


注意
點擊這裡下載完整範例程式碼
訓練一個玩瑪利歐的 RL 代理程式¶
建立於:2020 年 12 月 17 日 | 最後更新:2024 年 2 月 05 日 | 最後驗證:未驗證
作者: Yuansong Feng, Suraj Subramanian, Howard Wang, Steven Guo.
本教學課程將引導您了解深度強化學習的基礎知識。最後,您將實作一個由 AI 驅動的瑪利歐(使用 Double Deep Q-Networks),它可以自己玩遊戲。
雖然本教學課程不需要事先了解 RL,但您可以熟悉這些 RL 概念,並將此方便的 速查表 作為您的伴侶。完整的程式碼可在此處找到 這裡。

%%bash
pip install gym-super-mario-bros==7.4.0
pip install tensordict==0.3.0
pip install torchrl==0.3.0
import torch
from torch import nn
from torchvision import transforms as T
from PIL import Image
import numpy as np
from pathlib import Path
from collections import deque
import random, datetime, os
# Gym is an OpenAI toolkit for RL
import gym
from gym.spaces import Box
from gym.wrappers import FrameStack
# NES Emulator for OpenAI Gym
from nes_py.wrappers import JoypadSpace
# Super Mario environment for OpenAI Gym
import gym_super_mario_bros
from tensordict import TensorDict
from torchrl.data import TensorDictReplayBuffer, LazyMemmapStorage
RL 定義¶
環境 代理程式與之互動並從中學習的世界。
動作 \(a\):代理程式如何回應環境。所有可能動作的集合稱為動作空間。
狀態 \(s\):環境的目前特徵。環境可以處於的所有可能狀態的集合稱為狀態空間。
獎勵 \(r\):獎勵是環境對代理程式的關鍵回饋。它是驅使代理程式學習並改變其未來動作的原因。多個時間步長的獎勵聚合稱為 回報。
最佳動作值函數 \(Q^*(s,a)\):如果您從狀態 \(s\) 開始,採取任意動作 \(a\),然後對於每個未來的時間步長採取最大化回報的動作,則給出預期的回報。\(Q\) 可以說是代表狀態中動作的「品質」。我們嘗試近似此函數。
環境¶
初始化環境¶
在瑪利歐中,環境由水管、蘑菇和其他元件組成。
當瑪利歐採取動作時,環境會以變更的(下一個)狀態、獎勵和其他資訊來回應。
# Initialize Super Mario environment (in v0.26 change render mode to 'human' to see results on the screen)
if gym.__version__ < '0.26':
env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", new_step_api=True)
else:
env = gym_super_mario_bros.make("SuperMarioBros-1-1-v0", render_mode='rgb', apply_api_compatibility=True)
# Limit the action-space to
# 0. walk right
# 1. jump right
env = JoypadSpace(env, [["right"], ["right", "A"]])
env.reset()
next_state, reward, done, trunc, info = env.step(action=0)
print(f"{next_state.shape},\n {reward},\n {done},\n {info}")
/usr/local/lib/python3.10/dist-packages/gym/envs/registration.py:555: UserWarning:
WARN: The environment SuperMarioBros-1-1-v0 is out of date. You should consider upgrading to version `v3`.
/usr/local/lib/python3.10/dist-packages/gym/envs/registration.py:627: UserWarning:
WARN: The environment creator metadata doesn't include `render_modes`, contains: ['render.modes', 'video.frames_per_second']
/usr/local/lib/python3.10/dist-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning:
`np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24)
(240, 256, 3),
0.0,
False,
{'coins': 0, 'flag_get': False, 'life': 2, 'score': 0, 'stage': 1, 'status': 'small', 'time': 400, 'world': 1, 'x_pos': 40, 'y_pos': 79}
預處理環境¶
環境資料以 next_state 的形式返回給代理程式。如您在上面看到的,每個狀態都由一個 [3, 240, 256] 大小的陣列表示。通常,這比我們的代理程式需要的資訊更多;例如,瑪利歐的動作不取決於水管或天空的顏色!
我們使用 Wrappers 在將環境資料傳送給代理程式之前對其進行預處理。
GrayScaleObservation 是一個常見的 Wrapper,用於將 RGB 影像轉換為灰階;這樣做可以減少狀態表示的大小,而不會遺失有用的資訊。現在每個狀態的大小:[1, 240, 256]
ResizeObservation 將每個觀察值下取樣為方形影像。新大小:[1, 84, 84]
SkipFrame 是一個自訂 Wrapper,它繼承自 gym.Wrapper 並實作 step() 函數。因為連續影格變化不大,所以我們可以跳過 n 個中間影格,而不會遺失太多資訊。第 n 個影格會聚合每個跳過影格累積的獎勵。
FrameStack 是一個封裝器,能讓我們將環境中連續的影格壓縮成單一的觀察點,以便餵給我們的學習模型。這樣一來,我們就能根據 Mario 在前幾個影格中的移動方向來判斷他是正在著陸還是跳躍。
class SkipFrame(gym.Wrapper):
def __init__(self, env, skip):
"""Return only every `skip`-th frame"""
super().__init__(env)
self._skip = skip
def step(self, action):
"""Repeat action, and sum reward"""
total_reward = 0.0
for i in range(self._skip):
# Accumulate reward and repeat the same action
obs, reward, done, trunk, info = self.env.step(action)
total_reward += reward
if done:
break
return obs, total_reward, done, trunk, info
class GrayScaleObservation(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
obs_shape = self.observation_space.shape[:2]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def permute_orientation(self, observation):
# permute [H, W, C] array to [C, H, W] tensor
observation = np.transpose(observation, (2, 0, 1))
observation = torch.tensor(observation.copy(), dtype=torch.float)
return observation
def observation(self, observation):
observation = self.permute_orientation(observation)
transform = T.Grayscale()
observation = transform(observation)
return observation
class ResizeObservation(gym.ObservationWrapper):
def __init__(self, env, shape):
super().__init__(env)
if isinstance(shape, int):
self.shape = (shape, shape)
else:
self.shape = tuple(shape)
obs_shape = self.shape + self.observation_space.shape[2:]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def observation(self, observation):
transforms = T.Compose(
[T.Resize(self.shape, antialias=True), T.Normalize(0, 255)]
)
observation = transforms(observation).squeeze(0)
return observation
# Apply Wrappers to environment
env = SkipFrame(env, skip=4)
env = GrayScaleObservation(env)
env = ResizeObservation(env, shape=84)
if gym.__version__ < '0.26':
env = FrameStack(env, num_stack=4, new_step_api=True)
else:
env = FrameStack(env, num_stack=4)
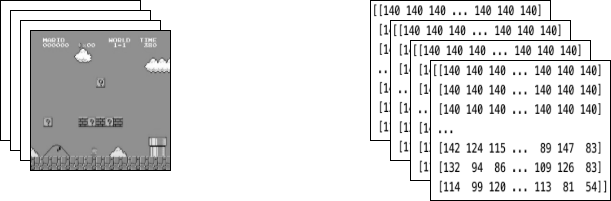
將上述封裝器應用到環境後,最終封裝的狀態包含 4 個堆疊在一起的灰階連續影格,如左側圖片所示。每次 Mario 採取一個動作,環境就會回應該結構的狀態。該結構由大小為 [4, 84, 84] 的 3D 陣列表示。
代理人 (Agent)¶
我們建立一個類別 Mario 來代表我們在遊戲中的代理人。Mario 應該能夠:
根據當前狀態(環境)按照最佳動作策略來行動 (Act)。
記住 (Remember) 經驗。經驗 = (當前狀態, 當前動作, 獎勵, 下一個狀態)。Mario 會快取 (caches) 並在之後回憶 (recalls) 他的經驗來更新他的動作策略。
學習 (Learn) 隨著時間推移,學習更好的動作策略。
class Mario:
def __init__():
pass
def act(self, state):
"""Given a state, choose an epsilon-greedy action"""
pass
def cache(self, experience):
"""Add the experience to memory"""
pass
def recall(self):
"""Sample experiences from memory"""
pass
def learn(self):
"""Update online action value (Q) function with a batch of experiences"""
pass
在接下來的章節中,我們將填寫 Mario 的參數並定義他的函數。
行動 (Act)¶
對於任何給定的狀態,代理人可以選擇執行最佳動作(利用 (exploit))或隨機動作(探索 (explore))。
Mario 以 self.exploration_rate 的機率隨機探索;當他選擇利用時,他依靠 MarioNet(在 Learn 區段中實作)來提供最佳動作。
class Mario:
def __init__(self, state_dim, action_dim, save_dir):
self.state_dim = state_dim
self.action_dim = action_dim
self.save_dir = save_dir
self.device = "cuda" if torch.cuda.is_available() else "cpu"
# Mario's DNN to predict the most optimal action - we implement this in the Learn section
self.net = MarioNet(self.state_dim, self.action_dim).float()
self.net = self.net.to(device=self.device)
self.exploration_rate = 1
self.exploration_rate_decay = 0.99999975
self.exploration_rate_min = 0.1
self.curr_step = 0
self.save_every = 5e5 # no. of experiences between saving Mario Net
def act(self, state):
"""
Given a state, choose an epsilon-greedy action and update value of step.
Inputs:
state(``LazyFrame``): A single observation of the current state, dimension is (state_dim)
Outputs:
``action_idx`` (``int``): An integer representing which action Mario will perform
"""
# EXPLORE
if np.random.rand() < self.exploration_rate:
action_idx = np.random.randint(self.action_dim)
# EXPLOIT
else:
state = state[0].__array__() if isinstance(state, tuple) else state.__array__()
state = torch.tensor(state, device=self.device).unsqueeze(0)
action_values = self.net(state, model="online")
action_idx = torch.argmax(action_values, axis=1).item()
# decrease exploration_rate
self.exploration_rate *= self.exploration_rate_decay
self.exploration_rate = max(self.exploration_rate_min, self.exploration_rate)
# increment step
self.curr_step += 1
return action_idx
快取與回憶 (Cache and Recall)¶
這兩個函數充當 Mario 的「記憶」過程。
cache():每次 Mario 執行一個動作,他都會將 experience 儲存到他的記憶中。他的經驗包括目前的狀態 (state)、執行的動作 (action)、來自該動作的獎勵 (reward)、下一個狀態 (next state) 以及遊戲是否結束 (done)。
recall():Mario 從他的記憶中隨機抽取一批經驗,並用它來學習遊戲。
class Mario(Mario): # subclassing for continuity
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.memory = TensorDictReplayBuffer(storage=LazyMemmapStorage(100000, device=torch.device("cpu")))
self.batch_size = 32
def cache(self, state, next_state, action, reward, done):
"""
Store the experience to self.memory (replay buffer)
Inputs:
state (``LazyFrame``),
next_state (``LazyFrame``),
action (``int``),
reward (``float``),
done(``bool``))
"""
def first_if_tuple(x):
return x[0] if isinstance(x, tuple) else x
state = first_if_tuple(state).__array__()
next_state = first_if_tuple(next_state).__array__()
state = torch.tensor(state)
next_state = torch.tensor(next_state)
action = torch.tensor([action])
reward = torch.tensor([reward])
done = torch.tensor([done])
# self.memory.append((state, next_state, action, reward, done,))
self.memory.add(TensorDict({"state": state, "next_state": next_state, "action": action, "reward": reward, "done": done}, batch_size=[]))
def recall(self):
"""
Retrieve a batch of experiences from memory
"""
batch = self.memory.sample(self.batch_size).to(self.device)
state, next_state, action, reward, done = (batch.get(key) for key in ("state", "next_state", "action", "reward", "done"))
return state, next_state, action.squeeze(), reward.squeeze(), done.squeeze()
學習 (Learn)¶
Mario 在底層使用 DDQN 演算法。DDQN 使用兩個 ConvNets - \(Q_{online}\) 和 \(Q_{target}\) - 來獨立地近似最佳動作價值函數。
在我們的實作中,我們跨 \(Q_{online}\) 和 \(Q_{target}\) 分享特徵生成器 features,但為每個網路維護單獨的 FC 分類器。\(\theta_{target}\)(\(Q_{target}\) 的參數)被凍結以防止通過反向傳播進行更新。相反,它會定期與 \(\theta_{online}\) 同步(稍後會詳細介紹)。
神經網路 (Neural Network)¶
class MarioNet(nn.Module):
"""mini CNN structure
input -> (conv2d + relu) x 3 -> flatten -> (dense + relu) x 2 -> output
"""
def __init__(self, input_dim, output_dim):
super().__init__()
c, h, w = input_dim
if h != 84:
raise ValueError(f"Expecting input height: 84, got: {h}")
if w != 84:
raise ValueError(f"Expecting input width: 84, got: {w}")
self.online = self.__build_cnn(c, output_dim)
self.target = self.__build_cnn(c, output_dim)
self.target.load_state_dict(self.online.state_dict())
# Q_target parameters are frozen.
for p in self.target.parameters():
p.requires_grad = False
def forward(self, input, model):
if model == "online":
return self.online(input)
elif model == "target":
return self.target(input)
def __build_cnn(self, c, output_dim):
return nn.Sequential(
nn.Conv2d(in_channels=c, out_channels=32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(3136, 512),
nn.ReLU(),
nn.Linear(512, output_dim),
)
TD 估計 & TD 目標 (TD Estimate & TD Target)¶
學習涉及兩個值:
TD 估計 (TD Estimate) - 針對給定狀態 \(s\) 預測的最佳 \(Q^*\)。
TD 目標 (TD Target) - 目前獎勵和下一個狀態 \(s'\) 中估計的 \(Q^*\) 的聚合。
因為我們不知道下一個動作 \(a'\) 會是什麼,所以我們使用最大化下一個狀態 \(s'\) 中 \(Q_{online}\) 的動作 \(a'\)。
請注意,我們在 td_target() 上使用了 @torch.no_grad() 裝飾器來停用此處的梯度計算(因為我們不需要在 \(\theta_{target}\) 上進行反向傳播)。
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.gamma = 0.9
def td_estimate(self, state, action):
current_Q = self.net(state, model="online")[
np.arange(0, self.batch_size), action
] # Q_online(s,a)
return current_Q
@torch.no_grad()
def td_target(self, reward, next_state, done):
next_state_Q = self.net(next_state, model="online")
best_action = torch.argmax(next_state_Q, axis=1)
next_Q = self.net(next_state, model="target")[
np.arange(0, self.batch_size), best_action
]
return (reward + (1 - done.float()) * self.gamma * next_Q).float()
更新模型 (Updating the model)¶
當 Mario 從他的重播緩衝區中採樣輸入時,我們計算 \(TD_t\) 和 \(TD_e\) 並將此損失反向傳播到 \(Q_{online}\) 以更新其參數 \(\theta_{online}\)(\(\alpha\) 是傳遞給 optimizer 的學習率 lr)。
\(\theta_{target}\) 不會通過反向傳播進行更新。相反,我們會定期將 \(\theta_{online}\) 複製到 \(\theta_{target}\)。
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=0.00025)
self.loss_fn = torch.nn.SmoothL1Loss()
def update_Q_online(self, td_estimate, td_target):
loss = self.loss_fn(td_estimate, td_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
def sync_Q_target(self):
self.net.target.load_state_dict(self.net.online.state_dict())
儲存檢查點 (Save checkpoint)¶
class Mario(Mario):
def save(self):
save_path = (
self.save_dir / f"mario_net_{int(self.curr_step // self.save_every)}.chkpt"
)
torch.save(
dict(model=self.net.state_dict(), exploration_rate=self.exploration_rate),
save_path,
)
print(f"MarioNet saved to {save_path} at step {self.curr_step}")
將它們放在一起 (Putting it all together)¶
class Mario(Mario):
def __init__(self, state_dim, action_dim, save_dir):
super().__init__(state_dim, action_dim, save_dir)
self.burnin = 1e4 # min. experiences before training
self.learn_every = 3 # no. of experiences between updates to Q_online
self.sync_every = 1e4 # no. of experiences between Q_target & Q_online sync
def learn(self):
if self.curr_step % self.sync_every == 0:
self.sync_Q_target()
if self.curr_step % self.save_every == 0:
self.save()
if self.curr_step < self.burnin:
return None, None
if self.curr_step % self.learn_every != 0:
return None, None
# Sample from memory
state, next_state, action, reward, done = self.recall()
# Get TD Estimate
td_est = self.td_estimate(state, action)
# Get TD Target
td_tgt = self.td_target(reward, next_state, done)
# Backpropagate loss through Q_online
loss = self.update_Q_online(td_est, td_tgt)
return (td_est.mean().item(), loss)
日誌 (Logging)¶
import numpy as np
import time, datetime
import matplotlib.pyplot as plt
class MetricLogger:
def __init__(self, save_dir):
self.save_log = save_dir / "log"
with open(self.save_log, "w") as f:
f.write(
f"{'Episode':>8}{'Step':>8}{'Epsilon':>10}{'MeanReward':>15}"
f"{'MeanLength':>15}{'MeanLoss':>15}{'MeanQValue':>15}"
f"{'TimeDelta':>15}{'Time':>20}\n"
)
self.ep_rewards_plot = save_dir / "reward_plot.jpg"
self.ep_lengths_plot = save_dir / "length_plot.jpg"
self.ep_avg_losses_plot = save_dir / "loss_plot.jpg"
self.ep_avg_qs_plot = save_dir / "q_plot.jpg"
# History metrics
self.ep_rewards = []
self.ep_lengths = []
self.ep_avg_losses = []
self.ep_avg_qs = []
# Moving averages, added for every call to record()
self.moving_avg_ep_rewards = []
self.moving_avg_ep_lengths = []
self.moving_avg_ep_avg_losses = []
self.moving_avg_ep_avg_qs = []
# Current episode metric
self.init_episode()
# Timing
self.record_time = time.time()
def log_step(self, reward, loss, q):
self.curr_ep_reward += reward
self.curr_ep_length += 1
if loss:
self.curr_ep_loss += loss
self.curr_ep_q += q
self.curr_ep_loss_length += 1
def log_episode(self):
"Mark end of episode"
self.ep_rewards.append(self.curr_ep_reward)
self.ep_lengths.append(self.curr_ep_length)
if self.curr_ep_loss_length == 0:
ep_avg_loss = 0
ep_avg_q = 0
else:
ep_avg_loss = np.round(self.curr_ep_loss / self.curr_ep_loss_length, 5)
ep_avg_q = np.round(self.curr_ep_q / self.curr_ep_loss_length, 5)
self.ep_avg_losses.append(ep_avg_loss)
self.ep_avg_qs.append(ep_avg_q)
self.init_episode()
def init_episode(self):
self.curr_ep_reward = 0.0
self.curr_ep_length = 0
self.curr_ep_loss = 0.0
self.curr_ep_q = 0.0
self.curr_ep_loss_length = 0
def record(self, episode, epsilon, step):
mean_ep_reward = np.round(np.mean(self.ep_rewards[-100:]), 3)
mean_ep_length = np.round(np.mean(self.ep_lengths[-100:]), 3)
mean_ep_loss = np.round(np.mean(self.ep_avg_losses[-100:]), 3)
mean_ep_q = np.round(np.mean(self.ep_avg_qs[-100:]), 3)
self.moving_avg_ep_rewards.append(mean_ep_reward)
self.moving_avg_ep_lengths.append(mean_ep_length)
self.moving_avg_ep_avg_losses.append(mean_ep_loss)
self.moving_avg_ep_avg_qs.append(mean_ep_q)
last_record_time = self.record_time
self.record_time = time.time()
time_since_last_record = np.round(self.record_time - last_record_time, 3)
print(
f"Episode {episode} - "
f"Step {step} - "
f"Epsilon {epsilon} - "
f"Mean Reward {mean_ep_reward} - "
f"Mean Length {mean_ep_length} - "
f"Mean Loss {mean_ep_loss} - "
f"Mean Q Value {mean_ep_q} - "
f"Time Delta {time_since_last_record} - "
f"Time {datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S')}"
)
with open(self.save_log, "a") as f:
f.write(
f"{episode:8d}{step:8d}{epsilon:10.3f}"
f"{mean_ep_reward:15.3f}{mean_ep_length:15.3f}{mean_ep_loss:15.3f}{mean_ep_q:15.3f}"
f"{time_since_last_record:15.3f}"
f"{datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S'):>20}\n"
)
for metric in ["ep_lengths", "ep_avg_losses", "ep_avg_qs", "ep_rewards"]:
plt.clf()
plt.plot(getattr(self, f"moving_avg_{metric}"), label=f"moving_avg_{metric}")
plt.legend()
plt.savefig(getattr(self, f"{metric}_plot"))
讓我們開始玩吧! (Let's play!)¶
在本範例中,我們將訓練迴圈執行 40 個回合,但為了讓 Mario 真正學習他世界的方式,我們建議將迴圈執行至少 40,000 個回合!
use_cuda = torch.cuda.is_available()
print(f"Using CUDA: {use_cuda}")
print()
save_dir = Path("checkpoints") / datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
save_dir.mkdir(parents=True)
mario = Mario(state_dim=(4, 84, 84), action_dim=env.action_space.n, save_dir=save_dir)
logger = MetricLogger(save_dir)
episodes = 40
for e in range(episodes):
state = env.reset()
# Play the game!
while True:
# Run agent on the state
action = mario.act(state)
# Agent performs action
next_state, reward, done, trunc, info = env.step(action)
# Remember
mario.cache(state, next_state, action, reward, done)
# Learn
q, loss = mario.learn()
# Logging
logger.log_step(reward, loss, q)
# Update state
state = next_state
# Check if end of game
if done or info["flag_get"]:
break
logger.log_episode()
if (e % 20 == 0) or (e == episodes - 1):
logger.record(episode=e, epsilon=mario.exploration_rate, step=mario.curr_step)
Using CUDA: True
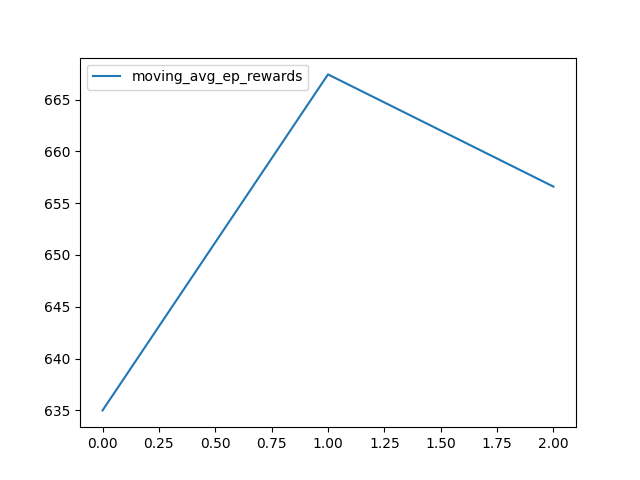
Episode 0 - Step 163 - Epsilon 0.9999592508251706 - Mean Reward 635.0 - Mean Length 163.0 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 1.881 - Time 2025-02-03T17:21:52
Episode 20 - Step 5007 - Epsilon 0.9987490329557962 - Mean Reward 667.429 - Mean Length 238.429 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 57.036 - Time 2025-02-03T17:22:49
Episode 39 - Step 8854 - Epsilon 0.9977889477081997 - Mean Reward 656.6 - Mean Length 221.35 - Mean Loss 0.0 - Mean Q Value 0.0 - Time Delta 46.039 - Time 2025-02-03T17:23:35
結論 (Conclusion)¶
在本教學課程中,我們看到了如何使用 PyTorch 來訓練一個玩遊戲的 AI。您可以使用相同的方法來訓練 AI 玩 OpenAI gym 中的任何遊戲。希望您喜歡本教學課程,請隨時透過 我們的 github 與我們聯繫!
腳本的總執行時間:(1 分鐘 45.929 秒)
