


注意
點擊此處下載完整的範例程式碼
使用基於 PyTorch 的 USB 的半監督學習¶
建立於:2023 年 12 月 07 日 | 最後更新:2024 年 03 月 07 日 | 最後驗證:未驗證
作者:Hao Chen
統一半監督學習基準 (USB) 是一個基於 PyTorch 的半監督學習 (SSL) 框架。基於 PyTorch 提供的 Datasets 和 Modules,USB 成為一個靈活、模組化且易於使用的半監督學習框架。它支援各種半監督學習演算法,包括 FixMatch、FreeMatch、DeFixMatch、SoftMatch 等。它還支援各種不平衡半監督學習演算法。USB 中包含跨越電腦視覺、自然語言處理和語音處理不同資料集的基準結果。
本教學將引導您了解使用 USB lighting 套件的基本知識。讓我們開始訓練一個使用預訓練 Vision Transformers (ViT) 的 CIFAR-10 上的 FreeMatch/SoftMatch 模型!我們將展示更改半監督演算法並在不平衡資料集上進行訓練是多麼容易。
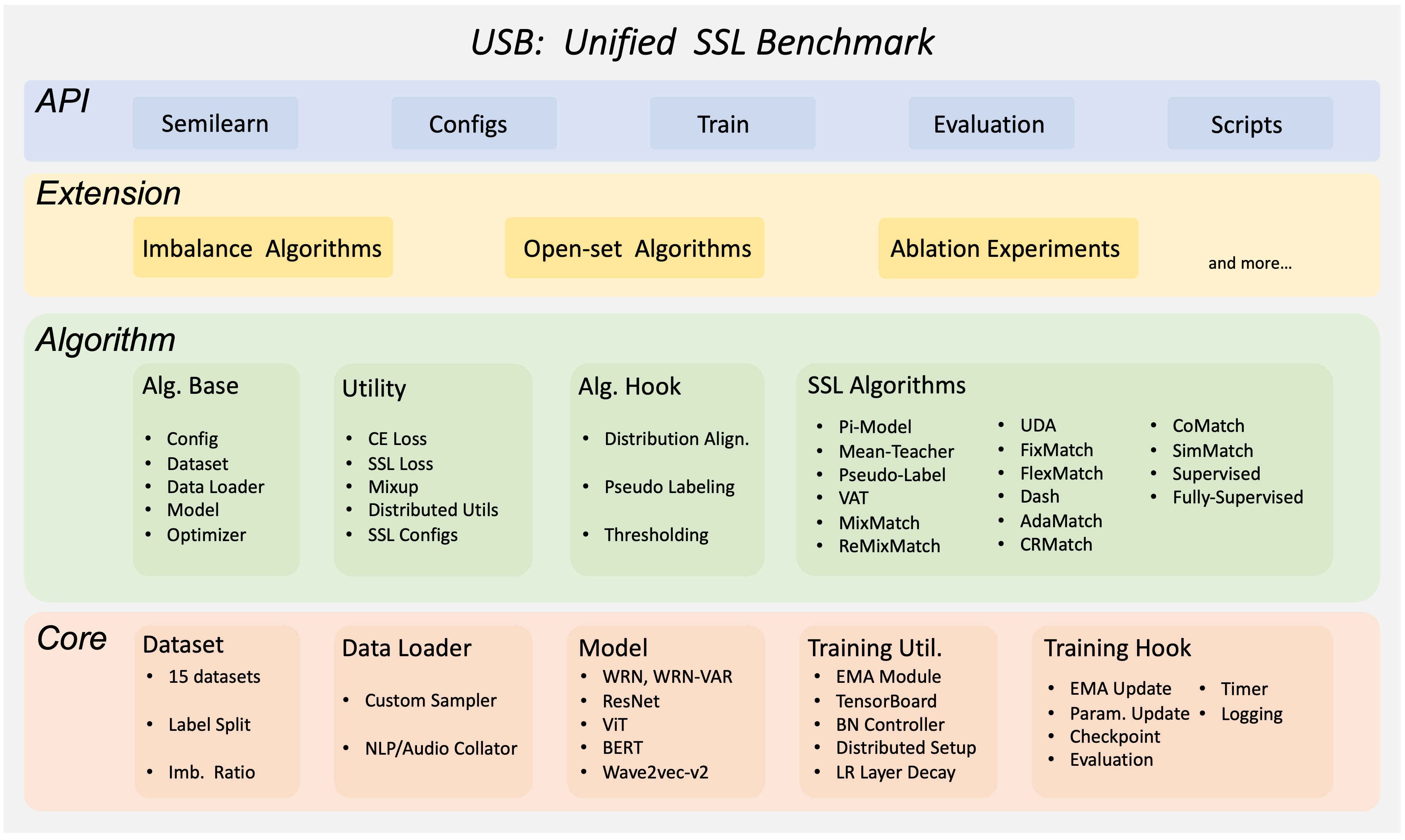
半監督學習中 FreeMatch 和 SoftMatch 簡介¶
在這裡,我們簡要介紹 FreeMatch 和 SoftMatch。首先,我們介紹一個著名的半監督學習基準,稱為 FixMatch。FixMatch 是一個非常簡單的半監督學習框架,它利用強大的擴增來為未標記的資料產生偽標籤。它採用信心閾值策略來過濾掉低信心的偽標籤,並設定固定閾值。FreeMatch 和 SoftMatch 是兩種改進 FixMatch 的演算法。FreeMatch 提出自適應閾值策略來取代 FixMatch 中的固定閾值策略。自適應閾值根據模型在每個類別上的學習狀態逐漸增加閾值。SoftMatch 吸收了信心閾值作為加權機制的概念。它提出了一種高斯加權機制來克服偽標籤中的數量-品質權衡。在本教學中,我們將使用 USB 來訓練 FreeMatch 和 SoftMatch。
使用 USB 僅使用 40 個標籤在 CIFAR-10 上訓練 FreeMatch/SoftMatch¶
USB 易於使用和擴充,小型團隊也能負擔得起,並且全面,適用於開發和評估 SSL 演算法。 USB 提供了基於一致性正規化的 14 種 SSL 演算法的實作,以及來自 CV、NLP 和音訊領域的 15 個評估任務。它具有模組化設計,允許使用者透過新增新的演算法和任務來輕鬆擴充套件。它還支援 Python API,以便更容易地將不同的 SSL 演算法應用於新資料。
現在,讓我們使用 USB 在 CIFAR-10 上訓練 FreeMatch 和 SoftMatch。首先,我們需要安裝 USB 套件 semilearn 並從 USB 匯入必要的 API 函數。如果您在 Google Colab 中執行此操作,請透過執行:!pip install semilearn 安裝 semilearn。
以下是我們將從 semilearn 使用的函數列表
get_dataset用於載入資料集,此處我們使用 CIFAR-10get_data_loader用於建立訓練(已標記和未標記)和測試資料
載入器,訓練未標記的載入器將提供未標記資料的強和弱擴增 - get_net_builder 用於建立模型,此處我們使用預訓練的 ViT - get_algorithm 用於建立半監督學習演算法,此處我們使用 FreeMatch 和 SoftMatch - get_config:用於取得演算法的預設配置 - Trainer:用於在資料集上訓練和評估演算法的 Trainer 類別
請注意,使用 semilearn 套件進行訓練需要啟用 CUDA 的後端。有關在 Google Colab 中啟用 CUDA 的說明,請參閱在 Google Colab 中啟用 CUDA。
import semilearn
from semilearn import get_dataset, get_data_loader, get_net_builder, get_algorithm, get_config, Trainer
匯入必要的函數後,我們先設定演算法的超參數。
config = {
'algorithm': 'freematch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 40,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
接著,我們載入資料集,並建立用於訓練和測試的資料載入器。然後指定要使用的模型和演算法。
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
現在我們可以開始在具有 40 個標籤的 CIFAR-10 上訓練演算法。我們訓練 500 個迭代次數,並每 500 個迭代次數評估一次。
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
最後,讓我們在驗證集上評估已訓練的模型。 在僅使用 CIFAR-10 的 40 個標籤,以 FreeMatch 訓練 500 個迭代次數後,我們獲得了一個分類器,該分類器在驗證集上達到約 87% 的準確度。
trainer.evaluate(eval_loader)
使用 USB 在不平衡的 CIFAR-10 上,以特定的不平衡演算法訓練 SoftMatch¶
現在假設我們有 CIFAR-10 的不平衡標記資料集和未標記資料集,並且我們想在上面訓練一個 SoftMatch 模型。 我們通過將 lb_imb_ratio 和 ulb_imb_ratio 設置為 10,來建立 CIFAR-10 的不平衡標記資料集和不平衡未標記資料集。 此外,我們將 algorithm 替換為 softmatch,並將 imbalanced 設置為 True。
config = {
'algorithm': 'softmatch',
'net': 'vit_tiny_patch2_32',
'use_pretrain': True,
'pretrain_path': 'https://github.com/microsoft/Semi-supervised-learning/releases/download/v.0.0.0/vit_tiny_patch2_32_mlp_im_1k_32.pth',
# optimization configs
'epoch': 1,
'num_train_iter': 500,
'num_eval_iter': 500,
'num_log_iter': 50,
'optim': 'AdamW',
'lr': 5e-4,
'layer_decay': 0.5,
'batch_size': 16,
'eval_batch_size': 16,
# dataset configs
'dataset': 'cifar10',
'num_labels': 1500,
'num_classes': 10,
'img_size': 32,
'crop_ratio': 0.875,
'data_dir': './data',
'ulb_samples_per_class': None,
'lb_imb_ratio': 10,
'ulb_imb_ratio': 10,
'ulb_num_labels': 3000,
# algorithm specific configs
'hard_label': True,
'T': 0.5,
'ema_p': 0.999,
'ent_loss_ratio': 0.001,
'uratio': 2,
'ulb_loss_ratio': 1.0,
# device configs
'gpu': 0,
'world_size': 1,
'distributed': False,
"num_workers": 4,
}
config = get_config(config)
接著,我們重新載入資料集,並建立用於訓練和測試的資料載入器。然後指定要使用的模型和演算法。
dataset_dict = get_dataset(config, config.algorithm, config.dataset, config.num_labels, config.num_classes, data_dir=config.data_dir, include_lb_to_ulb=config.include_lb_to_ulb)
train_lb_loader = get_data_loader(config, dataset_dict['train_lb'], config.batch_size)
train_ulb_loader = get_data_loader(config, dataset_dict['train_ulb'], int(config.batch_size * config.uratio))
eval_loader = get_data_loader(config, dataset_dict['eval'], config.eval_batch_size)
algorithm = get_algorithm(config, get_net_builder(config.net, from_name=False), tb_log=None, logger=None)
現在我們可以開始在具有 40 個標籤的 CIFAR-10 上訓練演算法。 我們訓練 500 個迭代次數,並每 500 個迭代次數評估一次。
trainer = Trainer(config, algorithm)
trainer.fit(train_lb_loader, train_ulb_loader, eval_loader)
最後,讓我們在驗證集上評估已訓練的模型。
trainer.evaluate(eval_loader)
參考文獻: - [1] USB: https://github.com/microsoft/Semi-supervised-learning - [2] Kihyuk Sohn et al. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence - [3] Yidong Wang et al. FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning - [4] Hao Chen et al. SoftMatch: Addressing the Quantity-Quality Trade-off in Semi-supervised Learning
腳本的總執行時間: ( 0 分鐘 0.000 秒)
