


注意
點擊這裡下載完整的範例程式碼
簡介 || 張量 || Autograd || 建構模型 || TensorBoard 支援 || 訓練模型 || 模型理解
PyTorch 簡介¶
建立於:2021 年 11 月 30 日 | 最後更新:2024 年 1 月 19 日 | 最後驗證:2024 年 11 月 05 日
跟隨以下的影片或在youtube上觀看。
PyTorch 張量¶
從 03:50 開始跟隨影片。
首先,我們導入 pytorch。
import torch
讓我們看看一些基本的張量操作。首先,僅是建立張量的幾種基本方法
z = torch.zeros(5, 3)
print(z)
print(z.dtype)
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
torch.float32
在上面,我們建立一個填充零的 5x3 矩陣,並查詢其資料類型以找出零是 32 位元浮點數,這是預設的 PyTorch。
如果想要整數呢?您可以隨時覆蓋預設值
i = torch.ones((5, 3), dtype=torch.int16)
print(i)
tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=torch.int16)
您可以看到,當我們變更預設值時,張量會在列印時有助於報告這一點。
通常隨機初始化學習權重,通常使用 PRNG 的特定種子,以實現結果的可重複性
torch.manual_seed(1729)
r1 = torch.rand(2, 2)
print('A random tensor:')
print(r1)
r2 = torch.rand(2, 2)
print('\nA different random tensor:')
print(r2) # new values
torch.manual_seed(1729)
r3 = torch.rand(2, 2)
print('\nShould match r1:')
print(r3) # repeats values of r1 because of re-seed
A random tensor:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
A different random tensor:
tensor([[0.4216, 0.0691],
[0.2332, 0.4047]])
Should match r1:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
PyTorch 張量直觀地執行算術運算。可以添加、相乘等等形狀相似的張量。與純量的運算會分佈在張量上
ones = torch.ones(2, 3)
print(ones)
twos = torch.ones(2, 3) * 2 # every element is multiplied by 2
print(twos)
threes = ones + twos # addition allowed because shapes are similar
print(threes) # tensors are added element-wise
print(threes.shape) # this has the same dimensions as input tensors
r1 = torch.rand(2, 3)
r2 = torch.rand(3, 2)
# uncomment this line to get a runtime error
# r3 = r1 + r2
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[2., 2., 2.],
[2., 2., 2.]])
tensor([[3., 3., 3.],
[3., 3., 3.]])
torch.Size([2, 3])
這是一個可用的數學運算的小樣本
r = (torch.rand(2, 2) - 0.5) * 2 # values between -1 and 1
print('A random matrix, r:')
print(r)
# Common mathematical operations are supported:
print('\nAbsolute value of r:')
print(torch.abs(r))
# ...as are trigonometric functions:
print('\nInverse sine of r:')
print(torch.asin(r))
# ...and linear algebra operations like determinant and singular value decomposition
print('\nDeterminant of r:')
print(torch.det(r))
print('\nSingular value decomposition of r:')
print(torch.svd(r))
# ...and statistical and aggregate operations:
print('\nAverage and standard deviation of r:')
print(torch.std_mean(r))
print('\nMaximum value of r:')
print(torch.max(r))
A random matrix, r:
tensor([[ 0.9956, -0.2232],
[ 0.3858, -0.6593]])
Absolute value of r:
tensor([[0.9956, 0.2232],
[0.3858, 0.6593]])
Inverse sine of r:
tensor([[ 1.4775, -0.2251],
[ 0.3961, -0.7199]])
Determinant of r:
tensor(-0.5703)
Singular value decomposition of r:
torch.return_types.svd(
U=tensor([[-0.8353, -0.5497],
[-0.5497, 0.8353]]),
S=tensor([1.1793, 0.4836]),
V=tensor([[-0.8851, -0.4654],
[ 0.4654, -0.8851]]))
Average and standard deviation of r:
(tensor(0.7217), tensor(0.1247))
Maximum value of r:
tensor(0.9956)
關於 PyTorch 張量的強大功能,還有很多需要了解的,包括如何設置它們以在 GPU 上進行平行計算 - 我們將在另一個影片中更深入地介紹。
PyTorch 模型¶
從 10:00 開始跟隨影片。
讓我們討論如何用 PyTorch 表達模型
import torch # for all things PyTorch
import torch.nn as nn # for torch.nn.Module, the parent object for PyTorch models
import torch.nn.functional as F # for the activation function
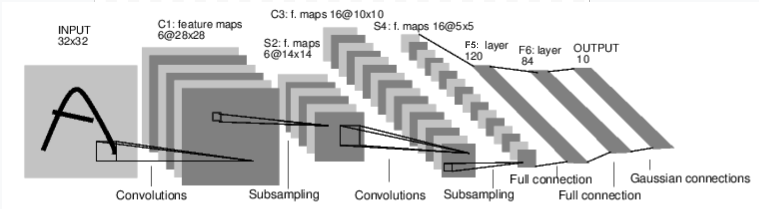
圖:LeNet-5
上面是 LeNet-5 的圖表,LeNet-5 是最早的卷積神經網路之一,也是深度學習爆炸式發展的推動者之一。它旨在讀取手寫數字的小圖像(MNIST 資料集),並正確分類圖像中代表的數字。
這是它工作原理的簡短版本
Layer C1 是一個卷積層,表示它掃描輸入圖像以尋找在訓練期間學習到的特徵。它輸出一個地圖,顯示它在圖像中看到每個學習到的特徵的位置。這個“激活地圖”在 Layer S2 中被降採樣。
Layer C3 是另一個卷積層,這次掃描 C1 的激活地圖以尋找特徵的組合。它還輸出了描述這些特徵組合空間位置的激活地圖,該地圖在 Layer S4 中被降採樣。
最後,末端的完全連接層 F5、F6 和 OUTPUT 是一個分類器,它採用最終的激活地圖,並將其分類為代表 10 個數字的 10 個 bin 之一。
我們如何在程式碼中表達這個簡單的神經網路?
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1 input image channel (black & white), 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
查看此程式碼,您應該能夠發現與上面的圖表的一些結構相似之處。
這展示了典型 PyTorch 模型的結構
它繼承自
torch.nn.Module- 模組可以嵌套 - 實際上,即使是Conv2d和Linear層類別也繼承自torch.nn.Module。一個模型會有一個
__init__()函數,用來實例化其層,並載入它可能需要的任何資料物件(例如,NLP 模型可能會載入一個詞彙表)。一個模型會有一個
forward()函數。 這是實際進行計算的地方:輸入會透過網路層和各種函數傳遞,以產生輸出。除此之外,您可以像建立任何其他 Python 類別一樣,建立您的模型類別,並添加支援模型計算所需的任何屬性和方法。
讓我們實例化這個物件,並透過它執行一個範例輸入。
net = LeNet()
print(net) # what does the object tell us about itself?
input = torch.rand(1, 1, 32, 32) # stand-in for a 32x32 black & white image
print('\nImage batch shape:')
print(input.shape)
output = net(input) # we don't call forward() directly
print('\nRaw output:')
print(output)
print(output.shape)
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
Image batch shape:
torch.Size([1, 1, 32, 32])
Raw output:
tensor([[ 0.0898, 0.0318, 0.1485, 0.0301, -0.0085, -0.1135, -0.0296, 0.0164,
0.0039, 0.0616]], grad_fn=<AddmmBackward0>)
torch.Size([1, 10])
上面發生了一些重要的事情
首先,我們實例化 LeNet 類別,然後我們印出 net 物件。 torch.nn.Module 的子類別會報告它已建立的層及其形狀和參數。 如果您想了解其處理的要點,這可以提供模型的方便概觀。
在它下方,我們建立一個虛擬輸入,代表一個具有 1 個顏色通道的 32x32 影像。 通常,您會載入一個影像圖塊,並將其轉換為這種形狀的張量。
您可能已經注意到我們的張量有一個額外的維度 - *批次維度*。 PyTorch 模型假設它們正在處理批次資料 - 例如,16 個影像圖塊的批次將具有形狀 (16, 1, 32, 32)。 由於我們只使用一張影像,因此我們建立一個形狀為 (1, 1, 32, 32) 的批次。
我們透過像函數一樣呼叫模型來請求推論:net(input)。 這個呼叫的輸出代表模型對輸入表示特定數字的信心。(由於此模型的實例尚未學習任何東西,因此我們不應期望在輸出中看到任何訊號。)查看 output 的形狀,我們可以發現它也具有批次維度,其大小應始終與輸入批次維度相符。 如果我們傳入了 16 個實例的輸入批次,則 output 將具有 (16, 10) 的形狀。
資料集和資料載入器¶
跟隨影片從 14:00 開始。
在下方,我們將示範如何使用 TorchVision 中可供下載的開放存取資料集之一、如何轉換影像以供模型使用,以及如何使用 DataLoader 將批次資料饋送到您的模型。
我們需要做的第一件事是將傳入的影像轉換為 PyTorch 張量。
#%matplotlib inline
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
在這裡,我們為輸入指定了兩個轉換
transforms.ToTensor()將 Pillow 載入的影像轉換為 PyTorch 張量。transforms.Normalize()調整張量的值,使其平均值為零,標準差為 1.0。 大多數激活函數在 x = 0 附近具有最強的梯度,因此將我們的資料集中在那裡可以加快學習速度。 傳遞給轉換的值是資料集中影像的 rgb 值的平均值(第一個元組)和標準差(第二個元組)。 您可以透過執行以下幾行程式碼自行計算這些值- ```
from torch.utils.data import ConcatDataset transform = transforms.Compose([transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root=’./data’, train=True,
download=True, transform=transform)
#將所有訓練影像堆疊在一起成為形狀為 #(50000, 3, 32, 32) 的張量 x = torch.stack([sample[0] for sample in ConcatDataset([trainset])])
#取得每個通道的平均值 mean = torch.mean(x, dim=(0,2,3)) #tensor([0.4914, 0.4822, 0.4465]) std = torch.std(x, dim=(0,2,3)) #tensor([0.2470, 0.2435, 0.2616])
還有更多可用的轉換,包括裁剪、居中、旋轉和反射。
接下來,我們將建立 CIFAR10 資料集的實例。 這是一組 32x32 的彩色影像圖塊,代表 10 種類型的物件:6 種動物(鳥、貓、鹿、狗、青蛙、馬)和 4 種車輛(飛機、汽車、船、卡車)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 459k/170M [00:00<00:37, 4.55MB/s]
4%|4 | 7.60M/170M [00:00<00:03, 43.7MB/s]
10%|# | 17.6M/170M [00:00<00:02, 69.3MB/s]
16%|#6 | 27.8M/170M [00:00<00:01, 82.1MB/s]
22%|##2 | 37.7M/170M [00:00<00:01, 88.4MB/s]
28%|##8 | 48.1M/170M [00:00<00:01, 93.5MB/s]
34%|###4 | 58.4M/170M [00:00<00:01, 96.4MB/s]
40%|#### | 68.5M/170M [00:00<00:01, 97.9MB/s]
46%|####6 | 78.4M/170M [00:00<00:00, 98.3MB/s]
52%|#####1 | 88.3M/170M [00:01<00:00, 96.6MB/s]
57%|#####7 | 98.0M/170M [00:01<00:00, 95.3MB/s]
63%|######3 | 108M/170M [00:01<00:00, 95.8MB/s]
69%|######9 | 118M/170M [00:01<00:00, 97.7MB/s]
75%|#######5 | 128M/170M [00:01<00:00, 99.3MB/s]
81%|########1 | 139M/170M [00:01<00:00, 101MB/s]
87%|########7 | 149M/170M [00:01<00:00, 102MB/s]
94%|#########3| 160M/170M [00:01<00:00, 102MB/s]
100%|#########9| 170M/170M [00:01<00:00, 103MB/s]
100%|##########| 170M/170M [00:01<00:00, 93.7MB/s]
注意
當您執行上面的單元格時,可能需要一些時間才能下載資料集。
這是在 PyTorch 中建立資料集物件的範例。 可下載的資料集(如上面的 CIFAR-10)是 torch.utils.data.Dataset 的子類別。 PyTorch 中的 Dataset 類別包括 TorchVision、Torchtext 和 TorchAudio 中的可下載資料集,以及實用程式資料集類別,例如 torchvision.datasets.ImageFolder,它將讀取標記影像的資料夾。 您也可以建立自己的 Dataset 子類別。
當我們實例化我們的資料集時,我們需要告訴它一些事情
我們希望資料前往的檔案系統路徑。
我們是否正在使用此集合進行訓練;大多數資料集將分為訓練和測試子集。
如果我們尚未下載資料集,我們是否要下載它。
我們想要套用至資料的轉換。
一旦您的資料集準備就緒,您就可以將其提供給 DataLoader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
Dataset 子類別封裝對資料的存取,並專門用於它所服務的資料類型。DataLoader 對於資料一無所知,但會將 Dataset 提供的輸入張量組織成具有您指定參數的批次。
在上面的範例中,我們要求 DataLoader 從 trainset 提供給我們 4 張影像的批次,隨機化它們的順序(shuffle=True),並且我們告訴它啟動兩個工作人員以從磁碟載入資料。
視覺化您的 DataLoader 提供的批次是一個好習慣
import matplotlib.pyplot as plt
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-0.49473685..1.5632443].
ship car horse ship
執行上述儲存格後,您應該會看到一條包含四張圖片的條帶,以及每張圖片的正確標籤。
訓練您的 PyTorch 模型¶
請依照影片從 17:10 開始觀看。
讓我們把所有部分整合在一起,並訓練一個模型
#%matplotlib inline
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
首先,我們需要訓練和測試資料集。如果您還沒有下載,請執行以下儲存格以確保資料集已下載。(可能需要一分鐘。)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
我們將對來自 DataLoader 的輸出執行檢查
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

cat cat deer frog
這就是我們要訓練的模型。 如果它看起來很熟悉,那是因為它是 LeNet 的變體 - 在本影片前面已討論過 - 適用於 3 色圖像。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
我們需要的最後要素是損失函數和最佳化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
正如本影片前面所討論的,損失函數是用於衡量模型的預測與我們理想輸出的差距。 交叉熵損失是分類模型(如我們的模型)的典型損失函數。
**最佳化器**是驅動學習的工具。 在這裡,我們建立了一個實現*隨機梯度下降*的最佳化器,這是最直接的最佳化演算法之一。 除了演算法的參數,如學習率 (lr) 和動量之外,我們還傳入 net.parameters(),它是模型中所有學習權重的集合 - 這也是最佳化器調整的內容。
最後,所有這些都組裝到訓練迴圈中。 繼續執行此儲存格,因為它可能需要幾分鐘才能執行
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
[1, 2000] loss: 2.195
[1, 4000] loss: 1.876
[1, 6000] loss: 1.655
[1, 8000] loss: 1.576
[1, 10000] loss: 1.519
[1, 12000] loss: 1.466
[2, 2000] loss: 1.421
[2, 4000] loss: 1.376
[2, 6000] loss: 1.336
[2, 8000] loss: 1.335
[2, 10000] loss: 1.326
[2, 12000] loss: 1.270
Finished Training
在這裡,我們僅執行 **2 個訓練 epoch**(第 1 行) - 也就是說,對訓練資料集進行兩次傳遞。 每次傳遞都有一個內部迴圈,它**迭代訓練資料**(第 4 行),提供批次轉換後的輸入圖像及其正確的標籤。
**將梯度歸零**(第 9 行)是一個重要的步驟。 梯度會在一個批次中累積; 如果我們沒有為每個批次重設它們,它們將繼續累積,這將提供不正確的梯度值,使學習無法進行。
在第 12 行,我們**要求模型對此批次進行預測**。 在下一行(第 13 行),我們計算損失 - outputs(模型預測)和 labels(正確輸出)之間的差異。
在第 14 行,我們執行 backward() 傳遞,並計算將指導學習的梯度。
在第 15 行,最佳化器執行一個學習步驟 - 它使用來自 backward() 呼叫的梯度,朝它認為會減少損失的方向推動學習權重。
迴圈的其餘部分對 epoch 編號、已完成的訓練實例數量以及在訓練迴圈中收集的損失進行了一些輕微的報告。
**當您執行上面的儲存格時,**您應該會看到類似於以下的內容
[1, 2000] loss: 2.235
[1, 4000] loss: 1.940
[1, 6000] loss: 1.713
[1, 8000] loss: 1.573
[1, 10000] loss: 1.507
[1, 12000] loss: 1.442
[2, 2000] loss: 1.378
[2, 4000] loss: 1.364
[2, 6000] loss: 1.349
[2, 8000] loss: 1.319
[2, 10000] loss: 1.284
[2, 12000] loss: 1.267
Finished Training
請注意,損失是單調遞減的,這表明我們的模型正在繼續提高其在訓練資料集上的效能。
作為最後一步,我們應該檢查模型是否確實進行了*一般*學習,而不僅僅是「記憶」資料集。 這稱為 **過度擬合,** 通常表示資料集太小(沒有足夠的範例進行一般學習),或者模型擁有的學習參數多於正確建立資料集模型所需的參數。
這就是資料集被分成訓練和測試子集的原因 - 為了測試模型的一般性,我們要求它對未經過訓練的資料進行預測
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 54 %
如果您按照說明進行操作,您應該會看到該模型目前大約有 50% 的準確性。 這並非最先進的,但遠遠優於我們從隨機輸出中期望的 10% 準確性。 這表明模型中確實發生了一些一般學習。
**腳本的總運行時間:**(1 分鐘 55.528 秒)
