


使用張量平行 (TP) 的大規模 Transformer 模型訓練¶
建立日期:2024 年 4 月 19 日 | 最後更新日期:2024 年 8 月 19 日 | 最後驗證日期:2024 年 11 月 05 日
注意
 在 github 中檢視和編輯本教學。
在 github 中檢視和編輯本教學。
本教學示範如何使用張量平行和 Fully Sharded Data Parallel 在數百到數千個 GPU 上訓練大型類 Transformer 模型。
先決條件
安裝 PyTorch 2.3.0 或更新版本,並搭配 CUDA/Linux
張量平行如何運作?¶
張量平行 (TP) 最初在 Megatron-LM 論文中提出,它是一種高效的模型平行技術,用於訓練大規模 Transformer 模型。 我們在本教學中提到的 序列平行 (SP) 是張量平行的一種變體,它在序列維度上進行分片,適用於 nn.LayerNorm 或 RMSNorm,以進一步節省訓練期間的激活記憶體。 隨著模型變得更大,激活記憶體成為瓶頸,因此在張量平行訓練中,通常將序列平行應用於 LayerNorm 或 RMSNorm 層。
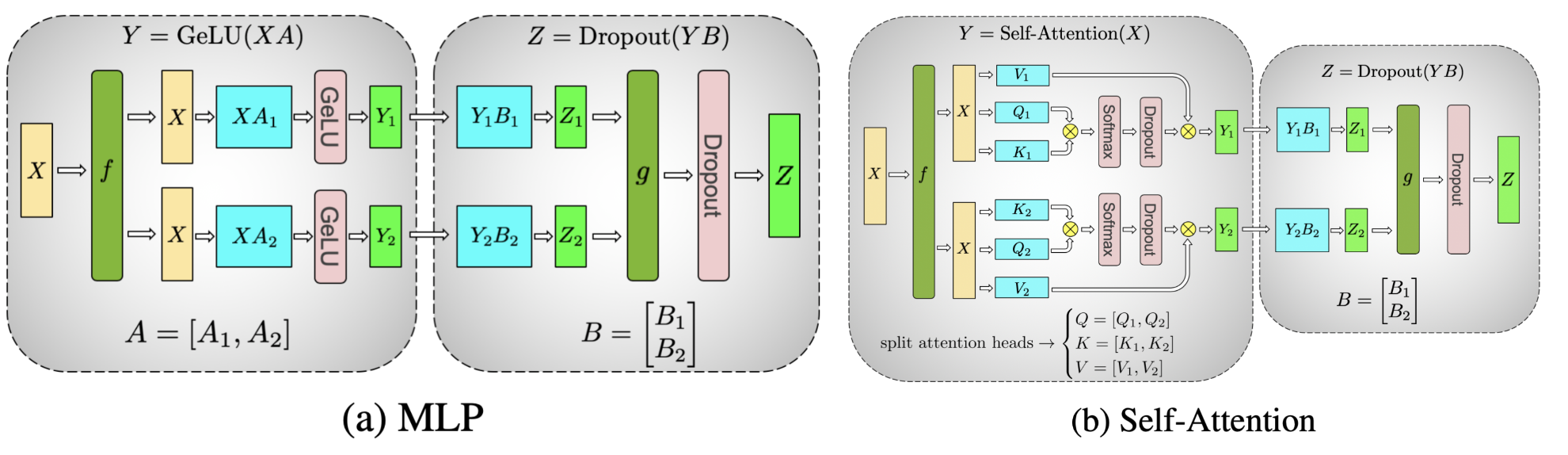
在高層次上,PyTorch 張量平行的運作方式如下
分片初始化
確定要將哪個
ParallelStyle應用於每一層,並透過呼叫parallelize_module來對初始化的模組進行分片。平行化的模組會將其模型參數交換為 DTensors,而 DTensor 將負責使用分片計算來執行平行化的模組。
執行階段前向/後向
根據使用者為每個
ParallelStyle指定的輸入/輸出 DTensor 佈局,它將執行適當的通訊操作,以轉換輸入/輸出的 DTensor 佈局 (例如allreduce、allgather和reduce_scatter)。為平行化的層執行分片計算,以節省計算/記憶體 (例如,
nn.Linear、nn.Embedding)。
何時以及為何應該應用張量平行¶
PyTorch Fully Sharded Data Parallel (FSDP) 已經能夠將模型訓練擴展到特定數量的 GPU。 但是,當涉及到根據模型大小和 GPU 數量進一步擴展模型訓練時,會出現許多額外的挑戰,可能需要將張量平行與 FSDP 結合使用。
由於世界大小(GPU 數量)變得過於龐大(超過 128/256 個 GPU),FSDP 集體操作(例如
allgather)正在被環路延遲所主導。 通過在 FSDP 之上實作 TP/SP,可以通過僅將 FSDP 應用於主機間來將 FSDP 世界大小縮小 8 倍,從而將延遲成本降低相同的量。達到資料平行限制,您無法將全域批次大小提高到高於 GPU 數量,因為存在收斂和 GPU 記憶體限制,張量/序列平行是唯一已知的「概估」全域批次大小並繼續隨著更多 GPU 擴展的方法。 這意味著模型大小和 GPU 數量都可以繼續擴展。
對於某些類型的模型,當本機批次大小變小時,TP/SP 可以產生針對浮點運算 (FLOPS) 進行了最佳化的矩陣乘法形狀。
那麼,在預訓練時,達到這些限制有多容易? 截至目前,即使使用數千個 GPU,使用數十億或數兆個 token 預訓練大型語言模型 (LLM) 可能需要數月時間。
在大型規模上訓練 LLM 時,總是會遇到限制 1。例如,使用 2000 個 GPU 訓練 Llama 2 70B 達 35 天,就需要 2000 個規模的多維平行處理。
當 Transformer 模型變得更大(例如 Llama2 70B)時,也會迅速遇到限制 2。即使使用本地
batch_size=1,也無法單獨使用 FSDP,因為存在記憶體和收斂約束。例如,Llama 2 的全域批次大小為 1K,因此單獨使用資料平行處理無法在 2K GPU 上進行。
如何應用張量平行(Tensor Parallel)¶
PyTorch 張量平行 API 提供了一組模組層級的原始元件 (ParallelStyle),用於配置模型中每個個別層的分片,包括:
ColwiseParallel和RowwiseParallel:以欄或列的方式對nn.Linear和nn.Embedding進行分片。SequenceParallel:對nn.LayerNorm、nn.Dropout、RMSNormPython等執行分片計算。PrepareModuleInput和PrepareModuleOutput:使用適當的通訊操作配置模組輸入/輸出的分片佈局。
為了演示如何使用 PyTorch 原生的張量平行 API,讓我們看看一個常見的 Transformer 模型。在本教學中,我們使用最新的 Llama2 模型作為參考 Transformer 模型實作,因為它也在社群中廣泛使用。
由於張量平行處理會在一組裝置上對個別張量進行分片,因此我們需要首先設定分散式環境(例如 NCCL 通訊器)。張量平行是一種單程式多資料 (SPMD) 分片演算法,類似於 PyTorch DDP/FSDP,並且在底層利用 PyTorch DTensor 執行分片。它還利用 DeviceMesh 抽象(在底層管理 ProcessGroups)進行裝置管理和分片。要了解如何使用 DeviceMesh 設定多維平行處理,請參閱本教學。張量平行通常在每個主機內工作,因此讓我們首先初始化一個 DeviceMesh,該 DeviceMesh 連接主機內的 8 個 GPU。
from torch.distributed.device_mesh import init_device_mesh
tp_mesh = init_device_mesh("cuda", (8,))
現在我們已經初始化了 DeviceMesh,讓我們詳細了解 Llama 2 模型架構,看看我們應該如何執行張量平行分片。在這裡,我們專注於核心 TransformerBlock,其中 Transformer 模型堆疊相同的 TransformerBlock 以擴展模型。
核心 TransformerBlock 包含一個 Attention 層和一個 FeedForward 層。讓我們首先看看更簡單的 FeedForward 層。對於 FeedForward 層,它包含三個 Linear 層,其中執行 SwiGLU 樣式的 MLP,查看其前向函數
# forward in the FeedForward layer
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
它同時執行 w1 和 w3 矩陣乘法,然後執行 w2 矩陣乘法,該乘法使用組合的 w1/w3 線性投影結果。這意味著我們可以從張量平行論文中使用這個想法,以欄方式對 w1/w3 Linear 層進行分片,並以列方式對 w2 Linear 層進行分片,以便在所有三個層的末尾僅發生一次 allreduce 通訊。使用 PyTorch 原生的張量平行,我們可以簡單地為 FeedForward 層建立一個 parallelize_plan,如下所示
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_module
layer_tp_plan = {
# by default ColwiseParallel input layouts is replicated
# and RowwiseParallel output layouts is replicated
"feed_foward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(),
"feed_forward.w3": ColwiseParallel(),
}
這就是我們使用 PyTorch 張量平行 API 為 FeedForward 層配置分片的簡單方法。請注意,使用者只需要指定如何對個別層進行分片,並且通訊(例如,allreduce)將在底層發生。
繼續討論 Attention 層。它包含 wq、wk、wv Linear 層,用於將輸入投影到 q/ k / v,然後執行 attention 並使用 wo Linear 層進行輸出投影。此處的張量平行處理旨在對 q/k/v 投影執行欄式分片,並對 wo 線性投影執行列式分片。因此,我們可以將 Attention 計劃新增到我們剛剛起草的 tp_plan 中
layer_tp_plan = {
# by default ColwiseParallel input layouts is replicated
# and RowwiseParallel output layouts is replicated
"attention.wq": ColwiseParallel(),
"attention.wk": ColwiseParallel(),
"attention.wv": ColwiseParallel(),
"attention.wo": RowwiseParallel(),
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(),
"feed_forward.w3": ColwiseParallel(),
}
這幾乎是我們需要將張量平行處理應用於 TransformerBlock 的 layer_tp_plan。但是,我們應該注意的一件事是,當以欄方式對線性層進行分片時,線性層的輸出將在最後一個張量維度上被分片,而列式分片線性層直接接受在最後一個維度上分片的輸入。如果在欄式線性層和列式線性層之間還有更多的張量操作(例如檢視操作),我們需要將相關的形狀相關操作調整為分片形狀。
對於 Llama 模型,在 attention 層中,有一些與形狀相關的檢視操作。特別是,對於 wq/ wk/ wv 線性層的欄式平行,activation 張量在 num_heads 維度上分片,因此我們需要將 num_heads 調整為本機 num_heads。
最後,我們需要呼叫 parallelize_module API,使每個 TransformerBlock 的規劃生效。在底層,它會將 Attention 和 FeedForward 層中的模型參數分發到 DTensors,並在必要時為模型輸入和輸出(分別在每個模組之前和之後)註冊通訊掛鉤。
for layer_id, transformer_block in enumerate(model.layers):
layer_tp_plan = {...} # i.e. the plan we just generated
# Adjust attention module to use the local number of heads
attn_layer = transformer_block.attention
attn_layer.n_heads = attn_layer.n_heads // tp_mesh.size()
attn_layer.n_kv_heads = attn_layer.n_kv_heads // tp_mesh.size()
parallelize_module(
module=transformer_block,
device_mesh=tp_mesh,
parallelize_plan=layer_tp_plan,
)
現在我們已經詳細說明了每個 TransformerBlock 的分片計畫,通常在第一層有一個 nn.Embedding 和一個最終的 nn.Linear 投影層,使用者可以選擇對第一個 nn.Embedding 進行按行或按列分片,以及對最後一個 nn.Linear 投影層進行按列分片,並指定適當的輸入和輸出佈局。以下是一個範例:
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
),
"output": ColwiseParallel(
output_layouts=Replicate(),
),
}
)
注意
如果要分割的模型太大,無法放入 CPU 記憶體,可以選擇使用 meta 裝置初始化(例如,先在 meta 裝置上初始化模型,對層進行分片,然後實體化模型),或在 Transformer 模型初始化期間逐層平行化 TransformerBlock。
將序列平行應用於 LayerNorm/RMSNorm 層¶
序列平行建立在上述張量平行的基礎之上。與基本的張量平行相比,張量平行僅對 Attention 模組和 FeedForward 模組內的張量進行分片,並保持其模組輸入和輸出(即正向傳遞中的激活和反向傳遞中的梯度)複製,而序列平行則保持它們在序列維度上進行分片。
在典型的 TransformerBlock 中,正向函數結合了範數層(LayerNorm 或 RMSNorm)、注意力層、前饋層和殘差連接。例如:
# forward in a TransformerBlock
def forward(self, x):
h = x + self.attention(self.attention_norm(x))
out = h + self.feed_forward(self.ffn_norm(h))
return out
在大多數情況下,激活(和梯度)在 Attention 和 FeedForward 模組之外的形狀為 [batch size, sequence length, hidden dimension]。 在 DTensor 的語言中,序列平行使用 Shard(1) 佈局執行模組正向/反向的激活計算。按照之前的程式碼範例,下面的程式碼示範了如何將序列平行應用於 TransformerBlock 內的範數層
首先,讓我們導入序列平行所需的依賴項
from torch.distributed.tensor.parallel import (
PrepareModuleInput,
SequenceParallel,
)
接下來,讓我們調整 layer_tp_plan,以在 RMSNorm 層上啟用序列平行
layer_tp_plan = {
# Now the input and output of SequenceParallel has Shard(1) layouts,
# to represent the input/output tensors sharded on the sequence dimension
"attention_norm": SequenceParallel(),
"attention": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"attention.wq": ColwiseParallel(),
"attention.wk": ColwiseParallel(),
"attention.wv": ColwiseParallel(),
"attention.wo": RowwiseParallel(output_layouts=Shard(1)),
"ffn_norm": SequenceParallel(),
"feed_forward": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(output_layouts=Shard(1)),
"feed_forward.w3": ColwiseParallel(),
}
可以看到,我們現在使用 PrepareModuleInput 將 Attention 和 FeedForward 層的模組輸入佈局從 Shard(1) 修改為 Replicate(),並將它們的輸出佈局標記為 Shard(1)。就像張量平行一樣,只需要指定輸入和輸出的張量分片佈局,層之間的通訊就會自動發生。
請注意,使用序列平行,我們假設 TransformerBlock 的輸入和輸出始終在序列維度上進行分片,以便可以無縫地串聯多個 TransformerBlocks。這可以通過顯式指定開始的 nn.Embedding 層的輸出和最終 nn.Linear 投影層的輸入為 Shard(1) 來實現
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
output_layouts=Shard(1),
),
"norm": SequenceParallel(),
"output": ColwiseParallel(
input_layouts=Shard(1),
output_layouts=Replicate()
),
}
)
應用損失平行¶
當計算損失函數時,損失平行是一種相關的技術,可以節省記憶體和通訊,因為模型輸出通常非常大。在損失平行中,當模型輸出在(通常很大的)詞彙表維度上進行分片時,可以有效地計算交叉熵損失,而無需將所有模型輸出收集到每個 GPU。這不僅顯著降低了記憶體消耗,還通過減少通訊開銷和平行執行分片計算來提高訓練速度。下面的圖片簡要說明了損失平行如何通過執行分片計算來避免將所有模型輸出收集到每個 GPU。
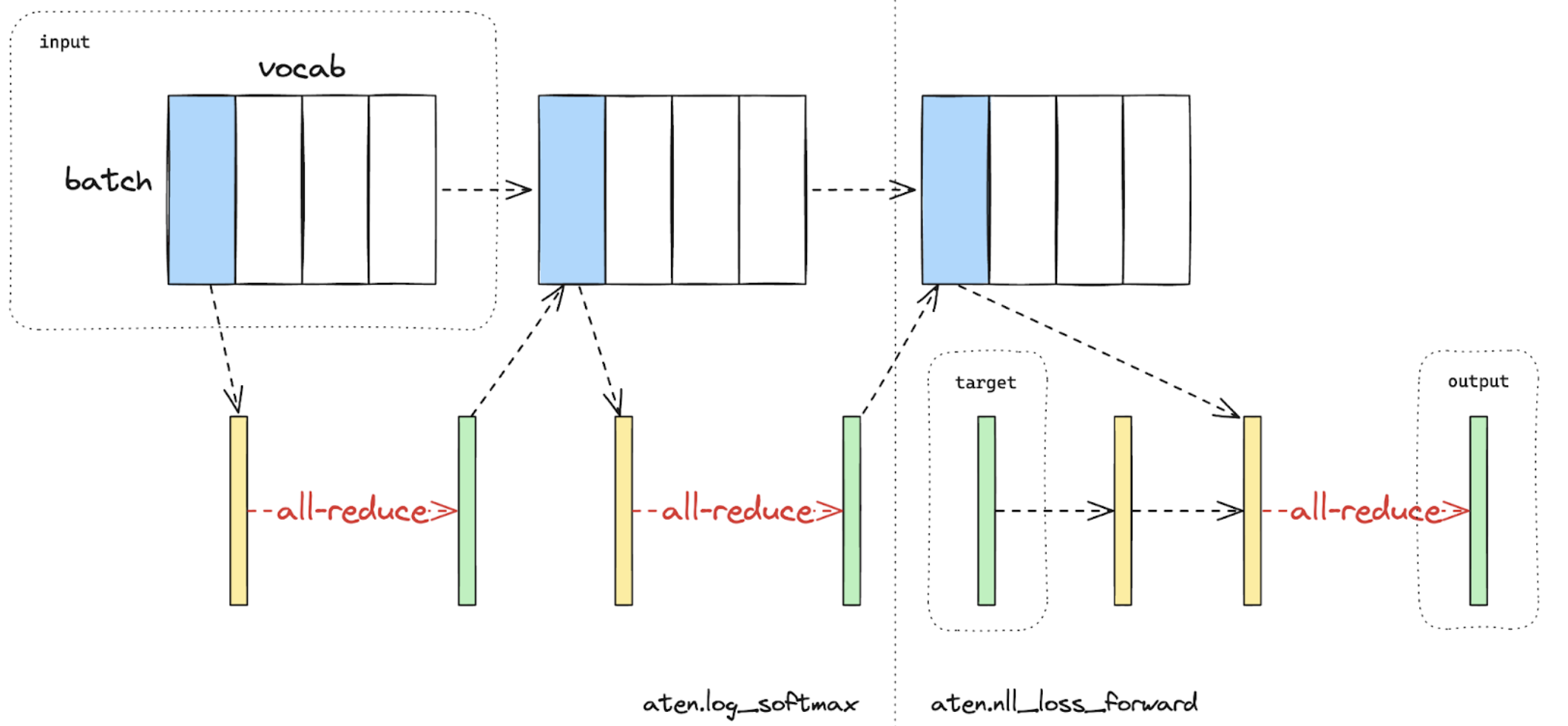
圖 2. 在一個 GPU 上使用損失平行進行交叉熵損失正向計算。藍色表示分片張量;綠色表示複製張量;黃色表示具有部分值的張量(將被 all-reduced)。黑色箭頭是本地計算;紅色箭頭是 GPU 之間的函數式集合。¶
在 PyTorch 張量平行 API 中,可以通過上下文管理器 loss_parallel 啟用損失平行,通過該管理器可以直接使用 torch.nn.functional.cross_entropy 或 torch.nn.CrossEntropyLoss,而無需修改程式碼的其他部分。
要應用損失平行,模型預測通常應以 [batch size, sequence length, vocabulary size] 的形狀在詞彙表維度上進行分片。這可以通過標記最後一個線性投影層輸出的輸出佈局來輕鬆完成
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
output_layouts=Shard(1),
),
"norm": SequenceParallel(),
"output": ColwiseParallel(
input_layouts=Shard(1),
# use DTensor as the output
use_local_output=False,
),
},
)
在上面的程式碼中,我們還將序列平行應用於輸出之前的範數層。我們應用 use_local_output=False 以使輸出保持為 DTensor,以便與 loss_parallel 上下文管理器一起使用。之後,可以簡單地呼叫交叉熵損失函數,如下所示。請注意,反向計算也需要在上下文中進行。
import torch.nn.functional as F
from torch.distributed.tensor.parallel import loss_parallel
pred = model(input_ids)
with loss_parallel():
# assuming pred and labels are of the shape [batch, seq, vocab]
loss = F.cross_entropy(pred.flatten(0, 1), labels.flatten(0, 1))
loss.backward()
將張量平行與完全分片資料平行結合在一起¶
現在我們已經展示了如何將張量/序列平行應用於模型,讓我們也看看張量平行和完全分片資料平行如何協同工作。由於張量平行會產生阻塞計算的通訊,因此我們希望確保它在快速通訊通道(如 NVLink)中執行。在實踐中,我們通常在每個主機內應用張量平行,並跨主機應用完全分片資料平行。
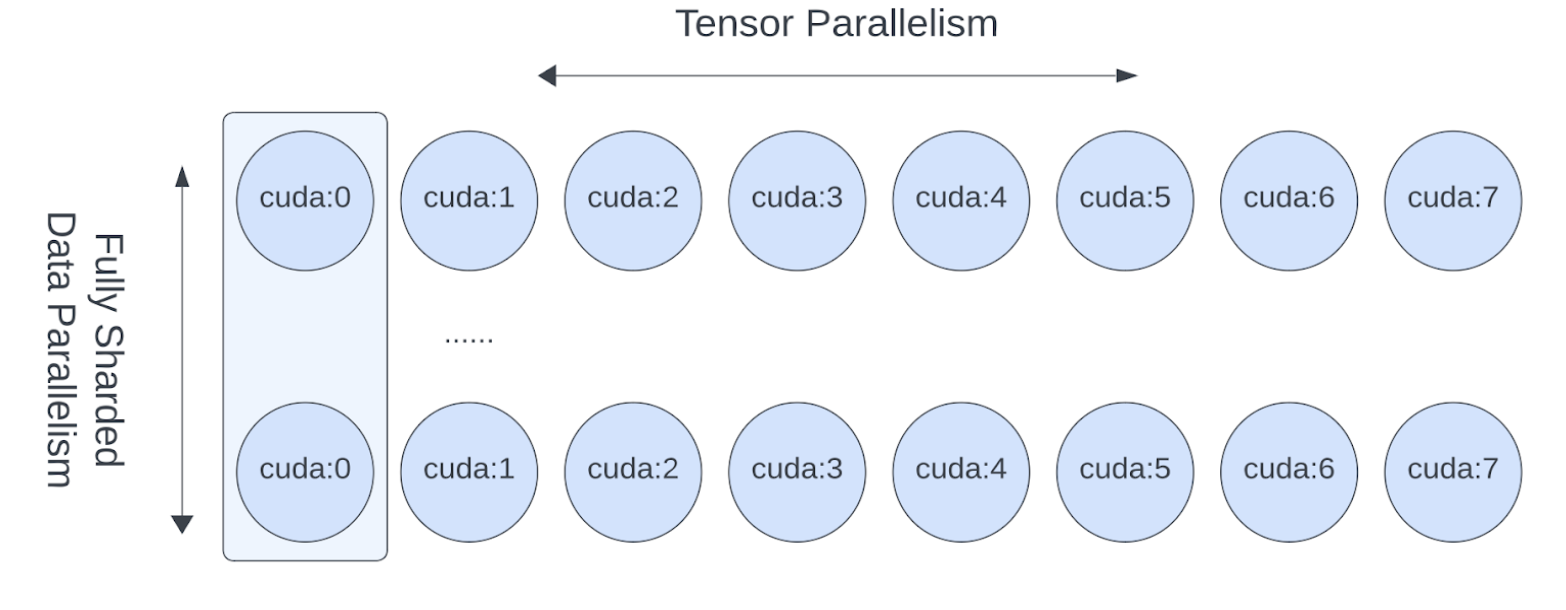
圖 3. FSDP 和 TP 在單獨的設備維度上工作,FSDP 通訊發生在主機之間,TP 通訊發生在主機內。¶
這種二維平行模式可以通過二維 DeviceMesh 輕鬆表達,我們只需要將每個“子” DeviceMesh 傳遞給每個單獨的平行 API
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_module
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
# i.e. 2-D mesh is [dp, tp], training on 64 GPUs that performs 8 way DP and 8 way TP
mesh_2d = init_device_mesh("cuda", (8, 8))
tp_mesh = mesh_2d["tp"] # a submesh that connects intra-host devices
dp_mesh = mesh_2d["dp"] # a submesh that connects inter-host devices
model = Model(...)
tp_plan = {...}
# apply Tensor Parallel intra-host on tp_mesh
model_tp = parallelize_module(model, tp_mesh, tp_plan)
# apply FSDP inter-host on dp_mesh
model_2d = FSDP(model_tp, device_mesh=dp_mesh, use_orig_params=True, ...)
這將使我們能夠輕鬆地在每個主機內(主機內)應用張量平行,並跨主機(主機間)應用 FSDP,並且 0 程式碼變更 到 Llama 模型。張量(模型)平行和資料平行技術相結合,提供了繼續增加模型大小並使用大量 GPU 有效訓練的能力。
