


從第一原理理解 PyTorch Intel CPU 效能¶
建立於:2022 年 4 月 15 日 | 最後更新:2025 年 1 月 23 日 | 最後驗證:2024 年 11 月 05 日
關於使用 Intel® Extension for PyTorch* 最佳化的 TorchServe 推論框架的案例研究。
作者:Min Jean Cho, Mark Saroufim
審閱者:Ashok Emani, Jiong Gong
在 CPU 上獲得強大的開箱即用深度學習效能可能很棘手,但如果您了解影響效能的主要問題、如何測量它們以及如何解決它們,就會容易得多。
總而言之
問題 |
如何測量 |
解決方案 |
瓶頸 GEMM 執行單元 |
透過核心綁定將線程親和性設定為實體核心,避免使用邏輯核心 |
|
非一致性記憶體存取 (NUMA) |
|
透過核心綁定將線程親和性設定為特定插槽,避免跨插槽計算 |
GEMM(通用矩陣乘法)在融合乘加 (FMA) 或點積 (DP) 執行單元上執行,這些單元將受到瓶頸,並在啟用超線程時導致線程等待/同步屏障處旋轉 - 因為使用邏輯核心會導致所有工作線程的並發性不足,因為每個邏輯線程爭奪相同的核心資源。相反,如果我們每個實體核心使用 1 個線程,我們就可以避免這種爭用。因此,我們通常建議透過核心綁定將 CPU 線程親和性設定為實體核心,來避免邏輯核心。
多插槽系統具有非一致性記憶體存取 (NUMA),這是一種共享記憶體架構,描述了主記憶體模組相對於處理器的放置位置。但是,如果一個進程不是 NUMA 感知的,則在執行時線程透過 Intel Ultra Path Interconnect (UPI) 跨插槽遷移時,經常會存取緩慢的遠端記憶體。我們透過將 CPU 線程親和性設定為特定插槽,透過核心綁定來解決這個問題。
記住這些原則,適當的 CPU 執行時配置可以顯著提高開箱即用的效能。
在本部落格中,我們將帶您了解您應該注意的 CPU 效能調整指南中的重要執行時配置,解釋它們的工作原理,如何分析它們以及如何透過易於使用的 啟動腳本 將它們整合到像 TorchServe 這樣的模型服務框架中,我們已經 原生整合 1。
我們將從第一原理以視覺化的方式解釋所有這些想法,並提供大量的效能分析,並向您展示我們如何應用我們的學習成果來改善 TorchServe 的開箱即用 CPU 效能。
必須透過在 config.properties 中設定 cpu_launcher_enable=true 來顯式啟用該功能。
避免將邏輯核心用於深度學習¶
對於深度學習工作負載,避免使用邏輯核心通常會提高效能。為了理解這一點,讓我們回顧一下 GEMM。
最佳化 GEMM 可最佳化深度學習
深度學習訓練或推論中的大部分時間都花費在數百萬次重複的 GEMM 運算上,這是全連接層的核心。自多層感知器 (MLP) 被證明為任何連續函數的通用逼近器以來,全連接層已經使用了數十年。任何 MLP 都可以完全表示為 GEMM。甚至可以使用 Toepliz 矩陣將卷積表示為 GEMM。
回到最初的主題,大多數 GEMM 運算子受益於使用非超線程,因為深度學習訓練或推論中的大部分時間都花費在數百萬次重複的 GEMM 運算上,這些運算在超線程核心共享的融合乘加 (FMA) 或點積 (DP) 執行單元上運行。啟用超線程後,OpenMP 線程將爭奪相同的 GEMM 執行單元。
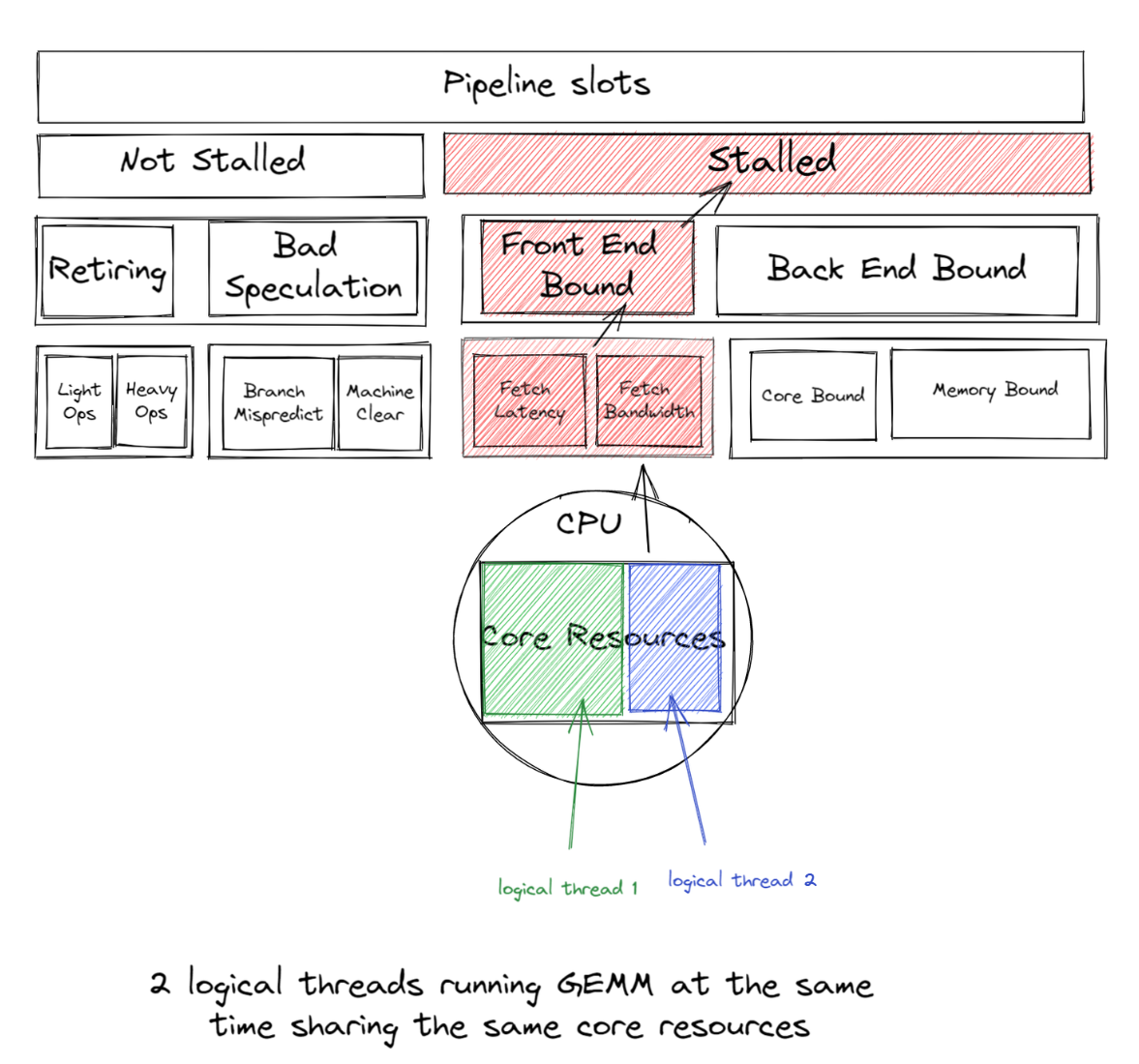
如果 2 個邏輯線程同時運行 GEMM,它們將共享相同的核心資源,從而導致前端受限,因此這種前端受限的開銷大於同時運行兩個邏輯線程所獲得的收益。
因此,我們通常建議避免將邏輯核心用於深度學習工作負載,以獲得良好的效能。預設情況下,啟動腳本僅使用實體核心;但是,使用者可以透過簡單地切換 --use_logical_core 啟動腳本旋鈕來輕鬆地試驗邏輯核心與實體核心。
練習
我們將使用以下範例饋送 ResNet50 虛擬張量
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
data = torch.rand(1, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
start = time.time()
for _ in range(100):
model(data)
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
在整個部落格中,我們將使用 Intel® VTune™ Profiler 來分析和驗證最佳化。我們將在配備兩顆 Intel(R) Xeon(R) Platinum 8180M CPU 的機器上執行所有練習。CPU 資訊如圖 2.1 所示。
環境變數 OMP_NUM_THREADS 用於設定平行區域的執行緒數量。我們將比較 OMP_NUM_THREADS=2 與 (1) 使用邏輯核心 和 (2) 僅使用物理核心。
兩個 OpenMP 執行緒都試圖利用超執行緒核心 (0, 56) 共享的相同 GEMM 執行單元
我們可以透過在 Linux 上執行 htop 命令來視覺化此行為,如下所示。
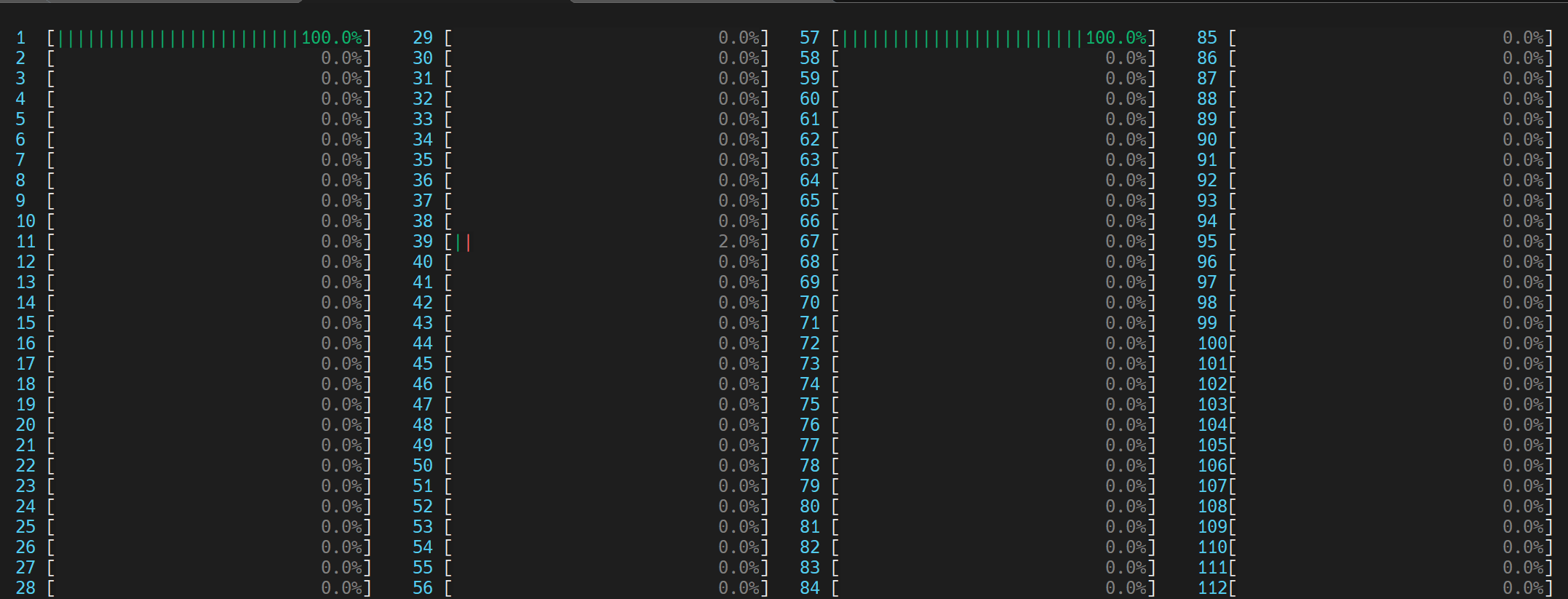
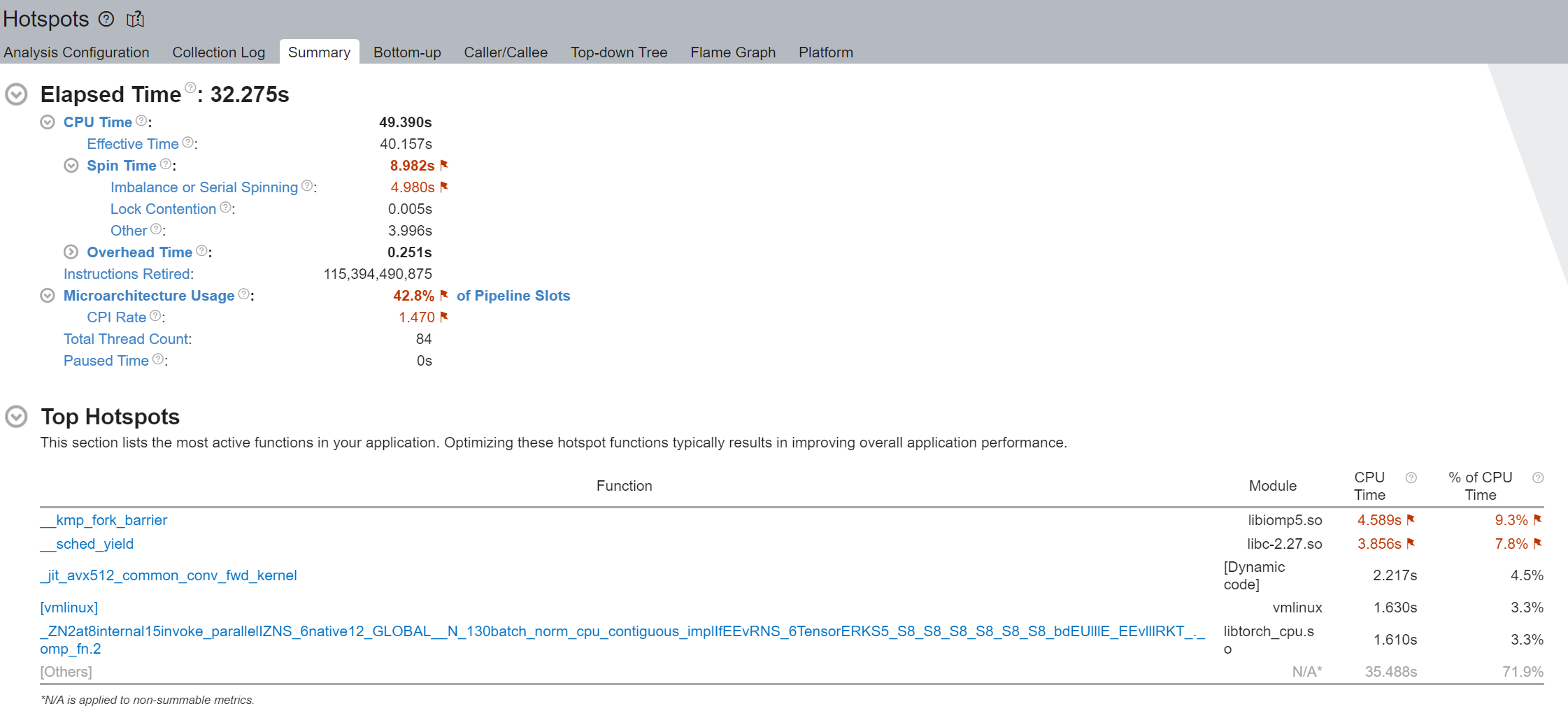
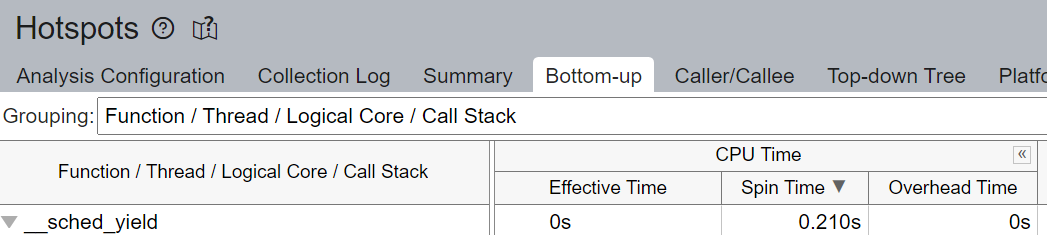
我們注意到 Spin Time 被標記,並且 Imbalance 或 Serial Spinning 佔了大部分 - 在總共 8.982 秒中佔了 4.980 秒。使用邏輯核心時發生的 Imbalance 或 Serial Spinning 是因為工作執行緒的並行性不足,因為每個邏輯執行緒都爭奪相同的核心資源。
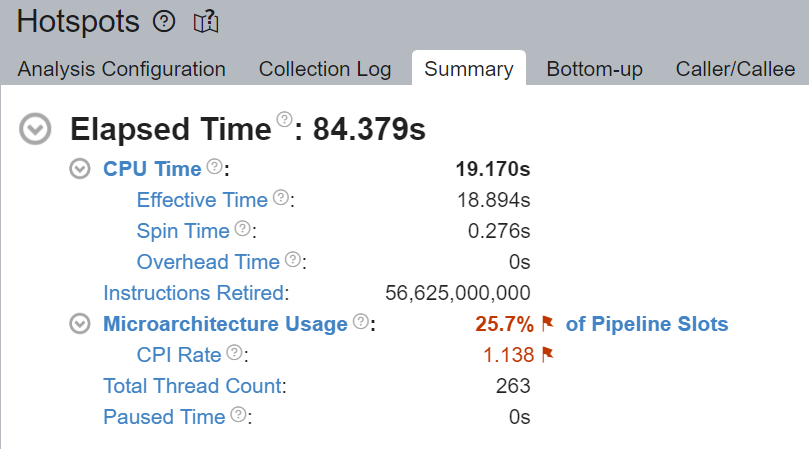
執行摘要的 Top Hotspots 部分表明 __kmp_fork_barrier 佔用了 4.589 秒的 CPU 時間 - 在 9.33% 的 CPU 執行時間內,執行緒僅僅因為執行緒同步而在這個 barrier 處空轉。
每個 OpenMP 執行緒都利用各自物理核心 (0,1) 中的 GEMM 執行單元
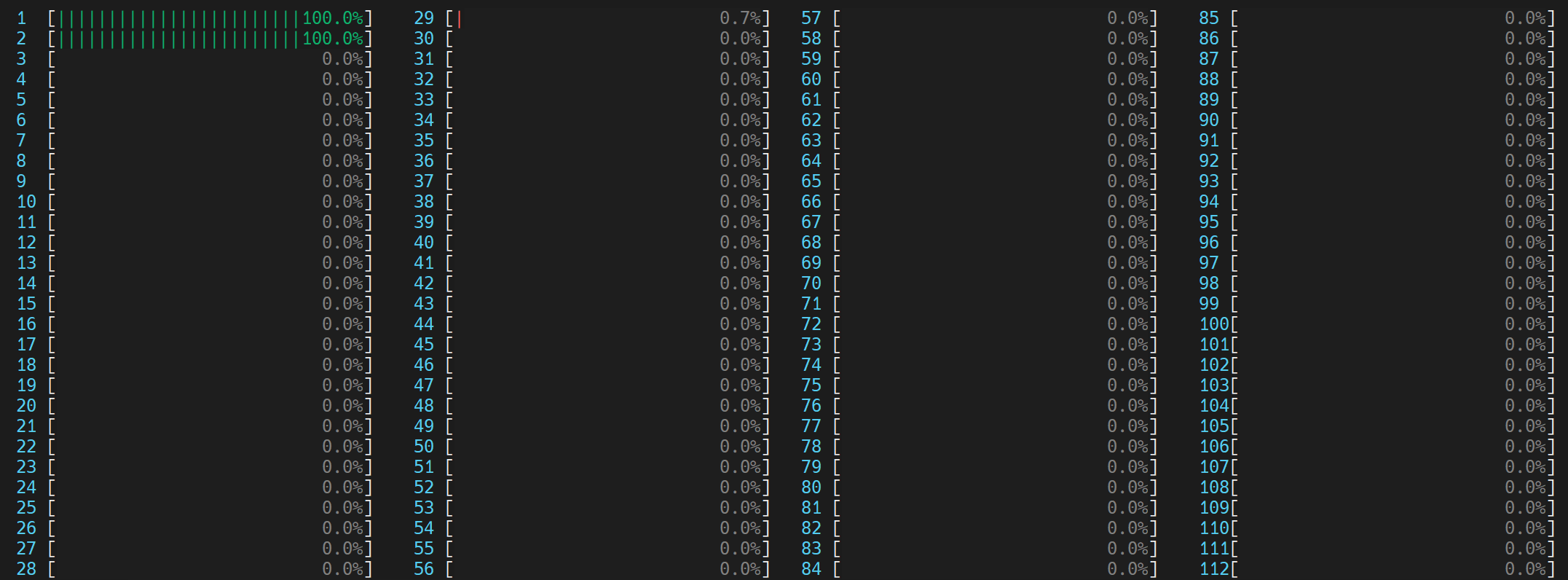
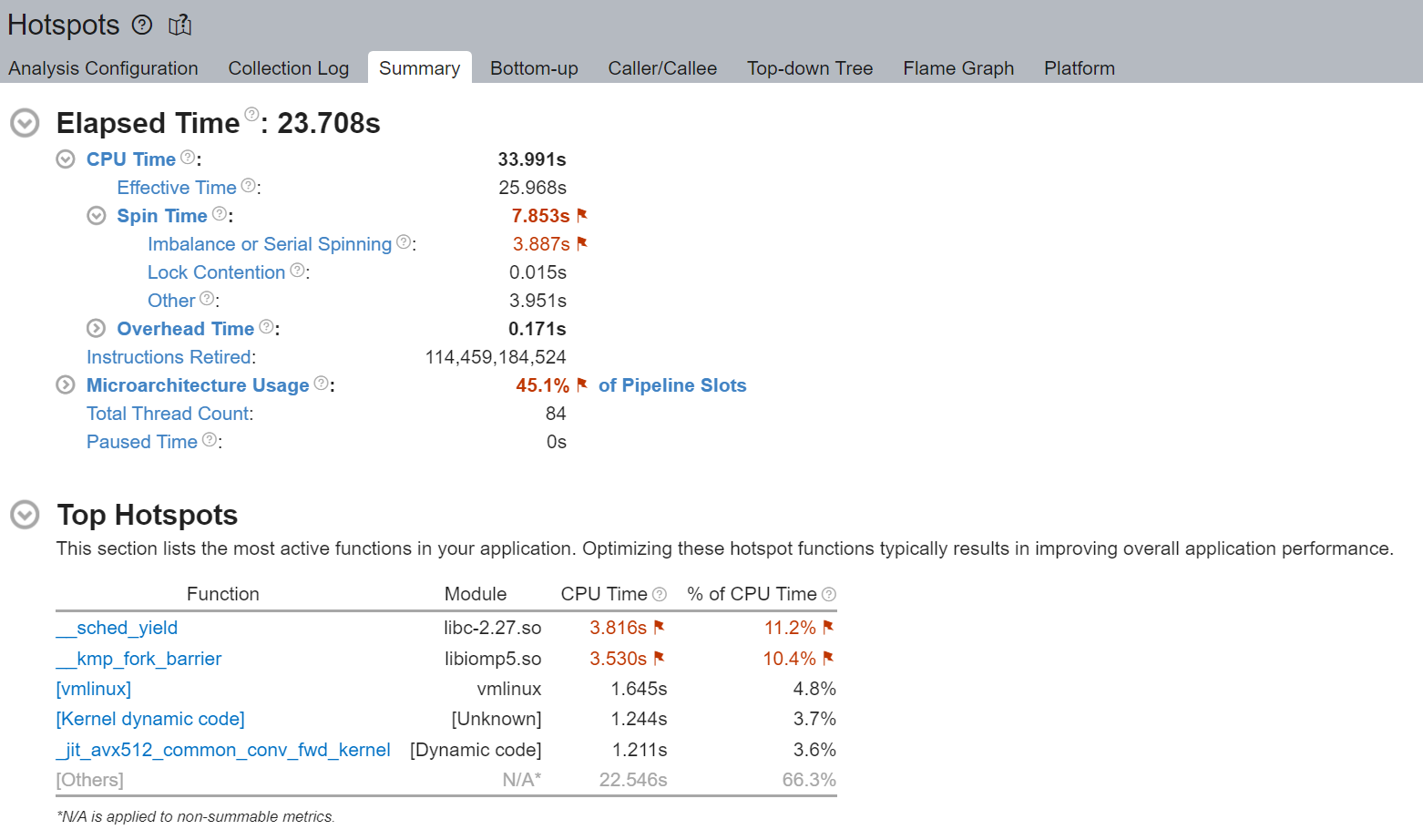
我們首先注意到,透過避免使用邏輯核心,執行時間從 32 秒減少到 23 秒。 雖然仍然存在一些不可忽略的 Imbalance 或 Serial Spinning,但我們注意到從 4.980 秒到 3.887 秒的相對改善。
透過不使用邏輯執行緒(而是每個物理核心使用 1 個執行緒),我們避免了邏輯執行緒爭奪相同的核心資源。Top Hotspots 部分也顯示 __kmp_fork_barrier 時間從 4.589 秒到 3.530 秒的相對改善。
本機記憶體存取始終比遠端記憶體存取更快¶
我們通常建議將進程繫結到本機插槽,以便該進程不會跨插槽遷移。通常這樣做的目的是利用本機記憶體上的高速快取,並避免遠端記憶體存取,後者速度可能會慢約 2 倍。
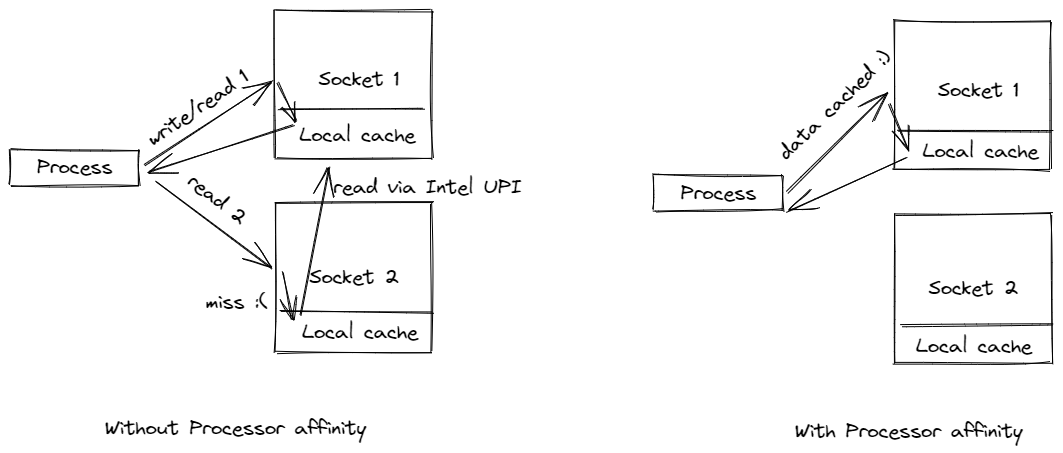
圖 1. 雙插槽配置
圖 1 顯示了一個典型的雙插槽配置。請注意,每個插槽都有自己的本機記憶體。插槽透過 Intel Ultra Path Interconnect (UPI) 相互連接,這允許每個插槽存取另一個插槽的本機記憶體,稱為遠端記憶體。本機記憶體存取始終比遠端記憶體存取更快。
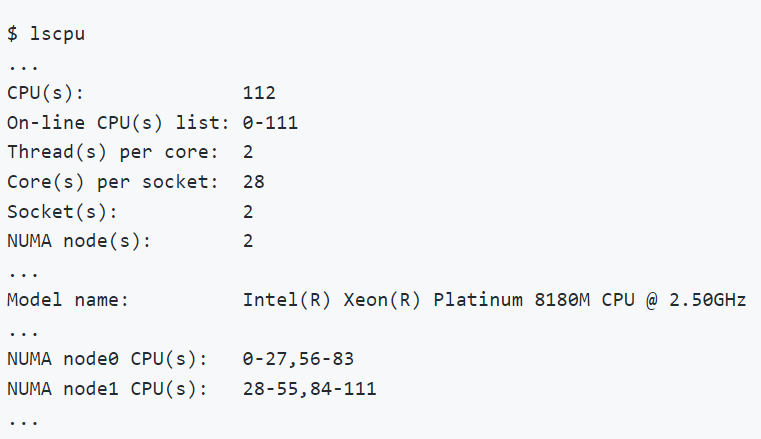
圖 2.1. CPU 資訊
使用者可以透過在其 Linux 機器上執行 lscpu 命令來取得他們的 CPU 資訊。圖 2.1 顯示了在具有兩顆 Intel(R) Xeon(R) Platinum 8180M CPU 的機器上執行 lscpu 的範例。請注意,每個插槽有 28 個核心,每個核心有 2 個執行緒(即,超執行緒已啟用)。換句話說,除了 28 個物理核心之外,還有 28 個邏輯核心,每個插槽總共有 56 個核心。並且有 2 個插槽,總共有 112 個核心(Thread(s) per core x Core(s) per socket x Socket(s))。
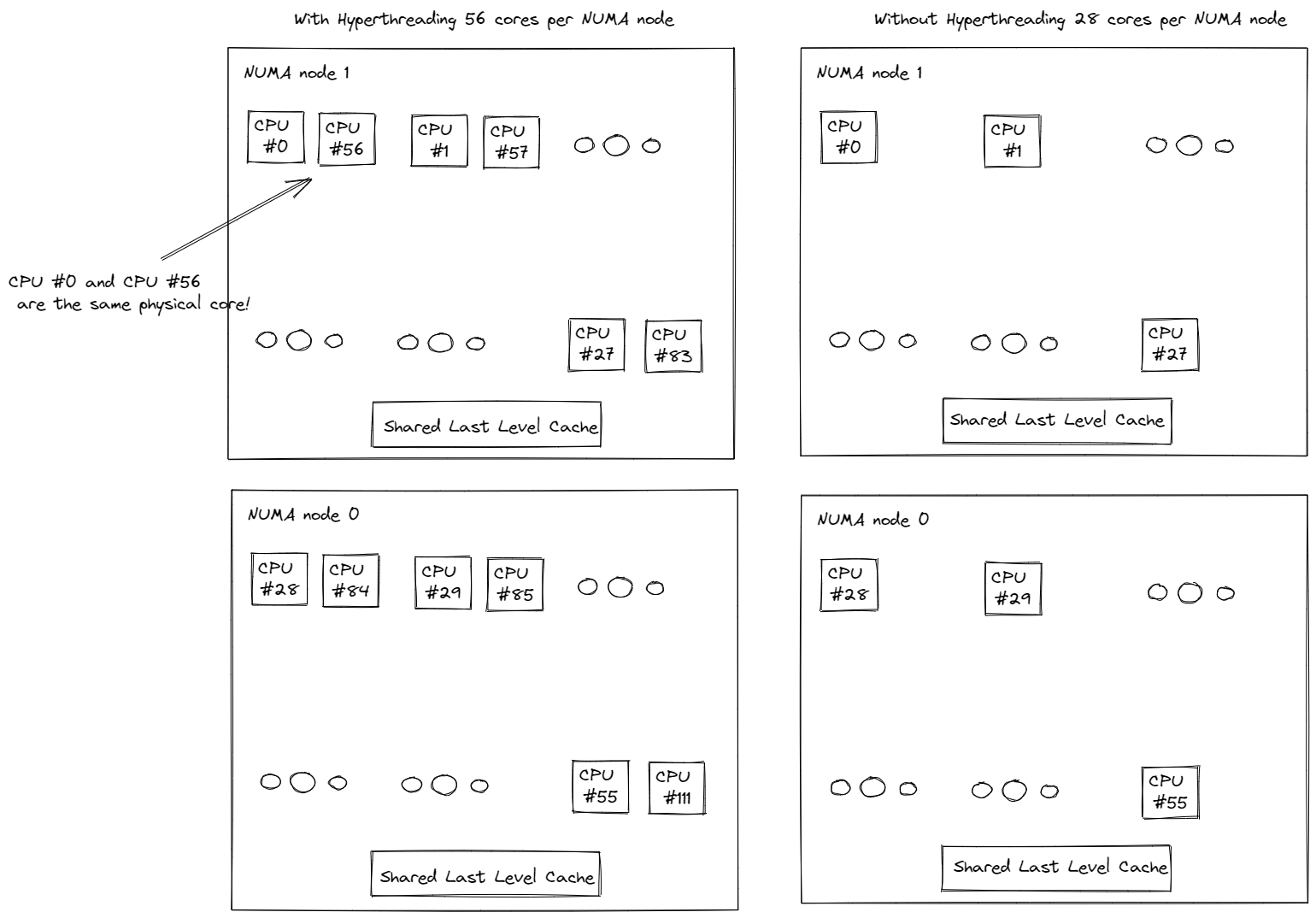
圖 2.2. CPU 資訊
這 2 個插槽分別映射到 2 個 NUMA 節點(NUMA 節點 0,NUMA 節點 1)。物理核心的索引優先於邏輯核心。如圖 2.2 所示,第一個插槽上的前 28 個物理核心 (0-27) 和前 28 個邏輯核心 (56-83) 位於 NUMA 節點 0 上。第二個插槽上的第二個 28 個物理核心 (28-55) 和第二個 28 個邏輯核心 (84-111) 位於 NUMA 節點 1 上。同一插槽上的核心共享本機記憶體和最後一層快取 (LLC),這比透過 Intel UPI 的跨插槽通訊快得多。
現在我們了解了 NUMA、跨插槽 (UPI) 流量、多處理器系統中的本機與遠端記憶體存取,讓我們來分析和驗證我們的理解。
練習
我們將重複使用上面的 ResNet50 範例。
由於我們沒有將執行緒釘選到特定插槽的處理器核心,因此作業系統會定期在位於不同插槽的處理器核心上排程執行緒。
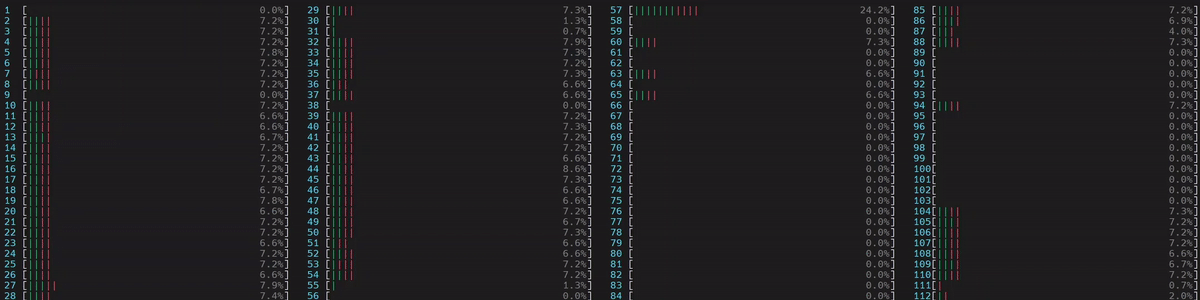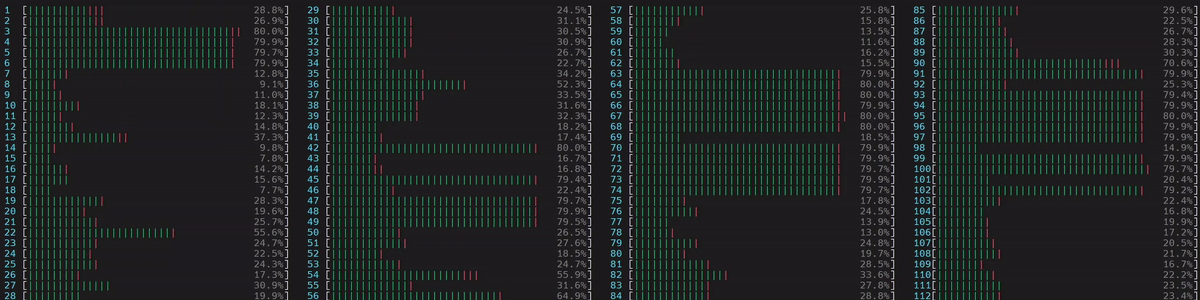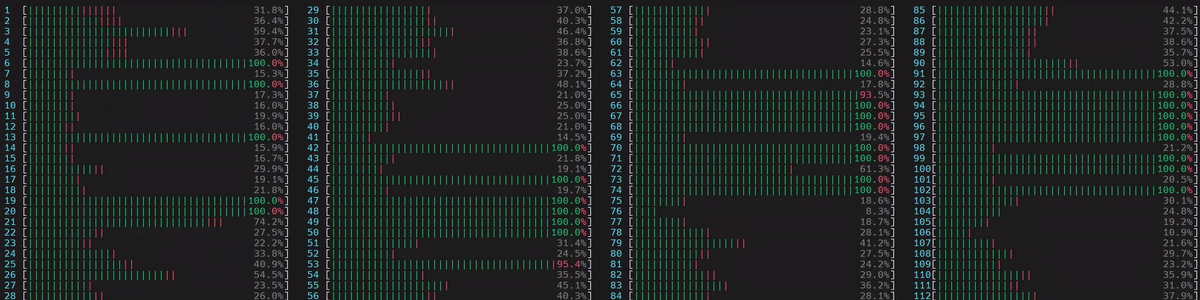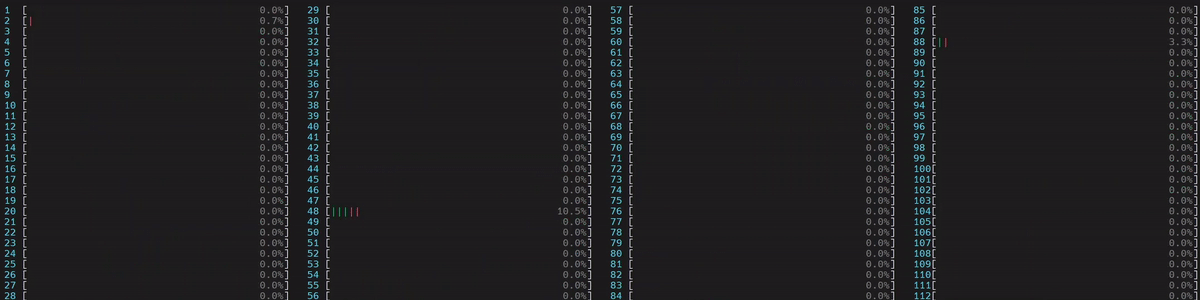
圖 3. 非 NUMA 感知應用程式的 CPU 使用率。啟動了 1 個主 worker 執行緒,然後它在所有核心(包括邏輯核心)上啟動了物理核心數量 (56) 的執行緒。
(旁註:如果執行緒數量未由 torch.set_num_threads 設定,則預設的執行緒數量是啟用超執行緒的系統中的物理核心數量。這可以透過 torch.get_num_threads 驗證。因此,我們看到上面大約一半的核心正忙於執行範例腳本。)

圖 4. 非均勻記憶體存取分析圖
圖 4 比較了隨時間變化的本機與遠端記憶體存取。我們驗證了遠端記憶體的使用情況,這可能會導致次佳的效能。
設定執行緒親和性以減少遠端記憶體存取和跨插槽 (UPI) 流量
將執行緒釘選到同一插槽上的核心有助於保持記憶體存取的局部性。 在此範例中,我們將釘選到第一個 NUMA 節點 (0-27) 上的物理核心。 透過啟動腳本,使用者只需切換 --node_id 啟動腳本旋鈕,即可輕鬆地試用 NUMA 節點配置。
現在讓我們視覺化 CPU 使用率。
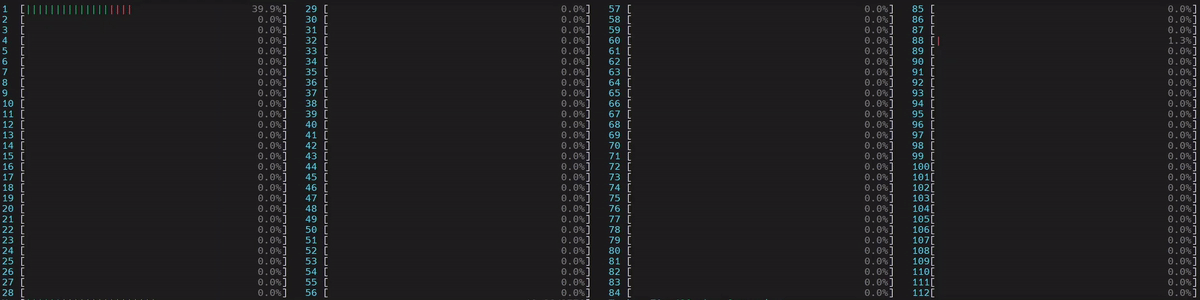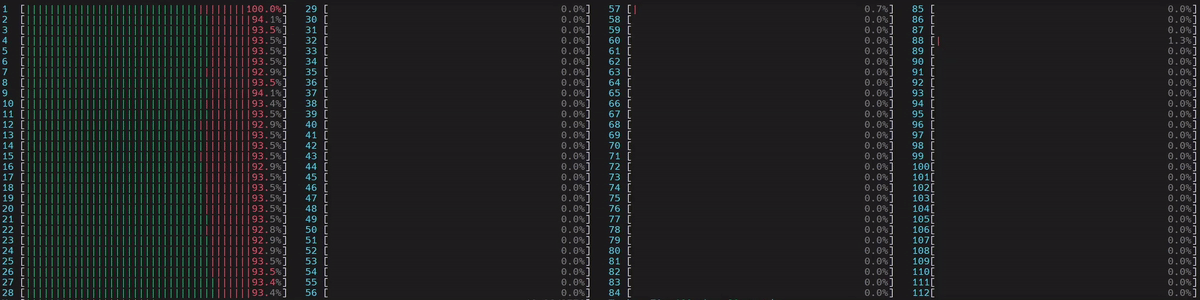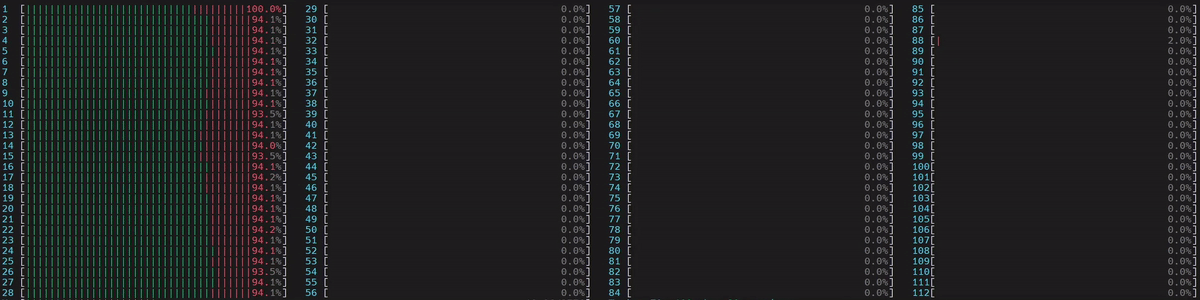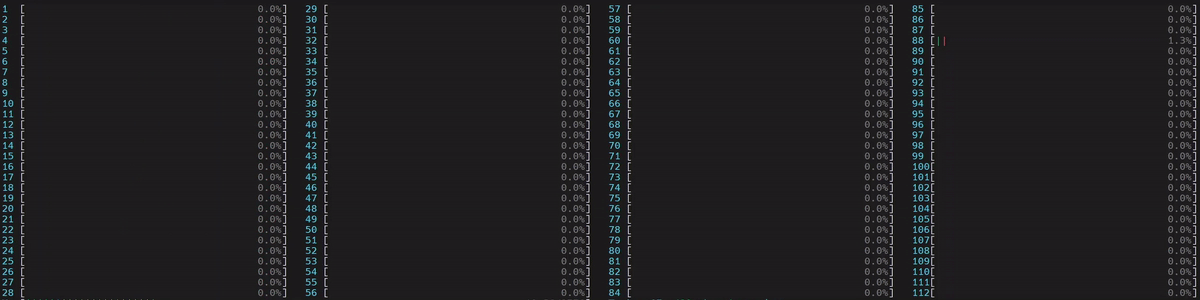
圖 5. NUMA 感知應用程式的 CPU 使用率
啟動了 1 個主 worker 執行緒,然後它在第一個 numa 節點上的所有物理核心上啟動了執行緒。

圖 6. 非均勻記憶體存取分析圖
如圖 6 所示,現在幾乎所有記憶體存取都是本機存取。
透過核心釘選實現多 worker 推論的高效率 CPU 使用率¶
當執行多 worker 推論時,核心會在 worker 之間重疊(或共享),導致 CPU 使用率降低。為了解決這個問題,啟動腳本會將可用核心的數量平均分配給 worker 的數量,以便在執行期間將每個 worker 釘選到分配的核心。
使用 TorchServe 練習
對於此練習,讓我們將到目前為止我們討論過的 CPU 效能調整原則和建議應用於 TorchServe apache-bench 基準測試。
我們將使用 ResNet50,搭配 4 個 worker、100 的並行數 (concurrency) 以及 10,000 個請求 (requests)。所有其他參數(例如 batch_size、input 等)都與預設參數相同。
我們將比較以下三種配置:
預設 TorchServe 設定(沒有核心綁定 (core pinning))
torch.set_num_threads =
實體核心數量 / worker 數量(沒有核心綁定)透過啟動腳本 (launch script) 進行核心綁定 (需要 Torchserve>=0.6.1)
經過此練習後,我們將驗證在實際的 TorchServe 使用案例中,我們更傾向於避免使用邏輯核心,並偏好透過核心綁定來實現本地記憶體存取。
1. 預設 TorchServe 設定(沒有核心綁定)¶
base_handler 沒有明確設定 torch.set_num_threads。因此,預設的執行緒數量是實體 CPU 核心的數量,如此處所述。使用者可以使用 torch.get_num_threads 在 base_handler 中檢查執行緒數量。4 個主 worker 執行緒中的每一個都啟動了等於實體核心數量 (56) 的執行緒,總共啟動了 56x4 = 224 個執行緒,這多於核心總數 112。因此,核心肯定會高度重疊,具有很高的邏輯核心利用率 - 多個 worker 同時使用多個核心。此外,由於執行緒沒有綁定到特定的 CPU 核心,因此作業系統會定期將執行緒排程到位於不同插槽 (socket) 中的核心。
CPU 使用率
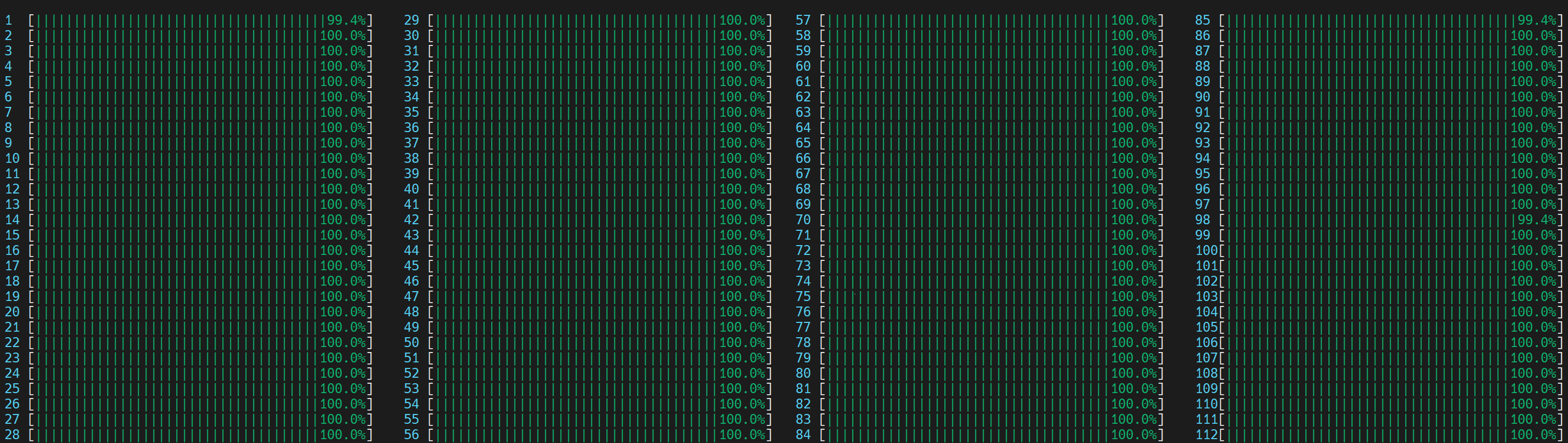
啟動了 4 個主 worker 執行緒,然後每個執行緒都在所有核心(包括邏輯核心)上啟動了等於實體核心數量 (56) 的執行緒。
核心綁定停頓 (Core Bound stalls)
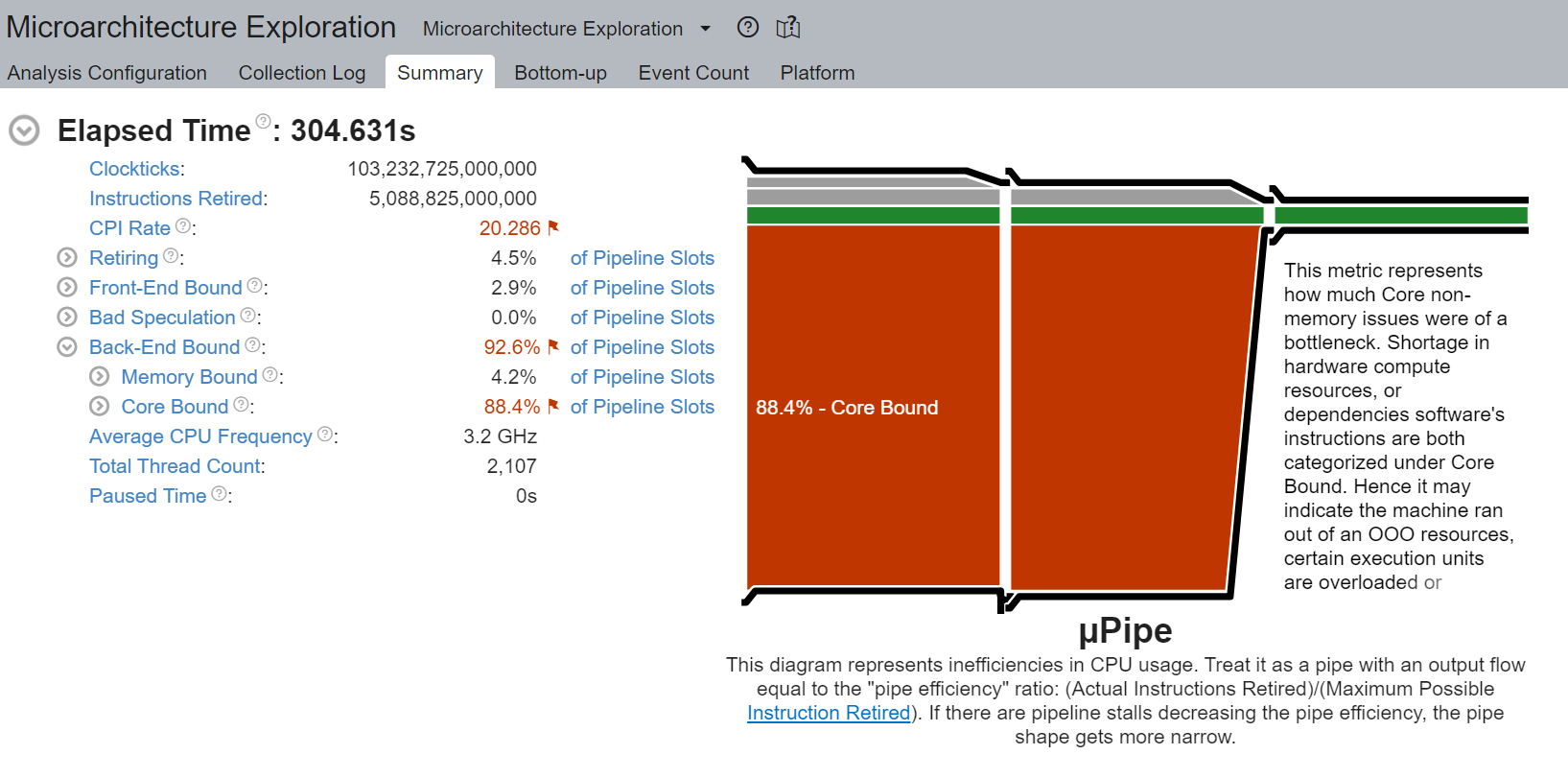
我們觀察到非常高的核心綁定停頓,高達 88.4%,降低了 pipeline 的效率。核心綁定停頓表示 CPU 中可用執行單元的使用效率不佳。例如,一系列 GEMM 指令爭奪由超執行緒核心共享的融合乘加 (FMA) 或點積 (DP) 執行單元可能會導致核心綁定停頓。如前一節所述,邏輯核心的使用放大了這個問題。
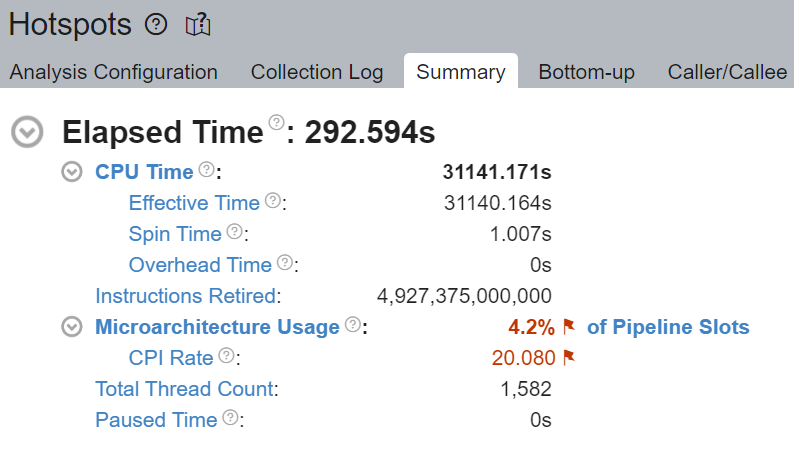
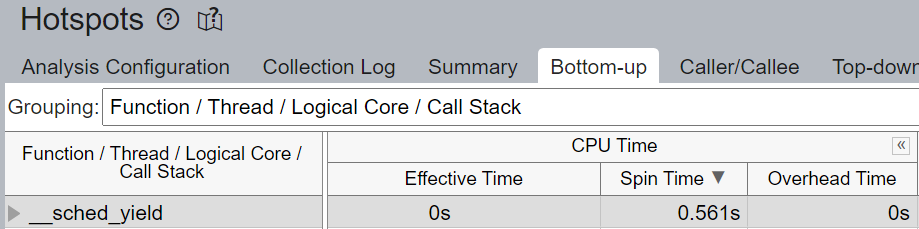
pipeline 中未填充 micro-ops (uOps) 的空槽位會被歸因於停頓。例如,如果沒有核心綁定,CPU 使用率可能無法有效地用於計算,而是用於來自 Linux 核心的執行緒排程等其他操作。我們在上面看到 __sched_yield 貢獻了大部分的 Spin Time。
執行緒遷移 (Thread Migration)
如果沒有核心綁定,排程器可能會將在核心上執行的執行緒遷移到另一個核心。執行緒遷移可能會使執行緒與已提取到快取中的資料分離,導致更長的資料存取延遲。當執行緒跨插槽遷移時,此問題在 NUMA 系統中會加劇。已提取到本地記憶體上的高速快取的資料現在變成了遠端記憶體,速度要慢得多。
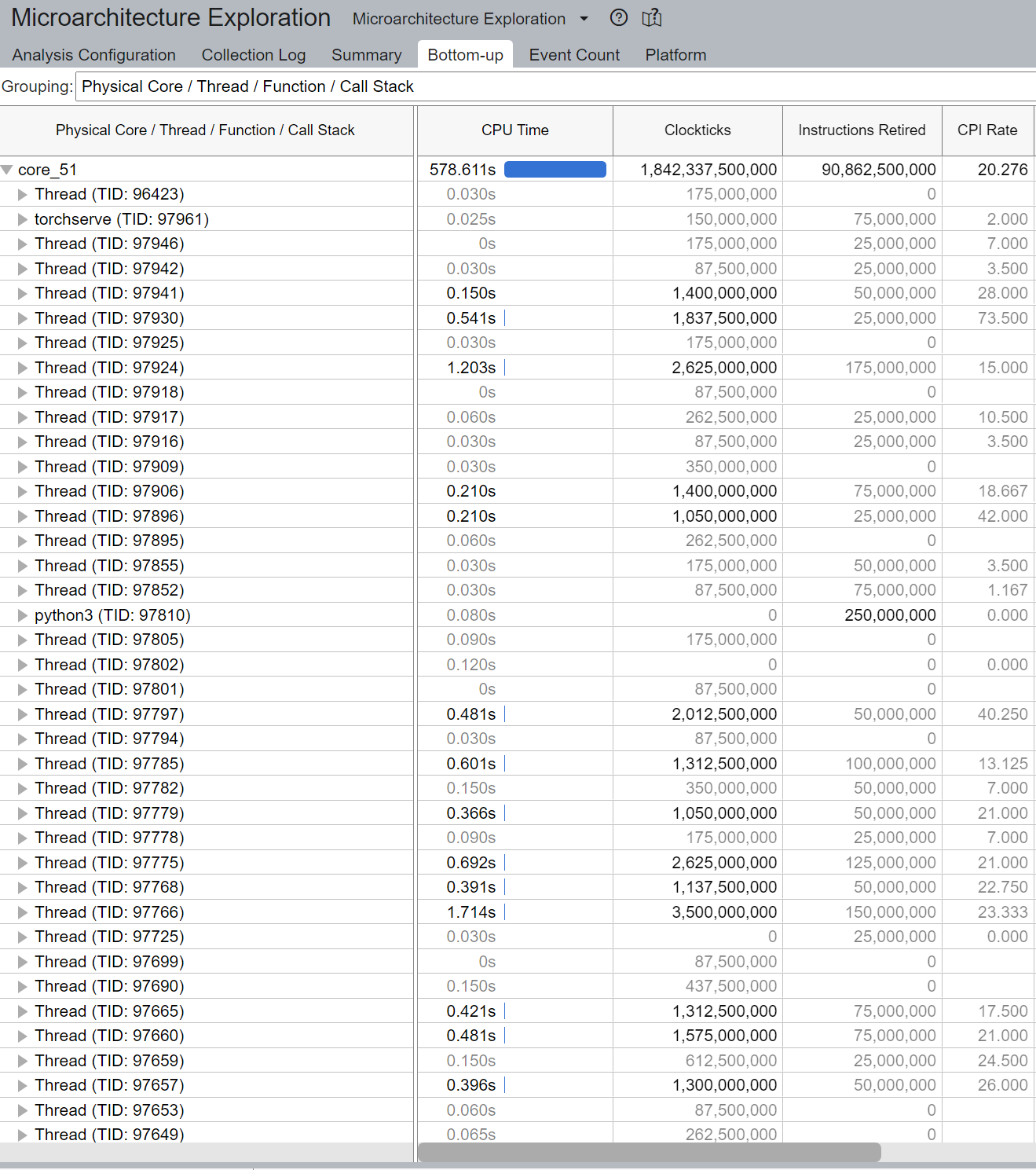
通常,執行緒總數應小於或等於核心支援的執行緒總數。在上面的範例中,我們注意到大量執行緒在 core_51 上執行,而不是預期的 2 個執行緒(因為 Intel(R) Xeon(R) Platinum 8180 CPU 中啟用了超執行緒)。這表示執行緒遷移。
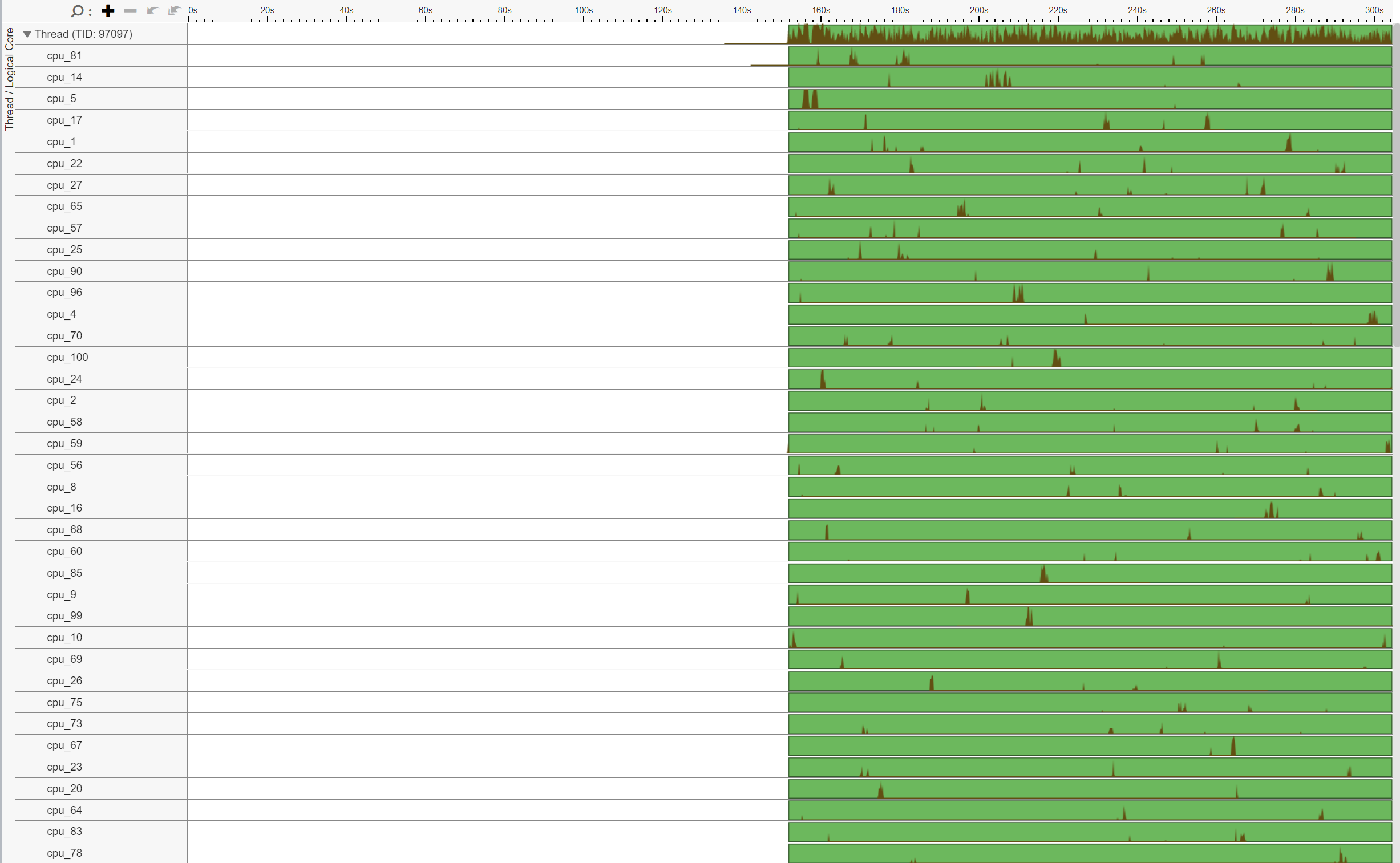
此外,請注意執行緒 (TID:97097) 正在大量 CPU 核心上執行,表示 CPU 遷移。例如,此執行緒在 cpu_81 上執行,然後遷移到 cpu_14,然後遷移到 cpu_5,依此類推。此外,請注意此執行緒多次來回跨插槽遷移,導致非常低效的記憶體存取。例如,此執行緒在 cpu_70 (NUMA 節點 0) 上執行,然後遷移到 cpu_100 (NUMA 節點 1),然後遷移到 cpu_24 (NUMA 節點 0)。
非均勻記憶體存取分析 (Non Uniform Memory Access Analysis)

比較一段時間內的本地與遠端記憶體存取。我們觀察到大約一半,51.09%,的記憶體存取是遠端存取,表示 NUMA 配置不佳。
2. torch.set_num_threads = 實體核心數量 / worker 數量 (沒有核心綁定)¶
為了與啟動器 (launcher) 的核心綁定進行公平的比較,我們將執行緒數量設定為核心數量除以 worker 數量(啟動器在內部執行此操作)。將以下程式碼片段新增到base_handler中
torch.set_num_threads(num_physical_cores/num_workers)
與之前沒有核心綁定的情況一樣,這些執行緒沒有綁定到特定的 CPU 核心,導致作業系統定期將執行緒排程到位於不同插槽中的核心。
CPU 使用率

啟動了 4 個主 worker 執行緒,然後每個執行緒都在所有核心(包括邏輯核心)上啟動了 num_physical_cores/num_workers 個執行緒 (14)。
核心綁定停頓 (Core Bound stalls)
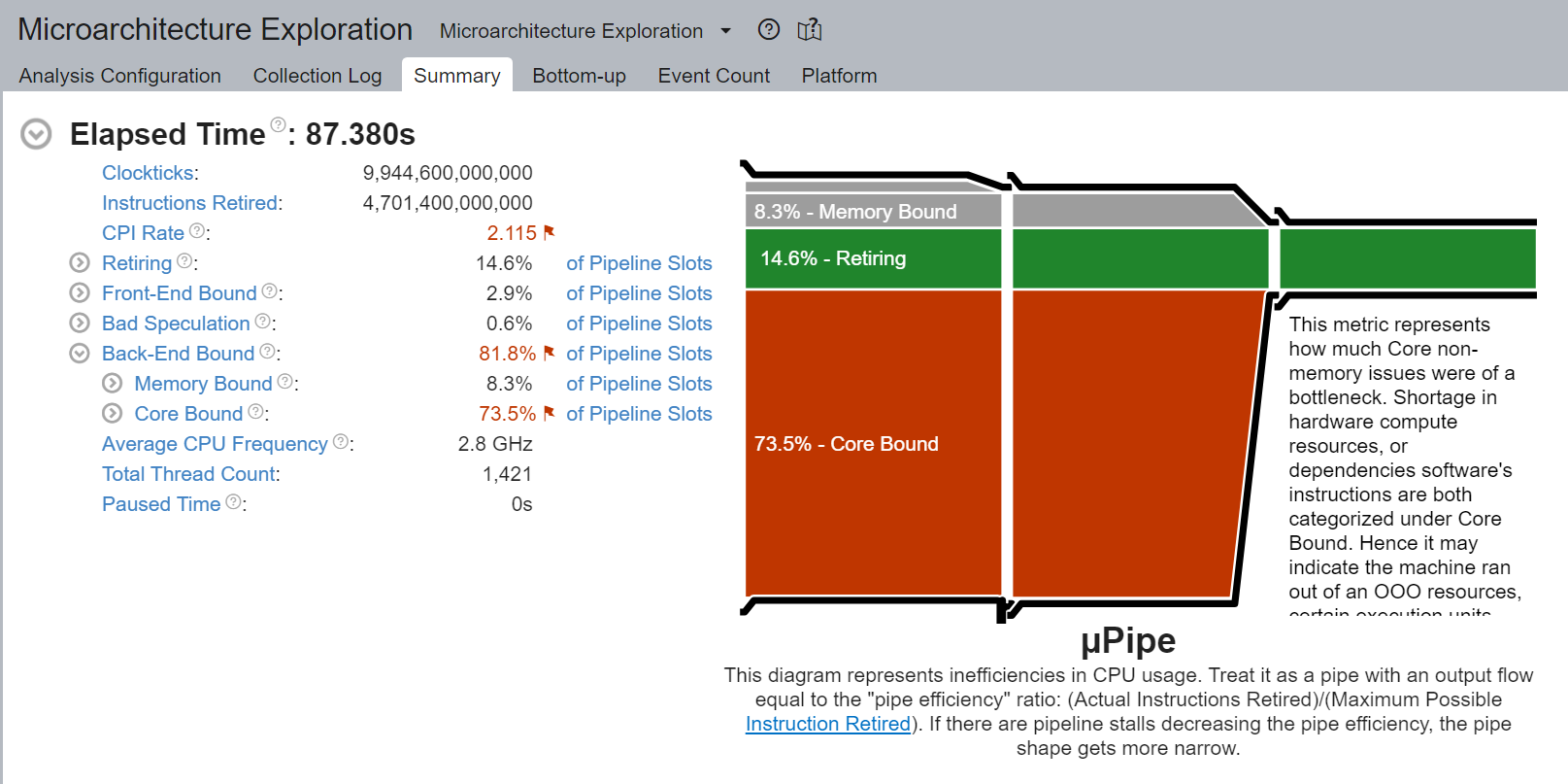
儘管核心綁定停頓的百分比從 88.4% 降低到 73.5%,但核心綁定仍然非常高。
執行緒遷移 (Thread Migration)
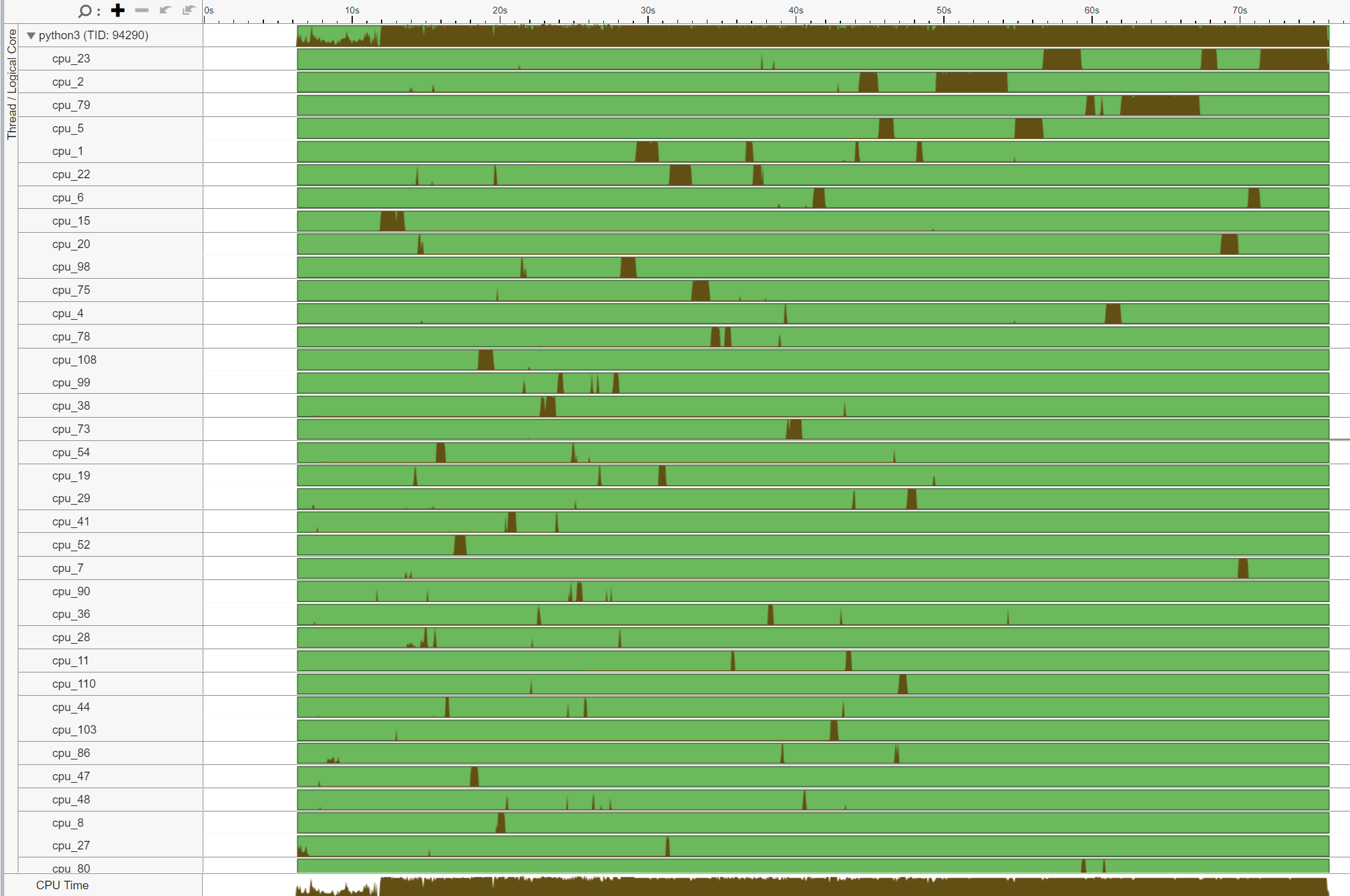
與之前類似,在沒有核心綁定的情況下,執行緒 (TID:94290) 正在大量 CPU 核心上執行,表示 CPU 遷移。我們再次注意到跨插槽執行緒遷移,導致非常低效的記憶體存取。例如,此執行緒在 cpu_78 (NUMA 節點 0) 上執行,然後遷移到 cpu_108 (NUMA 節點 1)。
非均勻記憶體存取分析 (Non Uniform Memory Access Analysis)

儘管比原始的 51.09% 有所改進,但仍然有 40.45% 的記憶體存取是遠端的,表示 NUMA 配置不佳。
3. 啟動器核心綁定¶
啟動器將在內部將實體核心平均分配給 worker,並將它們綁定到每個 worker。提醒一下,預設情況下啟動器僅使用實體核心。在此範例中,啟動器將 worker 0 綁定到核心 0-13(NUMA 節點 0),將 worker 1 綁定到核心 14-27(NUMA 節點 0),將 worker 2 綁定到核心 28-41(NUMA 節點 1),並將 worker 3 綁定到核心 42-55(NUMA 節點 1)。這樣做可確保核心不會在 worker 之間重疊,並避免使用邏輯核心。
CPU 使用率
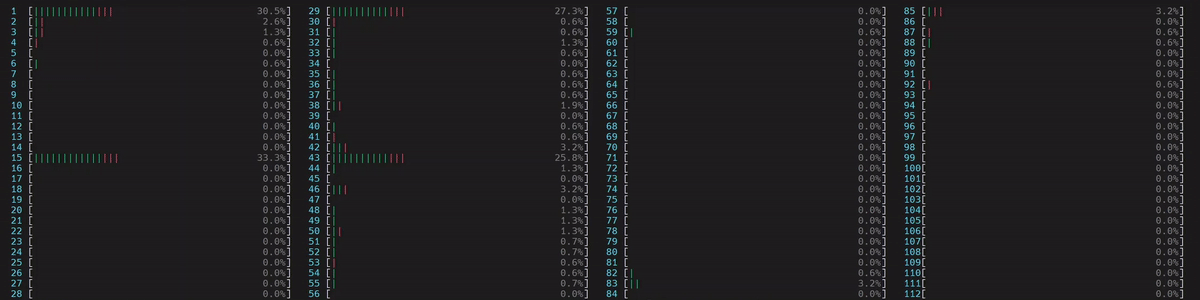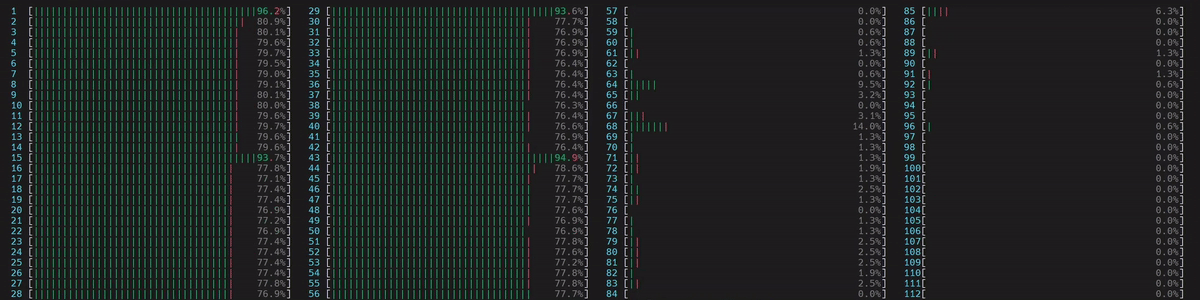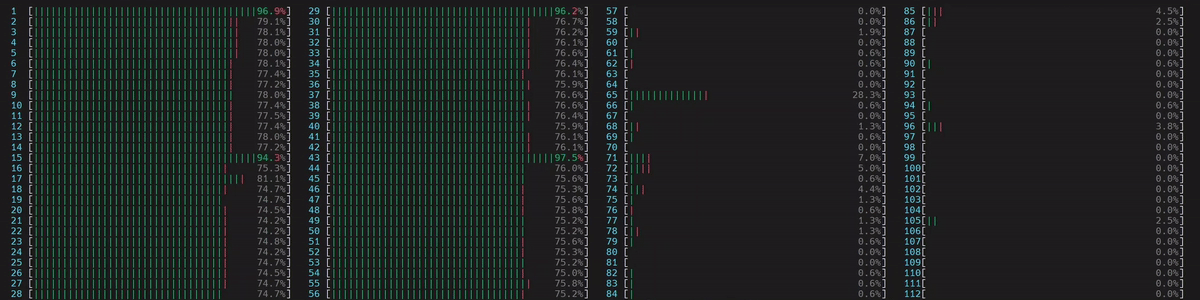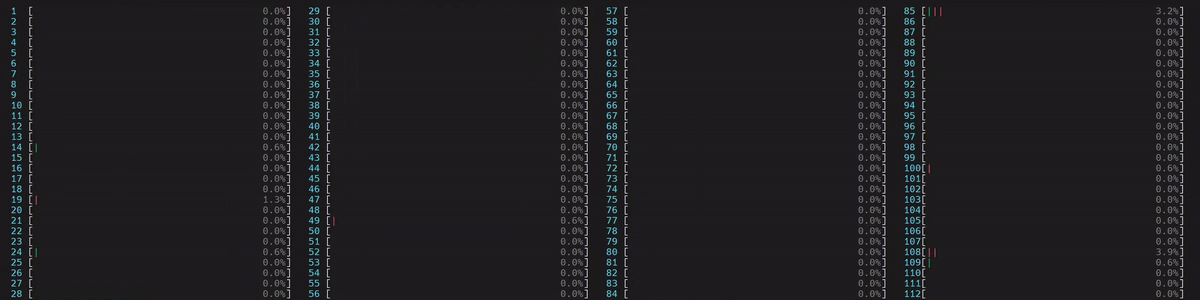
啟動了 4 個主 worker 執行緒,然後每個執行緒都啟動了 num_physical_cores/num_workers 個執行緒 (14),這些執行緒已綁定到分配的實體核心。
核心綁定停頓 (Core Bound stalls)
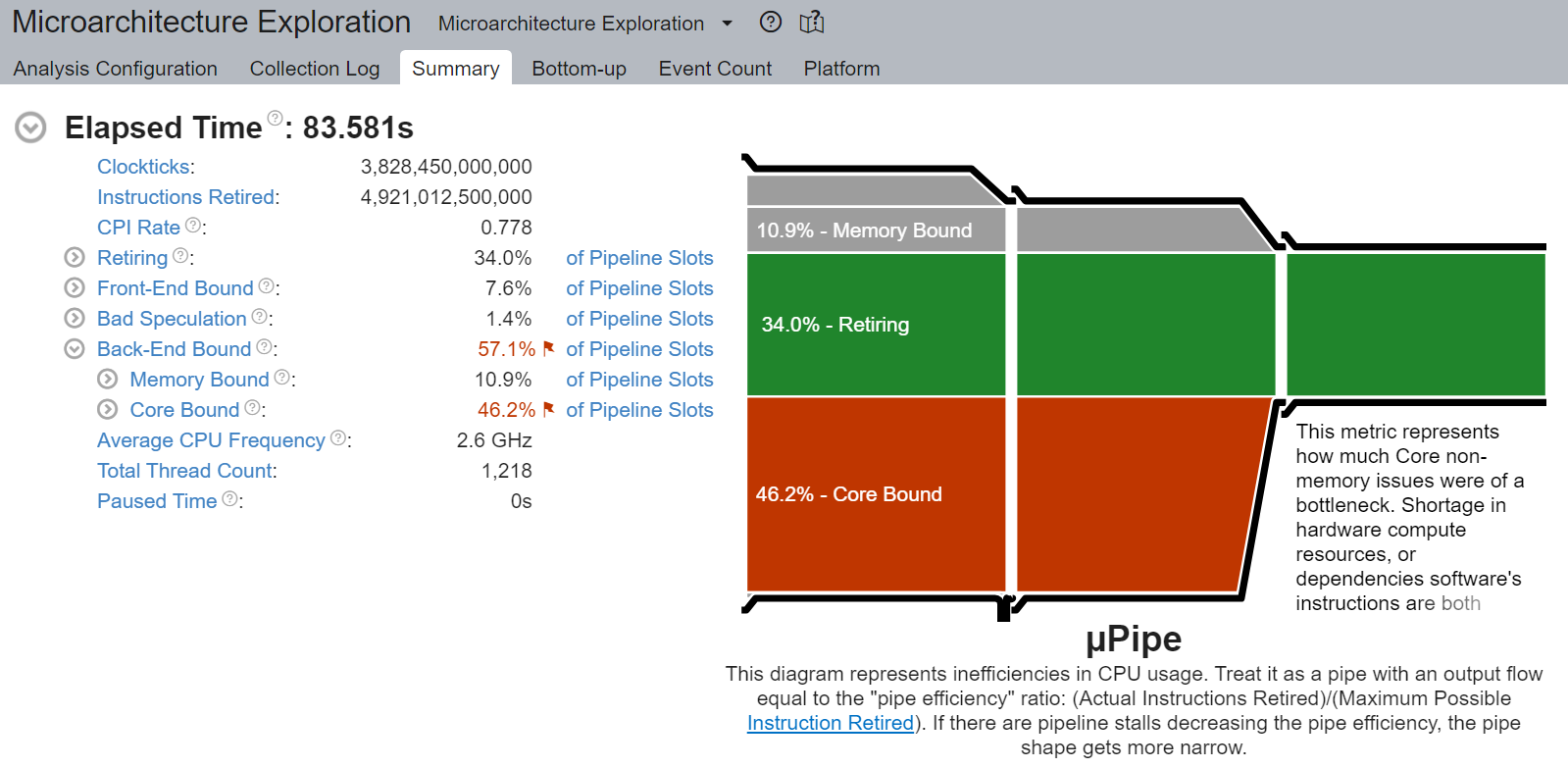
核心綁定停頓已從原始的 88.4% 顯著降低到 46.2% - 幾乎提高了 2 倍。
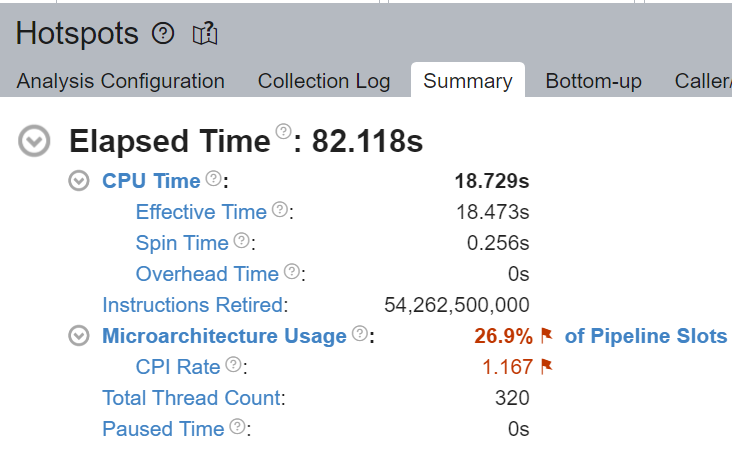
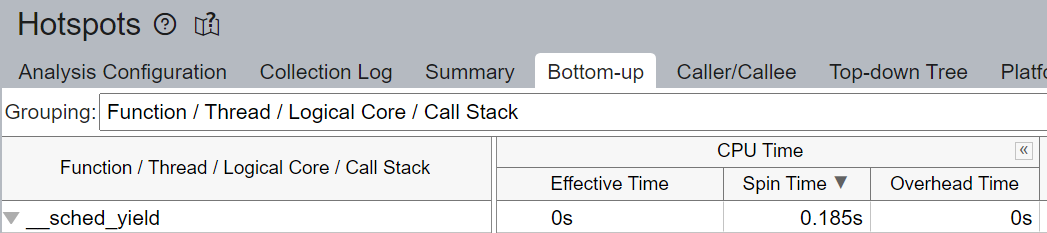
我們驗證了透過核心綁定,大多數 CPU 時間都有效地用於計算 - Spin Time 為 0.256 秒。
執行緒遷移 (Thread Migration)

我們驗證了OMP Primary Thread #0已綁定到指定的實體核心 (42-55),且未跨插槽遷移。
非均勻記憶體存取分析 (Non Uniform Memory Access Analysis)

現在幾乎所有記憶體存取,89.52%,都是本地存取。
結論¶
在本篇部落格中,我們展示了正確設定 CPU 執行時組態可以顯著提升開箱即用的 CPU 效能。
我們已經介紹了一些通用的 CPU 效能調整原則和建議。
在啟用超執行緒的系統中,透過核心綁定將執行緒親和性設定為僅使用實體核心,以避免使用邏輯核心。
在具有 NUMA 的多插槽系統中,透過核心綁定將執行緒親和性設定為特定插槽,以避免跨插槽的遠端記憶體存取。
我們已經從第一性原理視覺化地解釋了這些概念,並透過效能分析驗證了效能提升。最後,我們將所有學到的知識應用於 TorchServe,以提升開箱即用的 TorchServe CPU 效能。
這些原則可以透過一個易於使用的啟動腳本自動配置,該腳本已整合到 TorchServe 中。
對於感興趣的讀者,請查看以下文件:
請持續關注後續文章,內容關於透過 Intel® Extension for PyTorch* 對 CPU 上的最佳化核心以及進階啟動器配置(例如記憶體分配器)進行最佳化。
致謝¶
我們要感謝 Ashok Emani (Intel) 和 Jiong Gong (Intel) 在本篇部落格的許多步驟中給予的巨大指導和支持,以及詳盡的回饋和審閱。我們還要感謝 Hamid Shojanazeri (Meta)、Li Ning (AWS) 和 Jing Xu (Intel) 在程式碼審閱中提供的有益回饋。以及 Suraj Subramanian (Meta) 和 Geeta Chauhan (Meta) 對於部落格提供的有益回饋。
