


完全分片資料平行 (FSDP) 入門¶
建立於:2022 年 3 月 17 日 | 最後更新:2025 年 1 月 23 日 | 最後驗證:2024 年 11 月 05 日
作者:Hamid Shojanazeri、Yanli Zhao、Shen Li
注意
 在 github 中檢視和編輯此教學課程。
在 github 中檢視和編輯此教學課程。
大規模訓練 AI 模型是一項具挑戰性的任務,需要大量的運算能力和資源。它還帶來了相當大的工程複雜性來處理這些非常大的模型的訓練。PyTorch FSDP,在 PyTorch 1.11 中發布,使這更容易。
在本教學中,我們展示如何使用 FSDP API,用於簡單的 MNIST 模型,可以擴展到其他更大的模型,例如 HuggingFace BERT 模型、高達 1T 參數的 GPT 3 模型。 範例 DDP MNIST 程式碼由 Patrick Hu 提供。
FSDP 的運作方式¶
在 DistributedDataParallel (DDP) 訓練中,每個處理程序/工作程序都擁有一個模型副本並處理一批資料,最後它使用 all-reduce 來對不同工作程序的梯度求和。 在 DDP 中,模型權重和最佳化器狀態會在所有工作程序之間複製。 FSDP 是一種資料平行類型,它將模型參數、最佳化器狀態和梯度在 DDP 排名之間分片。
使用 FSDP 訓練時,所有工作程序的 GPU 記憶體佔用空間都小於使用 DDP 訓練時。 這使得一些非常大的模型的訓練變得可行,因為允許更大的模型或批次大小適合在裝置上。 這會增加通訊量的成本。 通訊開銷透過內部最佳化來減少,例如重疊通訊和計算。
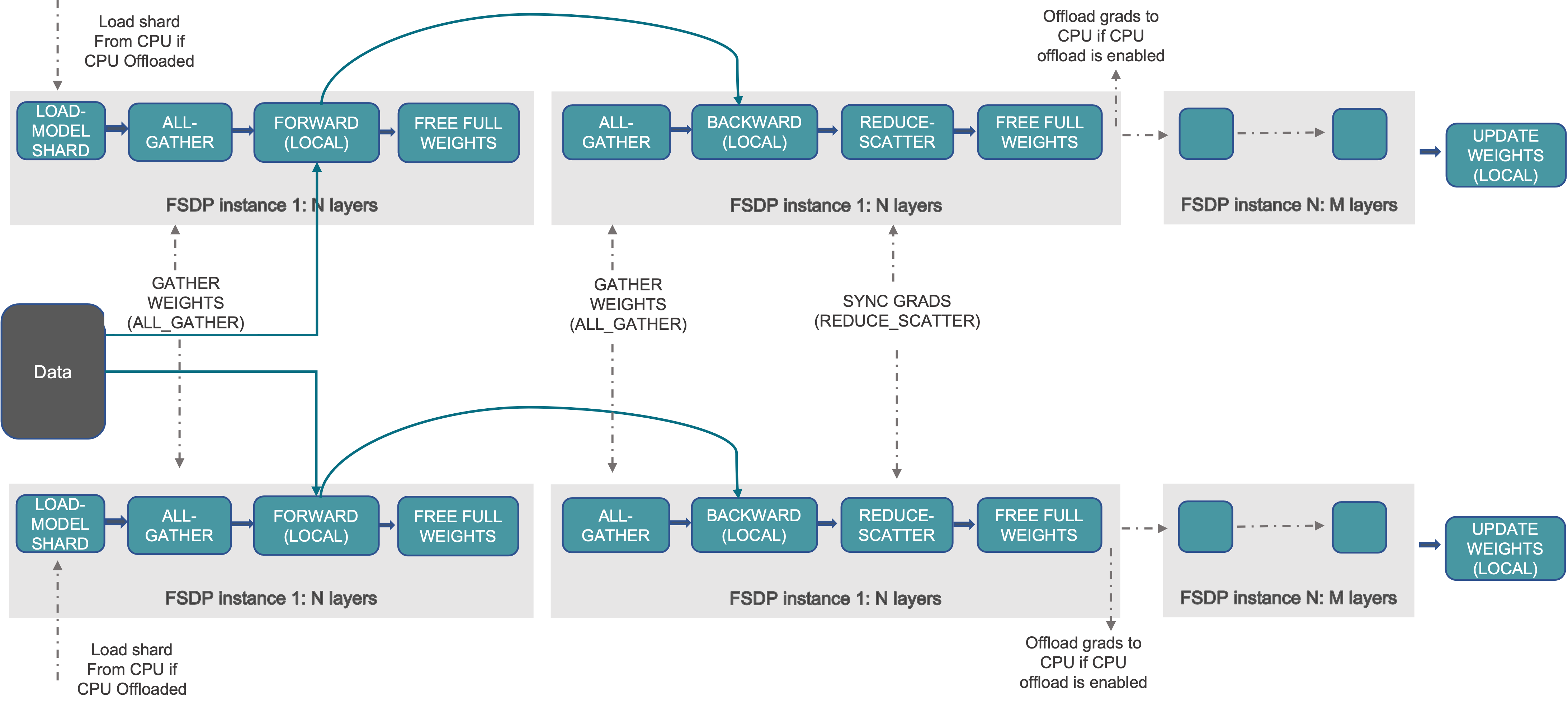
FSDP 工作流程¶
在高階層面,FSDP 的運作方式如下
在建構函數中
分片模型參數,每個排名僅保留自己的分片
在正向路徑中
執行 all_gather 以從所有排名收集所有分片,以恢復此 FSDP 單元中的完整參數
執行正向計算
丟棄它剛收集的參數分片
在反向路徑中
執行 all_gather 以從所有排名收集所有分片,以恢復此 FSDP 單元中的完整參數
執行反向計算
執行 reduce_scatter 以同步梯度
丟棄參數。
查看 FSDP 分片的一種方法是將 DDP 梯度 all-reduce 分解為 reduce-scatter 和 all-gather。 具體來說,在反向傳遞期間,FSDP 會減少和分散梯度,確保每個排名都擁有梯度的一個分片。 然後它更新最佳化器步驟中參數的對應分片。 最後,在後續的正向傳遞中,它會執行 all-gather 操作以收集和組合更新的參數分片。
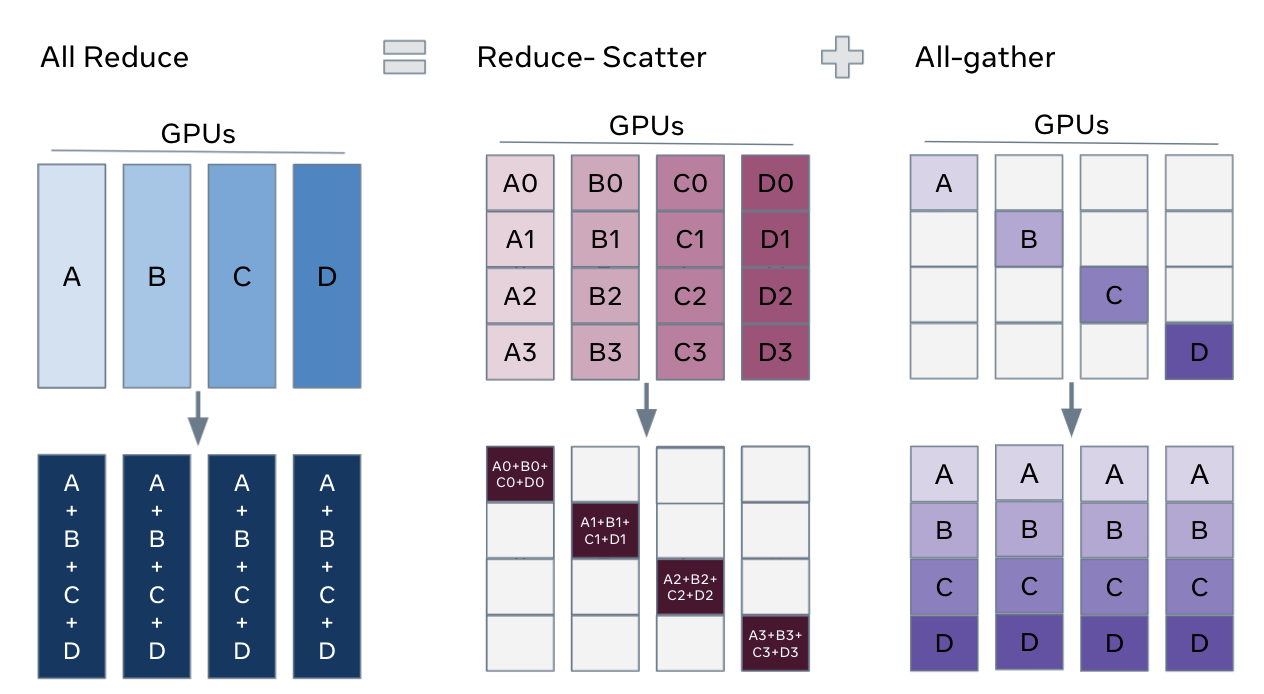
FSDP Allreduce¶
如何使用 FSDP¶
在這裡,我們使用一個玩具模型在 MNIST 資料集上執行訓練以進行示範。 API 和邏輯也可以應用於訓練更大的模型。
設定
1.1 安裝 PyTorch 以及 Torchvision
有關安裝的資訊,請參閱入門指南。
我們將以下程式碼片段新增到 python 腳本「FSDP_mnist.py」。
1.2 導入必要的套件
注意
本教學適用於 PyTorch 1.12 及更高版本。 如果您使用的是較早版本,請將所有 size_based_auto_wrap_policy 替換為 default_auto_wrap_policy,並將 fsdp_auto_wrap_policy 替換為 auto_wrap_policy。
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py
import os
import argparse
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.fully_sharded_data_parallel import (
CPUOffload,
BackwardPrefetch,
)
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
enable_wrap,
wrap,
)
1.3 分散式訓練設定。 如前所述,FSDP 是一種資料平行類型,需要分散式訓練環境,因此我們在這裡使用兩個輔助函數來初始化分散式訓練的處理程序並進行清理。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
2.1 定義我們用於手寫數字分類的玩具模型。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
2.2 定義一個訓練函數
def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None):
model.train()
ddp_loss = torch.zeros(2).to(rank)
if sampler:
sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(rank), target.to(rank)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target, reduction='sum')
loss.backward()
optimizer.step()
ddp_loss[0] += loss.item()
ddp_loss[1] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
print('Train Epoch: {} \tLoss: {:.6f}'.format(epoch, ddp_loss[0] / ddp_loss[1]))
2.3 定義一個驗證函數
def test(model, rank, world_size, test_loader):
model.eval()
correct = 0
ddp_loss = torch.zeros(3).to(rank)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(rank), target.to(rank)
output = model(data)
ddp_loss[0] += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
ddp_loss[1] += pred.eq(target.view_as(pred)).sum().item()
ddp_loss[2] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
test_loss = ddp_loss[0] / ddp_loss[2]
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, int(ddp_loss[1]), int(ddp_loss[2]),
100. * ddp_loss[1] / ddp_loss[2]))
2.4 定義一個分散式訓練函數,將模型包裝在 FSDP 中
注意:若要儲存 FSDP 模型,我們需要在每個排名上呼叫 state_dict,然後在排名 0 上儲存整體狀態。
def fsdp_main(rank, world_size, args):
setup(rank, world_size)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True)
sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size)
train_kwargs = {'batch_size': args.batch_size, 'sampler': sampler1}
test_kwargs = {'batch_size': args.test_batch_size, 'sampler': sampler2}
cuda_kwargs = {'num_workers': 2,
'pin_memory': True,
'shuffle': False}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100
)
torch.cuda.set_device(rank)
init_start_event = torch.cuda.Event(enable_timing=True)
init_end_event = torch.cuda.Event(enable_timing=True)
model = Net().to(rank)
model = FSDP(model)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
init_start_event.record()
for epoch in range(1, args.epochs + 1):
train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1)
test(model, rank, world_size, test_loader)
scheduler.step()
init_end_event.record()
if rank == 0:
init_end_event.synchronize()
print(f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec")
print(f"{model}")
if args.save_model:
# use a barrier to make sure training is done on all ranks
dist.barrier()
states = model.state_dict()
if rank == 0:
torch.save(states, "mnist_cnn.pt")
cleanup()
2.5 最後,解析引數並設定主函數
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
torch.manual_seed(args.seed)
WORLD_SIZE = torch.cuda.device_count()
mp.spawn(fsdp_main,
args=(WORLD_SIZE, args),
nprocs=WORLD_SIZE,
join=True)
我們已記錄 cuda 事件以測量 FSDP 模型特定的時間。 CUDA 事件時間為 110.85 秒。
python FSDP_mnist.py
CUDA event elapsed time on training loop 40.67462890625sec
使用 FSDP 包裝模型,該模型將如下所示,我們可以看出現模型已包裝在一個 FSDP 單元中。 或者,我們將研究新增 auto_wrap_policy,並討論差異。
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
)
以下是從 PyTorch Profiler 擷取的,在具有 4 個 GPU 的 g4dn.12.xlarge AWS EC2 執行個體上,使用 FSDP 進行 MNIST 訓練時的峰值記憶體使用量。
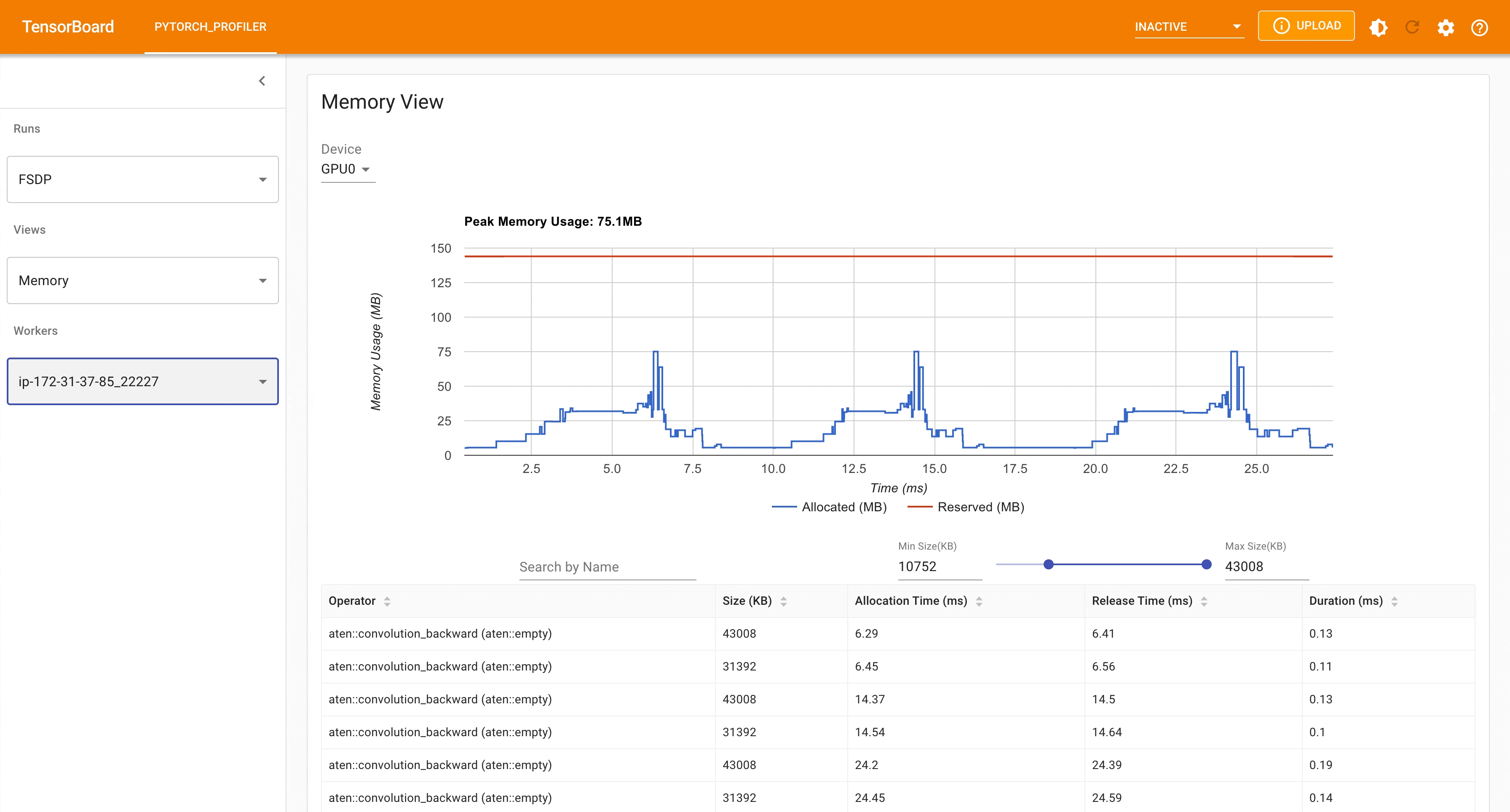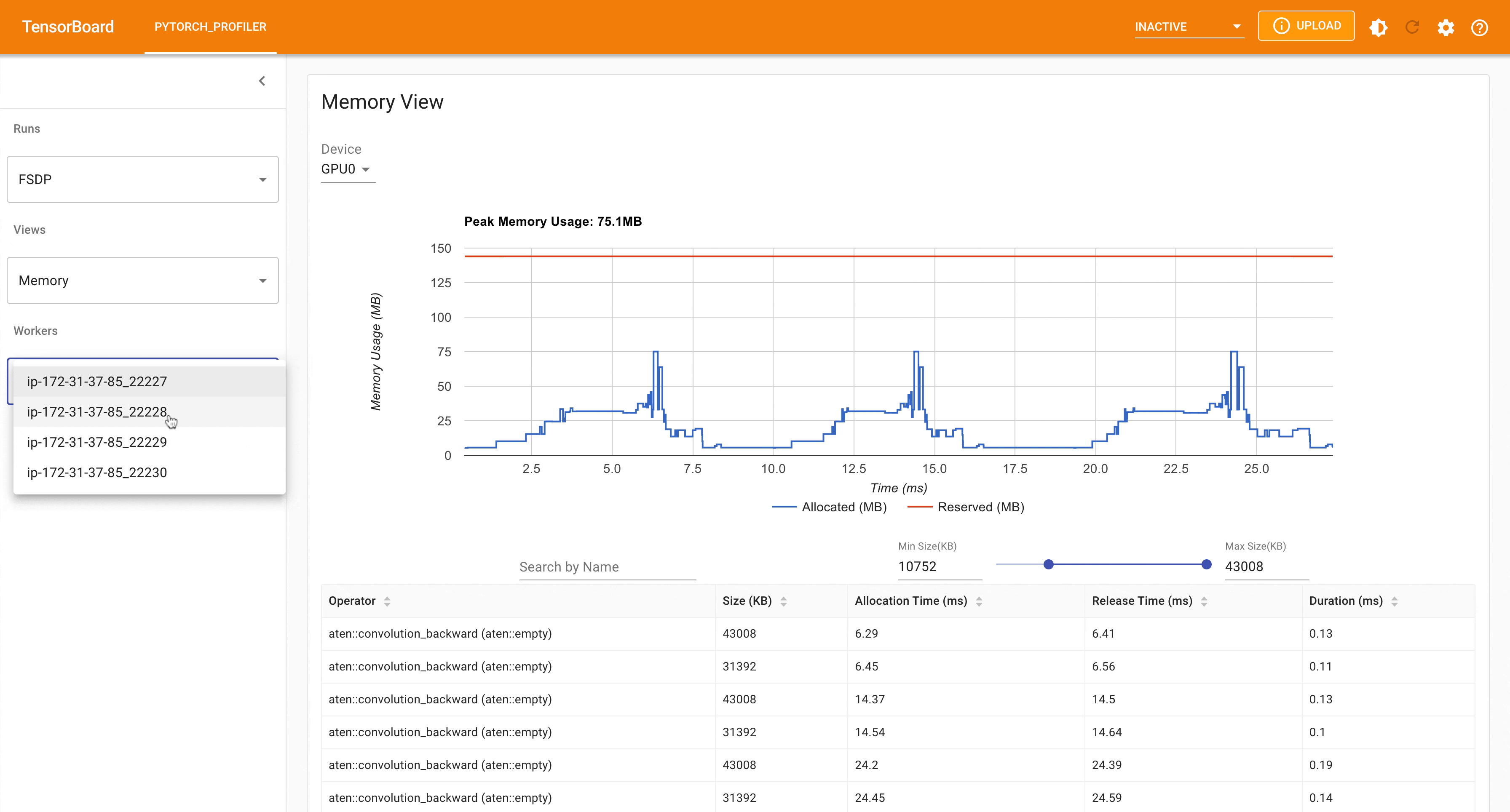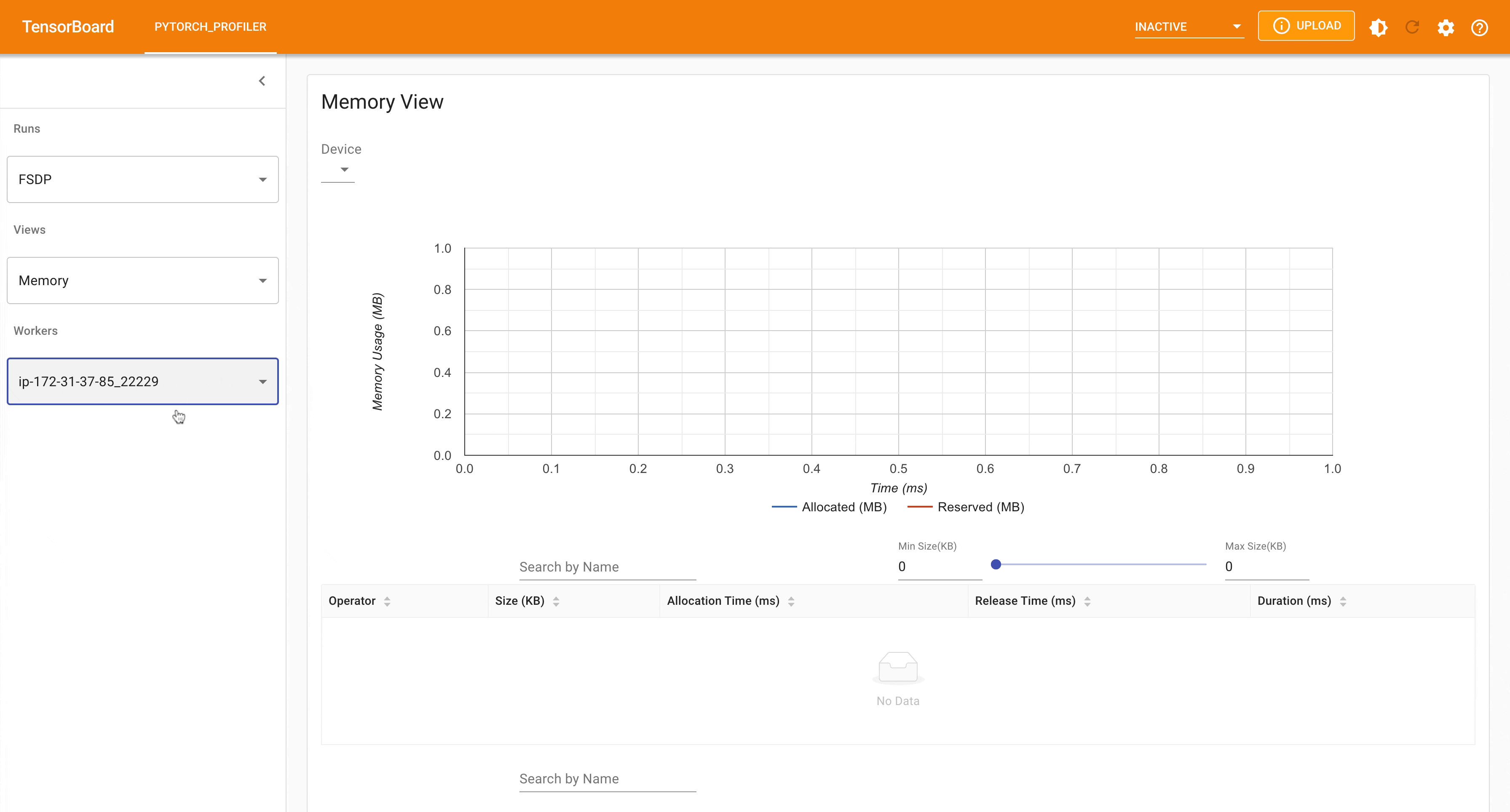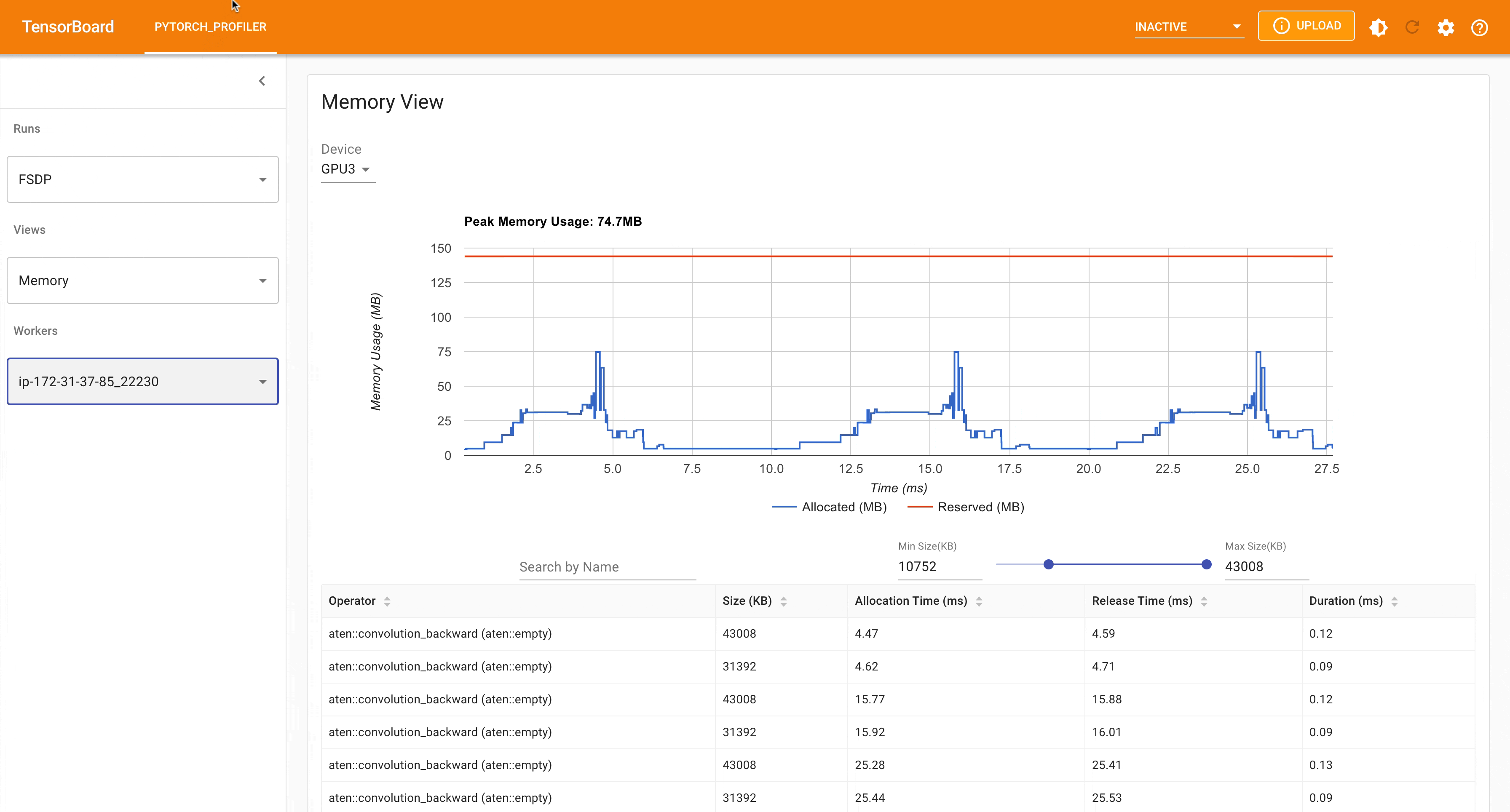
FSDP 峰值記憶體使用量¶
在 FSDP 中應用auto_wrap_policy,否則 FSDP 會將整個模型放在一個 FSDP 單元中,這會降低計算效率和記憶體效率。它的工作方式是,假設你的模型包含 100 個線性層 (Linear layer)。如果你執行 FSDP(model),則只會有一個 FSDP 單元包裝整個模型。在這種情況下,allgather 會收集所有 100 個線性層的完整參數,因此不會因為參數分片而節省 CUDA 記憶體。此外,對於所有 100 個線性層,只有一個阻塞式 allgather 呼叫,因此層之間不會有通訊和計算重疊。
為了避免這種情況,你可以傳入一個 auto_wrap_policy,它會在滿足指定條件(例如,大小限制)時自動封裝目前的 FSDP 單元並啟動一個新的 FSDP 單元。這樣,你將擁有多個 FSDP 單元,並且每次只需要一個 FSDP 單元收集完整參數。例如,假設你有 5 個 FSDP 單元,每個單元包裝 20 個線性層。那麼,在前向傳遞中,第一個 FSDP 單元將 allgather 前 20 個線性層的參數,進行計算,丟棄參數,然後移動到下一個 20 個線性層。因此,在任何時間點,每個 rank 只會具體化 20 個線性層的參數/梯度,而不是 100 個。
為了在 2.4 中做到這一點,我們定義了 auto_wrap_policy 並將其傳遞給 FSDP wrapper。在以下範例中,my_auto_wrap_policy 定義如果此層中的參數數量大於 100,則可以由 FSDP 包裝或分片該層。如果此層中的參數數量小於 100,則它將與其他小層一起被 FSDP 包裝。找到最佳的 auto wrap policy 具有挑戰性,PyTorch 將在未來為此配置添加自動調整。在沒有自動調整工具的情況下,最好通過實驗使用不同的 auto wrap policies 分析你的工作流程,並找到最佳的一個。
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=20000
)
torch.cuda.set_device(rank)
model = Net().to(rank)
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy)
應用 auto_wrap_policy 後,模型如下所示
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Linear(in_features=9216, out_features=128, bias=True)
)
)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
python FSDP_mnist.py
CUDA event elapsed time on training loop 41.89130859375sec
以下是從 PyTorch Profiler 擷取的,在具有 4 個 GPU 的 g4dn.12.xlarge AWS EC2 執行個體上,使用具有 auto_wrap policy 的 FSDP 進行 MNIST 訓練時的峰值記憶體使用量。可以觀察到,與未應用 auto wrap policy 的 FSDP 相比,每個裝置上的峰值記憶體使用量更小,從約 75 MB 降至 66 MB。
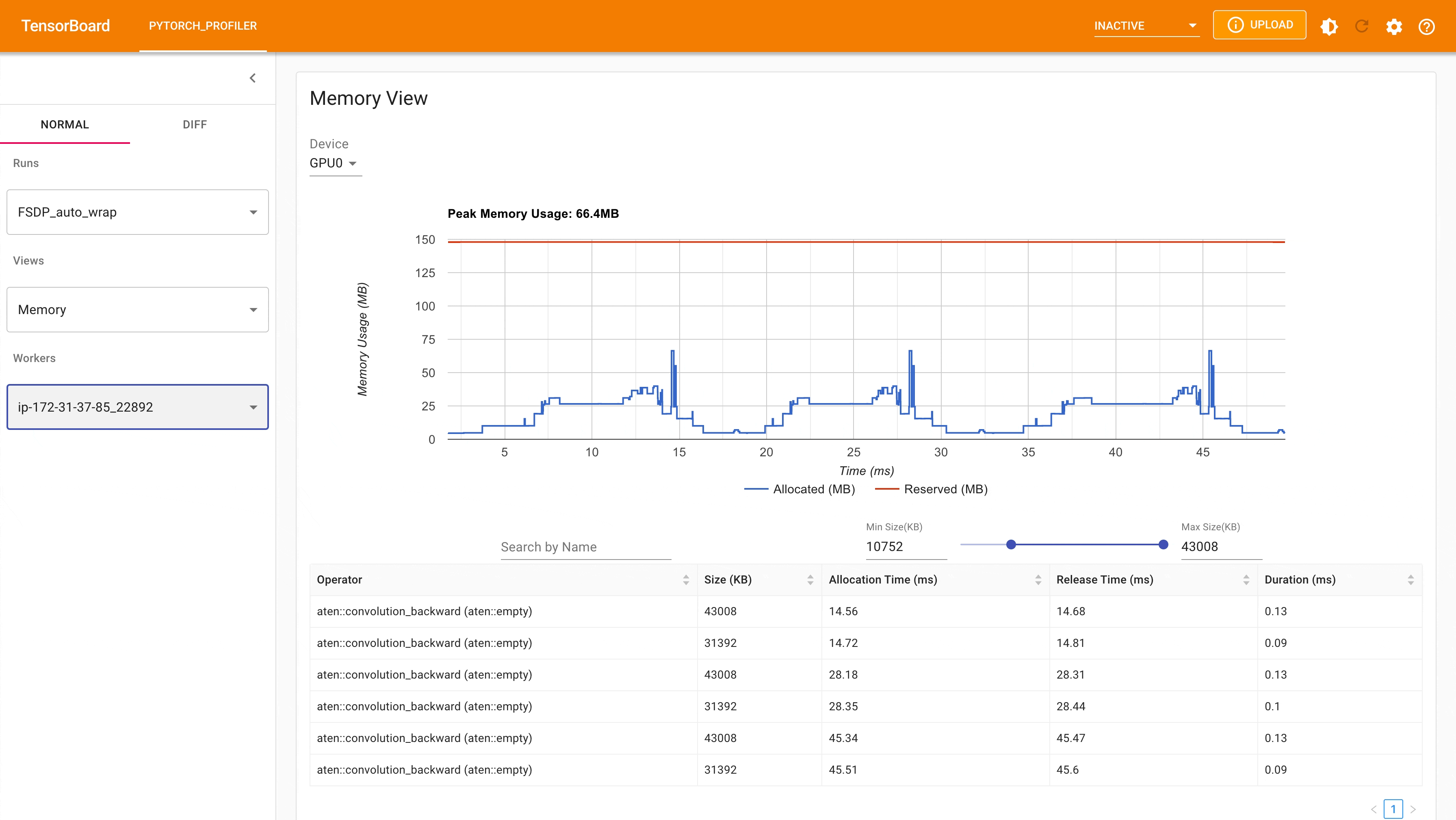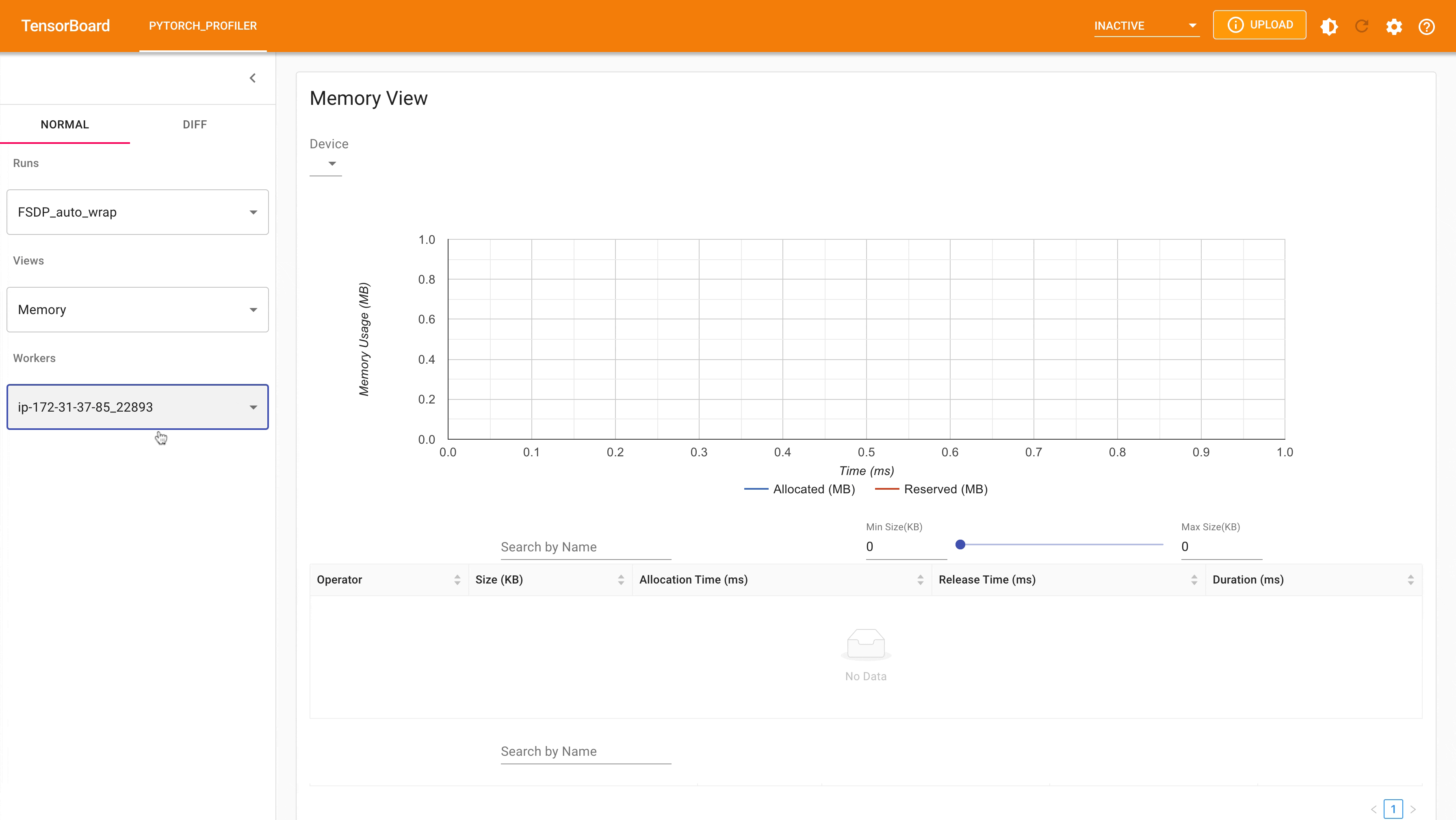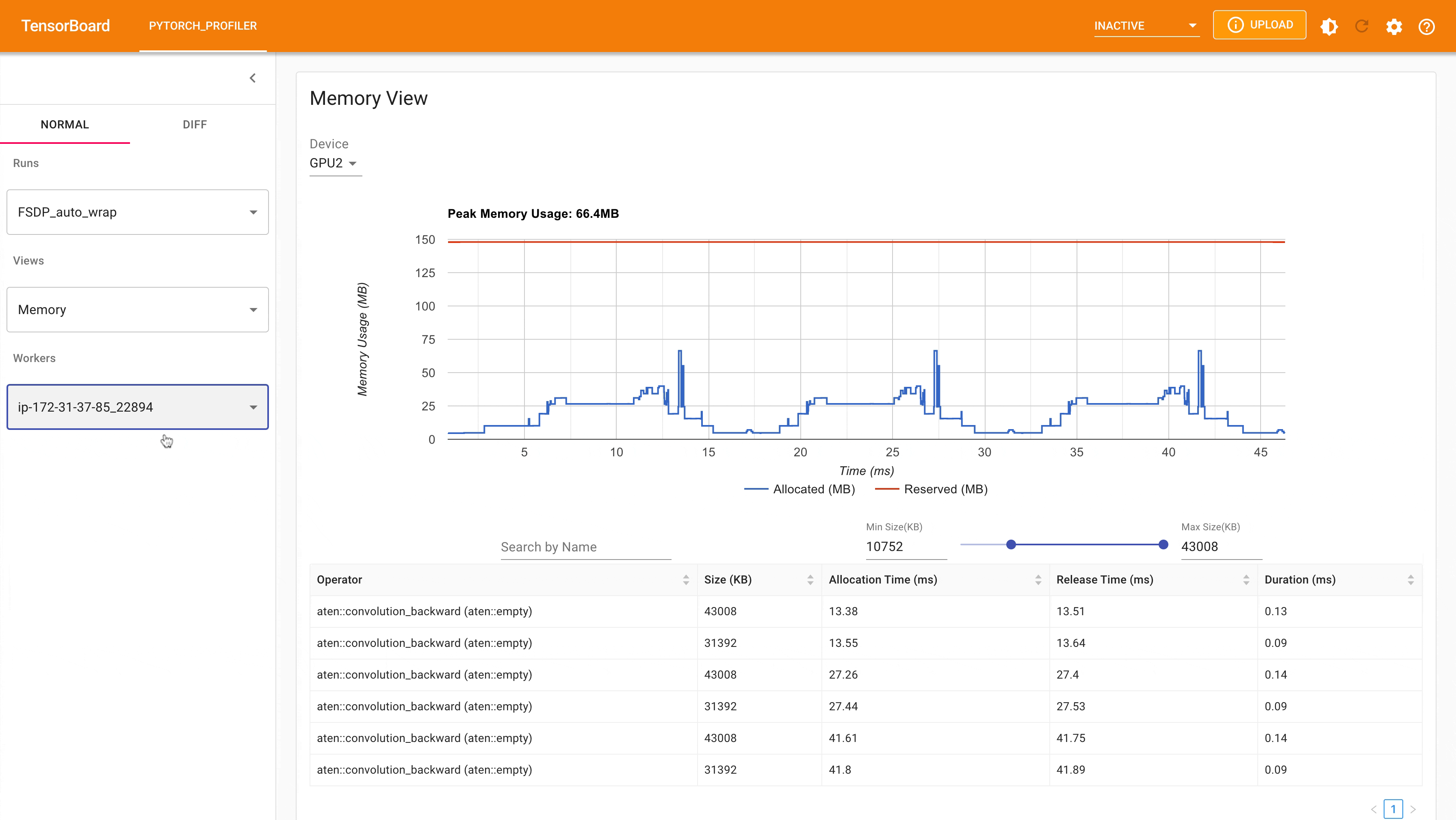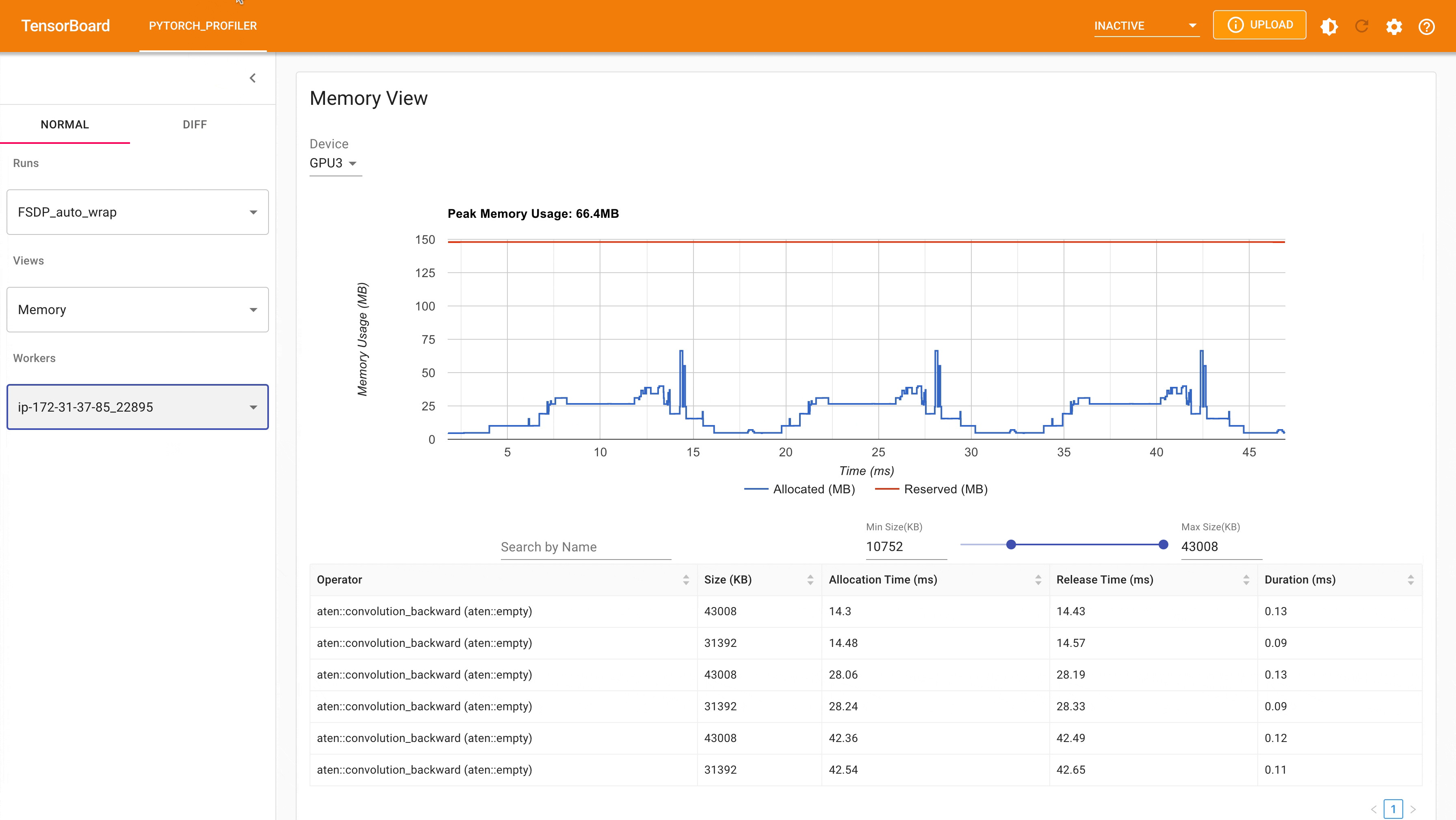
使用 Auto_wrap policy 的 FSDP 峰值記憶體使用量¶
CPU Off-loading (CPU 卸載):如果模型非常大,即使使用 FSDP 也無法放入 GPU 中,那麼 CPU 卸載可能會有幫助。
目前,僅支援參數和梯度 CPU 卸載。可以通過傳入 cpu_offload=CPUOffload(offload_params=True) 來啟用它。
請注意,目前這會隱式地啟用將梯度卸載到 CPU,以便參數和梯度位於同一裝置上,以與優化器一起使用。此 API 可能會更改。預設值為 None,在這種情況下,不會進行卸載。
由於頻繁地將 tensors 從主機複製到裝置,因此使用此功能可能會顯著減慢訓練速度,但它可以幫助提高記憶體效率並訓練更大規模的模型。
在 2.4 中,我們只需將其添加到 FSDP wrapper 中
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True))
與 DDP 進行比較,如果在 2.4 中我們只是正常地將模型包裝在 DPP 中,將更改保存在 “DDP_mnist.py” 中。
model = Net().to(rank)
model = DDP(model)
python DDP_mnist.py
CUDA event elapsed time on training loop 39.77766015625sec
以下是從 PyTorch profiler 擷取的,在具有 4 個 GPU 的 g4dn.12.xlarge AWS EC2 執行個體上,使用 DDP 進行 MNIST 訓練時的峰值記憶體使用量。
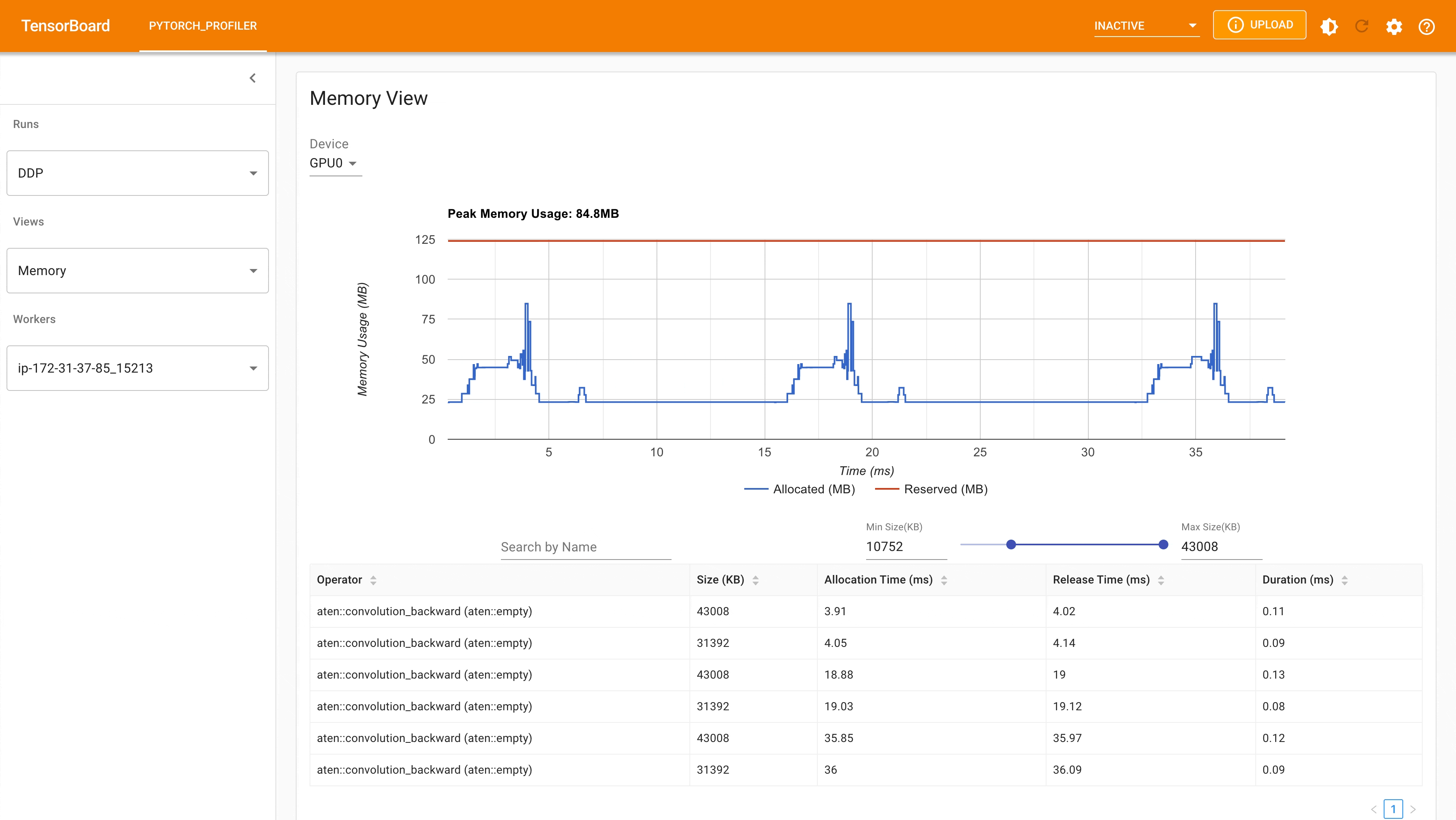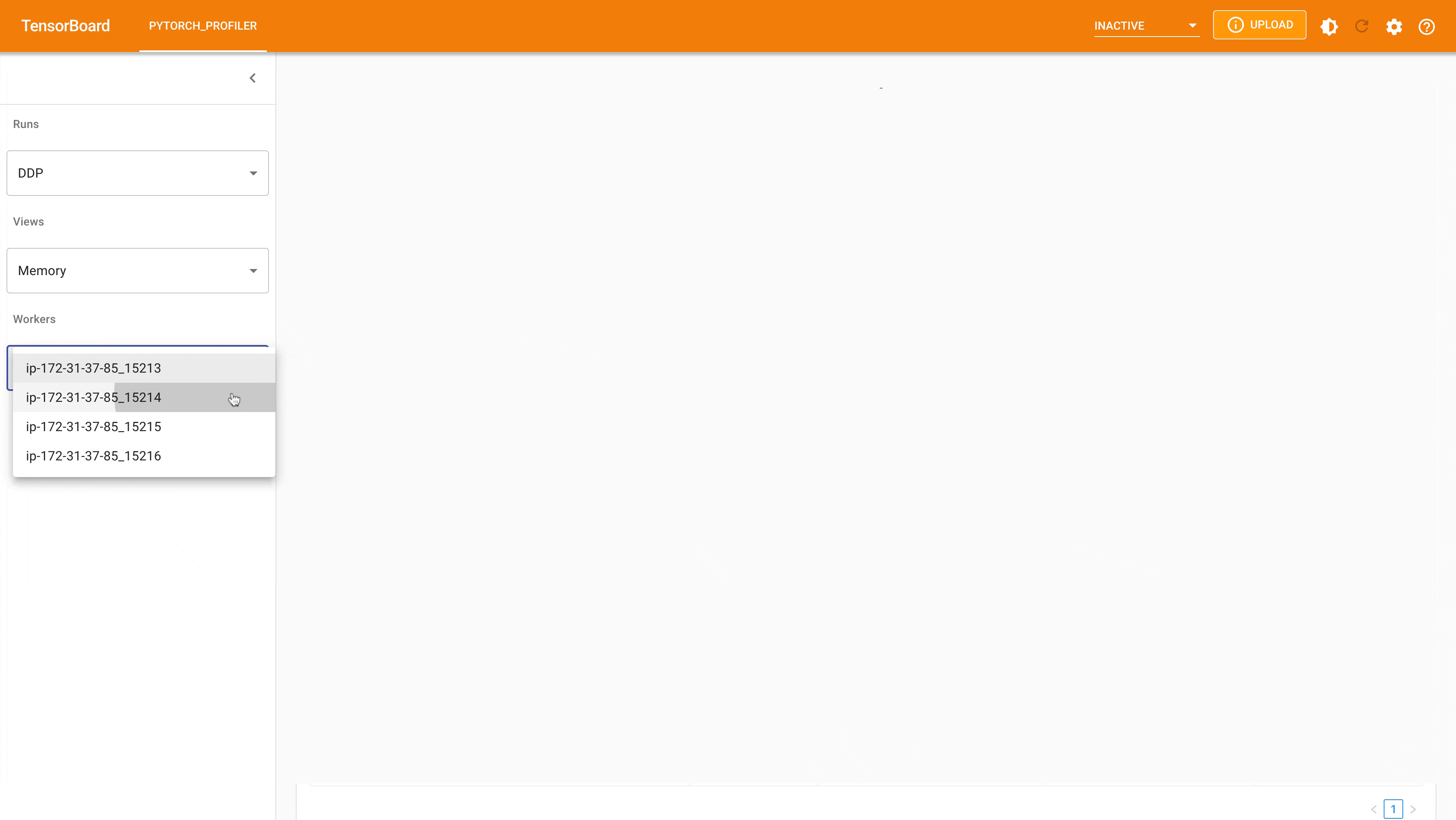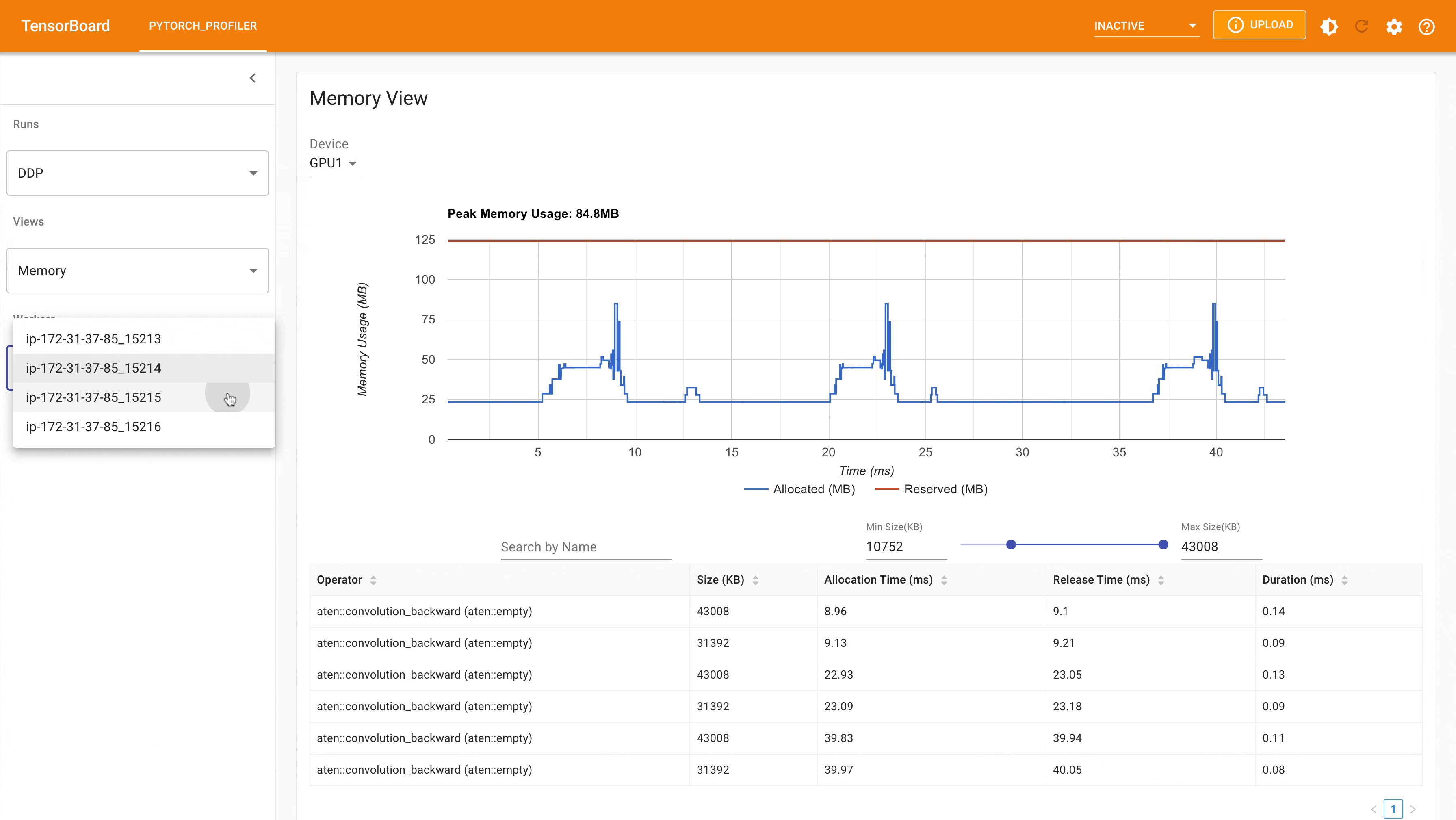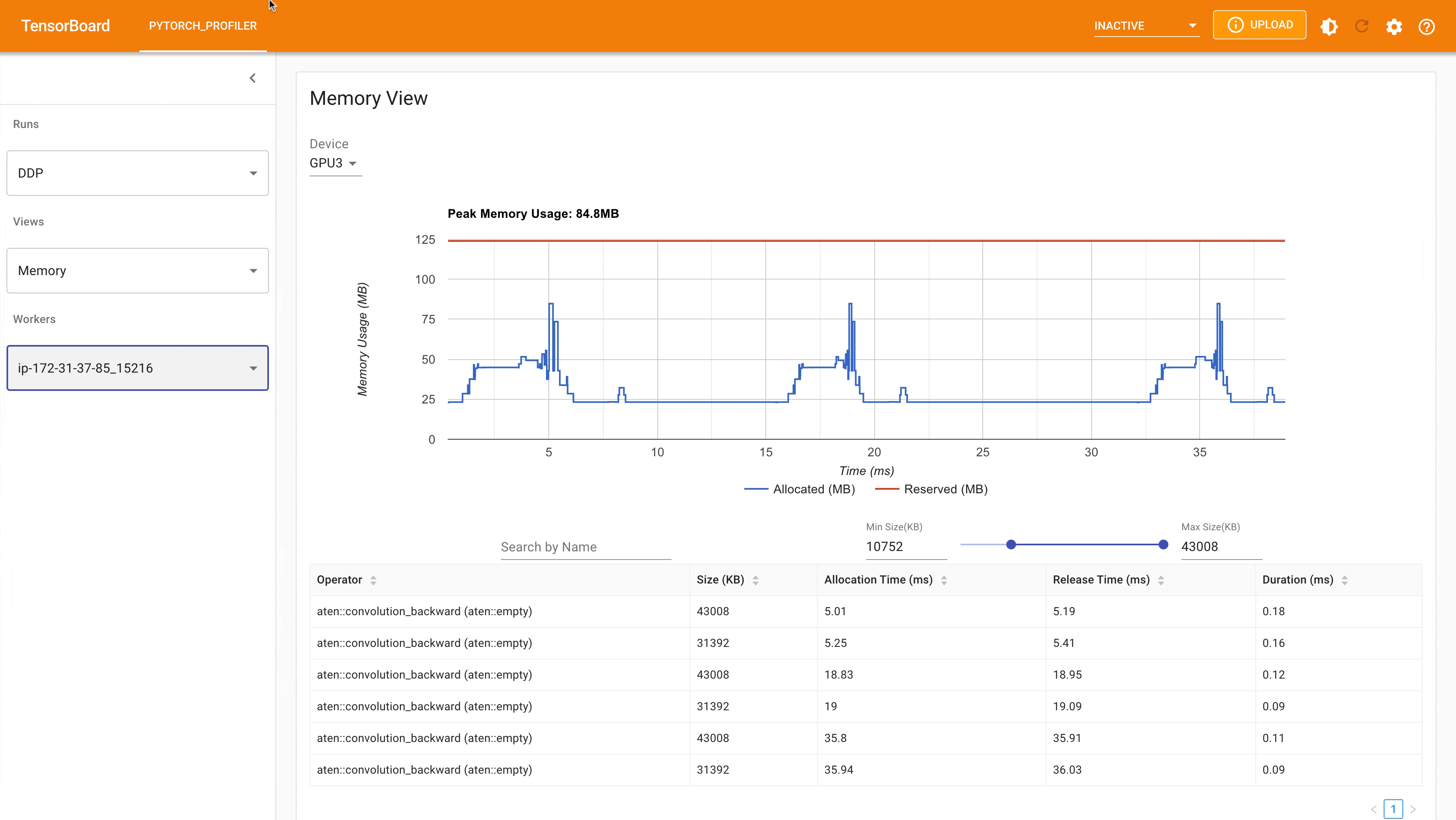
使用 Auto_wrap policy 的 DDP 峰值記憶體使用量¶
考慮到我們在此處定義的玩具範例和微小的 MNIST 模型,我們可以觀察到 DDP 和 FSDP 的峰值記憶體使用量之間的差異。在 DDP 中,每個進程都擁有一個模型副本,因此與 FSDP 相比,記憶體佔用量更高,FSDP 會將模型參數、優化器狀態和梯度分片到 DDP rank 上。使用具有 auto_wrap policy 的 FSDP 的峰值記憶體使用量最低,其次是 FSDP 和 DDP。
此外,查看時間,考慮到小型模型並在單個機器上運行訓練,具有和不具有 auto_wrap policy 的 FSDP 執行速度幾乎與 DDP 一樣快。此範例不代表大多數實際應用,有關 DDP 和 FSDP 之間的詳細分析和比較,請參閱此部落格文章。
