


注意
點擊這裡下載完整的範例程式碼
學習基礎知識 || 快速入門 || 張量 || 數據集和數據加載器 || 轉換 || 建立模型 || Autograd || 優化 || 保存和加載模型
使用 torch.autograd 進行自動微分¶
創建於:2021 年 2 月 10 日 | 最後更新:2024 年 1 月 16 日 | 最後驗證:2024 年 11 月 05 日
在訓練神經網路時,最常使用的演算法是反向傳播。在這種演算法中,參數(模型權重)根據損失函數相對於給定參數的梯度進行調整。
為了計算這些梯度,PyTorch 有一個內建的微分引擎,稱為 torch.autograd。它支持對任何計算圖進行梯度的自動計算。
考慮最簡單的單層神經網路,具有輸入 x、參數 w 和 b 以及一些損失函數。它可以用以下方式在 PyTorch 中定義
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
張量、函數和計算圖¶
此程式碼定義了以下計算圖
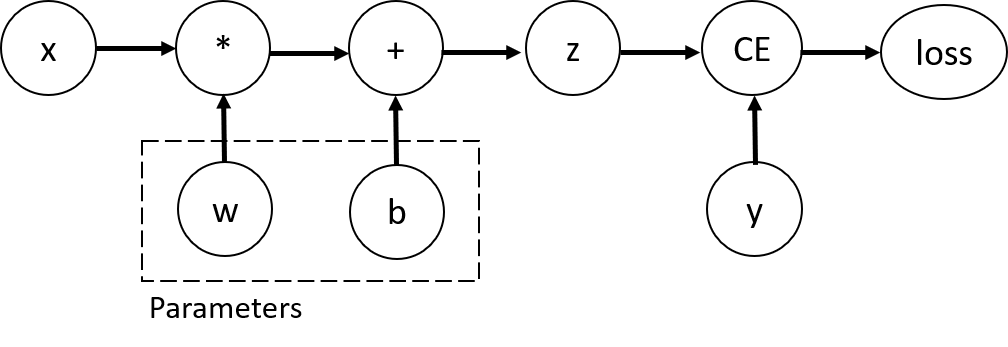
在這個網路中,w 和 b 是參數,我們需要優化。因此,我們需要能夠計算損失函數相對於這些變數的梯度。為了做到這一點,我們設置這些張量的 requires_grad 屬性。
注意
您可以在創建張量時設置 requires_grad 的值,或者稍後使用 x.requires_grad_(True) 方法。
我們應用於張量以構建計算圖的函數實際上是 Function 類別的對象。此物件知道如何在前向方向計算函數,以及如何在反向傳播步驟期間計算其導數。對反向傳播函數的引用儲存在張量的 grad_fn 屬性中。您可以在文檔中找到有關 Function 的更多資訊。
Gradient function for z = <AddBackward0 object at 0x7fd0c07d18d0>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward0 object at 0x7fd0c07d0ee0>
計算梯度¶
為了優化神經網路中參數的權重,我們需要計算損失函數相對於參數的導數,也就是說,我們需要 \(\frac{\partial loss}{\partial w}\) 和 \(\frac{\partial loss}{\partial b}\) 在 x 和 y 的一些固定值下。為了計算這些導數,我們調用 loss.backward(),然後從 w.grad 和 b.grad 中檢索值
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.3313, 0.0626, 0.2530],
[0.3313, 0.0626, 0.2530],
[0.3313, 0.0626, 0.2530],
[0.3313, 0.0626, 0.2530],
[0.3313, 0.0626, 0.2530]])
tensor([0.3313, 0.0626, 0.2530])
注意
我們只能獲得計算圖葉節點的
grad屬性,這些節點的requires_grad屬性設置為True。對於圖中的所有其他節點,梯度將不可用。基於效能考量,對於給定的圖,我們只能使用
backward進行一次梯度計算。如果我們需要在同一個圖上多次呼叫backward,我們需要將retain_graph=True傳遞給backward呼叫。
停用梯度追蹤¶
預設情況下,所有 requires_grad=True 的 tensors 都會追蹤它們的計算歷史並支援梯度計算。但是,在某些情況下,我們不需要這樣做,例如,當我們已經訓練好模型,只想將其應用於某些輸入資料時,也就是我們只想透過網路進行前向計算。我們可以透過將我們的計算程式碼包圍在 torch.no_grad() 區塊中來停止追蹤計算。
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
True
False
實現相同結果的另一種方法是在 tensor 上使用 detach() 方法。
False
- 您可能想要停用梯度追蹤的原因如下:
將您的神經網路中的某些參數標記為**凍結參數**。
當您僅執行前向傳遞時,可以**加速計算**,因為對不追蹤梯度的 tensors 進行計算會更有效率。
更多關於計算圖的資訊¶
從概念上講,autograd 會在一個有向無環圖 (DAG) 中記錄資料 (tensors) 和所有已執行的操作(以及產生的新 tensors),該圖由 Function 物件組成。在這個 DAG 中,葉節點是輸入 tensors,根節點是輸出 tensors。透過追蹤從根節點到葉節點的圖,您可以使用鏈式法則自動計算梯度。
在前向傳遞中,autograd 同時執行兩件事:
執行請求的操作以計算結果 tensor
在 DAG 中維護操作的梯度函數。
當在 DAG 根節點上呼叫 .backward() 時,反向傳遞啟動。autograd 然後:
從每個
.grad_fn計算梯度,將它們累積到相應 tensor 的
.grad屬性中使用鏈式法則,一直傳播到葉節點 tensors。
注意
**DAGs 在 PyTorch 中是動態的** 需要注意的重要一點是,該圖是從頭開始重新建立的;在每次呼叫 .backward() 後,autograd 開始填充一個新圖。這正是允許您在模型中使用控制流程語句的原因;如果需要,您可以在每次迭代中更改形狀、大小和操作。
選讀:Tensor 梯度和 Jacobian 乘積¶
在許多情況下,我們有一個純量損失函數,並且需要計算關於某些參數的梯度。但是,在某些情況下,輸出函數是一個任意 tensor。在這種情況下,PyTorch 允許您計算所謂的 **Jacobian 乘積**,而不是實際的梯度。
對於向量函數 \(\vec{y}=f(\vec{x})\),其中 \(\vec{x}=\langle x_1,\dots,x_n\rangle\) 且 \(\vec{y}=\langle y_1,\dots,y_m\rangle\),\(\vec{y}\) 關於 \(\vec{x}\) 的梯度由 **Jacobian 矩陣** 給出:
PyTorch 允許您計算 **Jacobian 乘積** \(v^T\cdot J\),而不是計算 Jacobian 矩陣本身,對於給定的輸入向量 \(v=(v_1 \dots v_m)\)。這是透過使用 \(v\) 作為參數呼叫 backward 來實現的。\(v\) 的大小應與我們要計算乘積的原始 tensor 的大小相同。
inp = torch.eye(4, 5, requires_grad=True)
out = (inp+1).pow(2).t()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"First call\n{inp.grad}")
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nSecond call\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"\nCall after zeroing gradients\n{inp.grad}")
First call
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
Second call
tensor([[8., 4., 4., 4., 4.],
[4., 8., 4., 4., 4.],
[4., 4., 8., 4., 4.],
[4., 4., 4., 8., 4.]])
Call after zeroing gradients
tensor([[4., 2., 2., 2., 2.],
[2., 4., 2., 2., 2.],
[2., 2., 4., 2., 2.],
[2., 2., 2., 4., 2.]])
請注意,當我們使用相同的參數第二次呼叫 backward 時,梯度的值是不同的。發生這種情況是因為在執行 backward 傳播時,PyTorch 會**累積梯度**,也就是說,計算出的梯度的值會添加到計算圖所有葉節點的 grad 屬性中。如果您想計算正確的梯度,則需要在之前將 grad 屬性歸零。在真實的訓練中,*優化器* 可以幫助我們做到這一點。
注意
之前我們呼叫 backward() 函數時沒有參數。這本質上等同於呼叫 backward(torch.tensor(1.0)),這是在純量值函數(例如神經網路訓練期間的損失)的情況下計算梯度的一種有用的方法。
