


Libuv TCPStore 後端介紹¶
建立於:2024 年 7 月 22 日 | 最後更新:2024 年 7 月 24 日 | 最後驗證:2024 年 11 月 05 日
作者: Xilun Wu
注意
 在 github 中檢視和編輯本教學。
在 github 中檢視和編輯本教學。
什麼是新的 TCPStore 後端
比較新的 libuv 後端與舊版後端
如何啟用以使用舊版後端
PyTorch 2.4 或更新版本
閱讀關於 TCPStore API 的資訊。
簡介¶
最近,我們推出了使用 libuv 的新 TCPStore 伺服器後端,libuv 是一個用於非同步 I/O 的第三方函式庫。 這個新的伺服器後端旨在解決大規模分散式訓練任務中的可擴展性和穩健性挑戰,例如那些具有超過 1024 個 ranks 的任務。 我們進行了一系列基準測試,將 libuv 後端與舊後端進行比較,實驗結果表明,在儲存初始化時間方面有了顯著的改進,並在儲存 I/O 操作中保持了相當的效能。
由於這些發現,libuv 後端已被設定為 PyTorch 2.4 中的預設 TCPStore 伺服器後端。 預計此變更將增強分散式訓練任務的效能和可擴展性。
此變更會對儲存初始化引入輕微的不相容性。 對於希望繼續使用舊版後端的使用者,本教學將提供有關如何指定使用先前的 TCPStore 伺服器後端的指南。
效能基準測試¶
為了更好地展示我們新的 libuv TCPStore 後端的好處,我們在從 1024 (1K) 到 98304 (96K) ranks 的廣泛任務規模範圍內設置了基準測試。 我們首先使用下面的程式碼片段測量了 TCPStore 初始化時間
import logging
import os
from time import perf_counter
import torch
import torch.distributed as dist
logger: logging.Logger = logging.getLogger(__name__)
# Env var are preset when launching the benchmark
env_rank = os.environ.get("RANK", 0)
env_world_size = os.environ.get("WORLD_SIZE", 1)
env_master_addr = os.environ.get("MASTER_ADDR", "localhost")
env_master_port = os.environ.get("MASTER_PORT", "23456")
start = perf_counter()
tcp_store = dist.TCPStore(
env_master_addr,
int(env_master_port),
world_size=int(env_world_size),
is_master=(int(env_rank) == 0),
)
end = perf_counter()
time_elapsed = end - start
logger.info(
f"Complete TCPStore init with rank={env_rank}, world_size={env_world_size} in {time_elapsed} seconds."
)
由於 TCPStore 伺服器線程的執行將被阻止,直到所有客戶端都成功連接,因此我們將在 rank 0 上測量的時間作為總 TCPStore 初始化運行時間。 實驗數字如下圖所示
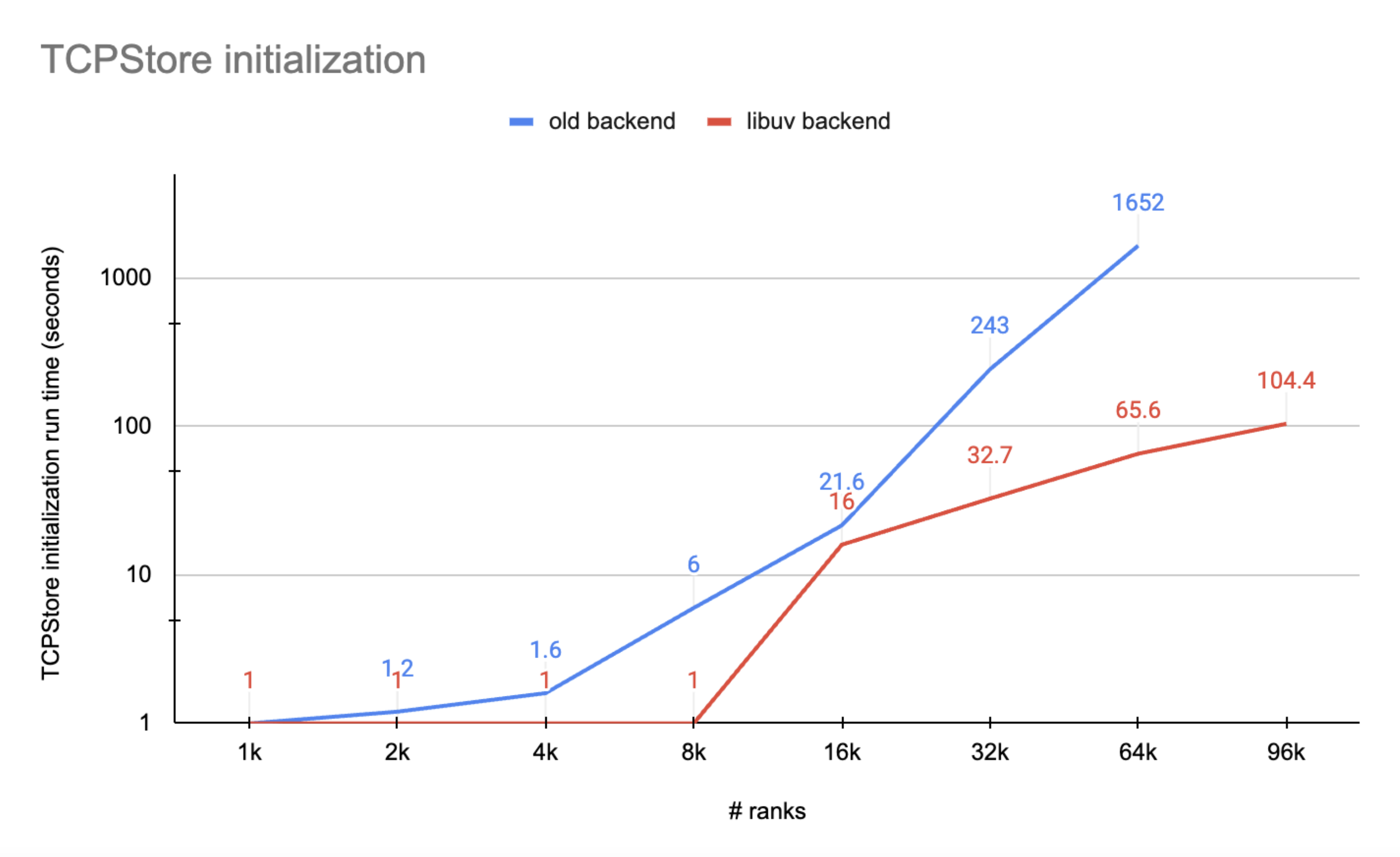
圖 1 顯示了一些重要的證據,表明 libuv 後端優於舊版後端
TCPStore 與 libuv 後端始終具有比舊版後端更快的初始化速度,尤其是在超大規模時
舊版後端會在 96K 規模的伺服器-客戶端連線時超時 (例如,超過 30 分鐘),而 libuv 後端在 100 秒內完成初始化。
我們做的第二個基準測試是測量 TCPStore store_based_barrier 操作的運行時間
import logging
import os
import time
from datetime import timedelta
from time import perf_counter
import torch
import torch.distributed as dist
DistStoreError = torch._C._DistStoreError
logger: logging.Logger = logging.getLogger(__name__)
# since dist._store_based_barrier is a private function and cannot be directly called, we need to write a function which does the same
def store_based_barrier(
rank,
store,
group_name,
rendezvous_count,
timeout=dist.constants.default_pg_timeout,
logging_interval=timedelta(seconds=10),
):
store_key = f"store_based_barrier_key:{group_name}"
store.add(store_key, 1)
world_size = rendezvous_count
worker_count = store.add(store_key, 0)
last_worker_key = f"{store_key}:last_worker"
if worker_count == world_size:
store.set(last_worker_key, "1")
start = time.time()
while True:
try:
# This will throw an exception after the logging_interval in which we print out
# the status of the group or time out officially, throwing runtime error
store.wait([last_worker_key], logging_interval)
break
except RuntimeError as e:
worker_count = store.add(store_key, 0)
# Print status periodically to keep track.
logger.info(
"Waiting in store based barrier to initialize process group for "
"rank: %s, key: %s (world_size=%s, num_workers_joined=%s, timeout=%s)"
"error: %s",
rank,
store_key,
world_size,
worker_count,
timeout,
e,
)
if timedelta(seconds=(time.time() - start)) > timeout:
raise DistStoreError(
"Timed out initializing process group in store based barrier on "
"rank {}, for key: {} (world_size={}, num_workers_joined={}, timeout={})".format(
rank, store_key, world_size, worker_count, timeout
)
)
logger.info(
"Rank %s: Completed store-based barrier for key:%s with %s nodes.",
rank,
store_key,
world_size,
)
# Env var are preset when launching the benchmark
env_rank = os.environ.get("RANK", 0)
env_world_size = os.environ.get("WORLD_SIZE", 1)
env_master_addr = os.environ.get("MASTER_ADDR", "localhost")
env_master_port = os.environ.get("MASTER_PORT", "23456")
tcp_store = dist.TCPStore(
env_master_addr,
int(env_master_port),
world_size=int(env_world_size),
is_master=(int(env_rank) == 0),
)
# sync workers
store_based_barrier(int(env_rank), tcp_store, "tcpstore_test", int(env_world_size))
number_runs = 10
start = perf_counter()
for _ in range(number_runs):
store_based_barrier(
int(env_rank), tcp_store, "tcpstore_test", int(env_world_size)
)
end = perf_counter()
time_elapsed = end - start
logger.info(
f"Complete {number_runs} TCPStore barrier runs with rank={env_rank}, world_size={env_world_size} in {time_elapsed} seconds."
)
我們將 rank 0 上測量的運行時間除以 number_runs 來計算平均值,並在下圖中報告它
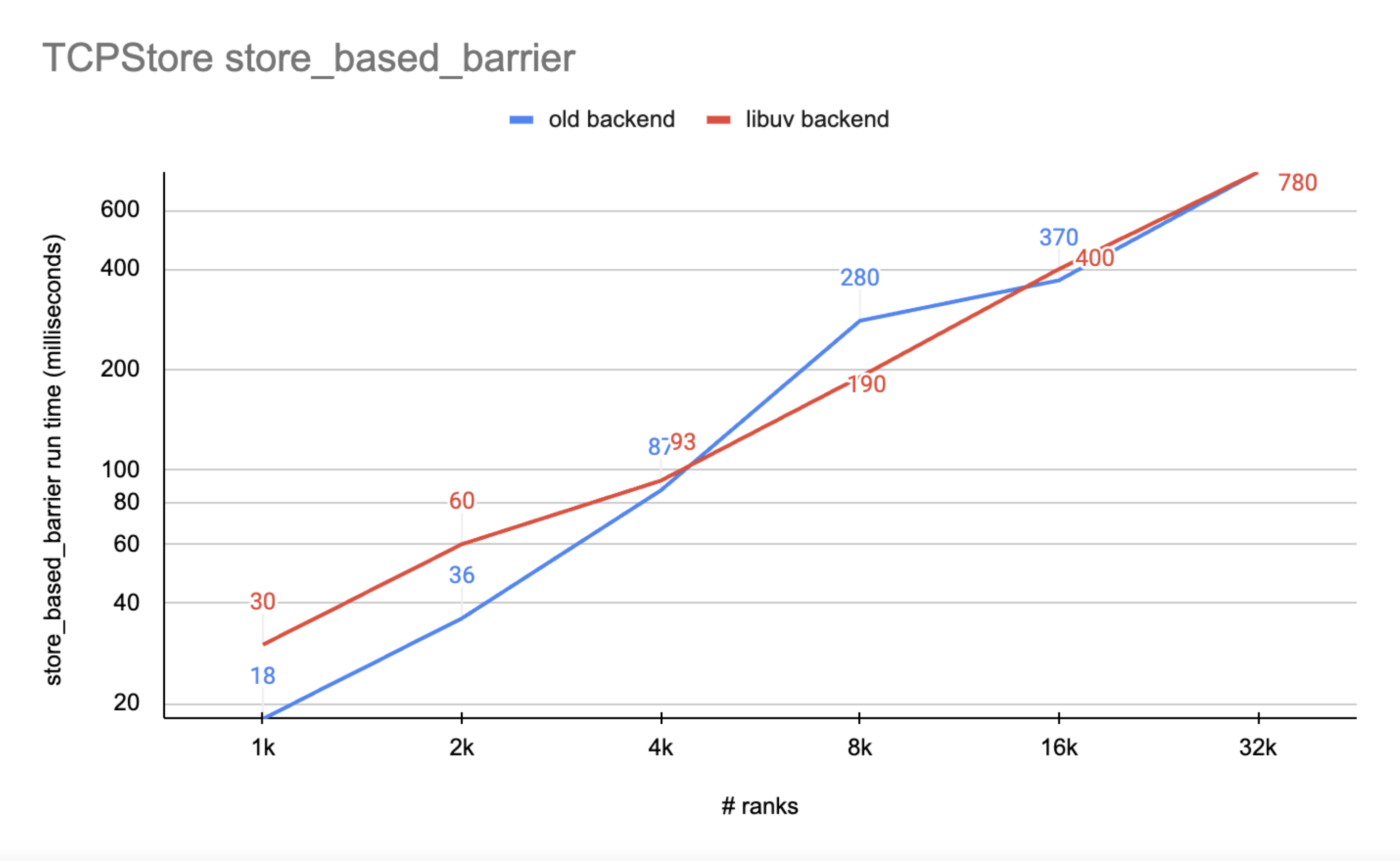
圖 2 顯示 libuv 後端的 I/O 效能與舊版後端相當
就 rank 數量而言,libuv 後端在整個範圍內都具有相當的效能
隨著 rank 數量的增長,libuv 後端的運行時間比舊版後端更穩定
影響¶
使用者可能需要注意的一個不相容之處是,在使用 libuv 後端時,TCPStore 目前不支援使用 listen_fd 進行初始化。 如果使用者想繼續使用此初始化方法,使用者只需傳遞 use_libuv=False 即可使用舊的 TCPStore 後端。
import socket
import torch
import torch.distributed as dist
listen_sock: socket.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_sock.bind(("localhost", 0))
addr, port, *_ = listen_sock.getsockname()
listen_fd = listen_sock.detach()
tcpstore = dist.TCPStore(addr, port, 1, True, master_listen_fd=listen_fd) # expect NotImplementedError
tcpstore = dist.TCPStore(addr, port, 1, True, master_listen_fd=listen_fd, use_libuv=False) # OK. Use legacy backend
退出途徑 1:將 use_libuv=False 傳遞給 TCPStore 初始化¶
如上面的程式碼片段所示,如果使用者呼叫 TCPStore init 方法來建立儲存,只需傳遞 use_libuv=False 即可讓使用者繼續使用舊的 TCPStore 後端。 這種覆蓋優先順序高於其他決定 TCPStore 伺服器應選擇哪個後端的方法。
退出途徑 2:在 ProcessGroup 初始化時將 use_libuv=0 新增到 init_method¶
如果使用者沒有明確地將 TCPStore 傳遞給 ProcessGroup 的初始化,則 ProcessGroup 會建立一個 TCPStore。使用者可以在初始化 ProcessGroup 時,將查詢選項 use_libuv=0 加入到 init_method 中。這種方法的優先順序低於退出路徑 1。
import torch
import torch.distributed as dist
addr = "localhost"
port = 23456
dist.init_process_group(
backend="cpu:gloo,cuda:nccl",
rank=0,
world_size=1,
init_method=f"tcp://{addr}:{port}?use_libuv=0",
)
dist.destroy_process_group()
退出路徑 3:將環境變數 USE_LIBUV 設為 0¶
當 ProcessGroup 建立 TCPStore 時,它也會檢查環境變數 USE_LIBUV 以確定要使用哪個 TCPStore 後端。使用者可以將環境變數 "USE_LIBUV" 設為 "0",以指定使用舊的 TCPStore 後端。這種方法的優先順序低於退出路徑 2。例如,如果使用者將環境變數 USE_LIBUV 設為 1,並且在 init_method 中也傳遞了 use_libuv=0,則會選擇舊的 store 後端。
import os
import torch
import torch.distributed as dist
addr = "localhost"
port = 23456
os.environ["USE_LIBUV"] = "0"
dist.init_process_group(
backend="cpu:gloo,cuda:nccl",
rank=0,
world_size=1,
init_method=f"tcp://{addr}:{port}",
)
dist.destroy_process_group()
結論¶
在 PyTorch 2.4 中,我們將新的 libuv TCPStore 後端設為預設值。儘管新的後端與從 listen_fd 初始化的方式不相容,但它在大型規模的 store 初始化方面顯示出顯著的性能提升,並且在小/中/大型規模的 store I/O 方面具有相容的性能,這為分散式訓練的控制平面帶來了主要的優勢。本教學說明了我們的動機,介紹了性能基準,通知使用者潛在的影響,並介紹了三種退出路徑,以繼續使用舊版後端。從長遠來看,我們的目標是最終棄用舊版後端。
