


DeviceMesh 入門¶
建立於:2024 年 1 月 24 日 | 最後更新:2025 年 1 月 08 日 | 最後驗證:2024 年 11 月 05 日
作者: Iris Zhang, Wanchao Liang
注意
 在 github 中檢視和編輯本教學。
在 github 中檢視和編輯本教學。
先決條件
Python 3.8 - 3.11
PyTorch 2.2
為分散式訓練設定分散式通訊器,例如 NVIDIA Collective Communication Library (NCCL) 通訊器,可能是一個巨大的挑戰。對於需要組合不同平行處理方式的工作負載,使用者需要手動設定和管理每個平行處理解決方案的 NCCL 通訊器(例如,ProcessGroup)。此過程可能很複雜且容易出錯。DeviceMesh 可以簡化此過程,使其更易於管理且不易出錯。
什麼是 DeviceMesh¶
DeviceMesh 是一個管理 ProcessGroup 的更高等級的抽象概念。 它允許使用者輕鬆建立節點間和節點內的進程組,而無需擔心如何為不同的子進程組正確設定排名。 使用者還可以透過 DeviceMesh 輕鬆管理多維平行處理的底層 process_groups/devices。
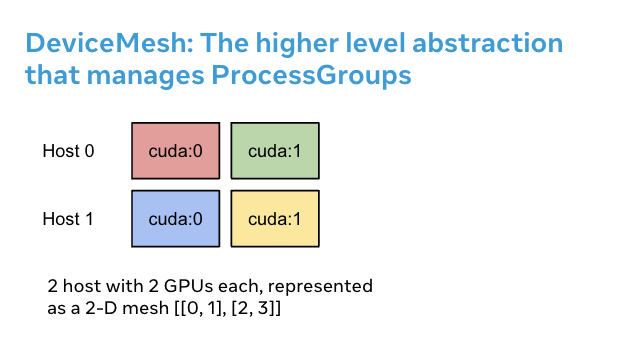
為什麼 DeviceMesh 有用¶
當使用需要平行處理可組合性的多維平行處理(即 3-D 平行處理)時,DeviceMesh 非常有用。 例如,當您的平行處理解決方案既需要跨主機通訊又需要在每個主機內通訊時。 上圖顯示我們可以建立一個 2D 網格,將每個主機內的裝置連接起來,並將每個裝置與同質設定中其他主機上的對應裝置連接起來。
如果沒有 DeviceMesh,使用者需要手動設定 NCCL 通訊器,在應用任何平行處理之前設定每個進程上的 cuda 裝置,這可能會非常複雜。 以下程式碼片段說明了在沒有 DeviceMesh 的情況下設定混合分片 2-D 平行模式。 首先,我們需要手動計算分片群組和複製群組。 然後,我們需要將正確的分片和複製群組分配給每個排名。
import os
import torch
import torch.distributed as dist
# Understand world topology
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
print(f"Running example on {rank=} in a world with {world_size=}")
# Create process groups to manage 2-D like parallel pattern
dist.init_process_group("nccl")
torch.cuda.set_device(rank)
# Create shard groups (e.g. (0, 1, 2, 3), (4, 5, 6, 7))
# and assign the correct shard group to each rank
num_node_devices = torch.cuda.device_count()
shard_rank_lists = list(range(0, num_node_devices // 2)), list(range(num_node_devices // 2, num_node_devices))
shard_groups = (
dist.new_group(shard_rank_lists[0]),
dist.new_group(shard_rank_lists[1]),
)
current_shard_group = (
shard_groups[0] if rank in shard_rank_lists[0] else shard_groups[1]
)
# Create replicate groups (for example, (0, 4), (1, 5), (2, 6), (3, 7))
# and assign the correct replicate group to each rank
current_replicate_group = None
shard_factor = len(shard_rank_lists[0])
for i in range(num_node_devices // 2):
replicate_group_ranks = list(range(i, num_node_devices, shard_factor))
replicate_group = dist.new_group(replicate_group_ranks)
if rank in replicate_group_ranks:
current_replicate_group = replicate_group
要執行上述程式碼片段,我們可以利用 PyTorch Elastic。 讓我們建立一個名為 2d_setup.py 的檔案。 然後,執行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 --rdzv_id=100 --rdzv_endpoint=localhost:29400 2d_setup.py
注意
為了簡化演示,我們僅使用一個節點來模擬 2D 平行處理。 請注意,此程式碼片段也可用於在多主機設定上執行。
借助 init_device_mesh(),我們只需兩行即可完成上述 2D 設定,如果需要,我們仍然可以存取底層 ProcessGroup。
from torch.distributed.device_mesh import init_device_mesh
mesh_2d = init_device_mesh("cuda", (2, 4), mesh_dim_names=("replicate", "shard"))
# Users can access the underlying process group thru `get_group` API.
replicate_group = mesh_2d.get_group(mesh_dim="replicate")
shard_group = mesh_2d.get_group(mesh_dim="shard")
讓我們建立一個名為 2d_setup_with_device_mesh.py 的檔案。 然後,執行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 2d_setup_with_device_mesh.py
如何將 DeviceMesh 與 HSDP 搭配使用¶
混合分片資料平行 (HSDP) 是一種在主機內執行 FSDP,並跨主機執行 DDP 的 2D 策略。
讓我們看一個範例,了解 DeviceMesh 如何在簡單的設定中協助您將 HSDP 應用於您的模型。 透過 DeviceMesh,使用者無需手動建立和管理分片群組和複製群組。
import torch
import torch.nn as nn
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP, ShardingStrategy
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
# HSDP: MeshShape(2, 4)
mesh_2d = init_device_mesh("cuda", (2, 4))
model = FSDP(
ToyModel(), device_mesh=mesh_2d, sharding_strategy=ShardingStrategy.HYBRID_SHARD
)
讓我們建立一個名為 hsdp.py 的檔案。 然後,執行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 hsdp.py
如何將 DeviceMesh 用於您的自訂平行處理解決方案¶
當使用大規模訓練時,您可能需要更複雜的自訂平行訓練組合。 例如,您可能需要為不同的平行處理解決方案切分出子網格。 DeviceMesh 允許使用者從父網格切分出子網格,並重複使用初始化父網格時已建立的 NCCL 通訊器。
from torch.distributed.device_mesh import init_device_mesh
mesh_3d = init_device_mesh("cuda", (2, 2, 2), mesh_dim_names=("replicate", "shard", "tp"))
# Users can slice child meshes from the parent mesh.
hsdp_mesh = mesh_3d["replicate", "shard"]
tp_mesh = mesh_3d["tp"]
# Users can access the underlying process group thru `get_group` API.
replicate_group = hsdp_mesh["replicate"].get_group()
shard_group = hsdp_mesh["shard"].get_group()
tp_group = tp_mesh.get_group()
