


編譯後的自動微分:為 torch.compile 捕獲更大的反向圖¶
建立於:2024 年 10 月 9 日 | 最後更新:2024 年 10 月 23 日 | 最後驗證:2024 年 10 月 9 日
作者: Simon Fan
編譯後的自動微分如何與
torch.compile互動如何使用編譯後的自動微分 API
如何使用
TORCH_LOGS檢查日誌
PyTorch 2.4
閱讀 PyTorch 2.x 入門 的 TorchDynamo 和 AOTAutograd 部分
概述¶
編譯後的自動微分是 PyTorch 2.4 中引入的 torch.compile 擴充,允許捕獲更大的反向圖。
雖然 torch.compile 確實捕獲了反向圖,但它只是部分捕獲。 AOTAutograd 組件會提前捕獲反向圖,但有一些限制
前向圖中的中斷會導致反向圖中的中斷
反向鉤子未被捕獲
編譯後的自動微分透過直接與 autograd 引擎整合來解決這些限制,使其能夠在運行時捕獲完整的反向圖。具有這兩個特徵的模型應該嘗試編譯後的自動微分,並可能觀察到更好的效能。
然而,編譯後的自動微分引入了自己的限制
在反向傳播開始時增加運行時開銷以進行快取查詢
由於更大的捕獲範圍,更容易在 dynamo 中重新編譯和產生圖中斷
注意
編譯後的自動微分正在積極開發中,並且尚未與所有現有的 PyTorch 功能相容。有關特定功能的最新狀態,請參閱 編譯後的自動微分著陸頁。
設定¶
在本教學中,我們將以這個簡單的神經網路模型為例。 它接受一個 10 維的輸入向量,透過一個線性層處理它,然後輸出另一個 10 維的向量。
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(10, 10)
def forward(self, x):
return self.linear(x)
基本用法¶
在呼叫 torch.compile API 之前,請確保將 torch._dynamo.config.compiled_autograd 設定為 True
model = Model()
x = torch.randn(10)
torch._dynamo.config.compiled_autograd = True
@torch.compile
def train(model, x):
loss = model(x).sum()
loss.backward()
train(model, x)
在上面的程式碼中,我們建立 Model 類別的實例,並使用 torch.randn(10) 產生一個隨機的 10 維張量 x。 我們定義了訓練迴圈函式 train,並使用 @torch.compile 修飾器來最佳化其執行。 當呼叫 train(model, x) 時
Python Interpreter 呼叫 Dynamo,因為這個呼叫是用
@torch.compile修飾的。Dynamo 攔截 Python 位元組碼,模擬它們的執行,並將操作記錄到圖中。
AOTDispatcher停用鉤子並呼叫 autograd 引擎來計算model.linear.weight和model.linear.bias的梯度,並將操作記錄到圖中。使用torch.autograd.Function,AOTDispatcher 重寫了train的前向和反向實作。Inductor 產生一個對應於 AOTDispatcher 前向和反向的最佳化實作的函式。
Dynamo 設定 Python Interpreter 接下來要評估的最佳化函式。
Python Interpreter 執行最佳化函式,該函式執行
loss = model(x).sum()。Python Interpreter 執行
loss.backward(),呼叫到 autograd 引擎,由於我們設定了torch._dynamo.config.compiled_autograd = True,因此路由到編譯後的自動微分引擎。Compiled Autograd 會計算
model.linear.weight和model.linear.bias的梯度,並將運算記錄到一個圖表中,包括它遇到的任何 hook。在此過程中,它會記錄先前由 AOTDispatcher 重寫的反向傳播。然後,Compiled Autograd 會生成一個新的函式,該函式對應於loss.backward()的完全追蹤實作,並以推論模式使用torch.compile執行它。相同的步驟會遞迴地應用於 Compiled Autograd 圖表,但這次 AOTDispatcher 將不需要分割圖表。
檢視已編譯的 Autograd 紀錄¶
使用 TORCH_LOGS 環境變數執行腳本
若只要印出已編譯的 autograd 圖表,請使用
TORCH_LOGS="compiled_autograd" python example.py若要印出包含更多張量元數據和重新編譯原因的圖表,但會犧牲效能,請使用
TORCH_LOGS="compiled_autograd_verbose" python example.py
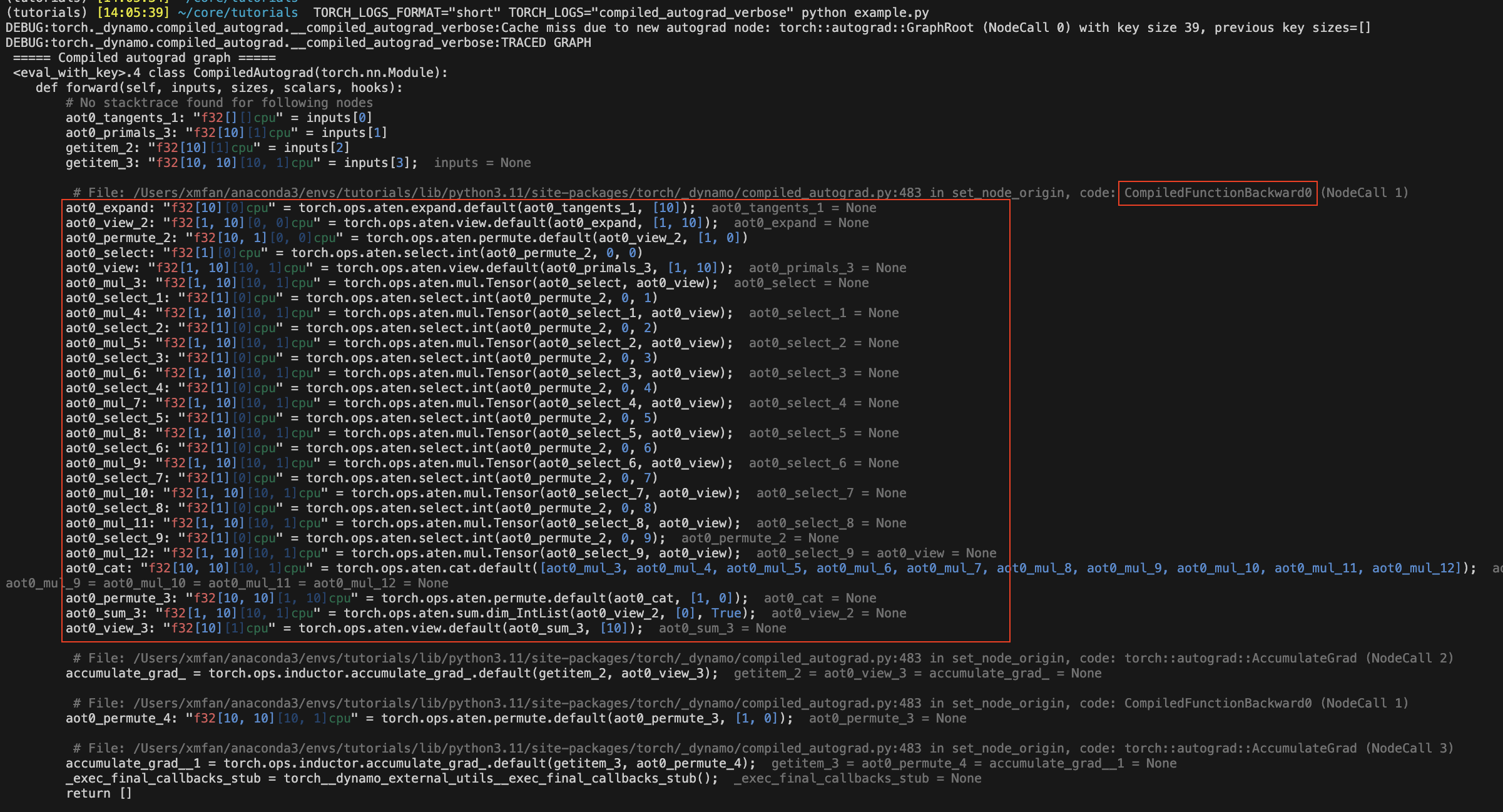
重新執行上面的程式碼片段,現在已編譯的 autograd 圖表應該會記錄到 stderr。某些圖表節點的名稱會以 aot0_ 作為前綴,這些節點對應於先前在 AOTAutograd 反向圖表 0 中預先編譯的節點,例如,aot0_view_2 對應於 ID=0 的 AOT 反向圖表的 view_2。
在下面的圖片中,紅色框框封裝了由 torch.compile 捕獲的 AOT 反向圖表,而未使用 Compiled Autograd。
注意
這是我們將呼叫 torch.compile 的圖表,**不是**最佳化的圖表。Compiled Autograd 基本上會生成一些未最佳化的 Python 程式碼來表示整個 C++ autograd 執行。
使用不同的標誌編譯前向和反向傳遞¶
您可以為兩個編譯使用不同的編譯器配置,例如,即使前向傳遞中有圖表斷裂,反向傳遞也可以是完整圖表。
def train(model, x):
model = torch.compile(model)
loss = model(x).sum()
torch._dynamo.config.compiled_autograd = True
torch.compile(lambda: loss.backward(), fullgraph=True)()
或者,您可以使用上下文管理器,它會套用到其範圍內的所有 autograd 呼叫。
def train(model, x):
model = torch.compile(model)
loss = model(x).sum()
with torch._dynamo.compiled_autograd.enable(torch.compile(fullgraph=True)):
loss.backward()
Compiled Autograd 解決了 AOTAutograd 的某些限制¶
前向傳遞中的圖表斷裂不再一定會導致反向傳遞中的圖表斷裂
@torch.compile(backend="aot_eager")
def fn(x):
# 1st graph
temp = x + 10
torch._dynamo.graph_break()
# 2nd graph
temp = temp + 10
torch._dynamo.graph_break()
# 3rd graph
return temp.sum()
x = torch.randn(10, 10, requires_grad=True)
torch._dynamo.utils.counters.clear()
loss = fn(x)
# 1. base torch.compile
loss.backward(retain_graph=True)
assert(torch._dynamo.utils.counters["stats"]["unique_graphs"] == 3)
torch._dynamo.utils.counters.clear()
# 2. torch.compile with compiled autograd
with torch._dynamo.compiled_autograd.enable(torch.compile(backend="aot_eager")):
loss.backward()
# single graph for the backward
assert(torch._dynamo.utils.counters["stats"]["unique_graphs"] == 1)
在第一個 torch.compile 的情況下,我們看到由於已編譯函式 fn 中的 2 個圖表斷裂,產生了 3 個反向圖表。而在第二個使用已編譯 autograd 的 torch.compile 的情況下,我們看到儘管有圖表斷裂,但仍追蹤到完整的反向圖表。
注意
Dynamo 在追蹤 Compiled Autograd 捕獲的反向 hook 時,仍然有可能發生圖表斷裂。
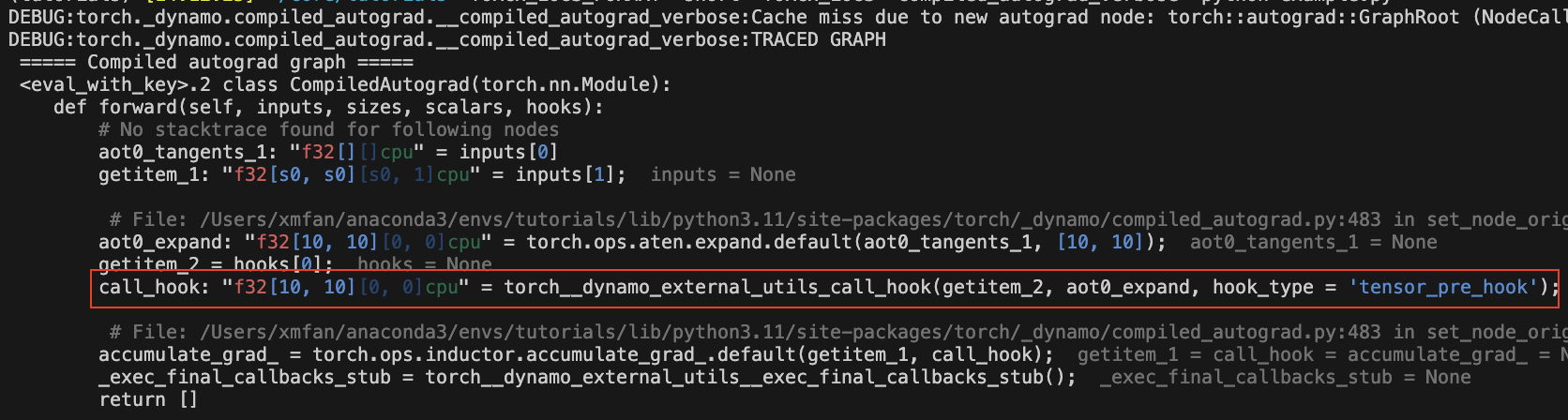
現在可以捕獲反向 hook
@torch.compile(backend="aot_eager")
def fn(x):
return x.sum()
x = torch.randn(10, 10, requires_grad=True)
x.register_hook(lambda grad: grad+10)
loss = fn(x)
with torch._dynamo.compiled_autograd.enable(torch.compile(backend="aot_eager")):
loss.backward()
圖表中應該有一個 call_hook 節點,Dynamo 稍後會將其內聯到以下內容中
Compiled Autograd 的常見重新編譯原因¶
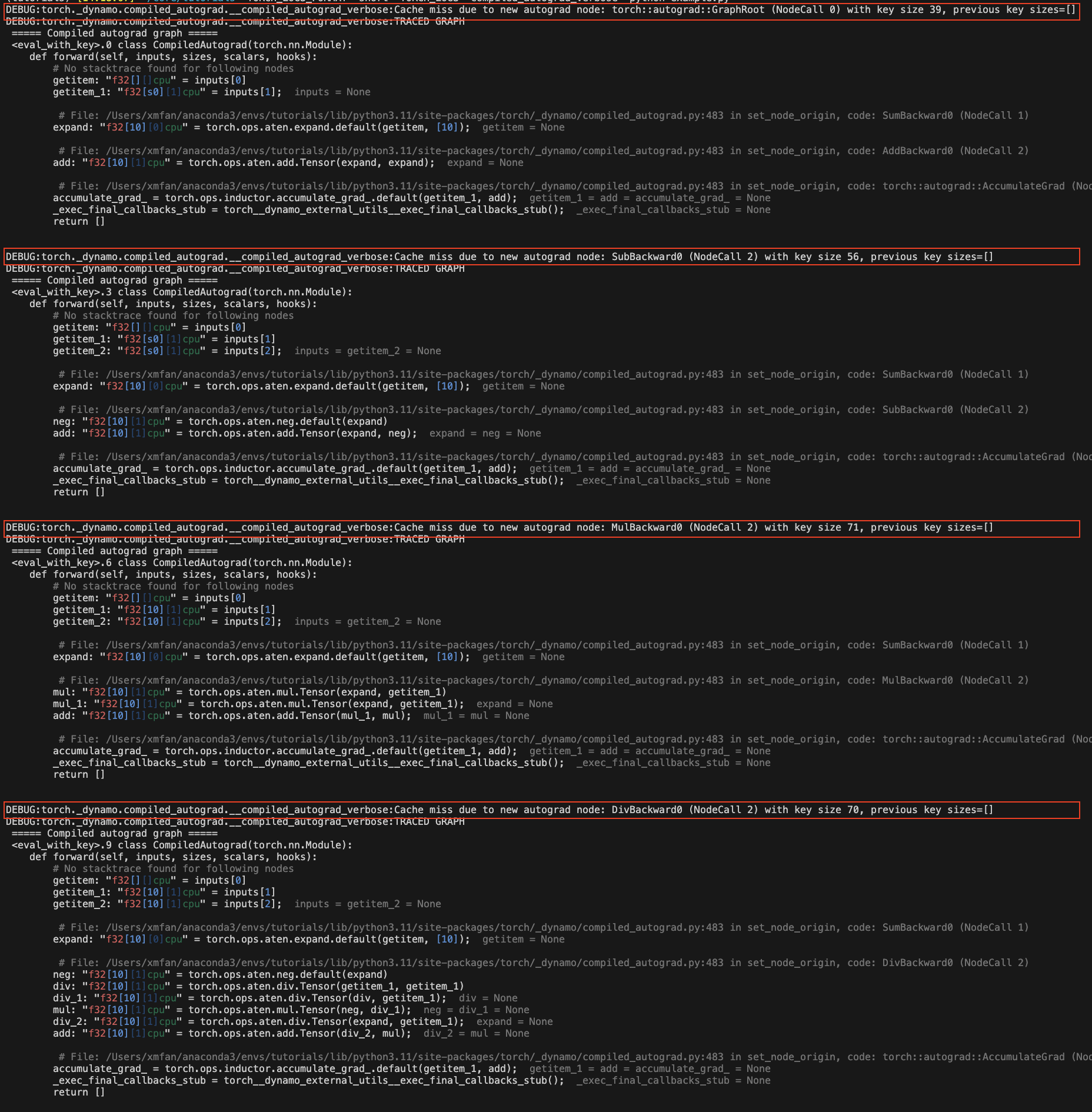
由於損失值的 autograd 結構發生變化
torch._dynamo.config.compiled_autograd = True
x = torch.randn(10, requires_grad=True)
for op in [torch.add, torch.sub, torch.mul, torch.div]:
loss = op(x, x).sum()
torch.compile(lambda: loss.backward(), backend="eager")()
在上面的範例中,我們在每次迭代中呼叫不同的運算子,導致 loss 每次都追蹤不同的 autograd 歷史記錄。您應該會看到一些重新編譯訊息:**Cache miss due to new autograd node**。
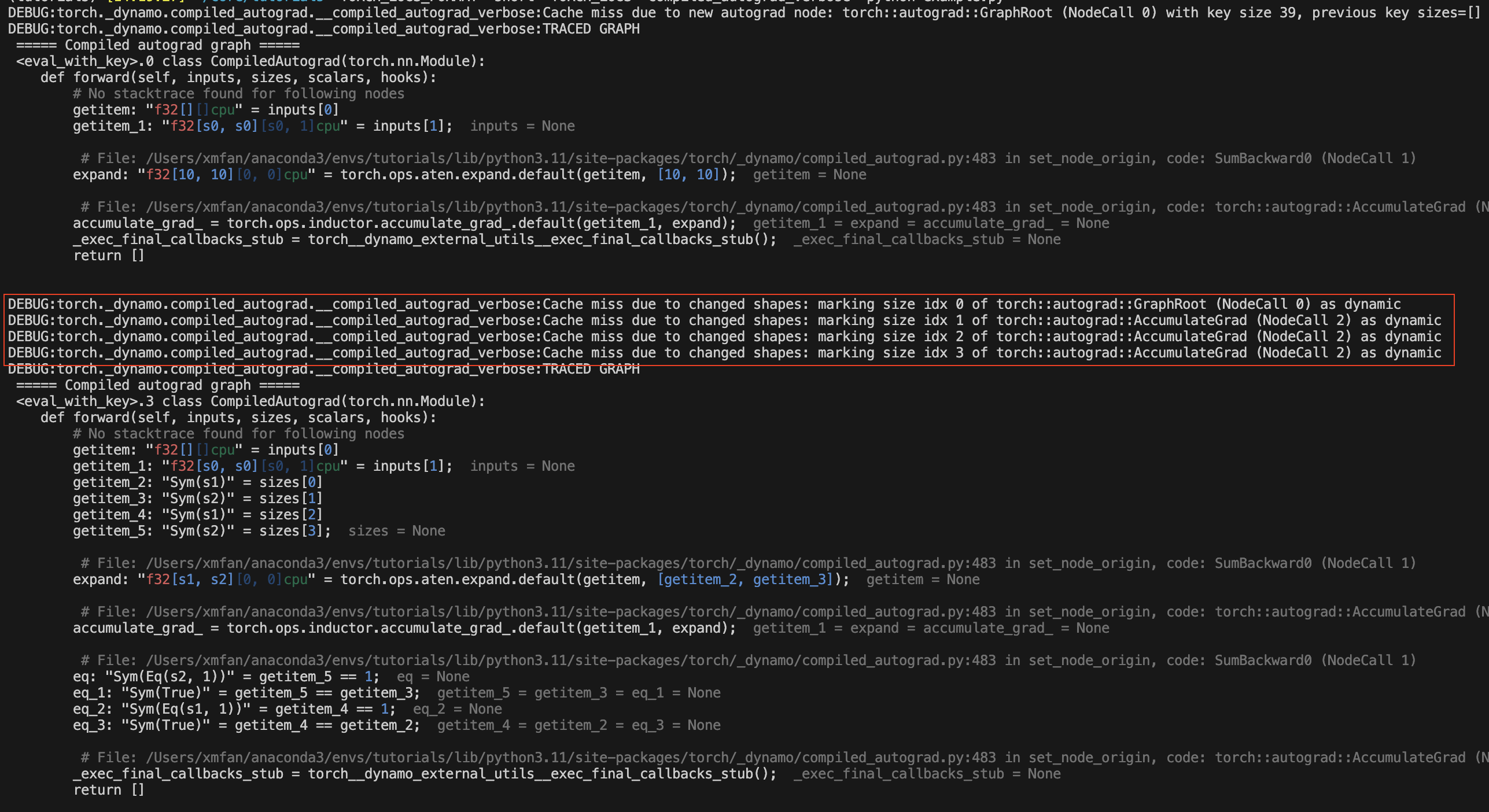
由於張量形狀改變
torch._dynamo.config.compiled_autograd = True
for i in [10, 100, 10]:
x = torch.randn(i, i, requires_grad=True)
loss = x.sum()
torch.compile(lambda: loss.backward(), backend="eager")()
在上面的範例中,x 的形狀會改變,並且在第一次變更後,已編譯的 autograd 會將 x 標記為動態形狀張量。您應該會看到重新編譯訊息:**Cache miss due to changed shapes**。
結論¶
在本教學課程中,我們介紹了 torch.compile 與已編譯 autograd 的高階生態系統、已編譯 autograd 的基礎知識以及一些常見的重新編譯原因。請繼續關注 dev-discuss 上的深入探討。
