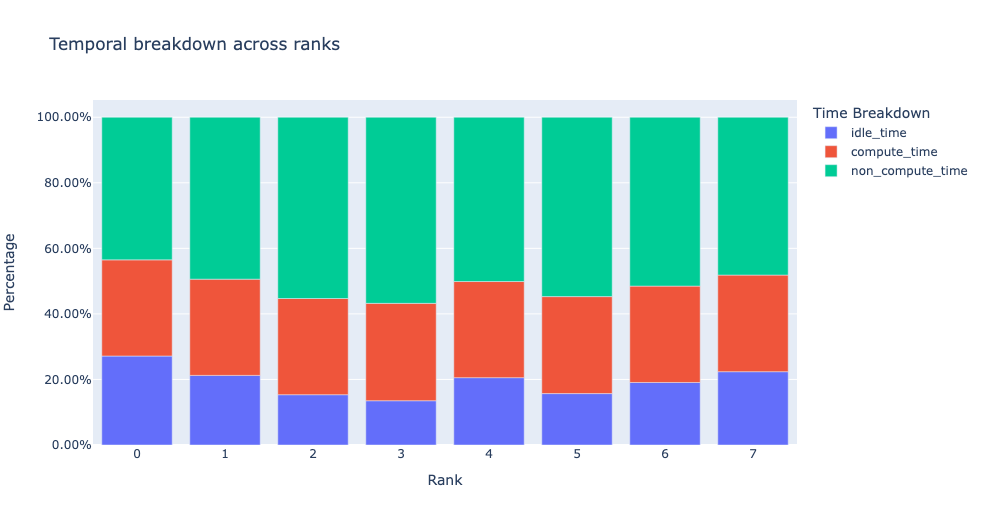
當 get_temporal_breakdown 函數中的 visualize 引數設定為 True 時,它也會產生一個條形圖,表示按等級分解。
閒置時間分解¶
深入了解 GPU 花費在閒置上的時間量以及背後的原因,有助於指導優化策略。 當沒有核心在 GPU 上執行時,GPU 會被視為閒置。 我們開發了一種演算法,將 閒置 時間分為三個不同的類別
Host wait: 指 GPU 上的閒置時間,這是因為 CPU 沒有足夠快地將核心排隊,以保持 GPU 的充分利用。 這些類型的效率低落可以通過檢查導致速度變慢的 CPU 運算符、增加批次大小和應用運算符融合來解決。
Kernel wait: 這指的是在 GPU 上啟動連續核心時的簡短開銷。 屬於此類別的閒置時間可以通過使用 CUDA 圖形優化來最小化。
Other wait: 此類別包含由於訊息不足目前無法歸因的閒置時間。 可能的原因包括使用 CUDA 事件在 CUDA 串流之間的同步以及啟動核心的延遲。
Host wait 時間可以解釋為 GPU 由於 CPU 而停止的時間。 為了將閒置時間歸因於核心等待,我們使用以下啟發式方法
連續核心之間的間隙 < 閾值
預設的臨界值為 30 奈秒,可以使用 consecutive_kernel_delay 參數進行配置。 預設情況下,閒置時間的細分僅針對 rank 0 計算。 為了計算其他 rank 的細分,請在 get_idle_time_breakdown 函數中使用 ranks 參數。 閒置時間的細分可以按如下方式產生
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
idle_time_df = analyzer.get_idle_time_breakdown()
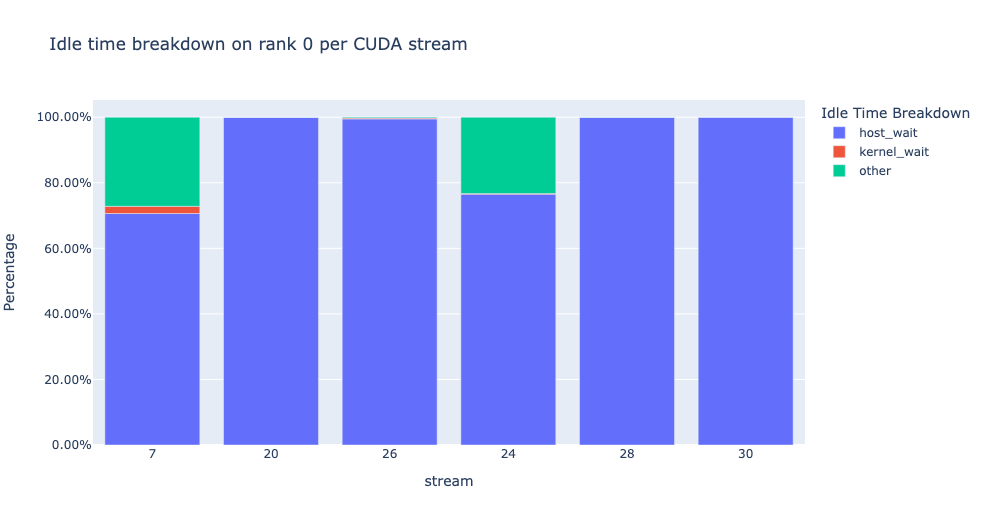
該函數返回一個 dataframes 的 tuple。 第一個 dataframe 包含每個 rank 的每個 stream 上的按類別劃分的閒置時間。
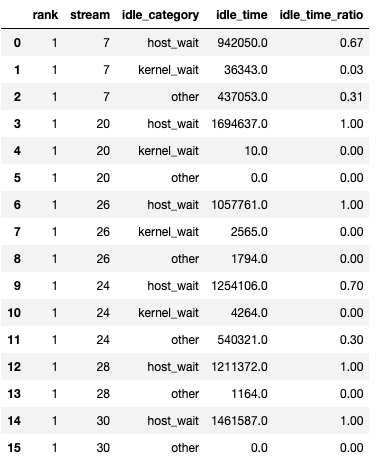
當 show_idle_interval_stats 設定為 True 時,將生成第二個 dataframe。 它包含每個 rank 的每個 stream 上閒置時間的摘要統計信息。
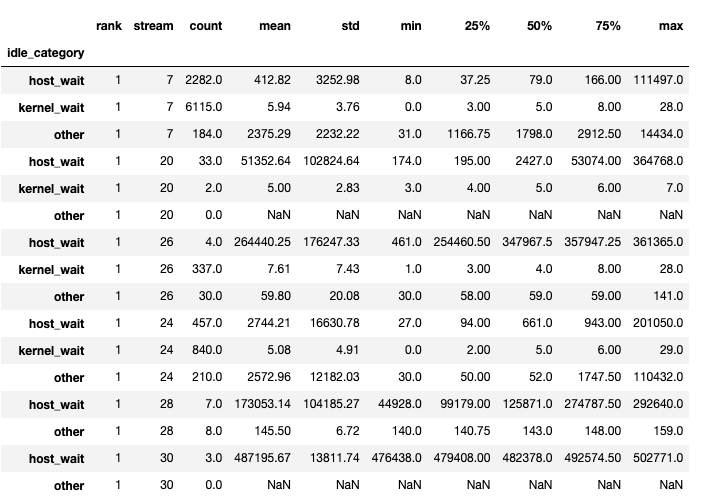
提示
預設情況下,閒置時間的細分呈現每個閒置時間類別的百分比。 將 visualize_pctg 參數設定為 False,該函數將在 y 軸上以絕對時間呈現。
核心細分¶
核心細分功能會細分每個核心類型(例如通訊 (COMM)、運算 (COMP) 和記憶體 (MEM))所花費的時間,遍及所有 rank,並呈現每個類別中所花費的時間比例。 以下是每個類別中花費的時間百分比,以圓餅圖表示
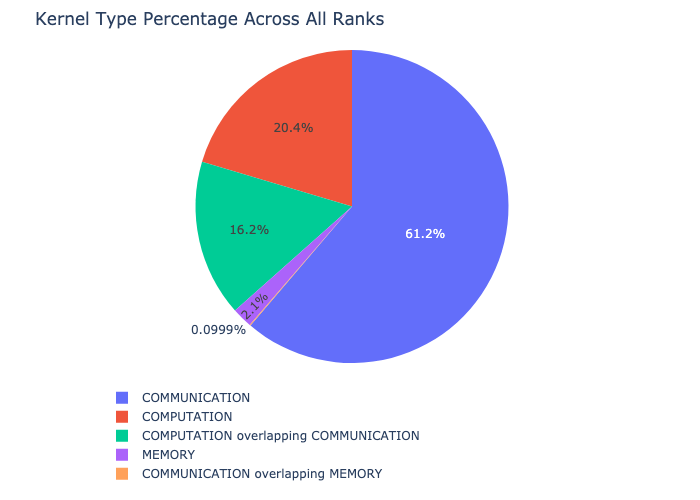
核心細分可以按如下方式計算
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
該函數返回的第一個 dataframe 包含用於生成圓餅圖的原始值。
核心持續時間分佈¶
get_gpu_kernel_breakdown 返回的第二個 dataframe 包含每個核心的持續時間摘要統計信息。 尤其是,這包括每個 rank 上每個核心的計數、最小值、最大值、平均值、標準差、總和和核心類型。
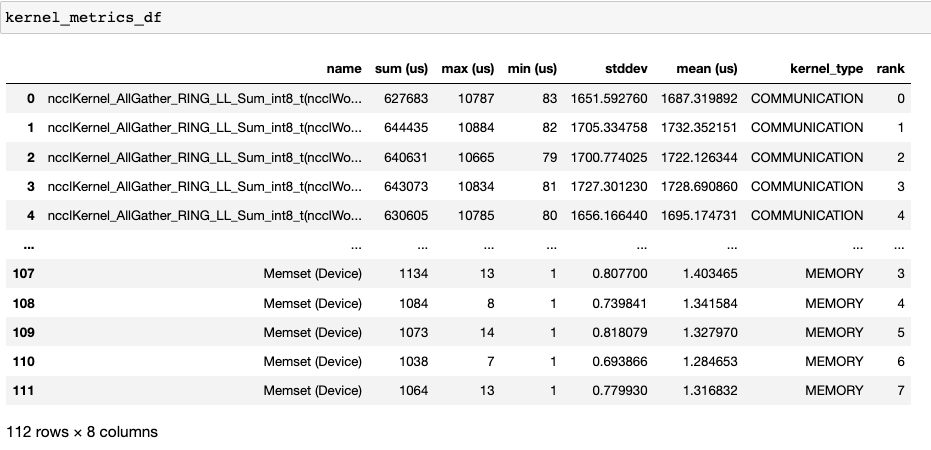
使用此資料,HTA 創建了許多視覺化效果來識別效能瓶頸。
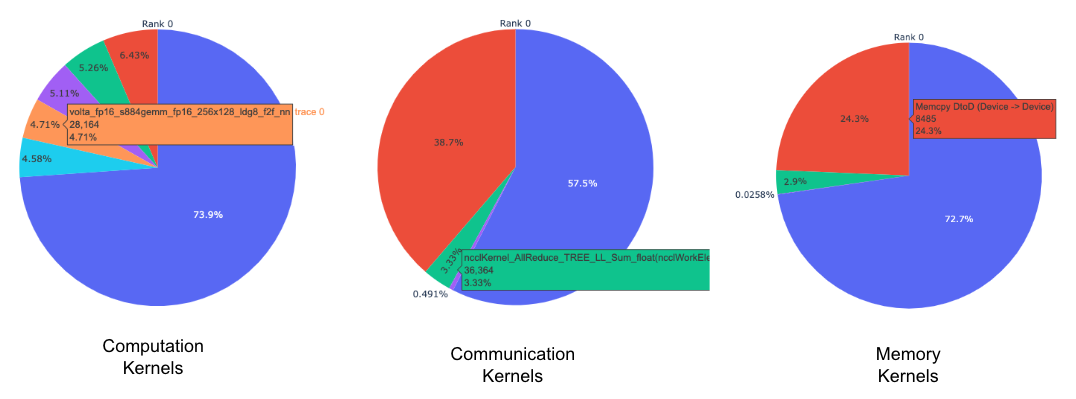
每個 rank 的每個核心類型的頂部核心的圓餅圖。
每個頂部核心和每個核心類型的所有 rank 的平均持續時間的長條圖。
提示
所有圖片都是使用 plotly 生成的。 將滑鼠懸停在圖表上會在右上角顯示模式列,使用者可以透過它來縮放、平移、選擇和下載圖表。
上面的圓餅圖顯示了前 5 個運算、通訊和記憶體核心。 為每個 rank 生成類似的圓餅圖。 可以配置圓餅圖以顯示前 k 個核心,方法是將 num_kernels 參數傳遞給 get_gpu_kernel_breakdown 函數。 此外,可以使用 duration_ratio 參數來調整需要分析的時間百分比。 如果同時指定 num_kernels 和 duration_ratio,則 num_kernels 優先。
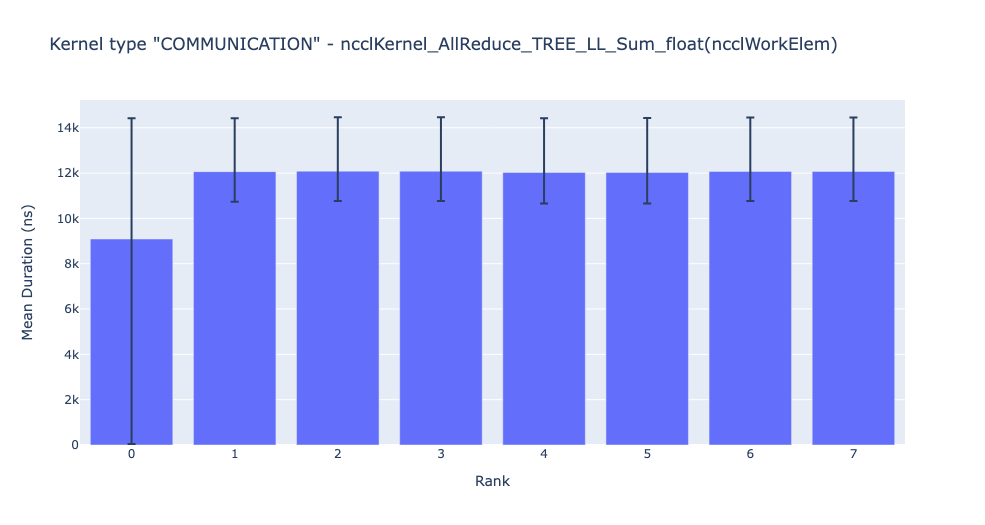
上面的長條圖顯示了所有 rank 中 NCCL AllReduce 核心的平均持續時間。 黑線表示每個 rank 上所花費的最短和最長時間。
警告
使用 jupyter-lab 時,請將 “image_renderer” 參數值設定為 “jupyterlab”,否則圖表將不會在筆記本中呈現。
有關此功能的詳細演練,請參閱 repo 的 examples 資料夾中的 gpu_kernel_breakdown 筆記本。
通訊運算重疊¶
在分散式訓練中,大量時間花費在 GPU 之間的通訊和同步事件中。 為了實現高的 GPU 效率(例如 TFLOPS/GPU),至關重要的是使 GPU 超額訂閱運算核心。 換句話說,GPU 不應由於未解決的資料依賴性而受到阻止。 衡量運算被資料依賴性阻止程度的一種方法是計算通訊運算重疊。 如果通訊事件與運算事件重疊,則會觀察到更高的 GPU 效率。 缺乏通訊和運算重疊將導致 GPU 閒置,從而導致效率降低。 總而言之,希望具有更高的通訊運算重疊。 為了計算每個 rank 的重疊百分比,我們測量以下比率
(在通訊時花費在運算上的時間) / (花費在通訊上的時間)
通訊運算重疊可以按如下方式計算
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
overlap_df = analyzer.get_comm_comp_overlap()
該函數返回一個 dataframe,其中包含每個 rank 的重疊百分比。
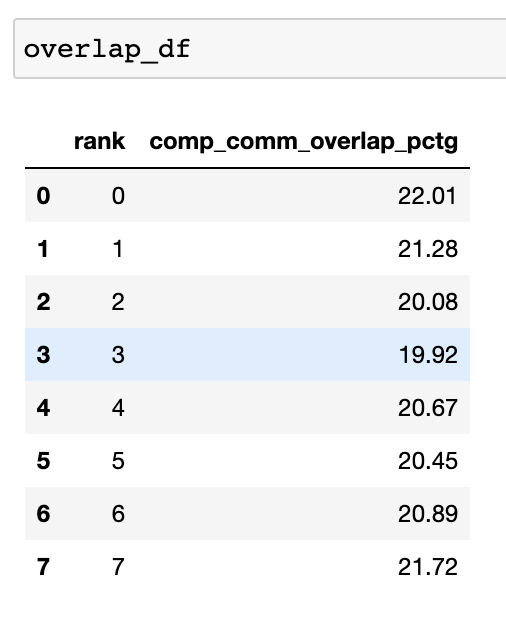
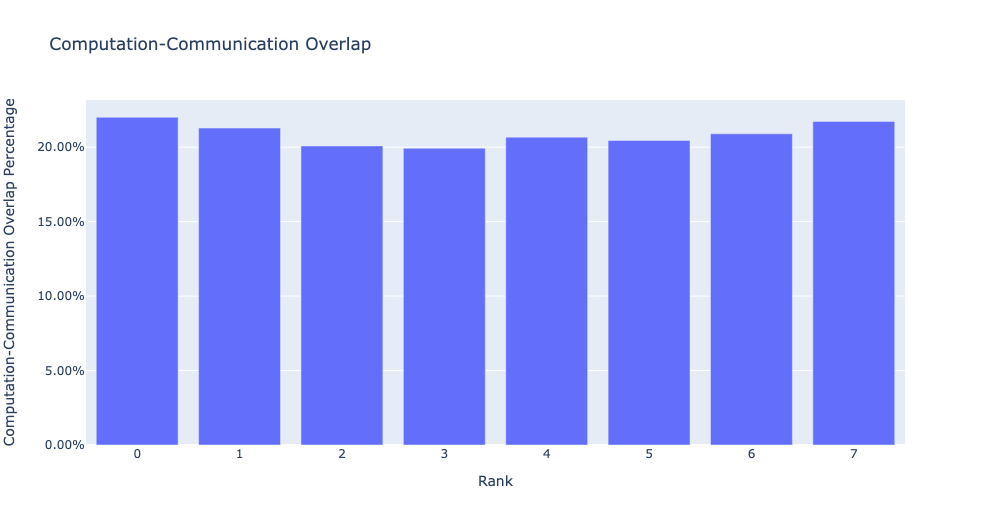
當 visualize 參數設定為 True 時,get_comm_comp_overlap 函數也會生成一個長條圖,表示按 rank 劃分的重疊。
增強計數器¶
記憶體頻寬和佇列長度計數器¶
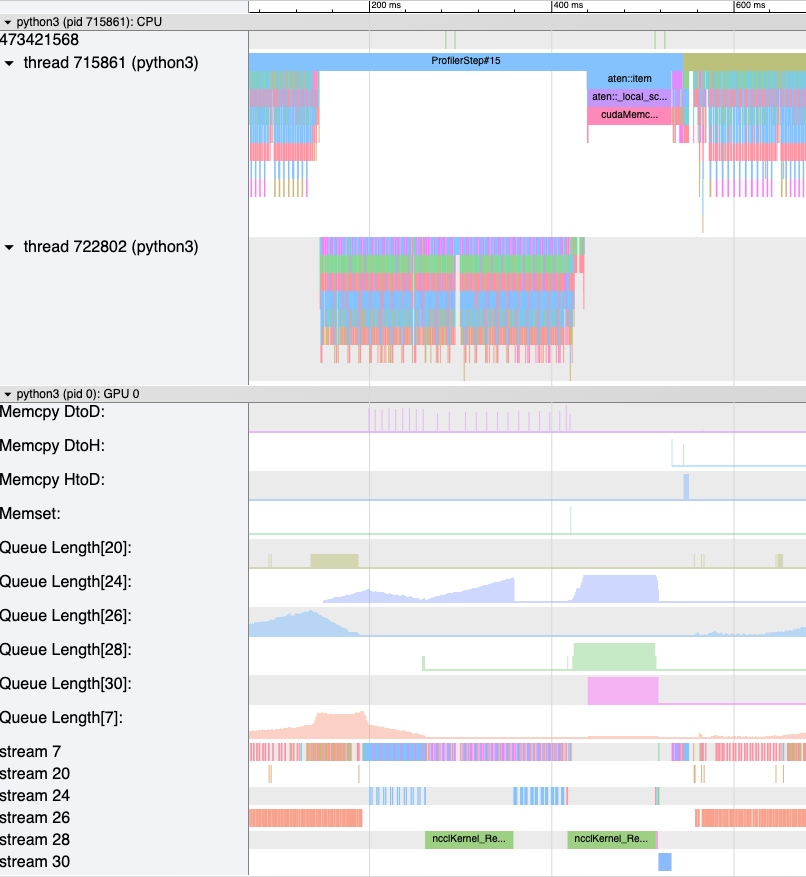
記憶體頻寬計數器測量用於透過記憶體複製 (memcpy) 和記憶體設定 (memset) 事件從 H2D、D2H 和 D2D 複製資料時所使用的記憶體複製頻寬。 HTA 也會計算每個 CUDA stream 上的未完成操作數。 我們將其稱為佇列長度。 當 stream 上的佇列長度為 1024 或更大時,無法在該 stream 上排程新事件,並且 CPU 將停頓,直到 GPU stream 上的事件處理完畢。
generate_trace_with_counters API 輸出一個新的追蹤檔案,其中包含記憶體頻寬和佇列長度計數器。 新的追蹤檔案包含軌跡,這些軌跡指示 memcpy/memset 操作使用的記憶體頻寬,以及每個 stream 上的佇列長度的軌跡。 預設情況下,這些計數器是使用 rank 0 追蹤檔案生成的,並且新檔案的名稱中包含後綴 _with_counters。 使用者可以選擇使用 generate_trace_with_counters API 中的 ranks 參數來為多個 rank 生成計數器。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
analyzer.generate_trace_with_counters()
帶有增強計數器的已生成追蹤檔案的螢幕截圖。
HTA 也提供了記憶體複製頻寬和佇列長度計數器的摘要,以及使用以下 API 剖析程式碼部分的計數器時間序列:
若要檢視摘要和時間序列,請使用
# generate summary
mem_bw_summary = analyzer.get_memory_bw_summary()
queue_len_summary = analyzer.get_queue_length_summary()
# get time series
mem_bw_series = analyzer.get_memory_bw_time_series()
queue_len_series = analyzer.get_queue_length_series()
摘要包含計數、最小值、最大值、平均值、標準差、第 25 百分位數、第 50 百分位數和第 75 百分位數。
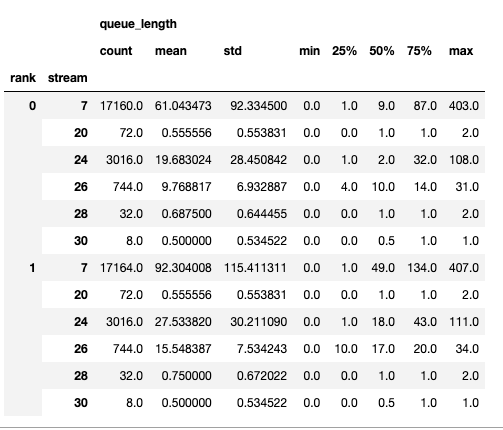
時間序列僅包含值變更時的點。一旦觀察到一個值,時間序列就會保持恆定,直到下一次更新。記憶體頻寬和佇列長度時間序列函式會傳回一個字典,其鍵是 rank(等級),值是該 rank 的時間序列。預設情況下,時間序列僅針對 rank 0 計算。
CUDA Kernel 啟動統計¶
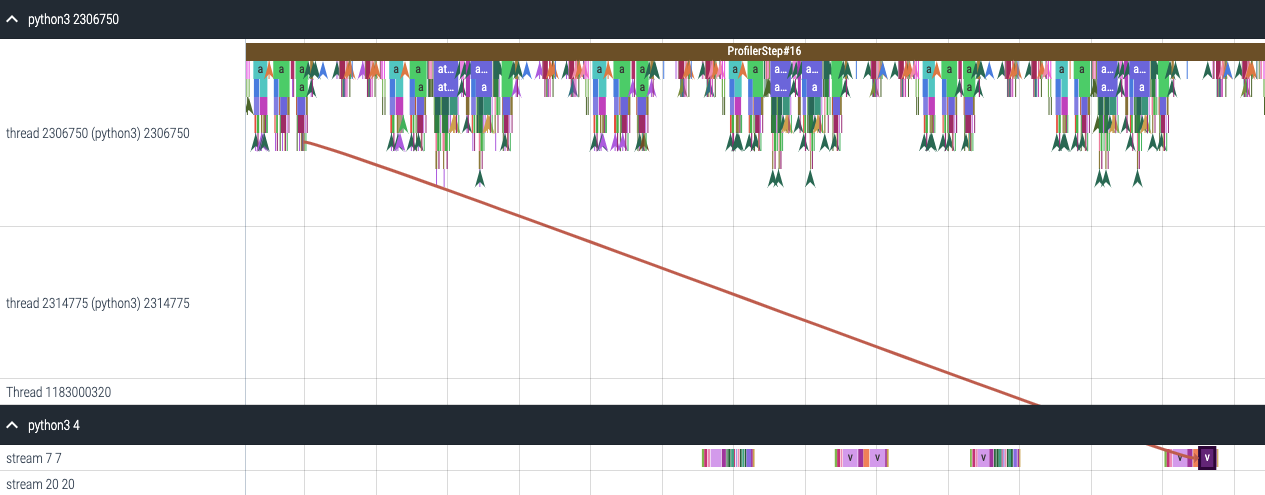
對於在 GPU 上啟動的每個事件,CPU 上都有一個對應的排程事件,例如 CudaLaunchKernel、CudaMemcpyAsync、CudaMemsetAsync。 這些事件通過追蹤中一個共同的關聯 ID 連結 - 請參閱上圖。此功能計算 CPU 執行時事件的持續時間、其對應的 GPU 核心以及啟動延遲,例如 GPU 核心啟動和 CPU 運算元結束之間的時間差。 可以如下產生核心啟動資訊
analyzer = TraceAnalysis(trace_dir="/path/to/trace/dir")
kernel_info_df = analyzer.get_cuda_kernel_launch_stats()
產生的資料框的螢幕截圖如下所示。
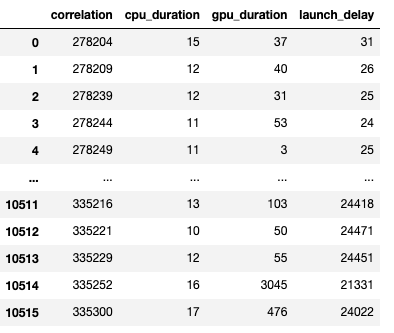
CPU 運算、GPU 核心和啟動延遲的持續時間讓我們可以找到以下內容:
短 GPU 核心 - 持續時間短於對應 CPU 執行時事件的 GPU 核心。
執行時事件離群值 - 持續時間過長的 CPU 執行時事件。
啟動延遲離群值 - 排程時間過長的 GPU 核心。
HTA 為上述三個類別中的每一個產生分佈圖。
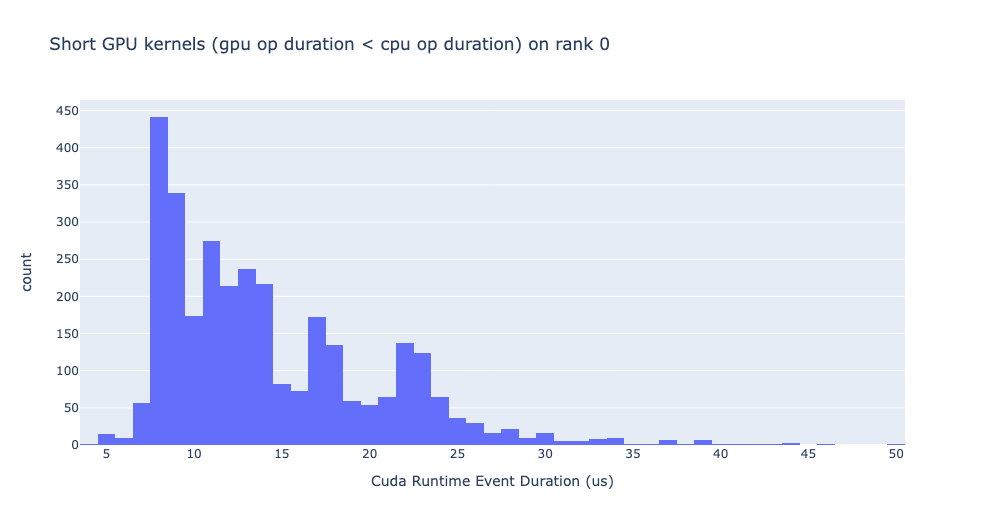
短 GPU 核心
通常,CPU 端的啟動時間範圍為 5-20 微秒。 在某些情況下,GPU 執行時間低於啟動時間本身。 下面的圖有助於我們找出此類實例在程式碼中發生的頻率。
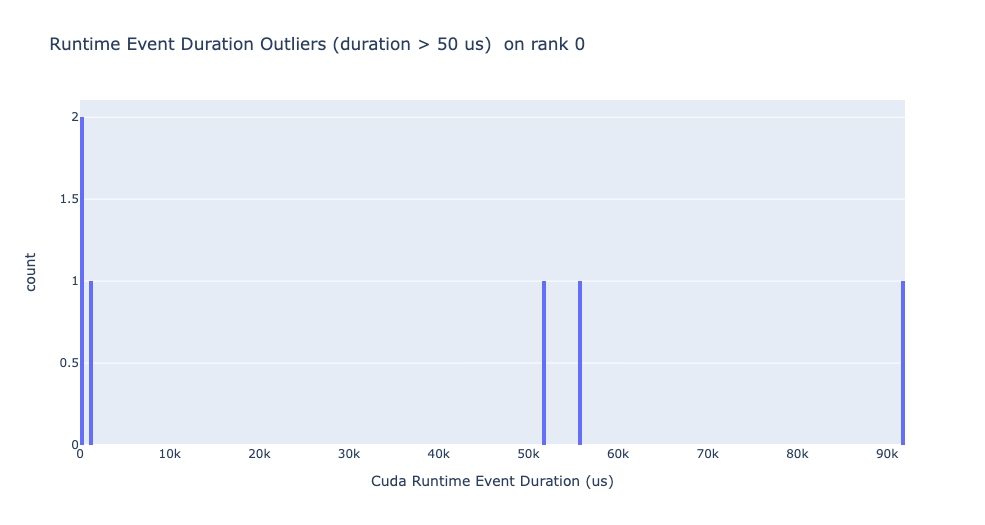
執行時事件離群值
執行時離群值取決於用於對離群值進行分類的截止值,因此 get_cuda_kernel_launch_stats API 提供了 runtime_cutoff 參數來配置該值。
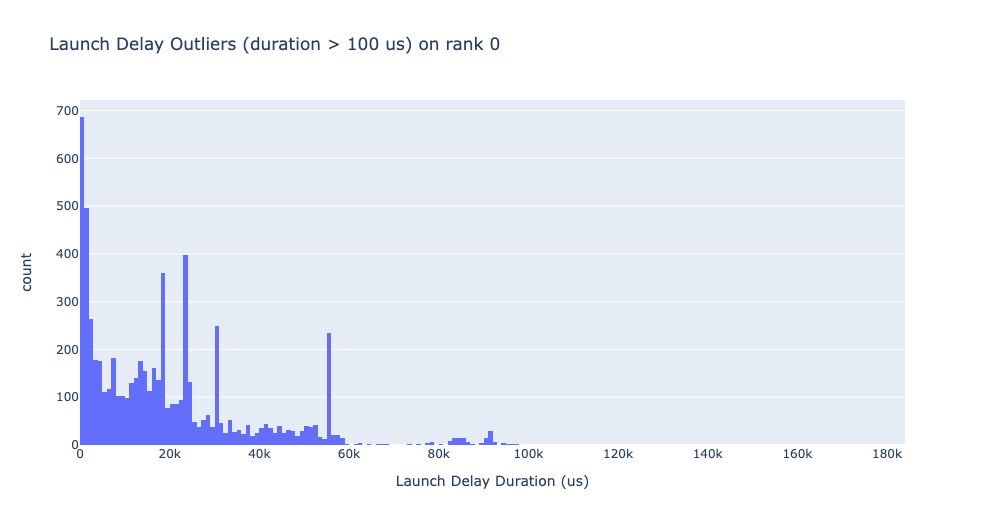
啟動延遲離群值
啟動延遲離群值取決於用於對離群值進行分類的截止值,因此 get_cuda_kernel_launch_stats API 提供了 launch_delay_cutoff 參數來配置該值。
結論¶
在本教學中,您學習了如何安裝和使用 HTA,這是一個性能工具,使您可以分析分散式訓練工作流程中的瓶頸。 若要了解如何使用 HTA 工具執行追蹤差異分析,請參閱 使用整體追蹤分析進行追蹤差異。
